
神經網路中交叉熵代價函式 求導
阿新 • • 發佈:2019-02-11
最近看了幾篇神經網路的入門介紹知識,有幾篇很淺顯的博文介紹了神經網路演算法執行的基本原理,首先盜用伯樂線上中的一個11行python程式碼搞定的神經網路,
import numpy as np
# sigmoid function
def nonlin(x,deriv=False):
if(deriv==True):
return x*(1-x)
return 1/(1+np.exp(-x))
# input dataset
X = np.array([ [0,0,1],
[0,1,1],
[1 確實該博文運用淺顯的語言解釋了神經網路的基本來龍去脈(剩下的由開發者自由發揮了),從輸入層到隱藏層到最終的輸出,基本都是這樣一張圖描述的:
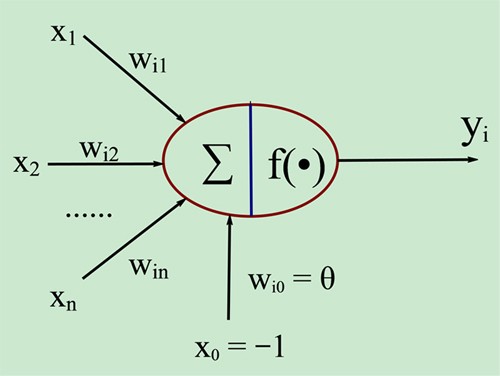
下面該講重點了,就是最核心的運用梯度下降來訓練模型,加快計算的效率,這個就是程式碼 l1_delta = l1_error * nonlin(l1,True) 的功效,只可惜這行程式碼看似簡單,背後涉及了的公式推導還不少,其實很多演算法看似簡單的編碼背後都是隱藏了大量的公式推導,這個才是最困難的,不廢話,講重點。
神經網路中的損失函式採用了交叉熵的公式,而沒有采用通常的差的平方和公式(具體解釋可看http://blog.csdn.net/u012162613/article/details/44239919),這個目的當然是為了簡化計算的複雜度,深度學習也是因為簡化了神經網路的計算複雜度得以推廣了,公式如下,x,y代表了訓練集中的輸入樣本x及真實類別值y:
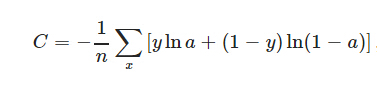
其中,a是神經元中的sigmod函式,也是最終的預測值,即上圖中的f(·)函式值,表示式為:
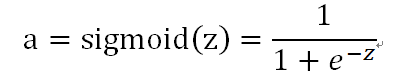
其中,對a求導後的表示式為,a的求導值可以用a表示:
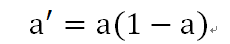
而z是輸入樣本x的線性組合,這一個神經元的處理跟邏輯迴歸很像的,即:
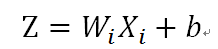
然後,基本公式都列出來(盜圖,σ()就是f()),可以求使得C取得最小值的w,b了,分別對w,b求導,然後就會得出:
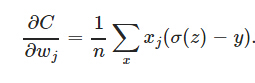
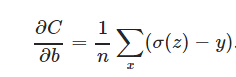
最終,梯度下降法就是為了計算對於w,b的更新速率,這裡面的好處可以參考更權威的解釋了。