
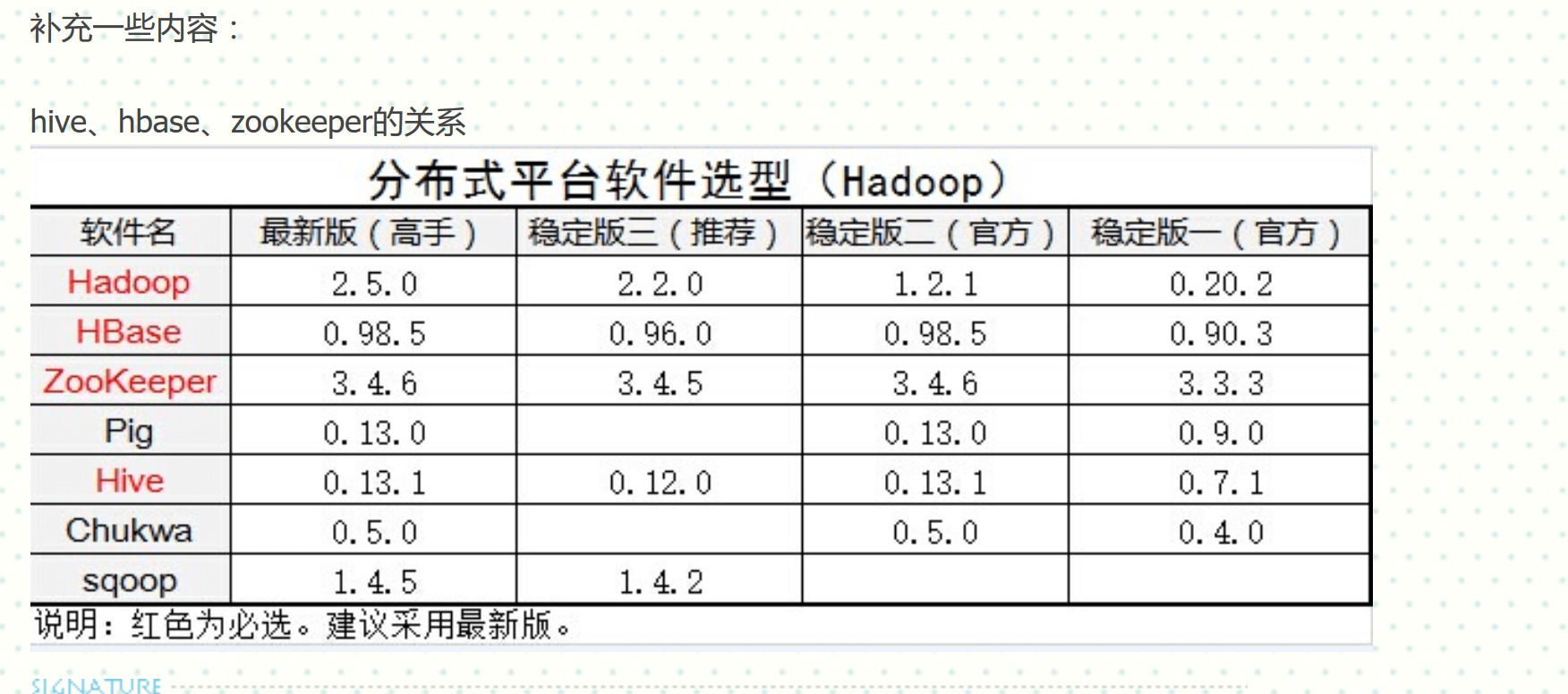
hadoop、hbase、hive版本對應關係
這是從一個部落格上找到的,地址:http://www.aboutyun.com/thread-7295-1-1.html
分享下核心內容:
帖子1
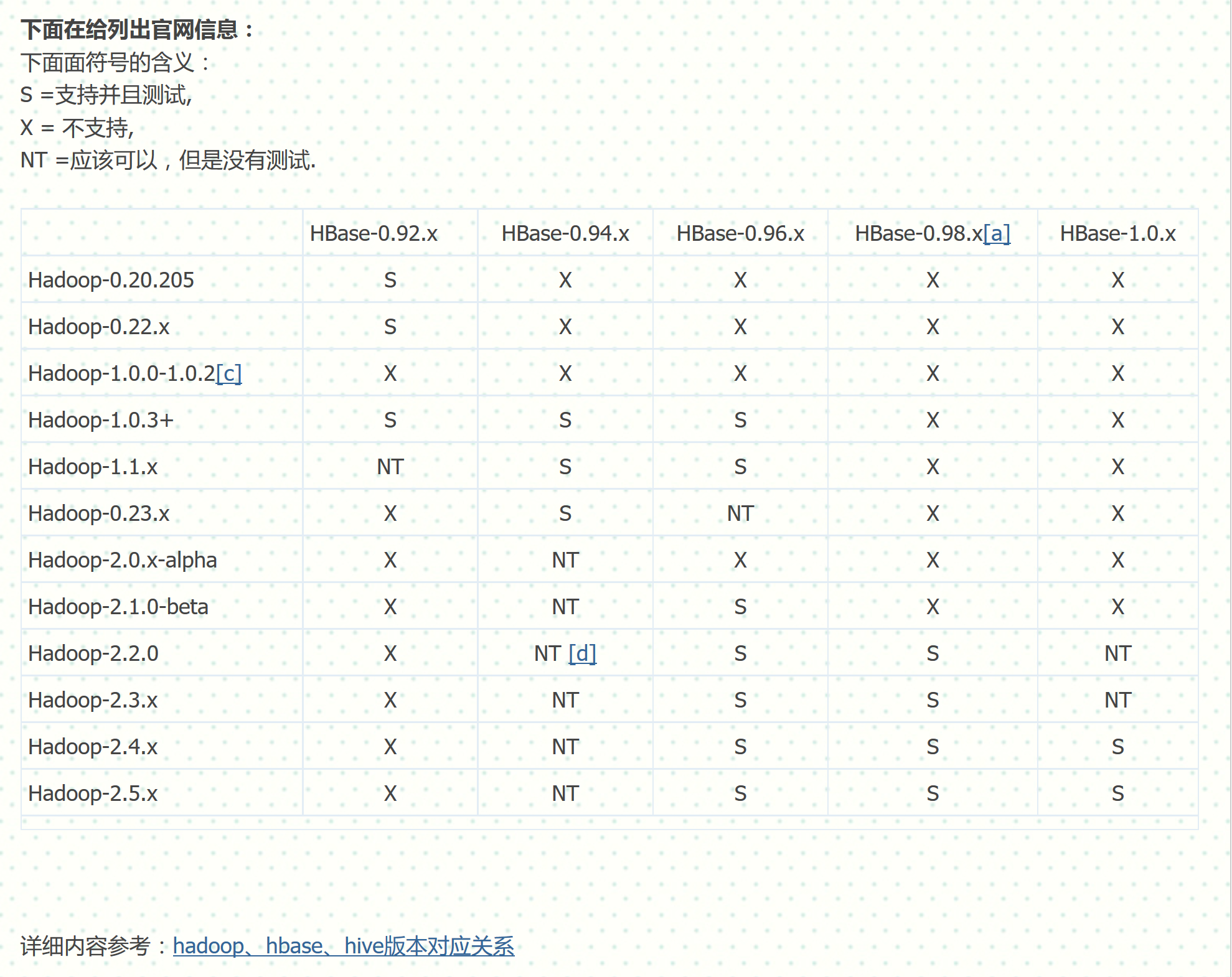
hadoop與HBase版本對應關係:
Hbase Hadoop
0.92.0 1.0.0
0.92.1 1.0.0
0.92.2 1.0.3
0.94.0 1.0.2
0.94.1 1.0.3
0.94.2 1.0.3
0.94.3 1.0.4
0.94.4 1.0.4
0.94.5 1.0.4
0.94.9 1.2.0
0.95.0 1.2.0
hadoop1.2+hbase0.95.0+hive0.11.0 會產生hbase+hive的不相容,建立hive+hbase的關聯表就會報pair對異常。
hadoop1.2+hbase0.94.9+hive0.10.0 沒問題,解決了上個版本的不相容問題。
帖子2(是不是官網,我沒驗證過啊)
帖子3:
相關推薦
hadoop 、hbase 、hive 版本對應關係
我們開發,使用過程中,安裝 hadoop,hbase,hive可能版本不同,產生各種相容性的問題。於是整理一下hbase 、hive 、hadoop 的對應關係,做一下記錄 hadoop1.2+hbase0.95.0+hive0.11.0 會產生hbase+hive的不相容
hadoop、hbase、hive版本對應關係
這是從一個部落格上找到的,地址:http://www.aboutyun.com/thread-7295-1-1.html 分享下核心內容: 帖子1hadoop與HBase版本對應關係: Hbase Hadoop 0.92.0 1.0.0 0.92.1
AndroidStudio、gradle、buildToolsVersion概述,版本對應關係
使用AndroidStudio 開發也已經2年了,每次gradle 或者studio 有推薦更新後,專案重新sync後都會報錯,提示更新相應的其他版本,比如AndroidStudio、gradle、buildToolsVersion版本; AndroidStudio: 是Google官方
檢視Anaconda版本、Anaconda和python版本對應關係和快速下載
官網 檢視Anaconda版本 (C:\ProgramData\Anaconda3) C:\Users\Administrator>conda -V conda 4.3.30 Anaconda和python版本對應關係 Anaconda3-4.3.0.1-Wind
hadoop、hbase、hive等版本對應關係
hadoop與HBase版本對應關係:Hbase Hadoop0.92.0 1.0.00.92.1 1.0.00.92.2 1.0.30.94.0 1.0.20.94.1 1.0.30.94.2 1.0.30.94.3 1.0.
Hadoop、Hbase、Hive和zookeeper版本匹配關係
Hadoop平臺中各個元件的版本匹配非常重要!不是所有元件都下載最新版本就好,版本不匹配和引發各種問題。 Hadoop和Hbase的匹配關係可以檢視Hbase官方文件,搜尋‘Hadoop version support matrix’: Hadoop和Hive的匹
Hadoop、Hbase、Hive、Zookeeper預設埠說明
elasticsearch: 9300:Java 客戶端都是通過 9300 埠並使用 Elasticsearch 的原生 傳輸 協議和叢集互動。叢集中的節點通過埠 9300 彼此通訊 9
hadoop、spark、Hbase、Hive、hdfs,是什麼
這些都是“大資料”相關的概念,即和關係型資料庫,相比較而產生的新技術。即j2ee的web開發中,資料庫部分(如傳統的關係型資料庫的oracle),的內容 1Hbase:是一個nosql資料庫,和mongodb類似。 2hdfs:hadoop distribut file
hadoop、hbase、hive、spark分散式系統架構原理
全棧工程師開發手冊 (作者:欒鵬) 機器學習、資料探勘等各種大資料處理都離不開各種開源分散式系統,hadoop使用者分散式儲存和map-reduce計算,spark用於分散式機器學習,hive是分散式資料庫,hbase是分散式kv系統,看似互不相關的他們卻
centos7下搭建hadoop、hbase、hive、spark分散式系統架構
全棧工程師開發手冊 (作者:欒鵬) 在使用前建議先將當前使用者設定為root使用者。參考https://blog.csdn.net/luanpeng825485697/article/details/80278383中修改使用者許可權的第三種方法。有了
大資料叢集遇到的問題(Hadoop、Spark、Hive、kafka、Hbase、Phoenix)
大資料平臺中遇到的實際問題,整理了一下,使用CDH5.8版本,包括Hadoop、Spark、Hive、kafka、Hbase、Phoenix、Impala、Sqoop、CDH等問題,初步整理下最近遇到的問題,不定期更新。 啟動nodemanager失敗 2016-09-07
mockito、powermock版本對應關係
相信有些朋友也碰到和我一樣的問題,mockito結合powermock做單元測試會碰到一些明明程式看起來沒問題,卻始終報錯。 有可能的問題就是版本使用不對,大家如果遇到這樣的問題可以試試。(PS:當然
我的Hadoop、Hbase、Hive、Impala總結
1.怎麼查詢hadoop_home 看Hive安裝的時候需要配置hadoop_home 因為不太懂,查找了一下/etc/profile檔案發現沒有, 又搜尋了一下發現叫hadoop的目錄到處都是,不知道哪個是,最後同事說,有bin的目錄就是hadoop_home,那麼多資料
Hadoop(HDFS、YARN、HBase、Hive和Spark等)預設埠表
埠 作用 9000 fs.defaultFS,如:hdfs://172.25.40.171:9000 9001 dfs.namenode.rpc-address,DataNode會連線這個
eclipse、jdk、tomcat版本對應關係
不同版本的eclipse對jdk版本要求不一樣,最高支援tomcat版本也不一樣,以下對應關係本人親自下載eclipse驗證過,可放心使用。 Eclipse 4.8 (Photon)--------Java8--------Tomcat9.0 Eclipse 4.7
sqoop命令,mysql導入到hdfs、hbase、hive
tar 新增 對數 lec 規約 協議 系列 聯系 ont 1.測試MySQL連接 bin/sqoop list-databases --connect jdbc:mysql://192.168.1.187:3306/trade_dev --username ‘mysq
Haddoop中的hdfs、hbase、 hive區別與聯絡
Hive: Hive不支援更改資料的操作,Hive基於資料倉庫,提供靜態資料的動態查詢。其使用類SQL語言,底層經過編譯轉為MapReduce程式,在Hadoop上執行,資料儲存在HDFS上。 HDFS: HDFS是GFS的一種實現
Hive、HBase、Impala的簡單對比
Impalad: 與DataNode執行在同一節點上,由Impalad程序表示,它接收客戶端的查詢請求(接收查詢請求的Impalad為Coordinator,Coordinator通過JNI呼叫java前端解釋SQL查詢語句,生成查詢計劃樹,再通過排程器把執行計劃分發給具有相應資料的其它Impalad進行執行
firefox、geckodriver.exe、selenium-server-standlone版本對應及下載地址
selenium-server-standlone-3.3.1.jar 下載地址: http://selenium-release.storage.googleapis.com/index.html geckodriver.exe V.15.0 下載地址:https:/
hive、hbase、mysql資料傳輸,hive優化實踐(一)
此次實踐緣由 hive自去年學習後,就一直放著少有使用了,前幾天接到面試,說hive這塊,讓再多學習學習。 所以有了這次實踐,複習一把。 主要是想做些優化,以及嘗試模擬出資料傾斜並解決傾斜的問題 關於實驗 實驗的前半部分大部分參考的林子雨