
Linux檔案系統學習(四)之read open系統呼叫
open的執行過程:v2.6.30
Open
Sys_open
|do_sys_open()
|get_unused_fd_flags ()//得到一個可用的檔案描述符;通過該函式,可知檔案描述符
//實質是程序開啟檔案列表中對應某個檔案物件的索引值;
|do_filp_open()//開啟檔案,返回一個file物件,代表由該程序開啟的一個文
//
|if(!(flag & O_CREAT))//不是要建立
|path_lookup_open()//根據檔案路徑名查詢檔案,並初始化struct nameidata物件
| do_path_lookup()
|goto OK;
|else //建立一個新的檔案
|do_path_lookup()//查詢父目錄
|__open_namei_create
|vfs_create()//建立inode在vfs_create()裡的一句核心語句dir->i_op->create(dir, dentry, mode, nd)
|may_open()//
只有寫許可權的目錄是不能被開啟的,先檢查nd->dentry->inode所指的檔案是否是這一類檔案,是的話則錯誤返回。還有一些檔案是不能以TRUNC的方式開啟的,若nd->dentry->inode所指的檔案屬於這一類,則顯式地關閉TRUNC標誌位。接著如果有以TRUNC方式開啟檔案的,則更新nd->dentry->inode的資訊
|nameidata_to_filp()//將nameidata轉換為一個open的file :filp
|__dentry_open()//將呼叫實際檔案的操作方法賦值給file物件,這樣當最後通過統一的系統呼叫處理file物件的時候,就會呼叫正確的實際檔案系統方法。
?end do_filp_open
|fd_install()//建立檔案描述符與file物件的聯絡,即把file物件賦值到fd陣列中,以後程序對檔案的讀寫就可以通過操縱該檔案描述符而進行。
?end do_sys_open
?end open
通過以上的過程可以把open過程總結如下:
1首先獲得一個未使用的檔案描述符
2然後通過把路徑解析為各個遞進的目錄項物件(如把/home/test/a.txt解析為”/”、”home”、”test”、”a.txt”),來查詢實際的檔案(也可以是路徑)是否存在,該過程就是為了獲得檔案的inode節點,並最終賦值給可操作的file物件
查詢的過程首先判斷該目錄(如”/”,由d_hash計算查詢)是否存在於dentry cache當中,如果存在則不需要再建立該目錄項物件,直接得到目錄項物件(此時說明inode也存在於inode cache中)所以就可以直接得到inode節點,然後開啟該檔案(這裡就是”/”目錄),然後依次類推,直接找到a.txt的inode節點為止。如果該目錄對應的目錄項物件不存在於dentry cache中,則先建立一個目錄項物件,然後再在磁碟中查詢該目錄項物件對應的inode節點是否存在,如果存在則快取到cache中,並查詢下一級目錄,如果不存在並且falg標誌為O_CREAT的話,則建立一個inode節點。因為只有得到inode節點,才能知道檔案的所在磁碟位置,以及相應的操作方法。
3 建立檔案描述符與file物件的聯絡
下來看一下read的系統呼叫過程如下圖:
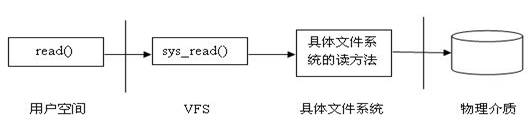
圖read的呼叫過程
上圖描述了從使用者空間的read()呼叫到資料從磁碟讀出的整個流程。當在使用者應用程式呼叫檔案I/O read()操作時,系統呼叫sys_read()被激發,sys_read()找到檔案所在的具體檔案系統,把控制權傳給該檔案系統,最後由具體檔案系統與物理介質互動,從介質中讀出資料。
對檔案進行讀操作時,需要先開啟它。在開啟一個檔案(open)時,會在記憶體組裝一個檔案物件,最後對該檔案執行的操作方法已在檔案物件設定好。所以對檔案進行讀操作時,VFS在做了一些簡單的轉換後(由檔案描述符得到其對應的檔案物件;其核心思想是返回current->files->fd[fd]所指向的檔案物件),就可以通過語句file->f_op->read(file, buf, count, pos)輕鬆呼叫實際檔案系統的相應方法對檔案進行讀操作了。
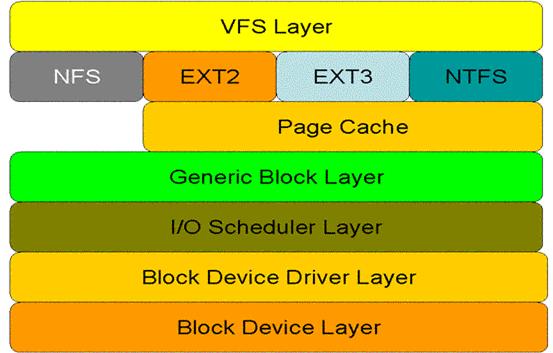
圖 系統呼叫在核心空間中的處理層次
上圖顯示了 read 系統呼叫在核心空間中所要經歷的層次模型。從圖中看出:對於磁碟的一次讀請求,首先經過虛擬檔案系統層(vfs layer),其次是具體的檔案系統層(例如 ext2),接下來是 cache 層(page cache 層)、通用塊層(generic block layer)、IO 排程層(I/O scheduler layer)、塊裝置驅動層(block device driver layer),最後是物理塊裝置層(block device layer)。
·虛擬檔案系統層的作用:遮蔽下層具體檔案系統操作的差異,為上層的操作提供一個統一的介面。正是因為有了這個層次,所以可以把裝置抽象成檔案,使得操作裝置就像操作檔案一樣簡單。
·在具體的檔案系統層中,不同的檔案系統(例如 ext2 和 NTFS)具體的操作過程也是不同的。每種檔案系統定義了自己的操作集合。關於檔案系統的更多內容,請參見參考資料。
·引入 cache 層的目的是為了提高 linux 作業系統對磁碟訪問的效能。 Cache 層在記憶體中快取了磁碟上的部分資料。當資料的請求到達時,如果在 cache 中存在該資料且是最新的,則直接將資料傳遞給使用者程式,免除了對底層磁碟的操作,提高了效能。
·通用塊層的主要工作是:接收上層發出的磁碟請求,並最終發出 IO 請求。該層隱藏了底層硬體塊裝置的特性,為塊裝置提供了一個通用的抽象檢視。
·IO 排程層的功能:接收通用塊層發出的 IO 請求,快取請求並試圖合併相鄰的請求(如果這兩個請求的資料在磁碟上是相鄰的)。並根據設定好的排程演算法,回撥驅動層提供的請求處理函式,以處理具體的 IO 請求。
·驅動層中的驅動程式對應具體的物理塊裝置。它從上層中取出 IO 請求,並根據該 IO 請求中指定的資訊,通過向具體塊裝置的裝置控制器傳送命令的方式,來操縱裝置傳輸資料。
裝置層中都是具體的物理裝置。定義了操作具體裝置的規範。