NumPy學習(二)
其他基本用法
廣播(Broadcasting)
廣播規則解釋NumPy如何處理不同維度陣列之間的算數運算問題。在一定條件下,維度較小的陣列廣播為更大的陣列,使他們具有相同的維度形狀。廣播提供了一種向量化陣列操作方法,使得迴圈發生在C而不是Python。廣播不會產生沒必要的資料複製,通常會使演算法執行更加有效。缺點是,廣播會使記憶體的使用效率降低,並影響計算速度。
NumPy運算執行在陣列的每個元素基礎上。如下所示,兩個陣列必須有相同的形狀。
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = np.array([2.0 當陣列滿足一定的約束時,NumPy的廣播規則會降低形狀必須相同的約束。廣播的一個簡單例子就是一個數組與一個數值進行運算。
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = 2.0
>>> a * b
array([ 2., 4., 6.])結果與第一個例子b為陣列時相同。我們可以認為數值b在與陣列a進行算數運算時被拉伸為與陣列a相同的形狀。陣列b中的元素是複製數值b所得。我們通過拉伸來做概念上的類比,NumPy更加有效地利用原始數值而不是複製,使廣播儘可能保證記憶體和計算的效率。
通用廣播規則
NumPy在陣列運算時會自動對比兩個陣列的形狀。首先對比陣列最後一軸的大小,依次向前對比。以下兩種情況是相容可運算的:
1. 形狀相同
2. 其中一個維度為1
如果不符合運算條件,則會丟擲ValueError: frames are not aligned異常,表明兩個陣列的形狀不同不能運算。運算結果的陣列形狀每一維都是輸入陣列中的最大值。
陣列不需要維度數相同。例如,你有一個256x256x3的三維RGB(顏色)值,你想將影象中的每維值用不同的數值等比例擴充套件。你可以用一個包含3個值得一維陣列乘以影象陣列。根據廣播規則,對準影象陣列最後一軸的大小,顯示兩者之間是可運算的:
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3在兩個陣列的兩個維度比較時,任何一個為1,則另一個即可計算。可以認為,維度為1即可以被拉伸複製去對應另一個數組的這一維。
A (4d array): 8 x 1 x 6 x 1
B (3d array): 7 x 1 x 5
Result (4d array): 8 x 7 x 6 x 5更多例子如下所示:
A (2d array): 5 x 4
B (1d array): 1
Result (2d array): 5 x 4
A (2d array): 5 x 4
B (1d array): 4
Result (2d array): 5 x 4
A (3d array): 15 x 3 x 5
B (3d array): 15 x 1 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 5
Result (3d array): 15 x 3 x 5
A (3d array): 15 x 3 x 5
B (2d array): 3 x 1
Result (3d array): 15 x 3 x 5不能廣播的例子:
A (1d array): 3
B (1d array): 4 # 最後一維的元素個數不匹配
A (2d array): 2 x 1
B (3d array): 8 x 4 x 3 # 倒數第二維不匹配實際應用的例子:
>>> x = np.arange(4)
>>> xx = x.reshape(4,1)
>>> y = np.ones(5)
>>> z = np.ones((3,4))
>>> x.shape
(4,)
>>> y.shape
(5,)
>>> x + y
<type 'exceptions.ValueError'>: shape mismatch: objects cannot be broadcast to a single shape
>>> xx.shape
(4, 1)
>>> y.shape
(5,)
>>> (xx + y).shape
(4, 5)
>>> xx + y
array([[ 1., 1., 1., 1., 1.],
[ 2., 2., 2., 2., 2.],
[ 3., 3., 3., 3., 3.],
[ 4., 4., 4., 4., 4.]])
>>> x.shape
(4,)
>>> z.shape
(3, 4)
>>> (x + z).shape
(3, 4)
>>> x + z
array([[ 1., 2., 3., 4.],
[ 1., 2., 3., 4.],
[ 1., 2., 3., 4.]])廣播還提供了便利的計算兩個陣列的外積的方法。如下所示:
>>> a = np.array([0.0, 10.0, 20.0, 30.0])
>>> b = np.array([1.0, 2.0, 3.0])
>>> a[:, np.newaxis]
array[[ 0.]
[ 10.]
[ 20.]
[ 30.]]
>>> a[:, np.newaxis] + b # 將外積轉化為求和操作
array([[ 1., 2., 3.],
[ 11., 12., 13.],
[ 21., 22., 23.],
[ 31., 32., 33.]])其中newaxis方法想陣列a插入一個新的軸,使其成為一個兩維的4×1陣列。使其和shape為(3,)的陣列b相加,得到一個4×3的陣列。
索引使用技巧
NumPy提供了比Python更多的索引功能和技巧。除了使用整數和切片索引,陣列可以由整數陣列和布林型陣列構建索引。
整數陣列構建索引
>>> a = np.arange(12)**2 # 陣列a包含前12個數的平方數
>>> i = np.array( [ 1,1,3,8,5 ] ) # 陣列的索引i
>>> a[i] # 陣列a中i位置的元素,陣列的索引i中的元素為索引值
array([ 1, 1, 9, 64, 25])
>>>
>>> j = np.array( [ [ 3, 4], [ 9, 7 ] ] ) # 二維陣列的索引j
>>> a[j] # 返回結果與陣列的索引j形狀相同
array([[ 9, 16],
[81, 49]])當索引陣列a是多維時,一個單一的陣列的索引作用於a的第一維。如下所示,使用調色盤將標籤影象轉換為彩色影象。
>>> palette = np.array( [ [0,0,0], # black
... [255,0,0], # red
... [0,255,0], # green
... [0,0,255], # blue
... [255,255,255] ] ) # white
>>> image = np.array( [ [ 0, 1, 2, 0 ], # 調色盤中的每個值對應一種顏色
... [ 0, 3, 4, 0 ] ] )
>>> palette[image] # 生成一個 (2,4,3) 的三維陣列
array([[[ 0, 0, 0],
[255, 0, 0],
[ 0, 255, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 255],
[255, 255, 255],
[ 0, 0, 0]]])也可以給索引多個維度,用作索引的陣列形狀需要一樣。
>>> a = np.arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> i = np.array( [ [0,1], # 陣列a第一維的索引
... [1,2] ] )
>>> j = np.array( [ [2,1], # 陣列a第二位的索引
... [3,3] ] )
>>>
>>> a[i,j] # 陣列i、j的形狀必須相同
array([[ 2, 5],
[ 7, 11]])
>>>
>>> a[i,2]
array([[ 2, 6],
[ 6, 10]])
>>>
>>> a[:,j]
array([[[ 2, 1],
[ 3, 3]],
[[ 6, 5],
[ 7, 7]],
[[10, 9],
[11, 11]]])也可以把陣列i、j放進一個列表中,然後用這個列表做索引。
>>> l = [i,j]
>>> a[l] # 等於a[i,j]
array([[ 2, 5],
[ 7, 11]])但是,不能把陣列i、j放進另一個數組,因為新生成的陣列只會對索引陣列的第一維進行構建索引。
>>> s = np.array( [i,j] )
>>> a[s] # 錯誤,不是我們要的
Traceback (most recent call last):
File "<stdin>", line 1, in ?
IndexError: index (3) out of range (0<=index<=2) in dimension 0
>>>
>>> a[tuple(s)] # 等於 a[i,j]
array([[ 2, 5],
[ 7, 11]])利用陣列構建索引的其他常見用法還有搜尋時間依存序列的最大值。
>>>
>>> time = np.linspace(20, 145, 5) # 時標
>>> data = np.sin(np.arange(20)).reshape(5,4) # 4個時間依賴性序列
>>> time
array([ 20. , 51.25, 82.5 , 113.75, 145. ])
>>> data
array([[ 0. , 0.84147098, 0.90929743, 0.14112001],
[-0.7568025 , -0.95892427, -0.2794155 , 0.6569866 ],
[ 0.98935825, 0.41211849, -0.54402111, -0.99999021],
[-0.53657292, 0.42016704, 0.99060736, 0.65028784],
[-0.28790332, -0.96139749, -0.75098725, 0.14987721]])
>>>
>>> ind = data.argmax(axis=0) # 每一系列最大值的索引,axis為0表示縱軸方向,為1表示橫軸方向
>>> ind
array([2, 0, 3, 1])
>>>
>>> time_max = time[ ind] # 最大值對應的時間
>>>
>>> data_max = data[ind, xrange(data.shape[1])] # data.shape為(5,4),data.shape[1]為4,xrange(4)返回0-3的列表
>>>
>>> time_max
array([ 82.5 , 20. , 113.75, 51.25])
>>> data_max
array([ 0.98935825, 0.84147098, 0.99060736, 0.6569866 ])
>>>
>>> np.all(data_max == data.max(axis=0))
True也可以利用陣列作為索引去賦值:
>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[[1,3,4]] = 0
>>> a
array([0, 0, 2, 0, 0])但是,當用作索引的陣列中包含重複值時,複製操作會重複多次,保留最後的值。
>>> a = np.arange(5)
>>> a[[0,0,2]]=[1,2,3]
>>> a
array([2, 1, 3, 3, 4])如果你想使用Python的連加符號+=,需要格外當心,得出的結果未必是你想要的。
>>> a = np.arange(5)
>>> a[[0,0,2]]+=1
>>> a
array([1, 1, 3, 3, 4])雖然0在索引列表裡出現兩次,陣列a中下標為0的元素只自加了一次。因為Python需要a+=1等於a=a+1。(不太懂)
布林陣列構建索引
當使用整數陣列構建索引時,我們是提供了索引下標列表去獲取陣列中的資料。使用布林陣列構建索引則不同,目的是希望通過布林陣列索引明確指出我們需要陣列中的哪些元素,不需要哪些。
最自然地理解布林檢索的方法是使用相同形狀的布林陣列作為原始陣列。
>>> a = np.arange(12).reshape(3,4)
>>> b = a > 4
>>> b # b是和陣列a形狀相同的布林陣列
array([[False, False, False, False],
[False, True, True, True],
[ True, True, True, True]], dtype=bool)
>>> a[b] # 生成只包含True值對應元素的一維陣列
array([ 5, 6, 7, 8, 9, 10, 11])這個屬性對應賦值很有用:
>>> a[b] = 0 # 將所有大於4的值修改為0,說明a[b]是陣列a的檢視
>>> a
array([[0, 1, 2, 3],
[4, 0, 0, 0],
[0, 0, 0, 0]])舉個例子演示如何使用布林檢索生成一個Mandelbrot set(曼德勃羅集合)的影象。
import numpy as np
import matplotlib.pyplot as plt
def mandelbrot(h, w, maxit=20):
# 返回一個(h, w)大小的曼德爾布羅特圖形
# ogrid方法用於構建一個多維的格點矩陣
y,x = np.ogrid[-1.4:1.4:h*1j, -2:0.8:w*1j]
c = x+y*1j
z = c
divtime = maxit + np.zeros(z.shape, dtype=int)
for i in range(maxit):
z = z**2 + c
diverge = z*np.conj(z) > 2**2 # 分叉處
div_now = diverge & (divtime==maxit) # 當前分叉點
divtime[div_now] = i # 記錄
z[diverge] = 2 # 避免分叉太頻繁
return divtime
plt.imshow(mandelbrot(400, 400)) # imshow函式是有樣板檔案自動生成的繪圖功能
plt.show()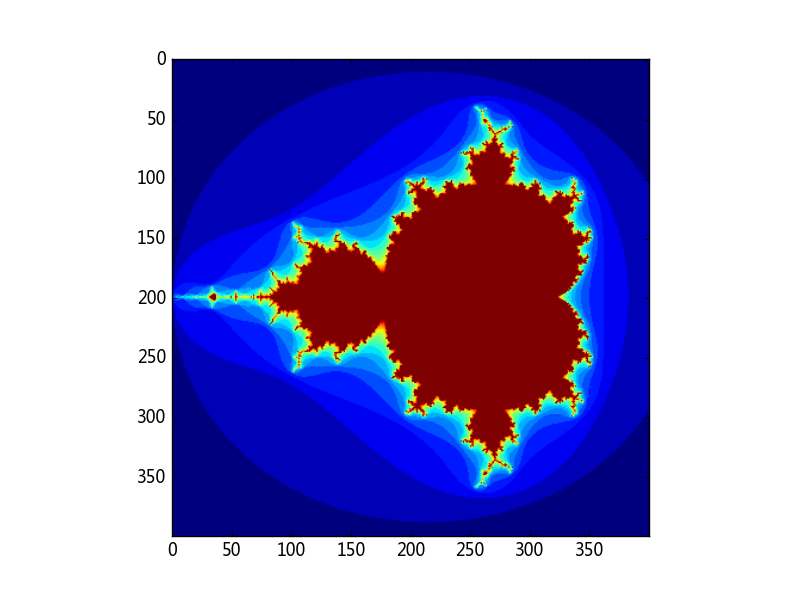
布林索引檢索的第二種方法和整數索引相似。對於陣列的每一維,使用一維的布林陣列獲取我們想要的切片。
>>> a = np.arange(12).reshape(3,4)
>>> b1 = np.array([False,True,True]) # 第一維篩選
>>> b2 = np.array([True,False,True,False]) # 第二維篩選
>>>
>>> a[b1,:] # 選擇行
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[b1] # 同上
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[:,b2] # 選擇列
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
>>>
>>> a[b1,b2] # 奇怪的地方,不解為什麼結果是這個,而不是[[4, 6],[8, 10]]
array([ 4, 10])需要注意的是一維布林陣列的長度必須和你想獲取切片的維度或軸的長度相同。在上個例子中,b1是長度為3的一維陣列(和陣列a的行數相同),b2是長度為4的一維陣列(與陣列a第二維的長度相等)。
ix_()函式
可以理解為對多個不同向量中的元素進行運算,通過ix函式修飾過的向量可以直接運算。例如,如果你想向量a,b,c中的三個值進行a+b*c的操作,如下所示:
>>> a = np.array([2,3,4,5])
>>> b = np.array([8,5,4])
>>> c = np.array([5,4,6,8,3])
>>> ax,bx,cx = np.ix_(a,b,c)
>>> ax
array([[[2]],
[[3]],
[[4]],
[[5]]])
>>> bx
array([[[8],
[5],
[4]]])
>>> cx
array([[[5, 4, 6, 8, 3]]])
>>> ax.shape, bx.shape, cx.shape
((4, 1, 1), (1, 3, 1), (1, 1, 5))
>>> result = ax+bx*cx
>>> result
array([[[42, 34, 50, 66, 26],
[27, 22, 32, 42, 17],
[22, 18, 26, 34, 14]],
[[43, 35, 51, 67, 27],
[28, 23, 33, 43, 18],
[23, 19, 27, 35, 15]],
[[44, 36, 52, 68, 28],
[29, 24, 34, 44, 19],
[24, 20, 28, 36, 16]],
[[45, 37, 53, 69, 29],
[30, 25, 35, 45, 20],
[25, 21, 29, 37, 17]]])
>>> result[3,2,4]
17
>>> a[3]+b[2]*c[4]
17也可以使用函式減少上述程式碼:
>>> def ufunc_reduce(ufct, *vectors):
... vs = np.ix_(*vectors)
... r = ufct.identity
... for v in vs:
... r = ufct(r,v)
... return r結果為:
>>> ufunc_reduce(np.add,a,b,c)
array([[[15, 14, 16, 18, 13],
[12, 11, 13, 15, 10],
[11, 10, 12, 14, 9]],
[[16, 15, 17, 19, 14],
[13, 12, 14, 16, 11],
[12, 11, 13, 15, 10]],
[[17, 16, 18, 20, 15],
[14, 13, 15, 17, 12],
[13, 12, 14, 16, 11]],
[[18, 17, 19, 21, 16],
[15, 14, 16, 18, 13],
[14, 13, 15, 17, 12]]])這個減少程式碼的版本相比較常規的ufunc.reduce的優勢在於,使用廣播避免產生一個輸出大小乘以向量的大小的引數陣列。
線性代數(Linear Algebra)
簡單的陣列操作
可以在linalg.py 檔案中檢視詳細內容。
>>> import numpy as np
>>> a = np.array([[1.0, 2.0], [3.0, 4.0]])
>>> print(a)
[[ 1. 2.]
[ 3. 4.]]
>>> a.transpose() # 陣列的轉置
array([[ 1., 3.],
[ 2., 4.]])
>>> np.linalg.inv(a) # 方陣的逆
array([[-2. , 1. ],
[ 1.5, -0.5]])
>>> u = np.eye(2) # 2x2 單位矩陣; "eye" 代表 "I"
>>> u
array([[ 1., 0.],
[ 0., 1.]])
>>> j = np.array([[0.0, -1.0], [1.0, 0.0]])
>>> np.dot (j, j) # 矩陣積
array([[-1., 0.],
[ 0., -1.]])
>>> np.trace(u) # 跡,矩陣對角線之和
2.0
>>> y = np.array([[5.], [7.]])
>>> np.linalg.solve(a, y) # 求解線性方程的值,```1*x1+2*x2=5```,```3*x1+4*x2=7```,陣列a為方程的引數
array([[-3.],
[ 4.]])
>>> np.linalg.eig(j) # 計算特徵值和方陣的右特徵向量
(array([ 0.+1.j, 0.-1.j]), array([[ 0.70710678+0.j , 0.70710678-0.j ],
[ 0.00000000-0.70710678j, 0.00000000+0.70710678j]]))技巧提示
自動變形(“Automatic” Reshaping)
想要改變陣列的維度,可以忽略某個維度值,然後這個值會被自動推匯出來。
>>> a = np.arange(30)
>>> a.shape = 2,-1,3 # -1 表示這個值需要被推匯出來
>>> a.shape
(2, 5, 3)
>>> a
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]],
[[15, 16, 17],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26],
[27, 28, 29]]])向量堆積(Vector Stacking)
如何從一個相同大小的行向量列表構建一個二維陣列?在MATLAB中相當簡單:如果x和y是兩個長度相等的向量,僅需要使m=[x;y]即可構建一個二維陣列。在NumPy中,可以使用column_stack、dstack、hstack、vstack函式實現。結果的形狀取決於使用哪種堆疊方法。
x = np.arange(0,10,2) # x=([0,2,4,6,8])
y = np.arange(5) # y=([0,1,2,3,4])
m = np.vstack([x,y]) # m=([[0,2,4,6,8],
# [0,1,2,3,4]])
xy = np.hstack([x,y]) # xy =([0,2,4,6,8,0,1,2,3,4])直方圖(Histograms)
histogram 函式作用於一個數組,返回兩個向量:陣列的直方圖和箱櫃向量。注意:matplotlib包中也有個構建直方圖的函式hist,與這裡的histogram不同。區別在於pylab.hist函式自動繪製直方圖,而numpy.histogram僅生成資料。
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> # 構建一個10000的向量,正態分佈方差 0.5^2 ,平均值為 2
>>> mu, sigma = 2, 0.5
>>> v = np.random.normal(mu,sigma,10000)
>>> # 繪製一個有50個箱櫃的正態分佈圖
>>> plt.hist(v, bins=50, normed=1)
>>> plt.show()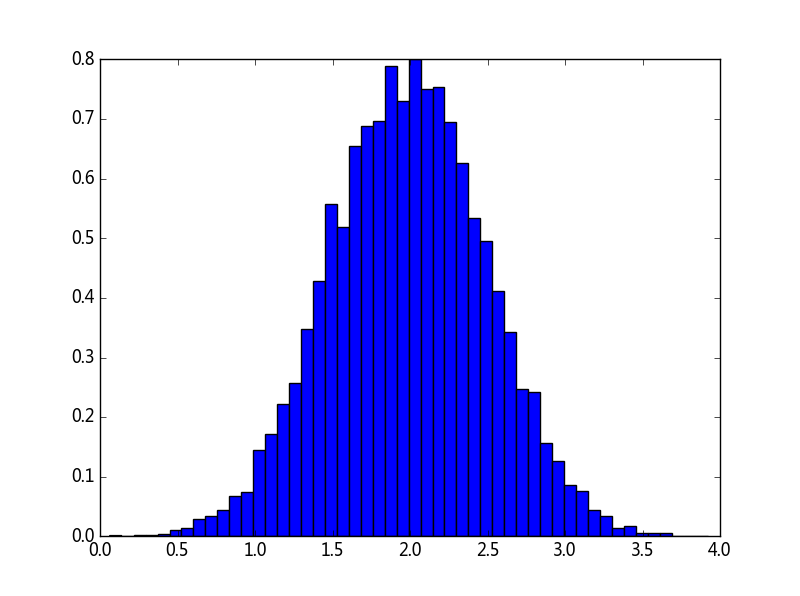
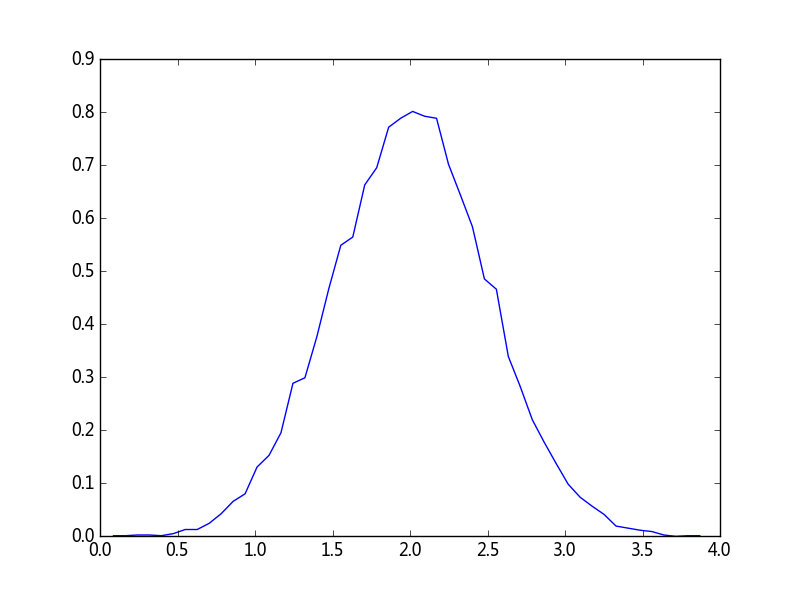
>>> # 計算陣列的直方圖,並繪製出來
>>> (n, bins) = np.histogram(v, bins=50, normed=True)
>>> plt.plot(.5*(bins[1:]+bins[:-1]), n)
>>> plt.show()