
【深度學習入門】——親手實現影象卷積操作
深度學習中有一個很重要的概念就是卷積神經網路 CNN,卷積神經網路中又有卷積層、池化層的概念。尤其是卷積層,理解難度比較大,雖然書中或者是視訊中都有詳細介紹過它的基礎概念,但對於求知慾望很強烈的我,我總心裡癢癢的,總想親手實現,看看效果,怕的就是自己會眼高手低,做技術人最可怕的就是眼高手低。所以,我打算用 python 來親自驗證一遍。
什麼是卷積?
卷積(convolution)是數學知識,概率論和訊號與系統中都有涉及。卷積的公式如下:
連續訊號:
離散訊號
卷積會由兩個原函式產生一個新的函式,兩個函式之間的這種操作就稱著卷積,卷積的數學意義與物理意義這裡不過多講述,因為展開來講的話可以另外寫一篇博文了,不熟悉的同學大家點選這裡,我們把目標放在影象的卷積操作之上。
需要說明的是,影象處理中的卷積對應的是離散卷積公式。
影象的卷積操作
我們假設有一張圖片,我們稱之為輸入圖片,我們對原圖片進行某種卷積操作之後會得到另外一張圖片,我們稱這張圖片為輸出圖片。

一般的,我們通過對圖片進行卷積操作,可以對圖片進行某種效果的增強或者是減弱。比如說圖片的模糊、銳化、浮雕效果等等。

當然,也可以發現圖片中某些特徵,如查詢物體的邊緣資訊。而深度學習做的最重要的工作之一就是發現數據的特徵,這也是卷積神經網路誕生的原因。
那麼對於一張圖片而言,卷積操作是如何進行的呢?
什麼是卷積核?
一張圖片進行卷積後的顯示效果,絕大部分取決於它的卷積核(kernel)。那麼,什麼是卷積核呢?
其實卷積核並沒有什麼神祕的,它是一個 2 維陣列。它的行數和列數相同並且數值為奇數。
上面就是一個 3x3 的卷積核,它的核大小(kernel size) 為 3。它裡面的元素值代表不同的權值。
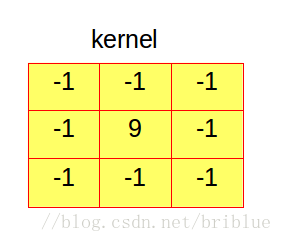
一般而言,卷積核裡面所有元素之和等於 1,當然你也可以不讓它等於 1,大於 1時生成的圖片亮度會增加,小於 0 時生成的圖片亮度會降低。
那麼,卷積核是如何作用在一張圖之上的呢?
一句話描述就是:針對輸入圖片中單個畫素,將它的值由周圍鄰近的畫素值加權平均。而這種加權平均的操作產生的新的畫素值按照次序可以產生一張新的輸出圖片。
需要注意的是,在深度學習當中,只需要逐元素相乘再相加就可以了,不需要對結果取均值,我在本文采取求平均數,只為了示例的演示效果
再來說說何為加權平均?
[1,2,3,4,5]
有 5 個數,加權平均就是
代表權值,如果所有的 為 1,則上面式子的等於 3。 是可以取不同的值的。
上面說過,卷積核裡面的數值代表權重,那麼它又是針對畫素如何做加權平均的呢?
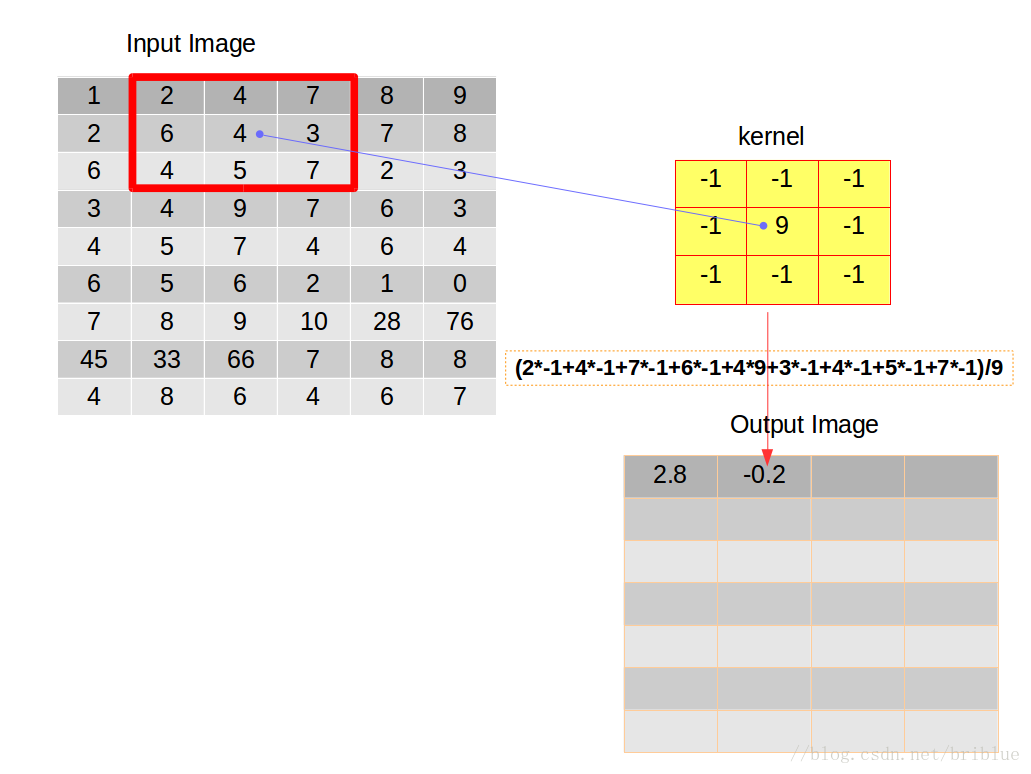
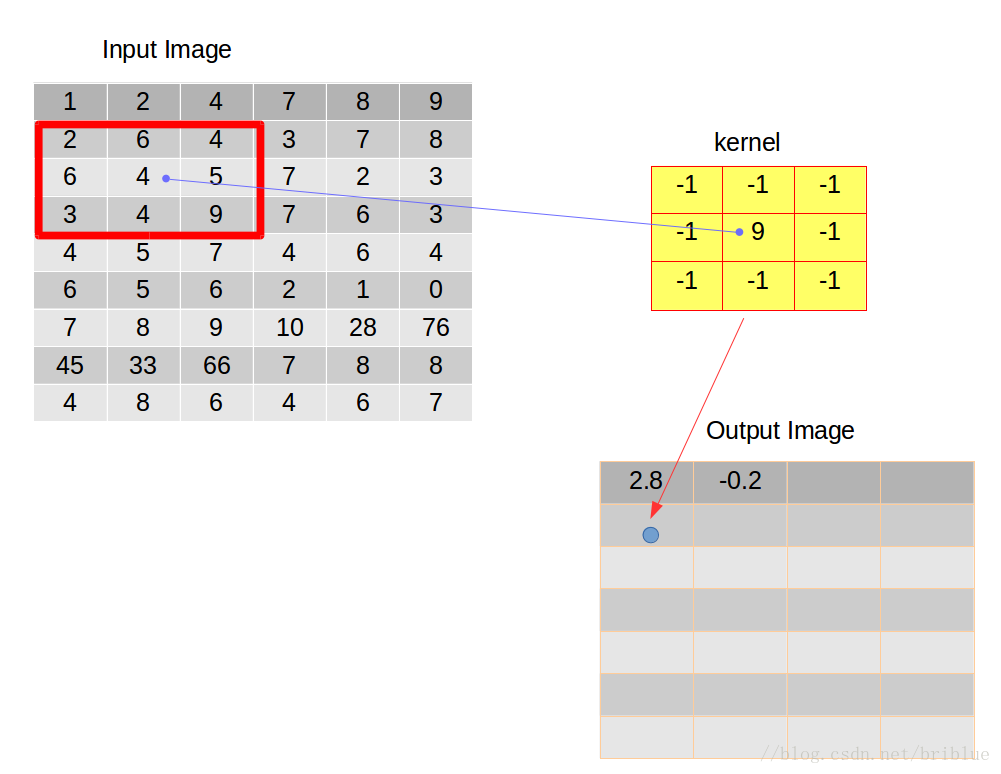
假設有這麼一張圖片,如下圖左,卷積核如下圖右。
卷積操作要求,開始的時候將它們在左上角對齊。

然後,逐元素相乘再相加,累加得到的數值再除以元素的數量,得到平均值放在輸出影象矩陣的第一個元素位置上。
在第一次操作之後,我們需要重複剛才這種行為,於是我們選擇將卷積核向右滑動 1 個距離,當然我們也可以選擇向右滑動更多的距離,而這種距離也有個專業的名詞叫做跨度(strides),也有人叫它步長。
如上圖,我們將卷積後的結果放在輸出的影象矩陣的第二個位置。
卷積核向右滑動是有條件的,當卷積核的右邊緣超過輸入影象的右邊緣時,就需要考慮向下滑動了。
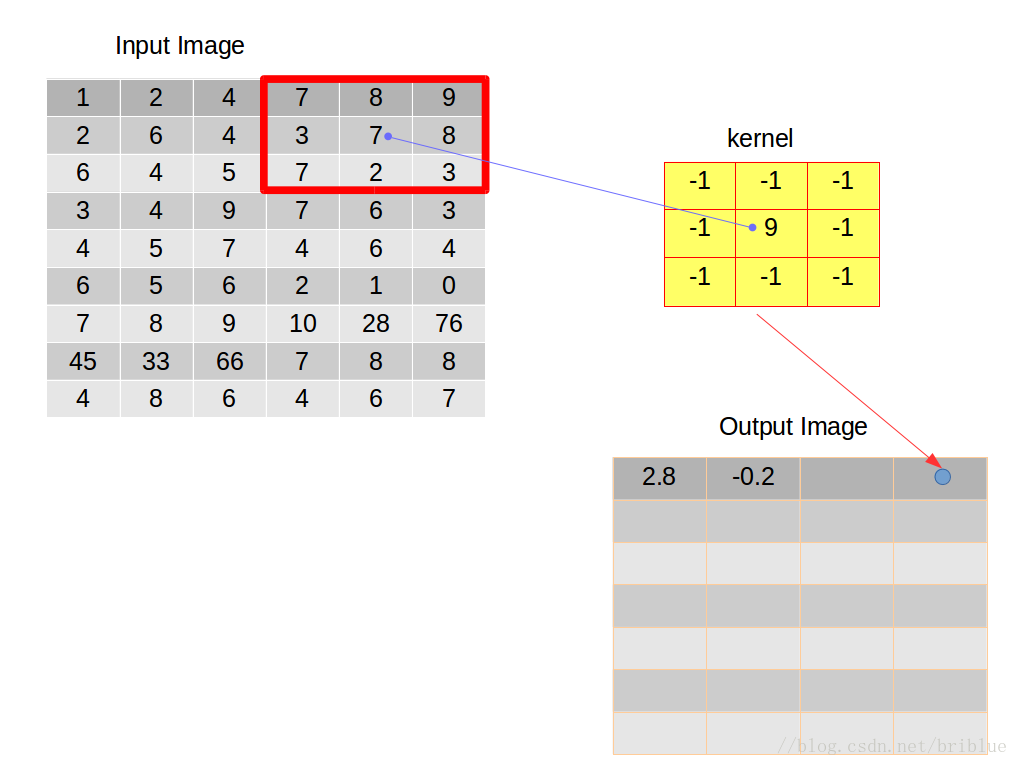
之後,卷積核不能再向右邊滑動時,就需要重新與輸入影象左對齊,並且在前面的基礎上向下滑動一個跨度,跨度由我們開發人員自主決定,本文實驗的跨度都取值為 1,左對齊之後重複上面敘述的卷積行為向右滑動,然後向下滑動。不停迴圈。
整個卷積行為終止的條件是卷積核需要向下滑動的時候,但它的下邊緣已經超出了輸入影象的下邊緣。
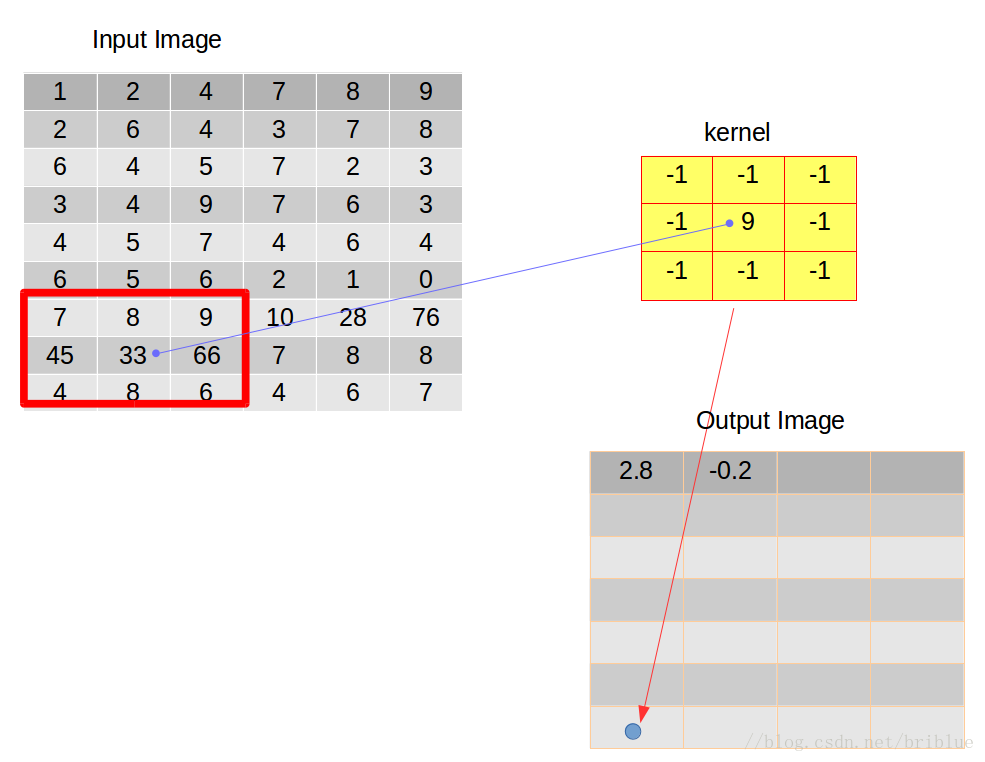
此時,我們經過操作得到的輸出影象就是我們這次卷積後的結果。
卷積後的影象尺寸
細心的同學可能已經發現了,卷積過程中,輸入圖片和輸出圖片的尺寸貌似是不一樣的。
一般情況,輸出圖片的尺寸要比輸入圖片的尺寸小,並且,它們之間的關係其實很容易用公式推算出來。
我們假定輸入圖片尺寸為 m x n,輸出的圖片尺寸為 l x c,跨度用 stride 表示,卷積核大小用 k 表示,則有下面公式。
大家仔細琢磨一下,相信很快就能理解明白。
剛剛說了,一般而言,輸出圖片的尺寸要比輸入圖片的尺寸小,那麼有同學可能會問,如果我想輸出圖片的尺寸跟輸入圖片不發生變化可以嗎?
答案是肯定的,這涉及了對輸入圖片的 padding 操作。
padding
如果要輸入影象核輸出影象尺寸保持一致,經常的做法是在卷積之前認為擴大輸入影象的尺寸。也就是在輸入圖片外圍補 0。
但是怎麼個補法呢?比如左邊補幾個 0? 上面補幾個 0 ?
以左右方向為例,我們根據上面的公式可以推斷出總共需要補充的 0 的個數。
我們假設跨度為 1,則 count 的值就是 k - 1 。
博文的示例中,輸入圖片尺寸是 9 x 6,輸出圖片尺寸是 7 x 4。核大小是 3.
於是在橫向,count 是 k - 1,也就是 2。我們可以讓左邊補 1 個 0,右邊補 1 個 0。
但如果 count 結果為奇數呢,比如 5 ,那麼我們可以讓一邊多一點,另一邊少補一點 ,比如左邊數值等於 ,ceil 表示向上取整。右邊數值等於 ,於是左邊等於 3,右邊等於 2。 這代表著在輸入圖片矩陣當中每一行左邊擴充 3 個 0,右邊擴充 2 個 0。
同理,可以求得圖片在豎直方向應該補充 0 的數量。
經過 padding 之後再進行卷積,輸出圖片的尺寸就能夠和輸入圖片保持一致。
這裡有一張很直觀的動圖。圖片出處
編碼實踐
經過上面的介紹,我們已經具備了影象卷積的基本理論,現在讓我們開始通過程式碼論證吧。
示例程式碼採用 python 語言,當然你不熟悉 python 語言的話,你可以換成其他語言其實也是可以的,比如 Matlab。
我們先引進 numpy 和 matplotlib.pyplot。
import numpy as np
import matplotlib.pyplot as plt
引進 numpy 的目的是因為它提供了極為便利的陣列和矩陣操作,而 matplotlib.pyplot 可以輕鬆實現圖示繪製,這在機器學習或者是深度學習過程當中是很重要的,因為資料的視覺化有助於我們理解演算法和除錯演算法。
我們然後需要一張測試圖片。
srcImg = plt.imread('../res/images/lena.jpg')

這是一張很出名的照片,在計算機視覺當中大家都喜歡用它進行測試,模特的名字就叫做 lena,大家有興趣可以搜尋它的相關資訊。
輸入圖片的尺寸是 512 x 512 x 3,512 就它的寬高,3 代表了 RGB 3 個顏色通道。
然後,我們構建一個 3 x 3 的卷積核。
test_kernel = np.array([[-1,-1,-1],
[-1,9,-1],
[-1,-1,-1]])
在示例程式碼中,我們卷積操作時,跨度為 1。根據前面介紹的公式,我們很容易根據輸入圖片矩陣去構建輸出圖片的影象矩陣。
def generate_dst(srcImg):
m = srcImg.shape[0]
n = srcImg.shape[1]
n_channel = srcImg.shape[2]
dstImg = np.zeros((m-test_kernel.shape[0]+1,n-test_kernel.shape[0]+1,n_channel ))
return dstImg
注意的是,構建輸出圖片影象矩陣的時候,它的通道和輸入圖片是一致的。
有了輸入圖片,構建了輸出圖片的資料結構,我們就可以開始編寫卷積操作了。
def conv_2d(src,kernel,k_size):
dst = generate_dst(src)
print dst.shape
conv(src,dst,kernel,k_size)
return dst
src 代表輸入圖片,kernel 自然就是卷積核,k_size 就是卷積核的大小,這裡為 3。
上面的程式碼構建了輸出圖片的資料結構,並在內部呼叫了conv()方法。
def conv(src,dst,kernel,k_size):
for i in range(dst.shape[0]):
for j in range(dst.shape[1]):
for k in range(dst.shape[2]):
value = _con_each(src[i:i+k_size,j:j+k_size,k],kernel)
dst[i,j,k] = value
前面的理論知識,介紹過,卷積操作需要滑動卷積核重複進行。
最裡面的巢狀表示,對每一個顏色通道都需要進行卷積操作。你可以想象一下輸入圖片分成了 3 份,每一份尺寸同原圖片一樣,他們的疊加形成了原圖。
不然看出,核心方法是 _con_each()
def _con_each(src_block,kernel):
pixel_count = kernel.size;
pixel_sum = 0;
_src = src_block.flatten();
_kernel = kernel.flatten();
for i in range(pixel_count):
pixel_sum += _src[i]*_kernel[i];
return pixel_sum / pixel_count;
注意它的輸入引數,src_block 代表的是從輸入圖片上擷取下來的畫素塊。它的尺寸同卷積核一樣。那它是怎麼擷取下來的呢?請看下面的程式碼
src[i:i+k_size,j:j+k_size,k]
src 是 numpy 中的 ndarray 物件,先前說了它極其方便對陣列和矩陣進行操作,這行程式碼表示,從原陣列中擷取起始座標為 (i,j),寬高都為 k_size 的資料塊。
我們再看 _con_each()方法,它進行了逐元素相乘,累計相加的操作,最終的數值還要求平均。
但我們知道,RGB 模式中,數值的取值範圍是 0 ~ 255,如果超出這個範圍就應該截斷,所以我們需要優化下程式。
def _con_each(src,kernel):
pixel_count = kernel.size;
pixel_sum = 0;
_src = src.flatten();
_kernel = kernel.flatten();
for i in range(pixel_count):
pixel_sum += _src[i]*_kernel[i];
value = pixel_sum / pixel_count
value = value if value >0 else 0
value = value if value < 255 else 255
return value;
小於 0 時,畫素值取 0,大於 255 時取 255,其它情況保持現值。
需要注意的是,在 python 中三目運算和其它程式語言有點不一樣。
比如我在 Java 中這樣寫:
a = a > 0 ? 1 : -1
在 python 中需要這樣寫。
a = 1 if a > 0 else -1
現在,我們卷積操作的函式也完成了,我們可以測試一下。
def test_conv(src,kernel,k_size):
plt.figure()
#121 1 代表 1行,2 代表 2 列,最後的 1 代表 圖片顯示在第一行第一列
plt.subplot(121)
plt.imshow(src)
dst = conv_2d(src,kernel,k_size)
#121 1 代表 1行,2 代表 2 列,最後的 2 代表 圖片顯示在第一行第發給列
plt.subplot(122)
plt.imshow(dst)
plt.show()
在這個測試函式中,將輸入影象和輸出影象在一個圖示中並排顯示。然後我們呼叫這個函式。
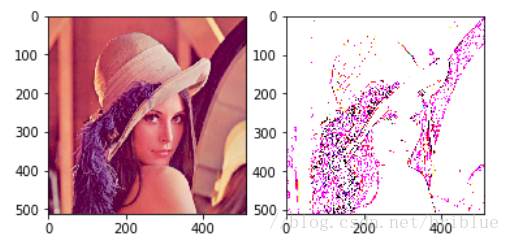
test_conv(srcImg,test_kernel,3)
最終結果如下圖。
卷積效果取決於卷積核,它的大小不同,裡面的數值不同,卷積後的效果就會不同的,大家可以自行設計不同的卷積核進行試驗。
CNN 中的卷積操作
在 CNN 中,每一個卷積層包含不止一個卷積核,並且卷積後的處理跟上面的影象處理過程也有一點點不一樣。
我們在上面的博文中,卷積得來的數值進行了平均化。
而在 CNN 中,我們不是將它平均化而是送到一個啟用函式裡面,得到一個新的輸出,啟用函式通常有 Sigmoid 和 tanh 函式等,我們以 Sigmoid 為例。
它的函式圖形如下:
它有個很好的特性就是,輸出值在 0 ~ 1 之間。
def sigmoid(x):
return 1 / (1 + np.exp(-x))
根據公式,可以很簡單寫出它的實現函式。
所以,我們可以改寫
def _con_each(src,kernel):
pixel_count = kernel.size;
pixel_sum = 0;
_src = src.flatten();
_kernel = kernel.flatten();
for i in range(pixel_count):
pixel_sum += _src[i]*_kernel[i];
value = pixel_sum / pixel_count
value = value if value >0 else 0
value = value if value < 255 else 255
value = sigmoid(value)
return value;
生成的圖片如下:
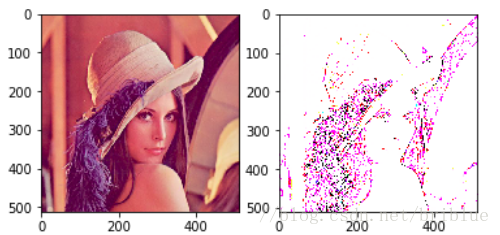
到這裡,我們完全掌握瞭如何對一張圖片進行卷積操作。
可能有同學會問,如何確定卷積核的大小及它們的值,在傳統的圖形處理中,卷積核是通過大量開發人員的經驗調試出來的,並且它本身具有一定的數學理論支撐,但是在深度學習中,除了核的尺寸是認為設計的,卷積核裡面的數值是深度學習自己訓練出來的,開發人員在事先是不能確定它的值的,這是它的魅力與神奇之處。