
Kubernetes主機和容器的監控方案
Docker 部署規模逐步變大後,視覺化監控容器環境的效能和健康狀態將會變得越來越重要。
在本章中,我們將討論幾個目前比較常用的容器監控工具和方案,為大家構建自己的監控系統提供參考。

首先我們會討論 Docker 自帶的幾個監控子命令:ps, top 和 stats。然後是幾個功能更強的開源監控工具 sysdig, Weave Scope, cAdvisor 和 Prometheus。最後我們會對這些不同的工具和方案做一個比較。
Docker 自帶的監控子命令
ps
docker container ps 是我們早已熟悉的命令了,方便我們檢視當前執行的容器。

 前面已經有大量示例,這裡就不贅述了。值得注意的是,新版的 Docker 提供了一個新命令
前面已經有大量示例,這裡就不贅述了。值得注意的是,新版的 Docker 提供了一個新命令 docker container ls
docker container ps 完全一樣。不過 ls 含義可能比 ps 更準確,所以更推薦使用。

top
如果想知道某個容器中運行了哪些程序,可以執行 docker container top [container] 命令。

上面顯示了 sysdig 這個容器中的程序。命令後面還可以跟上 Linux 作業系統 ps 命令的引數顯示特定的資訊,比如 -au。

stats
docker container stats 用於顯示每個容器各種資源的使用情況。

預設會顯示一個實時變化的列表,展示每個容器的 CPU 使用率,記憶體使用量和可用量。
注意:容器啟動時如果沒有特別指定記憶體 limit,stats 命令會顯示 host 的記憶體總量,但這並不意味著每個 container 都能使用到這麼多的記憶體。
除此之外 docker container stats 命令還會顯示容器網路和磁碟的 IO 資料。
預設的輸出有個缺點,顯示的是容器 ID 而非名字。我們可以在 stats 命令後面指定容器的名稱只顯示某些容器的資料。比如 docker container stats sysdig weave。

ps,top, stats 這幾個命令是 docker 自帶的,優點是執行方便,很適合想快速瞭解容器執行狀態的場景。其缺點是輸出的資料有限,而且都是實時資料,無法反應歷史變化和趨勢。接下來要介紹的幾個監控工具會提供更豐富的功能。
大家晚上好,今天很高興能在這裡和大家一起交流和分享在工作中的一些經驗和總結。都知道監控在運維體系乃至產品的整個生命中期都是重要的一個環節,針對不同的應用場景,監控方案也會有很大的不同。本次就和大家分享一下我在開發我們公司新產品ufleet的監控模組時的一些技術總結,如果有錯誤的地方,歡迎大家指出。主要內容有:
1.資料的採集方式
2.監控原理
3.容器的監控方案
4.kubernetes上的主機和容器的監控
5.監控工具的對比
一個完整的監控體系包括:採集資料、分析儲存資料、展示資料、告警以及自動化處理、監控工具自身的安全機制,接下來會對資料的採集和監控原理深入講解,其他部分會在一些架構中穿插講解。
一 、資料的採集方式
1.命令列方式。比如在linux系統上使用top,vmstat,netstat寫一些shell指令碼進行資料的採集,再把資料儲存在文字檔案中進行處理。
2.嵌入式。通過在程序中執行agent的方式獲取應用的狀態。如目前的APM產品都是通過將監控工具嵌入到應用內部進行資料採集。
3.主動輸出。提前在應用中埋點,應用主動上報。比如一些應用系統的業務狀態,可以通過在日誌中主動輸出狀態用於採集。
4.旁路式。通過外部獲取的方式採集資料。比如對網站url的探測,模擬業務的報文 ,對伺服器的ping,流量的監控。可以通過在交換機上將流量進行埠複製,將源始流量複製到另一個埠後再進行處理,這樣這業務系統是完全沒有侵入。
5.遠端接入。通過對應用程序介面呼叫獲取應用的狀態。比如使用JMX的方式連線到java程序中,對程序的狀態進行採集。
6.入侵式。不同於嵌入式,入侵式的agent是獨立執行的程序,而不是執行在程序中。這個目前監控工具比較常用的方式,比如zabbix,在主機上執行一個程序進行相關資料的採集。
二、監控原理
具體監控指標總結如下:
- 首先是容器本身資源使用情況:cpu,記憶體,網路,磁碟
- 物理機的資源使用情況:cpu,記憶體,網路,磁碟
- 物理機上容器映象情況,名字,大小,版本。
1.主機的監控
(1)Cpu資料
使用top命令可以檢視當前cpu使用情況,原始檔來自/proc/stat
取樣兩個足夠短的時間間隔的Cpu快照,分別記作t1,t2,其中t1、t2的結構均為:
(user、nice、system、idle、iowait、irq、softirq、stealstolen、guest)的9元組;
a) 計算總的Cpu時間片totalCpuTime
- 把第一次的所有cpu使用情況求和,得到s1;
- 把第二次的所有cpu使用情況求和,得到s2;
- s2 – s1得到這個時間間隔內的所有時間片,即totalCpuTime = j2 – j1 ;
b) 計算空閒時間idle
- idle對應第四列的資料,用第二次的第四列- 第一次的第四列即可
- idle=第二次的第四列- 第一次的第四列
c) 計算cpu使用率
- pcpu =100* (total-idle)/total
(2)linux記憶體監控
使用free命令可以檢視當前記憶體使用情況。
其資料來源是來自/proc/meminfo檔案
常用的計算公式:
real_used = used_mem – buffer – cache
real_free = free_mem + buffer + cache
total_mem = used_mem + free_mem
(3) Network資料
/proc/net/dev儲存著有關網路的資料
如計算一段時間sec秒內的網路平均流量:
infirst=$(awk ‘/’$eth’/{print $1 }’ /proc/net/dev |sed ‘s/’$eth’://’)
outfirst=$(awk ‘/’$eth’/{print $10 }’ /proc/net/dev)
sumfirst=$(($infirst+$outfirst))
sleep $sec”s”
inend=$(awk ‘/’$eth’/{print $1 }’ /proc/net/dev |sed ‘s/’$eth’://’)
outend=$(awk ‘/’$eth’/{print $10 }’ /proc/net/dev)
sumend=$(($inend+$outend))
sum=$(($sumend-$sumfirst))
aver=$(($sum/$sec))
2.docker的監控
docker自身提供了一種記憶體監控的方式,即可以通過docker stats對容器記憶體進行監控。
該方式實際是通過對cgroup中相關資料進行取值從而計算得到。其資料來源是/sys/fs/cgroup
docker client相關程式碼入口可參考:/docker/docker/api/client/stats.go#141
docker daemon相關程式碼入口可參考:/docker/docker/daemon/daemon.go#1474
(1)Cpu資料
docker daemon會記錄這次讀取/sys/fs/cgroup/cpuacct/docker/ [containerId]/cpuacct.usage的值,作為cpu_total_usage;並記錄了上一次讀取的該值為 pre_cpu_total_usage;讀取/proc/stat中cpu field value,並進行累加,得到system_usage;並 記錄上一次的值為pre_system_usage;讀取/sys/fs/cgroup/cpuacct/docker/ [containerId]/cpuacct.usage_percpu中的記錄,組成陣列per_cpu_usage_array;
docker stats計算Cpu Percent的演算法:
cpu_delta = cpu_total_usage – pre_cpu_total_usage;
system_delta = system_usage – pre_system_usage;
CPU % = ((cpu_delta / system_delta) * length(per_cpu_usage_array) ) * 100.0
(2) Memory資料
讀取/sys/fs/cgroup/memory/docker/[containerId]/memory.usage_in_bytes的值,作為 mem_usage;如果容器限制了記憶體,則讀取/sys/fs/cgroup/memory/docker/ [id]/memory.limit_in_bytes作為mem_limit,否則mem_limit = machine_mem;docker stats計算 Memory資料的演算法:
MEM USAGE = mem_usage
MEM LIMIT = mem_limit
MEM % = (mem_usage / mem_limit) * 100.0
(3)Network Stats資料:
獲取屬於該容器network namespace veth pairs在主機中對應的veth*虛擬網絡卡EthInterface 陣列,然後迴圈陣列中每個網絡卡裝置,讀取/sys/class/net/[device]/statistics/rx_bytes得到rx_bytes, 讀取/sys/class/net/[device]/statistics/tx_bytes得到對應的tx_bytes。
將所有這些虛擬網絡卡對應的rx_bytes累加得到該容器的rx_bytes。
將所有這些虛擬網絡卡對應的tx_bytes累加得到該容器的tx_bytes。
docker stats計算Network IO資料的演算法:
NET I = rx_bytes
NET O = tx_bytes
三、容器的監控方案
1.單臺主機容器監控:
(1)docker stats
單臺主機上容器的監控實現最簡單的方法就是使用命令Docker stats,就可以顯示所有容器的資源使用情況.
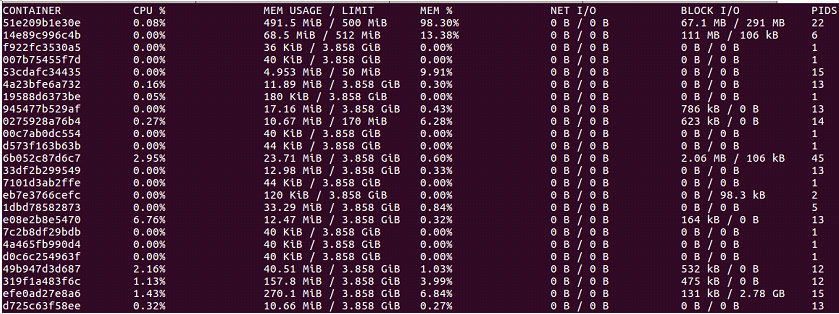
這樣就可以檢視每個容器的CPU利用率、記憶體的使用量以及可用記憶體總量。請注意,如果你沒有限制容器記憶體,那麼該命令將顯示您的主機的記憶體總量。但它並不意味著你的每個容器都能訪問那麼多的記憶體。另外,還可以看到容器通過網路傳送和接收的資料總量
雖然可以很直觀地看到每個容器的資源使用情況,但是顯示的只是一個當前值,並不能看到變化趨勢。
(2)Google的 cAdvisor 是另一個知名的開源容器監控工具:

只需在宿主機上部署cAdvisor容器,使用者就可通過Web介面或REST服務訪問當前節點和容器的效能資料(CPU、記憶體、網路、磁碟、檔案系統等等),非常詳細。
它的執行方式也有多種:
a.直接下載命令執行
格式: nohup /root/cadvisor -port=10000 &>>/var/log/kubernetes/cadvisor.log &
訪問: http://ip:10000/
b.以容器方式執行
docker pull index.alauda.cn/googlelib/cadvisor執行:
docker run -d --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw –volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --name=cadvisor
index.alauda.cn/googlelib/cadvisor:latestc.kubelet選項:
在啟動kubelete時候,啟動cadvisor
cAdvisor當前都是隻支援http介面方式,被監控的容器應用必須提供http介面,所以能力較弱。在Kubernetes的新版本中已經集成了cAdvisor,所以在Kubernetes架構下,不需要單獨再去安裝cAdvisor,可以直接使用節點的IP加預設埠4194就可以直接訪問cAdvisor的監控面板。UI介面如下:

因為cAdvisor預設是將資料快取在記憶體中,在顯示介面上只能顯示1分鐘左右的趨勢,所以歷史的資料還是不能看到,但它也提供不同的持久化儲存後端,比如influxdb等,同時也可以根據業務的需求,只利用cAdvisor提供的api介面,定時去獲取資料儲存到資料庫中,然後定製自己的介面。
如需要通過cAdvisor檢視某臺主機上某個容器的效能資料只需要呼叫: http://<host_ip>:4194/v1.3/subcontainers/docker/<container_id>
cAdvisor的api介面返回的資料結構如下:
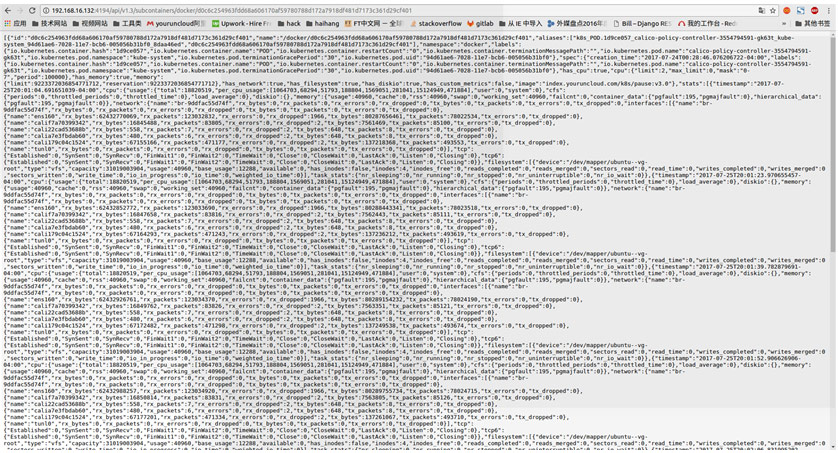
可以根據這些資料分別計算出 CPU、記憶體、網路等資源的使用或者佔用情況。
四、kubernetes上的監控
1.容器的監控
在Kubernetes監控生態中,一般是如下的搭配使用:

(1)Cadvisor+InfluxDB+Grafana:
Cadvisor:將資料,寫入InfluxDB
InfluxDB :時序資料庫,提供資料的儲存,儲存在指定的目錄下
Grafana :提供了WEB控制檯,自定義查詢指標,從InfluxDB查詢資料,並展示
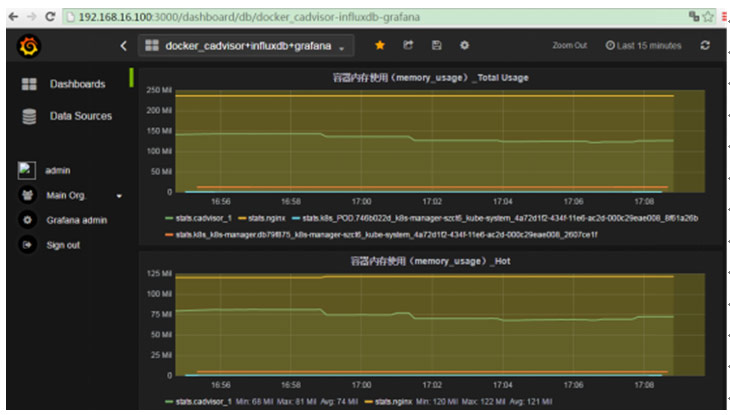
cAdivsor雖然能採集到監控資料,也有很好的介面展示,但是並不能顯示跨主機的監控資料,當主機多的情況,需要有一種集中式的管理方法將資料進行彙總展示,最經典的方案就是 cAdvisor+ Influxdb+grafana,可以在每臺主機上執行一個cAdvisor容器負責資料採集,再將採集後的資料都存到時序型資料庫influxdb中,再通過圖形展示工具grafana定製展示面板。
在上面的安裝步驟中,先是啟動influxdb容器,然後進行到容器內部配置一個數據庫給cadvisor專用,然後再啟動cadvisor容器,容器啟動的時候指定把資料儲存到influxdb中,最後啟動grafana容器,在展示頁面裡配置grafana的資料來源為influxdb,再定製要展示的資料,一個簡單的跨多主機的監控系統就構建成功了。
(2)Kubernetes——Heapster+InfluxDB+Grafana:
Heapster:在k8s叢集中獲取metrics和事件資料,寫入InfluxDB,heapster收集的資料比cadvisor多,卻全,而且儲存在influxdb的也少。
InfluxDB:時序資料庫,提供資料的儲存,儲存在指定的目錄下。
Grafana:提供了WEB控制檯,自定義查詢指標,從InfluxDB查詢資料,並展示。
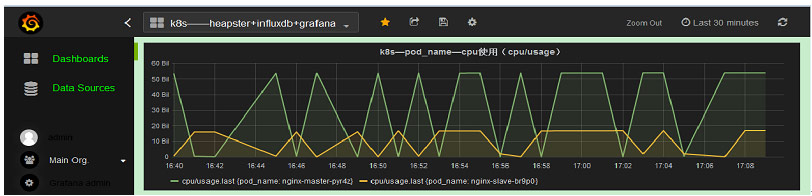
Heapster是一個收集者,將每個Node上的cAdvisor的資料進行彙總,然後導到InfluxDB。Heapster的前提是使用cAdvisor採集每個node上主機和容器資源的使用情況,再將所有node上的資料進行聚合,這樣不僅可以看到Kubernetes叢集的資源情況,還可以分別檢視每個node/namespace及每個node/namespace下pod的資源情況。這樣就可以從cluster,node,pod的各個層面提供詳細的資源使用情況。
2、kubernetes中主機監控方案:
prometheus
prometheus是個集 db、graph、statistic、alert 於一體的監控工具,安裝也非常簡單,下載包後做些引數的配置,比如監控的物件就可以運行了,預設通過9090埠訪問。
(1) 部署node-exporter容器
node-exporter 要在叢集的每臺主機上部署,使用主機網路,埠是9100 如果有多個K8S叢集,則要在多個叢集上部署,部署node-exporter的命令如下:
# kubectl create -f node-exporter-deamonset.yaml
獲取metrics資料http://ip:9100/metrics
返回的資料結構不是json格式,如果要使用該介面返回的資料,可以通過正則匹配,匹配出需要的資料,然後在儲存到資料庫中。
(2) 部署Prometheus和Grafana
Prometheus 通過配置檔案發現新的節點,檔案路徑是/sd/*.json,可以通過修改已有的配置檔案,新增新的節點納入監控,命令如下:
# kubectl create -f prometheus-file-sd.yaml
(3)檢視Prometheus監控的節點
Prometheus 的訪問地址是:http://192.168.xxx.xxx:31330
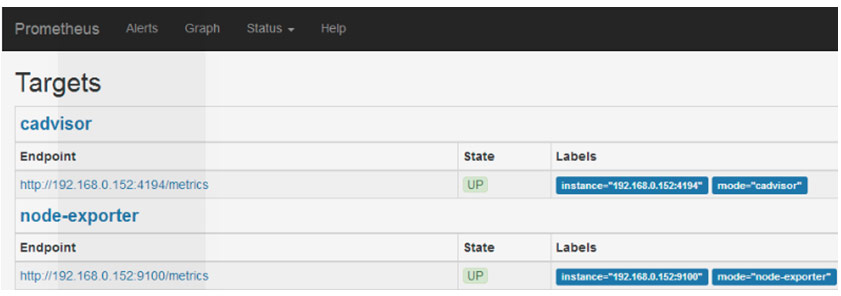
通過網頁檢視監控的節點Status –> Targets
(4)另外可以配置Grafana展示Prometheus輸出的監控資料,配置儀表盤等。
Grafana 訪問地址是:http://192.168.xxx.xxx:31331
賬號:admin 密碼:admin
注:系統預置了幾個常用監控儀表盤配置,更多的配置可以到官方網站下載
五、監控工具的對比
以上從幾個典型的架構上介紹了一些監控,但都不是最優實踐。需要根據生產環境的特點結合每個監控產品的優勢來達到監控的目的。比如Grafana的圖表展示能力強,但是沒有告警的功能,那麼可以結合Prometheus在資料處理能力改善資料分析的展示。下面列了一些監控產品,但並不是嚴格按表格進行分類,比如Prometheus和Zabbix都有采集,展示,告警的功能。都可以瞭解一下,各取所長。
| 採集 | cAdvisor, Heapster, collectd, Statsd, Tcollector, Scout |
| 儲存 | InfluxDb, OpenTSDB, Elasticsearch |
| 展示 | Graphite, Grafana, facette, Cacti, Ganglia, DataDog |
| 告警 | Nagios, prometheus, Icinga, Zabbix |
今天分享的內容主要就是這些,有不懂的地方或者有講錯的地方歡迎大家提出,謝謝大家。