
nginx從入門到精通And原理
本文是多篇文章整理在一起,因為本人比較懶。。。so整理了下各位大牛的文章便於我自己以及後來者一步到位的學習。
文章中的一些內容轉載至:
http://geek.csdn.net/news/detail/22208
http://www.open-open.com/lib/view/open1417488526633.html
首先介紹下nginx的基本概念:
Nginx 最常的用途是提供反向代理服務,那麼什麼反向代理呢?正向代理相信很多大陸同胞都在這片神奇的土地上用過了,正向代理:代理伺服器作為客戶端這邊的中介接受請求,隱藏掉真實的客戶,向伺服器獲取資源。如果代理伺服器在長城外的話還能順便幫助我們實現翻越長城的目的。而反向代理顧名思義就是反過來代理伺服器作為伺服器的中介,隱藏掉真實提供服務的伺服器,這麼做當然不是為了實現翻越長城,而是為了實現安全和負載均衡等一系列的功能。所謂安全指客戶端的請求不會直接落到內網的伺服器上而是通過代理做了
一層轉發,在這一層就可以實現安全過濾,流控,防 DDOS 等一系列策略。而負載均衡指我們可以水平擴充套件後端真正提供服務的伺服器數量,代理按規則轉發請求到各個伺服器,使得各個伺服器的負載接近均衡。
以前不是很明白,研究一項技術的時候總想搞懂他是幹什麼的,然後再瞭解他的一些原理和特性等等一些東西之後才會開始做demo去入門這項技術,導致研究技術的進展會慢一些,架構師說老油條不會這麼做,他們都會先做一個小demo,會用了之後再慢慢去研究,需要什麼就去研究什麼。和我思想綜合下,先會用,然後再去研究它的原理和特性。
come GO
Nginx的核心特點
(1)跨平臺:Nginx 可以在大多數 Unix like OS編譯執行,而且也有Windows的移植版本;
(2)配置異常簡單:非常容易上手。配置風格跟程式開發一樣,神一般的配置;
(3)非阻塞、高併發連線:資料複製時,磁碟I/O的第一階段是非阻塞的。官方測試能夠支撐5萬
PS:對於一個Web伺服器來說,首先看一個請求的基本過程:建立連線—接收資料—傳送資料,在系統底層看來 :上述過程(建立連線—接收資料—傳送資料)在系統底層就是讀寫事件。
①如果採用阻塞呼叫的方式,當讀寫事件沒有準備好時,必然不能夠進行讀寫事件,那麼久只好等待,等事件準備好了,才能進行讀寫事件,那麼請求就會被耽擱 。
②既然沒有準備好阻塞呼叫不行,那麼採用非阻塞呼叫方式。非阻塞就是:事件馬上返回,告訴你事件還沒準備好呢,你慌什麼,過會再來吧。好吧,你過一會,再來檢查一下事件,直到事件準備好了為止,在這期間,你就可以先去做其它事情,然後再來看看事件好了沒。雖然不阻塞了,但你得不時地過來檢查
(4)事件驅動:通訊機制採用epoll模型,支援更大的併發連線。
①非阻塞通過不斷檢查事件的狀態來判斷是否進行讀寫操作,這樣帶來的開銷很大,因此就有了非同步非阻塞的事件處理機制。這種機制讓你可以同時監控多個事件,呼叫他們是阻塞的,但可以設定超時時間,在超時時間之內,如果有事件準備好了,就返回。這種機制解決了上面阻塞呼叫與非阻塞呼叫的兩個問題。
②以epoll模型為例:當事件沒有準備好時,就放入epoll(佇列)裡面。如果有事件準備好了,那麼就去處 理;如果事件返回的是EAGAIN,那麼繼續將其放入epoll裡面。從而,只要有事件準備好了,我們就去處理它,只有當所有事件都沒有準備好時,才在 epoll裡面等著。這樣,我們就可以併發處理大量的併發了,當然,這裡的併發請求,是指未處理完的請求,執行緒只有一個,所以同時能處理的請求當然只有一 個了,只是在請求間進行不斷地切換而已,切換也是因為非同步事件未準備好,而主動讓出的。這裡的切換是沒有任何代價,你可以理解為迴圈處理多個準備好的事 件,事實上就是這樣的。
③與多執行緒方式相比,這種事件處理方式是有很大的優勢的,不需要建立執行緒,每個請求佔用的記憶體也很少,沒有上下文切換, 事件處理非常的輕量級,併發數再多也不會導致無謂的資源浪費(上下文切換)。對於IIS伺服器,每個請求會獨佔一個工作執行緒,當併發數上到幾千時,就同時 有幾千的執行緒在處理請求了。這對作業系統來說,是個不小的挑戰:因為執行緒帶來的記憶體佔用非常大,執行緒的上下文切換帶來的cpu開銷很大,自然效能就上不 去,從而導致在高併發場景下效能下降嚴重。
總結:通過非同步非阻塞的事件處理機制,Nginx實現由程序迴圈處理多個準備好的事件,從而實現高併發和輕量級。
Master/Worker結構:一個master程序,生成一個或多個worker程序。
PS:Master-Worker設計模式核心思想是將原來序列的邏輯並行化, 並將邏輯拆分成很多獨立模組並行執行。其中主要包含兩個主要元件Master和Worker,Master主要將邏輯進行拆分,拆分為互相獨立的部分,同 時維護了Worker佇列,將每個獨立部分下發到多個Worker並行執行,Worker主要進行實際邏輯計算,並將結果返回給Master。
問:nginx採用這種程序模型有什麼好處?
答:採用獨立的程序,可以讓互相之間不會影響,一個程序退出後,其它程序還在工作,服務不會中斷,Master 程序則很快重新啟動新的Worker程序。當然,Worker程序的異常退出,肯定是程式有bug了,異常退出,會導致當前Worker上的所有請求失 敗,不過不會影響到所有請求,所以降低了風險。
(6)記憶體消耗小:處理大併發的請求記憶體消耗非常小。在3萬併發連線下,開啟的10個Nginx 程序才消耗150M記憶體(15M*10=150M)。
(7)內建的健康檢查功能:如果 Nginx 代理的後端的某臺 Web 伺服器宕機了,不會影響前端訪問。
(8)節省頻寬:支援 GZIP 壓縮,可以新增瀏覽器本地快取的 Header 頭。
(9)穩定性高:用於反向代理,宕機的概率微乎其微。
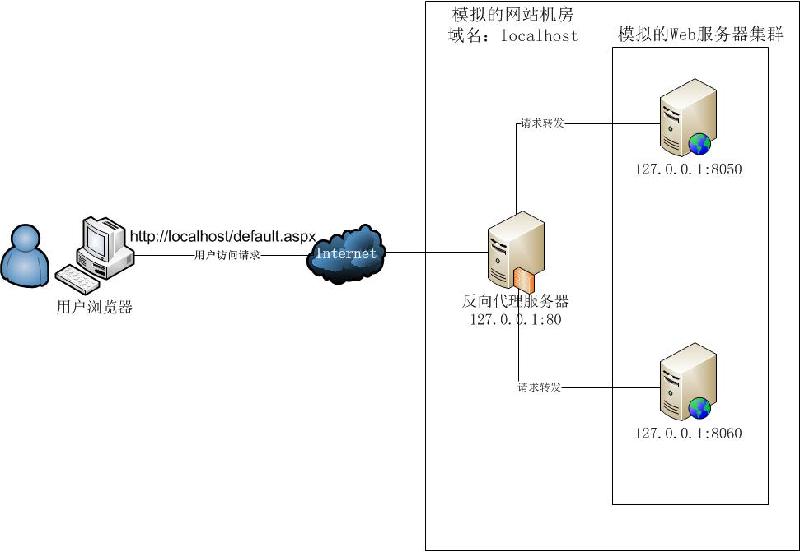
三、構建實戰:Nginx+IIS構築Web伺服器叢集的負載均衡
這裡我們主要在Windows環境下,通過將同一個Web網站部署到不同伺服器的IIS上,再通過一個統一的Nginx反響代理伺服器對外提供統一訪問接入,實現一個最簡化的反向代理和負載均衡服務。但是,受限於實驗條件, 我們這裡主要在一臺計算機上進行反向代理、IIS叢集的模擬,具體的實驗環境如下圖所示:我們將nginx服務和web網站都部署在一臺計算機 上,nginx監聽http80埠,而web網站分別以不同的埠號(這裡是8050及8060)部署在同一個IIS伺服器上,使用者訪問 localhost時,nginx作為反向代理將請求均衡地轉發給兩個IIS中不同埠的Web應用程式進行處理。雖然實驗環境很簡單而且有限,但是對於 一個簡單的負載均衡效果而言,本文是可以達到並且展示的。
3.1 準備一個ASP.NET網站部署到IIS伺服器叢集中
(1)在VS中新建一個ASP.NET Web應用程式,但是為了在一臺計算機上展示效果,我們將這個Web程式複製一份,並修改兩個Web程式的Default.aspx,讓其的首頁顯示不同 的一點資訊。這裡Web1展示的是“The First Web:”,而Web2展示的則是“The Second Web”。
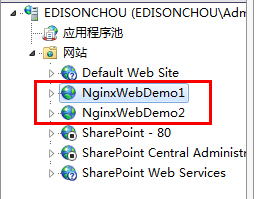
③部署到IIS中,分配不同的埠號:這裡我選擇了Web1:8050,Web2:8060
(3)總結:在真實環境中,構建Web應用伺服器叢集的實現是將同一個Web應用程式部署到Web伺服器叢集中的多個Web伺服器上。
3.2 下載Nginx並部署到伺服器中作為自啟動的Windows服務
(1)到Nginx官網下載Nginx的Windows版本:http://nginx.org/en/download.html(這裡我們使用nginx/Windows-1.4.7版本進行實驗,本文底部有下載地址)
(2)解壓到磁碟任意目錄,例如這裡我解壓到了:D:\Servers\nginx-1.4.7
(3)啟動、停止和重新載入服務:通過cmd以守護程序方式啟動nginx.exe:start nginx.exe,停止服務:nginx -s stop,重新載入配置:nginx -s reload;

3.3 修改Nginx核心配置檔案nginx.conf
(1)程序數與每個程序的最大連線數:
•nginx程序數,建議設定為等於CPU總核心數 •單個程序最大連線數,那麼該伺服器的最大連線數=連線數*程序數
(2)Nginx的基本配置:
•監聽埠一般都為http埠:80; •域名可以有多個,用空格隔開:例如 server_name www.ha97.com ha97.com;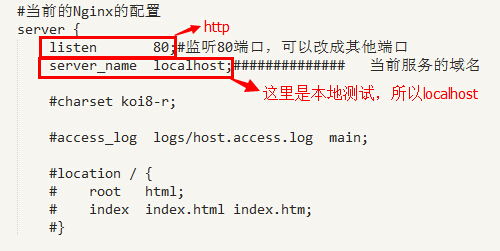
這裡可以配置多個server去監聽多個埠或者去監聽多個域名。或域名:

(3)負載均衡列表基本配置:
•location / {}:對aspx字尾的進行負載均衡請求,假如我們要對所有的aspx字尾的檔案進行負載均衡時,可以這樣寫:location ~ .*\.aspx$ {}
•proxy_pass:請求轉向自定義的伺服器列表,這裡我們將請求都轉向標識為http://cuitccol.com的負載均衡伺服器列表;
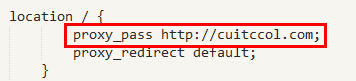
•在負載均衡伺服器列表的配置中,weight是權重,可以根據機器配置定義權重(如果某臺伺服器的硬體配置十分好,可以處理更多的請求,那麼可以 為其設定一個比較高的weight;而有一臺的伺服器的硬體配置比較差,那麼可以將前一臺的weight配置為weight=2,後一臺差的配置為 weight=1)。weigth引數表示權值,權值越高被分配到的機率越大;

(4)總結:最基本的Nginx配置差不多就是上面這些內容,當然僅僅是最基礎的配置。(詳細的配置內容請下載底部的nginx-1.4.7詳細檢視)
3.4 新增Nginx對於靜態檔案的快取配置
為了提高響應速度,減輕真實伺服器的負載,對於靜態資源我們可以在反向代理伺服器中進行快取,這也是反向代理伺服器的一個重要的作用。
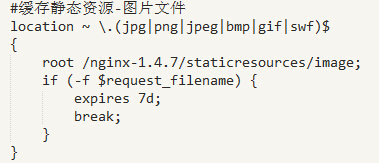
(1)快取靜態資源之圖片檔案
root /nginx-1.4.7/staticresources/image:對於配置中提到的jpg/png等檔案均定為到/nginx-1.4.7/staticresources/image資料夾中進行尋找匹配並將檔案返回;
expires 7d:過期時效為7天,靜態檔案不怎麼更新,過期時效可以設大一點,如果頻繁更新,則可以設定得小一點;
TIPS:下面的樣式、指令碼快取配置同這裡一樣,只是定位的資料夾不一樣而已,不再贅述。
(2)快取靜態資源之樣式檔案
(3)快取靜態資源之指令碼檔案
(4)在nginx服務資料夾中建立靜態資原始檔夾,並要快取的靜態檔案拷貝進去:這裡我主要將Web程式中用到的image、css以及js檔案拷貝了進去;
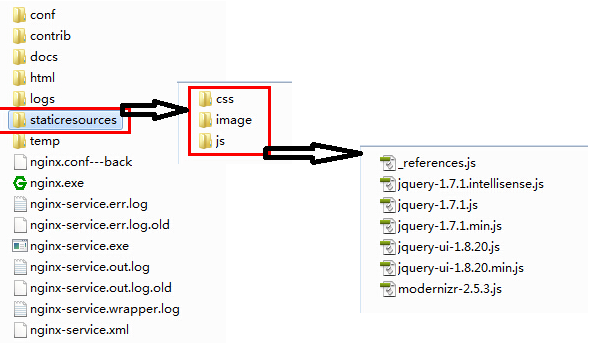
(5)總結:通過配置靜態檔案的快取設定,對於這些靜態檔案的請求可以直接從反向代理伺服器中直接返回,而無需再將這些靜態資源請求轉發到具體的Web伺服器進行處理了,可以提高響應速度,減輕真實Web伺服器的負載壓力。
3.5 簡單測試Nginx反向代理實現負載均衡效果
(1)第一次訪問http://localhost/Default.aspx時從127.0.0.1:8050處理響應返回結果
(2)第二次訪問http://localhost/Default.aspx時從127.0.0.1:8060處理響應返回結果
(3)多次訪問http://localhost/Default.aspx時的截圖:
學習小結
在本文中,藉助了Nginx這個神器簡單地在Windows環境下搭建了一個反向代理服務,並模擬了一個IIS伺服器叢集的負載均衡效果。從這個 DEMO中,我們可以簡單地感受到反向代理為我們所做的事情,並體會負載均衡是怎麼一回事。但是,在目前大多數的應用中,都會將Nginx部署在 Linux伺服器中,並且會做一些針對負載均衡的優化配置,這裡我們所做的僅僅就是一個小小的使用而已(just修改一下配置檔案)。不過,萬丈高樓平地 起,前期的小小體會,也會幫助我們向後期的深入學習奠定一點點的基礎。
上面這篇轉載至http://www.cnblogs.com/edisonchou/p/4126742.html,很感謝各位前輩的探索與研究。下面是另一篇nginx工作原理和優化
本文轉載至http://blog.csdn.net/hguisu/article/details/8930668 很感謝各位前輩的探索與研究。
1. Nginx的模組與工作原理
Nginx由核心和模組組成,其中,核心的設計非常微小和簡潔,完成的工作也非常簡單,僅僅通過查詢配置檔案將客戶端請求對映到一個location block(location是Nginx配置中的一個指令,用於URL匹配),而在這個location中所配置的每個指令將會啟動不同的模組去完成相應的工作。
Nginx的模組從結構上分為核心模組、基礎模組和第三方模組:
核心模組:HTTP模組、EVENT模組和MAIL模組
基礎模組:HTTP Access模組、HTTP FastCGI模組、HTTP Proxy模組和HTTP Rewrite模組,
第三方模組:HTTP Upstream Request Hash模組、Notice模組和HTTP Access Key模組。
使用者根據自己的需要開發的模組都屬於第三方模組。正是有了這麼多模組的支撐,Nginx的功能才會如此強大。
Nginx的模組從功能上分為如下三類。
Handlers(處理器模組)。此類模組直接處理請求,並進行輸出內容和修改headers資訊等操作。Handlers處理器模組一般只能有一個。
Filters (過濾器模組)。此類模組主要對其他處理器模組輸出的內容進行修改操作,最後由Nginx輸出。
Proxies (代理類模組)。此類模組是Nginx的HTTP Upstream之類的模組,這些模組主要與後端一些服務比如FastCGI等進行互動,實現服務代理和負載均衡等功能。
圖1-1展示了Nginx模組常規的HTTP請求和響應的過程。
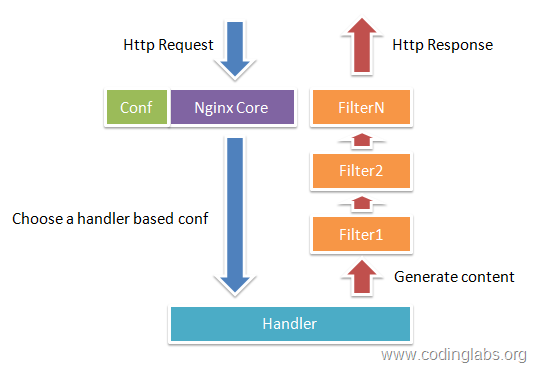
圖1-1展示了Nginx模組常規的HTTP請求和響應的過程。
Nginx本身做的工作實際很少,當它接到一個HTTP請求時,它僅僅是通過查詢配置檔案將此次請求對映到一個location block,而此location中所配置的各個指令則會啟動不同的模組去完成工作,因此模組可以看做Nginx真正的勞動工作者。通常一個location中的指令會涉及一個handler模組和多個filter模組(當然,多個location可以複用同一個模組)。handler模組負責處理請求,完成響應內容的生成,而filter模組對響應內容進行處理。
Nginx的模組直接被編譯進Nginx,因此屬於靜態編譯方式。啟動Nginx後,Nginx的模組被自動載入,不像Apache,首先將模組編譯為一個so檔案,然後在配置檔案中指定是否進行載入。在解析配置檔案時,Nginx的每個模組都有可能去處理某個請求,但是同一個處理請求只能由一個模組來完成。
2. Nginx的程序模型
在工作方式上,Nginx分為單工作程序和多工作程序兩種模式。在單工作程序模式下,除主程序外,還有一個工作程序,工作程序是單執行緒的;在多工作程序模式下,每個工作程序包含多個執行緒。Nginx預設為單工作程序模式。
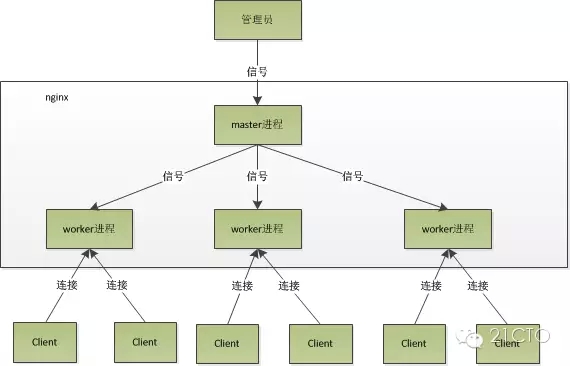
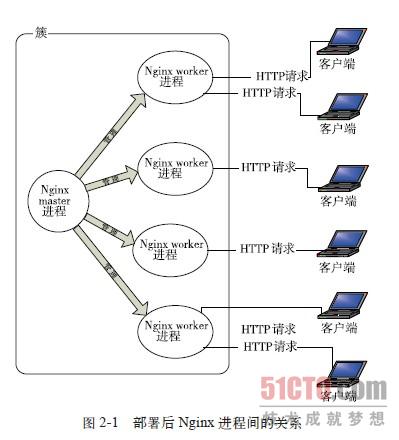
Nginx在啟動後,會有一個master程序和多個worker程序。
master程序
主要用來管理worker程序,包含:接收來自外界的訊號,向各worker程序傳送訊號,監控worker程序的執行狀態,當worker程序退出後(異常情況下),會自動重新啟動新的worker程序。
master程序充當整個程序組與使用者的互動介面,同時對程序進行監護。它不需要處理網路事件,不負責業務的執行,只會通過管理worker程序來實現重啟服務、平滑升級、更換日誌檔案、配置檔案實時生效等功能。
我們要控制nginx,只需要通過kill向master程序傳送訊號就行了。比如kill -HUP pid,則是告訴nginx,從容地重啟nginx,我們一般用這個訊號來重啟nginx,或重新載入配置,因為是從容地重啟,因此服務是不中斷的。master程序在接收到HUP訊號後是怎麼做的呢?首先master程序在接到訊號後,會先重新載入配置檔案,然後再啟動新的worker程序,並向所有老的worker程序傳送訊號,告訴他們可以光榮退休了。新的worker在啟動後,就開始接收新的請求,而老的worker在收到來自master的訊號後,就不再接收新的請求,並且在當前程序中的所有未處理完的請求處理完成後,再退出。當然,直接給master程序傳送訊號,這是比較老的操作方式,nginx在0.8版本之後,引入了一系列命令列引數,來方便我們管理。比如,./nginx -s reload,就是來重啟nginx,./nginx -s stop,就是來停止nginx的執行。如何做到的呢?我們還是拿reload來說,我們看到,執行命令時,我們是啟動一個新的nginx程序,而新的nginx程序在解析到reload引數後,就知道我們的目的是控制nginx來重新載入配置檔案了,它會向master程序傳送訊號,然後接下來的動作,就和我們直接向master程序傳送訊號一樣了。
worker程序:
而基本的網路事件,則是放在worker程序中來處理了。多個worker程序之間是對等的,他們同等競爭來自客戶端的請求,各程序互相之間是獨立的。一個請求,只可能在一個worker程序中處理,一個worker程序,不可能處理其它程序的請求。worker程序的個數是可以設定的,一般我們會設定與機器cpu核數一致,這裡面的原因與nginx的程序模型以及事件處理模型是分不開的。
worker程序之間是平等的,每個程序,處理請求的機會也是一樣的。當我們提供80埠的http服務時,一個連線請求過來,每個程序都有可能處理這個連線,怎麼做到的呢?首先,每個worker程序都是從master程序fork過來,在master程序裡面,先建立好需要listen的socket(listenfd)之後,然後再fork出多個worker程序。所有worker程序的listenfd會在新連線到來時變得可讀,為保證只有一個程序處理該連線,所有worker程序在註冊listenfd讀事件前搶accept_mutex,搶到互斥鎖的那個程序註冊listenfd讀事件,在讀事件裡呼叫accept接受該連線。當一個worker程序在accept這個連線之後,就開始讀取請求,解析請求,處理請求,產生資料後,再返回給客戶端,最後才斷開連線,這樣一個完整的請求就是這樣的了。我們可以看到,一個請求,完全由worker程序來處理,而且只在一個worker程序中處理。worker程序之間是平等的,每個程序,處理請求的機會也是一樣的。當我們提供80埠的http服務時,一個連線請求過來,每個程序都有可能處理這個連線,怎麼做到的呢?首先,每個worker程序都是從master程序fork過來,在master程序裡面,先建立好需要listen的socket(listenfd)之後,然後再fork出多個worker程序。所有worker程序的listenfd會在新連線到來時變得可讀,為保證只有一個程序處理該連線,所有worker程序在註冊listenfd讀事件前搶accept_mutex,搶到互斥鎖的那個程序註冊listenfd讀事件,在讀事件裡呼叫accept接受該連線。當一個worker程序在accept這個連線之後,就開始讀取請求,解析請求,處理請求,產生資料後,再返回給客戶端,最後才斷開連線,這樣一個完整的請求就是這樣的了。我們可以看到,一個請求,完全由worker程序來處理,而且只在一個worker程序中處理。
nginx的程序模型,可以由下圖來表示:
3. Nginx+FastCGI執行原理
1、什麼是 FastCGI
FastCGI是一個可伸縮地、高速地在HTTP server和動態指令碼語言間通訊的介面。多數流行的HTTP server都支援FastCGI,包括Apache、Nginx和lighttpd等。同時,FastCGI也被許多指令碼語言支援,其中就有PHP。
FastCGI是從CGI發展改進而來的。傳統CGI介面方式的主要缺點是效能很差,因為每次HTTP伺服器遇到動態程式時都需要重新啟動指令碼解析器來執行解析,然後將結果返回給HTTP伺服器。這在處理高併發訪問時幾乎是不可用的。另外傳統的CGI介面方式安全性也很差,現在已經很少使用了。
FastCGI介面方式採用C/S結構,可以將HTTP伺服器和指令碼解析伺服器分開,同時在指令碼解析伺服器上啟動一個或者多個指令碼解析守護程序。當HTTP伺服器每次遇到動態程式時,可以將其直接交付給FastCGI程序來執行,然後將得到的結果返回給瀏覽器。這種方式可以讓HTTP伺服器專一地處理靜態請求或者將動態指令碼伺服器的結果返回給客戶端,這在很大程度上提高了整個應用系統的效能。
2、Nginx+FastCGI執行原理
Nginx不支援對外部程式的直接呼叫或者解析,所有的外部程式(包括PHP)必須通過FastCGI介面來呼叫。FastCGI介面在Linux下是socket(這個socket可以是檔案socket,也可以是ip socket)。
wrapper:為了呼叫CGI程式,還需要一個FastCGI的wrapper(wrapper可以理解為用於啟動另一個程式的程式),這個wrapper繫結在某個固定socket上,如埠或者檔案socket。當Nginx將CGI請求傳送給這個socket的時候,通過FastCGI介面,wrapper接收到請求,然後Fork(派生)出一個新的執行緒,這個執行緒呼叫直譯器或者外部程式處理指令碼並讀取返回資料;接著,wrapper再將返回的資料通過FastCGI介面,沿著固定的socket傳遞給Nginx;最後,Nginx將返回的資料(html頁面或者圖片)傳送給客戶端。這就是Nginx+FastCGI的整個運作過程,如圖1-3所示。
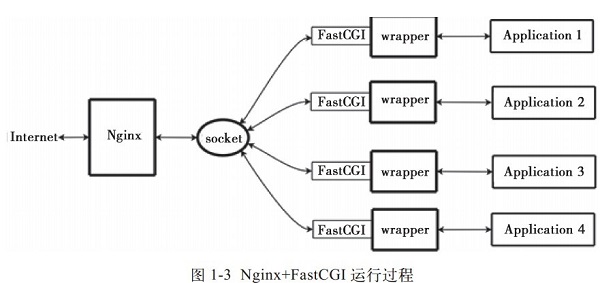
所以,我們首先需要一個wrapper,這個wrapper需要完成的工作:
- 通過呼叫fastcgi(庫)的函式通過socket和ningx通訊(讀寫socket是fastcgi內部實現的功能,對wrapper是非透明的)
- 排程thread,進行fork和kill
- 和application(php)進行通訊
3、spawn-fcgi與PHP-FPM
FastCGI介面方式在指令碼解析伺服器上啟動一個或者多個守護程序對動態指令碼進行解析,這些程序就是FastCGI程序管理器,或者稱為FastCGI引擎。 spawn-fcgi與PHP-FPM就是支援PHP的兩個FastCGI程序管理器。因此HTTPServer完全解放出來,可以更好地進行響應和併發處理。 spawn-fcgi與PHP-FPM的異同:1)spawn-fcgi是HTTP伺服器lighttpd的一部分,目前已經獨立成為一個專案,一般與lighttpd配合使用來支援PHP。但是ligttpd的spwan-fcgi在高併發訪問的時候,會出現記憶體洩漏甚至自動重啟FastCGI的問題。即:PHP指令碼處理器當機,這個時候如果使用者訪問的話,可能就會出現白頁(即PHP不能被解析或者出錯)。 2)Nginx是個輕量級的HTTP server,必須藉助第三方的FastCGI處理器才可以對PHP進行解析,因此其實這樣看來nginx是非常靈活的,它可以和任何第三方提供解析的處理器實現連線從而實現對PHP的解析(在nginx.conf中很容易設定)。nginx也可以使用spwan-fcgi(需要一同安裝lighttpd,但是需要為nginx避開埠,一些較早的blog有這方面安裝的教程),但是由於spawn-fcgi具有上面所述的使用者逐漸發現的缺陷,現在慢慢減少用nginx+spawn-fcgi組合了。
由於spawn-fcgi的缺陷,現在出現了第三方(目前已經加入到PHP core中)的PHP的FastCGI處理器PHP-FPM,它和spawn-fcgi比較起來有如下優點:
由於它是作為PHP的patch補丁來開發的,安裝的時候需要和php原始碼一起編譯,也就是說編譯到php core中了,因此在效能方面要優秀一些;
同時它在處理高併發方面也優於spawn-fcgi,至少不會自動重啟fastcgi處理器。因此,推薦使用Nginx+PHP/PHP-FPM這個組合對PHP進行解析。
相對Spawn-FCGI,PHP-FPM在CPU和記憶體方面的控制都更勝一籌,而且前者很容易崩潰,必須用crontab進行監控,而PHP-FPM則沒有這種煩惱。FastCGI 的主要優點是把動態語言和HTTP Server分離開來,所以Nginx與PHP/PHP-FPM經常被部署在不同的伺服器上,以分擔前端Nginx伺服器的壓力,使Nginx專一處理靜態請求和轉發動態請求,而PHP/PHP-FPM伺服器專一解析PHP動態請求。
4、Nginx+PHP-FPM
PHP-FPM是管理FastCGI的一個管理器,它作為PHP的外掛存在,在安裝PHP要想使用PHP-FPM時在老php的老版本(php5.3.3之前)就需要把PHP-FPM以補丁的形式安裝到PHP中,而且PHP要與PHP-FPM版本一致,這是必須的)
PHP-FPM其實是PHP原始碼的一個補丁,旨在將FastCGI程序管理整合進PHP包中。必須將它patch到你的PHP原始碼中,在編譯安裝PHP後才可以使用。
PHP5.3.3已經整合php-fpm了,不再是第三方的包了。PHP-FPM提供了更好的PHP程序管理方式,可以有效控制記憶體和程序、可以平滑過載PHP配置,比spawn-fcgi具有更多優點,所以被PHP官方收錄了。在./configure的時候帶 –enable-fpm引數即可開啟PHP-FPM。
fastcgi已經在php5.3.5的core中了,不必在configure時新增 --enable-fastcgi了。老版本如php5.2的需要加此項。
當我們安裝Nginx和PHP-FPM完後,配置資訊:
PHP-FPM的預設配置php-fpm.conf: listen_address 127.0.0.1:9000 #這個表示php的fastcgi程序監聽的ip地址以及埠 start_servers min_spare_servers max_spare_servers Nginx配置執行php: 編輯nginx.conf加入如下語句: location ~ \.php$ {root html;
fastcgi_pass 127.0.0.1:9000; 指定了fastcgi程序偵聽的埠,nginx就是通過這裡與php互動的
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /usr/local/nginx/html$fastcgi_script_name;
} Nginx通過location指令,將所有以php為字尾的檔案都交給127.0.0.1:9000來處理,而這裡的IP地址和埠就是FastCGI程序監聽的IP地址和埠。 其整體工作流程: 1)、FastCGI程序管理器php-fpm自身初始化,啟動主程序php-fpm和啟動start_servers個CGI 子程序。 主程序php-fpm主要是管理fastcgi子程序,監聽9000埠。 fastcgi子程序等待來自Web Server的連線。 2)、當客戶端請求到達Web Server Nginx是時,Nginx通過location指令,將所有以php為字尾的檔案都交給127.0.0.1:9000來處理,即Nginx通過location指令,將所有以php為字尾的檔案都交給127.0.0.1:9000來處理。 3)FastCGI程序管理器PHP-FPM選擇並連線到一個子程序CGI直譯器。Web server將CGI環境變數和標準輸入傳送到FastCGI子程序。 4)、FastCGI子程序完成處理後將標準輸出和錯誤資訊從同一連線返回Web Server。當FastCGI子程序關閉連線時,請求便告處理完成。 5)、FastCGI子程序接著等待並處理來自FastCGI程序管理器(執行在 WebServer中)的下一個連線。
4. Nginx+PHP正確配置
這個就不說了,文章的書寫著用的php,對此不是很瞭解。5. Nginx為啥效能高-多程序IO模型
參考http://mp.weixin.qq.com/s?__biz=MjM5NTg2NTU0Ng==&mid=407889757&idx=3&sn=cfa8a70a5fd2a674a91076f67808273c&scene=23&srcid=0401aeJQEraSG6uvLj69Hfve#rd
1、nginx採用多程序模型好處
首先,對於每個worker程序來說,獨立的程序,不需要加鎖,所以省掉了鎖帶來的開銷,同時在程式設計以及問題查詢時,也會方便很多。
其次,採用獨立的程序,可以讓互相之間不會影響,一個程序退出後,其它程序還在工作,服務不會中斷,master程序則很快啟動新的worker程序。當然,worker程序的異常退出,肯定是程式有bug了,異常退出,會導致當前worker上的所有請求失敗,不過不會影響到所有請求,所以降低了風險。
1、nginx多程序事件模型:非同步非阻塞
雖然nginx採用多worker的方式來處理請求,每個worker裡面只有一個主執行緒,那能夠處理的併發數很有限啊,多少個worker就能處理多少個併發,何來高併發呢?非也,這就是nginx的高明之處,nginx採用了非同步非阻塞的方式來處理請求,也就是說,nginx是可以同時處理成千上萬個請求的。一個worker程序可以同時處理的請求數只受限於記憶體大小,而且在架構設計上,不同的worker程序之間處理併發請求時幾乎沒有同步鎖的限制,worker程序通常不會進入睡眠狀態,因此,當Nginx上的程序數與CPU核心數相等時(最好每一個worker程序都繫結特定的CPU核心),程序間切換的代價是最小的。
而apache的常用工作方式(apache也有非同步非阻塞版本,但因其與自帶某些模組衝突,所以不常用),每個程序在一個時刻只處理一個請求,因此,當併發數上到幾千時,就同時有幾千的程序在處理請求了。這對作業系統來說,是個不小的挑戰,程序帶來的記憶體佔用非常大,程序的上下文切換帶來的cpu開銷很大,自然效能就上不去了,而這些開銷完全是沒有意義的。
為什麼nginx可以採用非同步非阻塞的方式來處理呢,或者非同步非阻塞到底是怎麼回事呢?
我們先回到原點,看看一個請求的完整過程:首先,請求過來,要建立連線,然後再接收資料,接收資料後,再發送資料。
具體到系統底層,就是讀寫事件,而當讀寫事件沒有準備好時,必然不可操作,如果不用非阻塞的方式來呼叫,那就得阻塞呼叫了,事件沒有準備好,那就只能等了,等事件準備好了,你再繼續吧。阻塞呼叫會進入核心等待,cpu就會讓出去給別人用了,對單執行緒的worker來說,顯然不合適,當網路事件越多時,大家都在等待呢,cpu空閒下來沒人用,cpu利用率自然上不去了,更別談高併發了。好吧,你說加程序數,這跟apache的執行緒模型有什麼區別,注意,別增加無謂的上下文切換。所以,在nginx裡面,最忌諱阻塞的系統呼叫了。不要阻塞,那就非阻塞嘍。非阻塞就是,事件沒有準備好,馬上返回EAGAIN,告訴你,事件還沒準備好呢,你慌什麼,過會再來吧。好吧,你過一會,再來檢查一下事件,直到事件準備好了為止,在這期間,你就可以先去做其它事情,然後再來看看事件好了沒。雖然不阻塞了,但你得不時地過來檢查一下事件的狀態,你可以做更多的事情了,但帶來的開銷也是不小的。
關於IO模型:http://blog.csdn.NET/hguisu/article/details/7453390
nginx支援的事件模型如下(nginx的wiki):
Nginx支援如下處理連線的方法(I/O複用方法),這些方法可以通過use指令指定。
- select– 標準方法。 如果當前平臺沒有更有效的方法,它是編譯時預設的方法。你可以使用配置引數 –with-select_module 和 –without-select_module 來啟用或禁用這個模組。
- poll– 標準方法。 如果當前平臺沒有更有效的方法,它是編譯時預設的方法。你可以使用配置引數 –with-poll_module 和 –without-poll_module 來啟用或禁用這個模組。
- kqueue– 高效的方法,使用於 FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 和 MacOS X. 使用雙處理器的MacOS X系統使用kqueue可能會造成核心崩潰。
- epoll–高效的方法,使用於Linux核心2.6版本及以後的系統。在某些發行版本中,如SuSE 8.2, 有讓2.4版本的核心支援epoll的補丁。
- rtsig–可執行的實時訊號,使用於Linux核心版本2.2.19以後的系統。預設情況下整個系統中不能出現大於1024個POSIX實時(排隊)訊號。這種情況 對於高負載的伺服器來說是低效的;所以有必要通過調節核心引數 /proc/sys/kernel/rtsig-max 來增加佇列的大小。可是從Linux核心版本2.6.6-mm2開始, 這個引數就不再使用了,並且對於每個程序有一個獨立的訊號佇列,這個佇列的大小可以用 RLIMIT_SIGPENDING 引數調節。當這個佇列過於擁塞,nginx就放棄它並且開始使用 poll 方法來處理連線直到恢復正常。
- /dev/poll– 高效的方法,使用於 Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+ 和 Tru64 UNIX 5.1A+.
- eventport– 高效的方法,使用於 Solaris 10. 為了防止出現核心崩潰的問題, 有必要安裝這個安全補丁。
在linux下面,只有epoll是高效的方法
下面再來看看epoll到底是如何高效的
Epoll是Linux核心為處理大批量控制代碼而作了改進的poll。
要使用epoll只需要這三個系統呼叫:epoll_create(2), epoll_ctl(2), epoll_wait(2)。它是在2.5.44核心中被引進的(epoll(4) is a new API introduced in Linux kernel 2.5.44),在2.6核心中得到廣泛應用。
epoll的優點
- 支援一個程序開啟大數目的socket描述符(FD)
select 最不能忍受的是一個程序所開啟的FD是有一定限制的,由FD_SETSIZE設定,預設值是2048。對於那些需要支援的上萬連線數目的IM伺服器來說顯 然太少了。這時候你一是可以選擇修改這個巨集然後重新編譯核心,不過資料也同時指出這樣會帶來網路效率的下降,二是可以選擇多程序的解決方案(傳統的 Apache方案),不過雖然linux上面建立程序的代價比較小,但仍舊是不可忽視的,加上程序間資料同步遠比不上執行緒間同步的高效,所以也不是一種完 美的方案。不過 epoll則沒有這個限制,它所支援的FD上限是最大可以開啟檔案的數目,這個數字一般遠大於2048,舉個例子,在1GB記憶體的機器上大約是10萬左 右,具體數目可以cat /proc/sys/fs/file-max察看,一般來說這個數目和系統記憶體關係很大。
- IO效率不隨FD數目增加而線性下降
傳統的select/poll另一個致命弱點就是當你擁有一個很大的socket集合,不過由於網路延時,任一時間只有部分的socket是”活躍”的,但 是select/poll每次呼叫都會線性掃描全部的集合,導致效率呈現線性下降。但是epoll不存在這個問題,它只會對”活躍”的socket進行操 作—這是因為在核心實現中epoll是根據每個fd上面的callback函式實現的。那麼,只有”活躍”的socket才會主動的去呼叫 callback函式,其他idle狀態socket則不會,在這點上,epoll實現了一個”偽”AIO,因為這時候推動力在os核心。在一些 benchmark中,如果所有的socket基本上都是活躍的—比如一個高速LAN環境,epoll並不比select/poll有什麼效率,相 反,如果過多使用epoll_ctl,效率相比還有稍微的下降。但是一旦使用idle connections模擬WAN環境,epoll的效率就遠在select/poll之上了。
- 使用mmap加速核心與使用者空間的訊息傳遞。
這 點實際上涉及到epoll的具體實現了。無論是select,poll還是epoll都需要核心把FD訊息通知給使用者空間,如何避免不必要的記憶體拷貝就很 重要,在這點上,epoll是通過核心於使用者空間mmap同一塊記憶體實現的。而如果你想我一樣從2.5核心就關注epoll的話,一定不會忘記手工 mmap這一步的。
- 核心微調
這一點其實不算epoll的優點了,而是整個linux平臺的優點。也許你可以懷疑linux平臺,但是你無法迴避linux平臺賦予你微調核心的能力。比如,核心TCP/IP協 議棧使用記憶體池管理sk_buff結構,那麼可以在執行時期動態調整這個記憶體pool(skb_head_pool)的大小— 通過echo XXXX>/proc/sys/net/core/hot_list_length完成。再比如listen函式的第2個引數(TCP完成3次握手 的資料包佇列長度),也可以根據你平臺記憶體大小動態調整。更甚至在一個數據包面數目巨大但同時每個資料包本身大小卻很小的特殊系統上嘗試最新的NAPI網絡卡驅動架構。
(epoll內容,參考epoll_互動百科)
推薦設定worker的個數為cpu的核數,在這裡就很容易理解了,更多的worker數,只會導致程序來競爭cpu資源了,從而帶來不必要的上下文切換。而且,nginx為了更好的利用多核特性,提供了cpu親緣性的繫結選項,我們可以將某一個程序繫結在某一個核上,這樣就不會因為程序的切換帶來cache的失效。像這種小的優化在nginx中非常常見,同時也說明了nginx作者的苦心孤詣。比如,nginx在做4個位元組的字串比較時,會將4個字元轉換成一個int型,再作比較,以減少cpu的指令數等等。
程式碼來總結一下nginx的事件處理模型:
- while (true) {
- for t in run_tasks:
- t.handler();
- update_time(&now);
- timeout = ETERNITY;
- for t in wait_tasks: /* sorted already */
- if (t.time <= now) {
- t.timeout_handler();
- } else {
- timeout = t.time - now;
- break;
- }
- nevents = poll_function(events, timeout);
- for i in nevents:
- task t;
- if (events[i].type == READ) {
- t.handler = read_handler;
- }