
Lucene學習總結之四:Lucene索引過程分析(1)

對於Lucene的索引過程,除了將詞(Term)寫入倒排表並最終寫入Lucene的索引檔案外,還包括分詞(Analyzer)和合並段(merge segments)的過程,本次不包括這兩部分,將在以後的文章中進行分析。
Lucene的索引過程,很多的部落格,文章都有介紹,推薦大家上網搜一篇文章:《Annotated Lucene》,好像中文名稱叫《Lucene原始碼剖析》是很不錯的。
想要真正瞭解Lucene索引檔案過程,最好的辦法是跟進程式碼除錯,對著文章看程式碼,這樣不但能夠最詳細準確的掌握索引過程(描述都是有偏差的,而程式碼是不會騙你的),而且還能夠學習Lucene的一些優秀的實現,能夠在以後的工作中為我所用,畢竟Lucene是比較優秀的開源專案之一。
由於Lucene已經升級到3.0.0了,本索引過程為Lucene 3.0.0的索引過程。
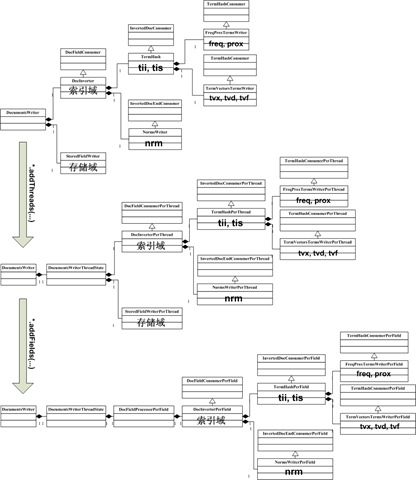
一、索引過程體系結構
Lucene 3.0的搜尋要經歷一個十分複雜的過程,各種資訊分散在不同的物件中分析,處理,寫入,為了支援多執行緒,每個執行緒都建立了一系列類似結構的物件集,為了提高效率,要複用一些物件集,這使得索引過程更加複雜。
其實索引過程,就是經歷下圖中所示的索引鏈的過程,索引鏈中的每個節點,負責索引文件的不同部分的資訊 ,當經歷完所有的索引鏈的時候,文件就處理完畢了。最初的索引鏈,我們稱之基本索引鏈。
為了支援多執行緒,使得多個執行緒能夠併發處理文件,因而每個執行緒都要建立自己的索引鏈體系,使得每個執行緒能夠獨立工作,在基本索引鏈基礎上建立起來的每個執行緒獨立的索引鏈體系,我們稱之執行緒索引鏈。執行緒索引鏈的每個節點是由基本索引鏈中的相應的節點呼叫函式addThreads建立的。
為了提高效率,考慮到對相同域的處理有相似的過程,應用的快取也大致相當,因而不必每個執行緒在處理每一篇文件的時候都重新建立一系列物件,而是複用這些物件。所以對每個域也建立了自己的索引鏈體系,我們稱之域索引鏈
當完成對文件的處理後,各部分資訊都要寫到索引檔案中,寫入索引檔案的過程是同步的,不是多執行緒的,也是沿著基本索引鏈將各部分資訊依次寫入索引檔案的。
下面詳細分析這一過程。
二、詳細索引過程
1、建立IndexWriter物件
程式碼:
| IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); |
IndexWriter物件主要包含以下幾方面的資訊:
- 用於索引文件
- Directory directory; 指向索引資料夾
- Analyzer analyzer; 分詞器
- Similarity similarity = Similarity.getDefault(); 影響打分的標準化因子(normalization factor)部分,對文件的打分分兩個部分,一部分是索引階段計算的,與查詢語句無關,一部分是搜尋階段計算的,與查詢語句相關。
- SegmentInfos segmentInfos = new SegmentInfos(); 儲存段資訊,大家會發現,和segments_N中的資訊幾乎一一對應。
- IndexFileDeleter deleter; 此物件不是用來刪除文件的,而是用來管理索引檔案的。
- Lock writeLock; 每一個索引資料夾只能開啟一個IndexWriter,所以需要鎖。
- Set<SegmentInfo> segmentsToOptimize = new HashSet<SegmentInfo>(); 儲存正在最優化(optimize)的段資訊。當呼叫optimize的時候,當前所有的段資訊加入此Set,此後新生成的段並不參與此次最優化。
- 用於合併段,在合併段的文章中將詳細描述
- SegmentInfos localRollbackSegmentInfos;
- HashSet<SegmentInfo> mergingSegments = new HashSet<SegmentInfo>();
- MergePolicy mergePolicy = new LogByteSizeMergePolicy(this);
- MergeScheduler mergeScheduler = new ConcurrentMergeScheduler();
- LinkedList<MergePolicy.OneMerge> pendingMerges = new LinkedList<MergePolicy.OneMerge>();
- Set<MergePolicy.OneMerge> runningMerges = new HashSet<MergePolicy.OneMerge>();
- List<MergePolicy.OneMerge> mergeExceptions = new ArrayList<MergePolicy.OneMerge>();
- long mergeGen;
- 為保持索引完整性,一致性和事務性
- SegmentInfos rollbackSegmentInfos; 當IndexWriter對索引進行了新增,刪除文件操作後,可以呼叫commit將修改提交到檔案中去,也可以呼叫rollback取消從上次commit到此時的修改。
- SegmentInfos localRollbackSegmentInfos; 此段資訊主要用於將其他的索引資料夾合併到此索引資料夾的時候,為防止合併到一半出錯可回滾所儲存的原來的段資訊。
- 一些配置
- long writeLockTimeout; 獲得鎖的時間超時。當超時的時候,說明此索引資料夾已經被另一個IndexWriter打開了。
- int termIndexInterval; 同tii和tis檔案中的indexInterval。
有關SegmentInfos物件所儲存的資訊:
- 當索引資料夾如下的時候,SegmentInfos物件如下表
| segmentInfos SegmentInfos (id=37) |
有關IndexFileDeleter:
- 其不是用來刪除文件的,而是用來管理索引檔案的。
- 在對文件的新增,刪除,對段的合併的處理過程中,會生成很多新的檔案,並需要刪除老的檔案,因而需要管理。
- 然而要被刪除的檔案又可能在被用,因而要儲存一個引用計數,僅僅當引用計數為零的時候,才執行刪除。
- 下面這個例子能很好的說明IndexFileDeleter如何對檔案引用計數並進行新增和刪除的。
| (1) 建立IndexWriter時 IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); 索引資料夾如下:
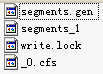
引用計數如下: refCounts HashMap<K,V> (id=101) (2) 新增第一個段時 indexDocs(writer, docDir); 首先生成的不是compound檔案
因而引用計數如下: refCounts HashMap<K,V> (id=101) 然後會合併成compound檔案,並加入引用計數
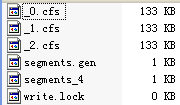
refCounts HashMap<K,V> (id=101) 然後會用IndexFileDeleter.decRef()來刪除[_0.nrm, _0.tis, _0.fnm, _0.tii, _0.frq, _0.fdx, _0.prx, _0.fdt]檔案
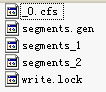
refCounts HashMap<K,V> (id=101) 然後為建立新的segments_2
refCounts HashMap<K,V> (id=77) 然後IndexFileDeleter.decRef() 刪除segments_1檔案
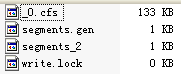
refCounts HashMap<K,V> (id=77) (3) 新增第二個段 indexDocs(writer, docDir);
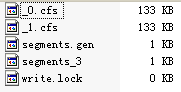
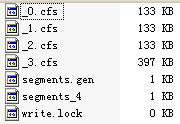
(4) 新增第三個段,由於MergeFactor為3,則會進行一次段合併。 indexDocs(writer, docDir); 首先和其他的段一樣,生成_2.cfs以及segments_4
同時建立了一個執行緒來進行背後進行段合併(ConcurrentMergeScheduler$MergeThread.run())
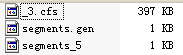
這時候的引用計數如下 refCounts HashMap<K,V> (id=84) (5) 關閉writer writer.close(); 通過IndexFileDeleter.decRef()刪除被合併的段
|

有關SimpleFSLock進行JVM之間的同步:
- 有時候,我們寫java程式的時候,也需要不同的JVM之間進行同步,來保護一個整個系統中唯一的資源。
- 如果唯一的資源僅僅在一個程序中,則可以使用執行緒同步的機制
- 然而如果唯一的資源要被多個程序進行訪問,則需要程序間同步的機制,無論是Windows和Linux在作業系統層面都有很多的程序間同步的機制。
- 但程序間的同步卻不是Java的特長,Lucene的SimpleFSLock給我們提供了一種方式。
| Lock的抽象類 public abstract class Lock { public static long LOCK_POLL_INTERVAL = 1000; public static final long LOCK_OBTAIN_WAIT_FOREVER = -1; public abstract boolean obtain() throws IOException; public boolean obtain(long lockWaitTimeout) throws LockObtainFailedException, IOException { boolean locked = obtain(); if (lockWaitTimeout < 0 && lockWaitTimeout != LOCK_OBTAIN_WAIT_FOREVER) long maxSleepCount = lockWaitTimeout / LOCK_POLL_INTERVAL; long sleepCount = 0; while (!locked) { if (lockWaitTimeout != LOCK_OBTAIN_WAIT_FOREVER && sleepCount++ >= maxSleepCount) { public abstract void release() throws IOException; public abstract boolean isLocked() throws IOException; } LockFactory的抽象類 public abstract class LockFactory { public abstract Lock makeLock(String lockName); abstract public void clearLock(String lockName) throws IOException; SimpleFSLock的實現類 class SimpleFSLock extends Lock { File lockFile; public SimpleFSLock(File lockDir, String lockFileName) { @Override if (!lockDir.exists()) { if (!lockDir.mkdirs()) } else if (!lockDir.isDirectory()) { throw new IOException("Found regular file where directory expected: " + lockDir.getAbsolutePath()); return lockFile.createNewFile(); } @Override if (lockFile.exists() && !lockFile.delete()) } @Override return lockFile.exists(); } } SimpleFSLockFactory的實現類 public class SimpleFSLockFactory extends FSLockFactory { public SimpleFSLockFactory(String lockDirName) throws IOException { setLockDir(new File(lockDirName)); } @Override if (lockPrefix != null) { lockName = lockPrefix + "-" + lockName; } return new SimpleFSLock(lockDir, lockName); } @Override if (lockDir.exists()) { if (lockPrefix != null) { lockName = lockPrefix + "-" + lockName; } File lockFile = new File(lockDir, lockName); if (lockFile.exists() && !lockFile.delete()) { throw new IOException("Cannot delete " + lockFile); } } } }; |
2、建立文件Document物件,並加入域(Field)
程式碼:
| Document doc = new Document(); doc.add(new Field("path", f.getPath(), Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("modified",DateTools.timeToString(f.lastModified(), DateTools.Resolution.MINUTE), Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("contents", new FileReader(f))); |
Document物件主要包括以下部分:
- 此文件的boost,預設為1,大於一說明比一般的文件更加重要,小於一說明更不重要。
- 一個ArrayList儲存此文件所有的域
- 每一個域包括域名,域值,和一些標誌位,和fnm,fdx,fdt中的描述相對應。
| doc Document (id=42) |