
cs229 斯坦福機器學習筆記(一)-- 入門與LR模型
https://blog.csdn.net/Dinosoft/article/details/34960693
前言
說到機器學習,非常多人推薦的學習資料就是斯坦福Andrew Ng的cs229。有相關的視頻和講義。只是好的資料 != 好入門的資料,Andrew Ng在coursera有另外一個機器學習課程,更適合入門。課程有video,review questions和programing exercises,視頻盡管沒有中文字幕,只是看演示的講義還是非常好理解的(假設當初大學裏的課有這麽好。我也不至於畢業後成為文盲。。)。最重要的就是裏面的programing exercises,得理解透才完畢得來的,畢竟不是簡單點點鼠標的選擇題。
只是coursera的課程屏蔽非常一些比較難的內容,假設認為課程不夠過癮。能夠再看看cs229的。這篇筆記主要是參照cs229的課程。但也會穿插coursera的一些內容。
接觸完機器學習,會發現有兩門課非常重要,一個是概率統計。另外一個是線性代數。由於機器學習使用的數據,能夠看成概率統計裏的樣本,而機器學習建模之後,你會發現剩下的就是線性代數求解問題。
線性回歸 linear regression
? 通過現實生活中的樣例。能夠幫助理解和體會線性回歸。比方某日,某屌絲同事說買了房子,那一般大家關心的就是房子在哪。哪個小區,多少錢一平方這些信息,由於我們知道。這些信息是"關鍵信息”(機器學習裏的黑話叫“feature”)。那假設如今要你來評估一套二手房的價格(或者更直接點。你就是一個賣房子的黑中介,嘿嘿),假設你對房價一無所知(比方說房子是在非洲),那你肯定估算不準。最好就能提供同小區其它房子的報價。沒有的話。旁邊小區也行;再沒有的話,所在區的房子均價也行;還是沒有的話,所在城市房子均價也行(在北京有套房和在余杭有套房能一樣麽),由於你知道,這些信息是有“參考價值”的。其次,估算的時候我們肯定希望提供的信息能盡量詳細,由於我們知道房子的朝向。裝修好壞,位置(靠近馬路還是小區中心)是會影響房子價格的。 ? ? 事實上我們人腦在估算的過程,就相似一個“機器學習”的過程。 a)首先我們須要“訓練數據”,也就是相關的房價數據,當然。數據太少肯定不行,要盡量豐富。
有了這些數據。人腦能夠“學習”出房價的一個大體情況。由於我們知道同一小區的同一戶型,一般價格是幾乎相同的(特征相近。目標值-房價也是相近的。不然就沒法預測了);房價我們一般按平方算,平方數和房價有“近似”線性的關系。
b)而“訓練數據”裏面要有啥信息?僅僅給你房子照片肯定不行。肯定是要小區地點。房子大小等等這些關鍵“特征”
c)一般我們人肉估算的時候,比較任意,也就估個大概。不會算到小數點後幾位;而估算的時候,我們會參照現有數據,不會讓估算跟“訓練數據”差得離譜(也就是以下要講的讓損失函數盡量小),不然還要“訓練數據”幹嘛。 計算機擅好處理數值計算。把房價估算問題全然能夠用數學方法來做。把這裏的“人肉估算”數學形式化,也就是“線性回歸”。
1.我們定義線性回歸函數(linear regression)為:?
然後用h(x) 來預測y
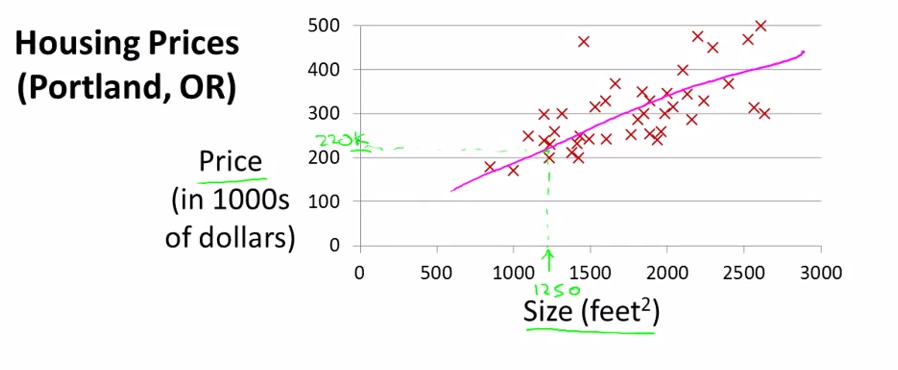
最簡單的樣例,一個特征size,y是Price,把訓練數據畫在圖上,例如以下圖。(舉最簡單的樣例僅僅是幫助理解,當特征僅僅有一維的時候。畫出來是一條直線。多維的時候就是超平面了)
這裏有一個問題,假設真實模型不是線性的怎麽辦?所以套用線性回歸的時候是須要預判的。不然訓練出來的效果肯定不行。這裏不必過於深究,後面也會介紹怎麽通過預處理數據處理非線性的情況。
2.目標就是畫一條直線盡量靠近這些點。用數學語言來描寫敘述就是cost function盡量小。
為什麽是平方和? 直接相減取一下絕對值不行麽, | h(x)-y | ???(後面的Probabilistic interpretation會解釋。這樣求出來的是likelihood最大。另外一個問題。 | h(x)-y |大的時候 (?h(x)-y )^2 不也是一樣增大,看上去好像也一樣?!
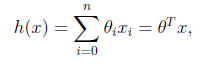
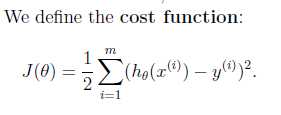
除了後者是凸函數,好求解,所以就用平方和? 不是的,單獨一個樣本縱向比較確實一樣,但別漏了式子前面另一個求和符號,這兩者的差異體如今樣本橫向比較的時候,比方如今有兩組差值,每組兩個樣本,第一組絕對值差是1,3,第二組是2,2,絕對值差求和是一樣,4=4。
算平方差就不一樣了,10 > 8。事實上,x^2求導是2x,這裏的意思就是懲處隨偏差值線性增大,終於的效果從圖上看就是盡可能讓直線靠近全部點)
3 然後就是怎麽求解了。假設h(x)=y那就是初中時候的多元一次方程組了,如今不是。所以要用高端一點的方法。
曾經初中、高中課本也有提到怎麽求解回歸方程,都是按計算器。難怪我一點印象都沒有。囧。
。
還以為失憶了 notes 1裏面介紹3種方法
1.gradient descent (梯度下降)2.the normal equations 3.Newton method(Fisher scoring)a.batch?gradient descent b.stochastic gradient descent (上面的變形)
1.gradient descent?algorithm
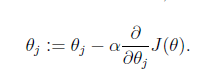 α is called the learning rate.
α is called the learning rate.
僅僅有一個訓練數據的樣例:
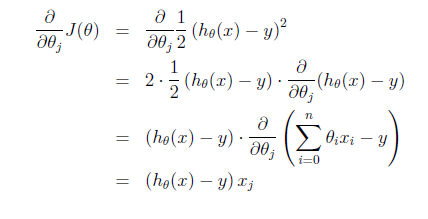
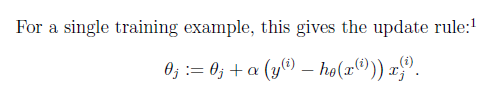 這個式子直觀上也非常好理解,假設xj是正數。y比預測值h(x)大的話,我們要加大θ,所以α前面是+號(當xj是負數同理)
這個式子直觀上也非常好理解,假設xj是正數。y比預測值h(x)大的話,我們要加大θ,所以α前面是+號(當xj是負數同理)
舉一個數據的樣例僅僅是幫助我們理解,實際中是會有多個數據的,你會體會到矩陣的便利性的。
上面的式子在詳細更新的時候有小的不同 方法 a.batch?gradient descent 註意,要同一時候進行更新。由於更新θ(j+1)的時候要用hθ(x),這裏的hθ(x)用的還是老的θ1 到 θj。
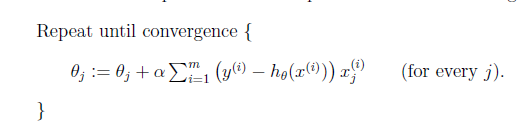
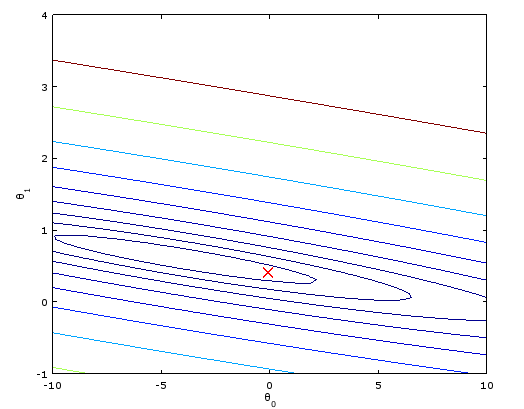
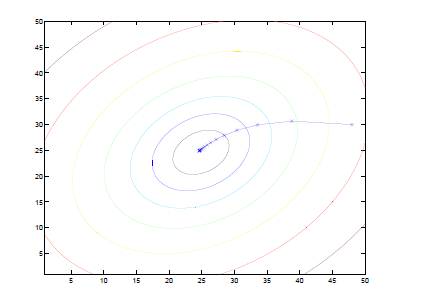 直觀上看,等高線代表cost function的值,橫縱坐標是θ1 θ2兩個參數。梯度下降就是每次一小步沿著垂直等高線的方向往等高線低(圖的中心)的地方走。
直觀上看,等高線代表cost function的值,橫縱坐標是θ1 θ2兩個參數。梯度下降就是每次一小步沿著垂直等高線的方向往等高線低(圖的中心)的地方走。顯然步子不能太大,不然easy扯著蛋(跨一大步之後反而到了更高的點)
方法 b.stochastic gradient descent (also incremental?gradient descent)?
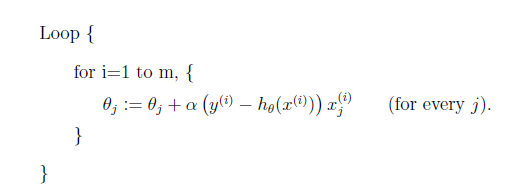
2.the normal equations。
剛開始學習的人能夠先跳過推導過程(不是鼓舞不看。),直接先記住結論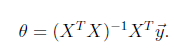 。
。(在線性代數的復習課件cs229-linalg會說明。這個式子事實上是把y投影到X)
3.牛頓法
Another algorithm for maximizing ?(θ) Returning to logistic regression with g(z) being the sigmoid function, lets?now talk about a different algorithm for minimizing -?(θ)。(感覺notes1裏面少了個負號) 牛頓法求函數0點。即 f (Θ) = 0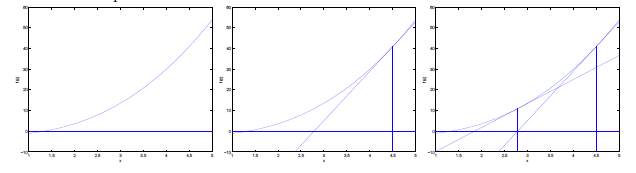
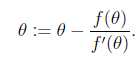 這樣叠代即可,f′(θ)是斜率,從圖上看,就是“用三角形去擬合曲線。找0點”
這樣叠代即可,f′(θ)是斜率,從圖上看,就是“用三角形去擬合曲線。找0點”
由於我們是要求導數等於0。把上面的式子替換一下f(θ) = ?′(θ)
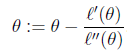 θ是多維的。有
θ是多維的。有
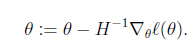
where?
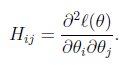 When Newton’s method is applied to maximize the logistic regression log likelihood function ?(θ), the resulting method is also called?Fisher?scoring.
When Newton’s method is applied to maximize the logistic regression log likelihood function ?(θ), the resulting method is also called?Fisher?scoring.
coursera的課件提到其它方法,預計剛開始學習的人沒空深究,了解一下有這些東西就好。

邏輯回歸logistic regression
如今假設有一個0和1的2分類問題的。套進去線性回歸去解,例如以下圖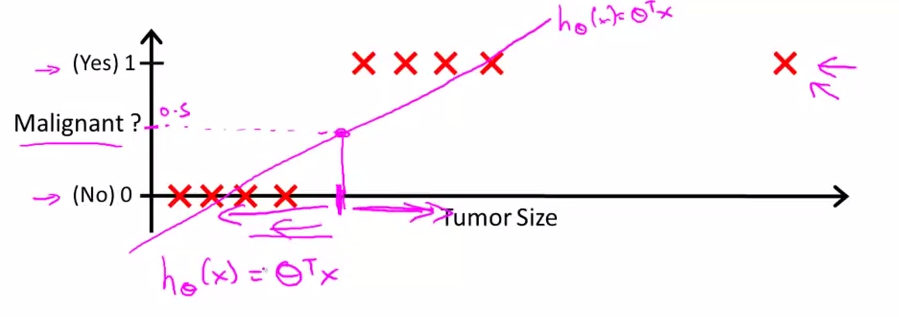 離群點會對結果影響非常大,比方上圖(我們以h(x)>0.5時預測y=1。一個離群點讓直線大旋轉。一下子把不少點誤分類了)(coursera的課程僅僅提到這個原因,但貌似不止),並且另一個問題,Intuitively, it also doesn’t make sense for h(x) to take values larger than 1 or smaller than 0 when we know that
y ∈ {0, 1}. (那h(x)在[0,1]又代表什麽呢?呵呵)
離群點會對結果影響非常大,比方上圖(我們以h(x)>0.5時預測y=1。一個離群點讓直線大旋轉。一下子把不少點誤分類了)(coursera的課程僅僅提到這個原因,但貌似不止),並且另一個問題,Intuitively, it also doesn’t make sense for h(x) to take values larger than 1 or smaller than 0 when we know that
y ∈ {0, 1}. (那h(x)在[0,1]又代表什麽呢?呵呵)
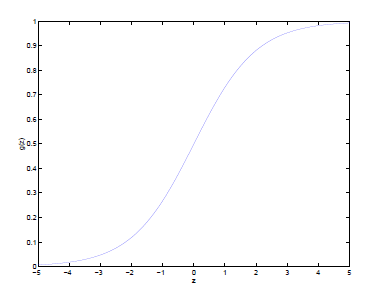 換成這個曲線就好多了,這個函數是sigmoid function
換成這個曲線就好多了,這個函數是sigmoid function
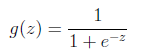 g(z) 值域 (0,1)
g(z) 值域 (0,1)
把線性回歸套進去g(z)就是
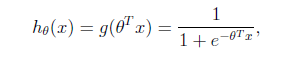
為什麽是sigmoid函數?換個形狀相似的函數不行麽?這個後面一樣有概率解釋的。
註意,這個函數輸出值代表“y為1的概率”,再回過頭看看,前面y用1和0來表示正反也是有講究的(講svn的時候又換成+1。-1),直觀上看sigmoid越接近1表示1的概率大,接近0表示0的概率大,另一個好處就是以下算likelihood的時候用式子好表示。
建模好,還缺一個cost function,是不是跟linear regression一樣求平方差即可?
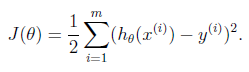 呵呵。不是。coursera課程給出的原因是套入sigmoid後,這個函數不是凸函數。不好求解了。但事實上h(x) -y 算出來是一個概率。多個訓練數據的概率相加是沒意義的。得相乘。
呵呵。不是。coursera課程給出的原因是套入sigmoid後,這個函數不是凸函數。不好求解了。但事實上h(x) -y 算出來是一個概率。多個訓練數據的概率相加是沒意義的。得相乘。p(x,y) = p(x)* p(y)。
先講一個useful property
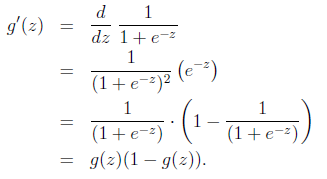
把兩個概率公式合到一起

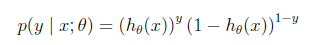
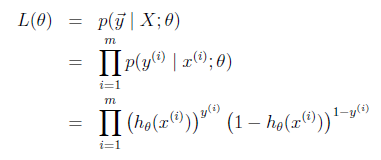
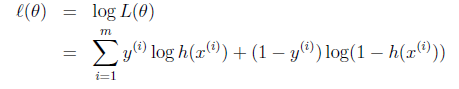
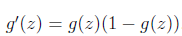

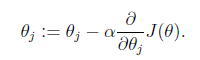
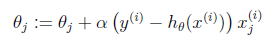
machine learning in practice
我總認為計算機科學動手實踐非常重要,紙上談兵不接地氣。coursera有programing exercise,必須完畢下。octave用起來挺爽的。這裏記錄一下關鍵點。
1.coursera的cost function多除了一個m
事實上起到一個歸一化的作用,讓叠代步長α與訓練樣本數無關(你能夠當作α=α‘/m)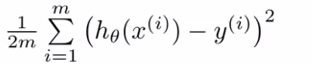
2.batch?gradient descent和stochastic gradient descent的區別
batch?gradient descentfor iter = 1:num_iters
A = ( X * theta - y )‘;
theta = theta - 1/m * alpha * ( A * X )‘;
endstochastic gradient descent
for iter = 1:num_iters
A = ( X * theta - y )‘;
for j = 1:m
theta = theta - alpha * ( A(1, j) * X(j, :) )‘;
end
end用ex1_multi.m改改,生成兩個cost下降圖。能夠發現stochastic gradient descent挺犀利的。
。
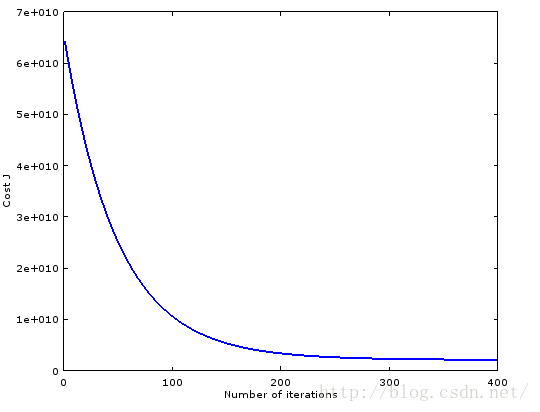
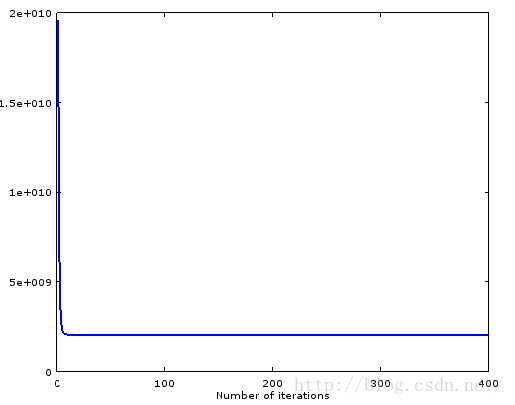
3.feature scaling的作用是啥?
(詳細模型詳細分析,這裏僅僅針對LR模型,不要把結論任意推廣)coursera提到的作用是加速收斂。那會影響結果麽?直覺上,把一個feature擴大10倍,那算cost function的時候豈不是非常占廉價。算出來的權重會偏向這個feature麽? 對這樣的問題,數學家會理論證明,project師做實驗驗證,我習慣粗略證明,然後實驗驗證自己對不正確。 (以下都是粗略的想法,不是嚴謹證明。!)假設每一個樣本的feature j 乘以10,那算出來的θj除以10不就結果跟原來一樣了?我猜不會影響。看一下我們叠代時候的式子
xj變大,h(x) 也變大,粗略叠代步長要擴大10倍(那就起到抑制θ的作用)但終於的θ要變為1/10。想想略蛋疼,比方如今100每次降低1,減99次後變為1,如今每次要降低10。卻要讓終於的結果到0.1,得改α才行啊。看來feature scaling能起到歸一化α的作用。
把ex1.m改一下。做做實驗。
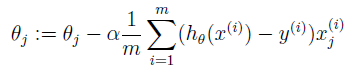
會發現縮放一個feature後,收斂非常困難啊,我僅僅乘以2,原來的代碼就輸出NaN了。
。我把alpha平方一下 alpha^2。
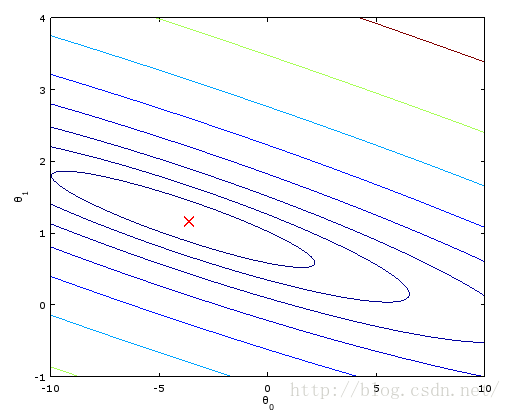
能夠發現等高線變密集了,橢圓形變得非常扁,所以步長不能非常大,收斂非常困難。一直在一個相似直線的橢圓跳來跳去慢慢挪。至於結果會不會變。用normal equation來驗證,由於梯度下降有困難。
改下ex1_muliti.m
X2 = X;
X2(:,2) = X2(:, 2)* 2;
theta2 = pinv(X2‘ * X2) * X2‘ * y;
theta2
thetatheta2(2)就是奇妙地變1/2了。。
theta2 =
8.9598e+004
6.9605e+001
-8.7380e+003
theta =
8.9598e+004
1.3921e+002
-8.7380e+003前面是linear regression,對logistic regression能夠改ex2.m也驗證下
X2(:,2)= X2(:,2)*2;
[theta2, cost] = fminunc(@(t)(costFunction(t, X2, y)), initial_theta, options);
theta2theta:
-25.161272
0.206233
0.201470
theta2 =
-25.16127
0.10312
0.20147
附錄
cost function的概率解釋
我們知道h(x)和真實的y是有偏差的,設偏差是ε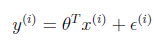 假設ε是iid(獨立同分布)的。符合高斯分布(通常高斯分布是合理的,詳細不解釋),聯想到高斯分布的式子。有平方就不奇怪了。
假設ε是iid(獨立同分布)的。符合高斯分布(通常高斯分布是合理的,詳細不解釋),聯想到高斯分布的式子。有平方就不奇怪了。
?
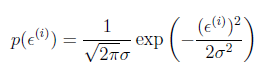 得到
得到
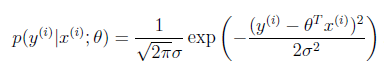 likelihood function:
likelihood function:
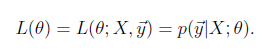
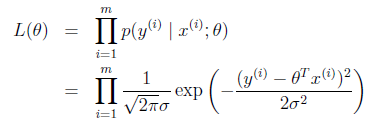
求解技巧,轉成 log likelihood ?(θ)(這個是個非常基礎的技巧,後面會大量用到):
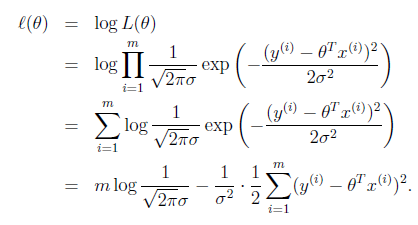
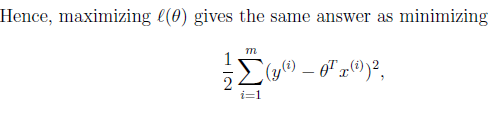
? To summarize: Under the previous probabilistic assumptions on the data, least-squares regression?corresponds to finding the?maximum likelihood estimate of θ.
Next《cs229 斯坦福機器學習筆記(二)-- LR回想與svm算法idea理解》
cs229 斯坦福機器學習筆記(一)-- 入門與LR模型