
基於TensorFlow.js的JavaScript機器學習

Credits: aijs.rocks
雖然python或r程式語言有一個相對容易的學習曲線,但是Web開發人員更喜歡在他們舒適的javascript區域內做事情。目前來看,node.js已經開始向每個領域應用javascript,在這一大趨勢下我們需要理解並使用JS進行機器學習。由於可用的軟體包數量眾多,python變得流行起來,但是JS社群也緊隨其後。這篇文章會幫助初學者學習如何構建一個簡單的分類器。
擴充套件:
2019年11個javascript機器學習庫
很棒的機器學習庫,可以在你的下一個應用程式中新增一些人工智慧!
Big.bitsrc.io
建立
我們可以建立一個使用tensorflow.js在瀏覽器中訓練模型的網頁。考慮到房屋的“avgareanumberofrows”,模型可以學習去預測房屋的“價格”。
為此我們要做的是:
載入資料併為培訓做好準備。
定義模型的體系結構。
訓練模型並在訓練時監控其效能。
通過做出一些預測來評估經過訓練的模型。
第一步:讓我們從基礎開始
建立一個HTML頁面幷包含JavaScript。將以下程式碼複製到名為index.html的HTML檔案中。
<!DOCTYPE html> <html> <head> <title>TensorFlow.js Tutorial</title> <!-- Import TensorFlow.js --> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js"></script> <!-- Import tfjs-vis --> <script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tfjs-vis.umd.min.js"></script> <!-- Import the main script file --> <script src="script.js"></script> </head> <body> </body> </html>
為程式碼建立javascript檔案
在與上面的HTML檔案相同的資料夾中,建立一個名為script.js的檔案,並將以下程式碼放入其中。
console.log('Hello TensorFlow');
測試
既然已經建立了HTML和JavaScript檔案,那麼就測試一下它們。在瀏覽器中開啟index.html檔案並開啟devtools控制檯。
如果一切正常,那麼應該在devtools控制檯中建立並可用兩個全域性變數:
- tf是對tensorflow.js庫的引用
- tfvis是對tfjs vis庫的引用
現在你應該可以看到一條訊息,上面寫著“Hello TensorFlow”。如果是這樣,你就可以繼續下一步了。

需要這樣的輸出
注意:可以使用Bit來共享可重用的JS程式碼
Bit(GitHub上的Bit)是跨專案和應用程式共享可重用JavaScript程式碼的最快和最可擴充套件的方式。可以試一試,它是免費的:
Bit是開發人員共享元件和協作,共同構建令人驚歎的軟體的地方。發現共享的元件…
Bit.dev
例如:Ramda用作共享元件
一個用於JavaScript程式設計師的實用函式庫。-256個javascript元件。例如:等號,乘…
Bit.dev
第2步:載入資料,格式化資料並可視化輸入資料
我們將載入“house”資料集,可以在這裡找到。它包含了特定房子的許多不同特徵。對於本教程,我們只需要有關房間平均面積和每套房子價格的資料。
將以下程式碼新增到script.js檔案中。
async function getData() {
Const houseDataReq=await
fetch('https://raw.githubusercontent.com/meetnandu05/ml1/master/house.json');
const houseData = await houseDataReq.json();
const cleaned = houseData.map(house => ({
price: house.Price,
rooms: house.AvgAreaNumberofRooms,
}))
.filter(house => (house.price != null && house.rooms != null));
return cleaned;
}
這可以刪除沒有定義價格或房間數量的任何條目。我們可以將這些資料繪製成散點圖,看看它是什麼樣子的。
將以下程式碼新增到script.js檔案的底部。
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.rooms,
y: d.price,
}));
tfvis.render.scatterplot(
{name: 'No.of rooms v Price'},
{values},
{
xLabel: 'No. of rooms',
yLabel: 'Price',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
重新整理頁面時,你可以在頁面左側看到一個面板,上面有資料的散點圖,如下圖。
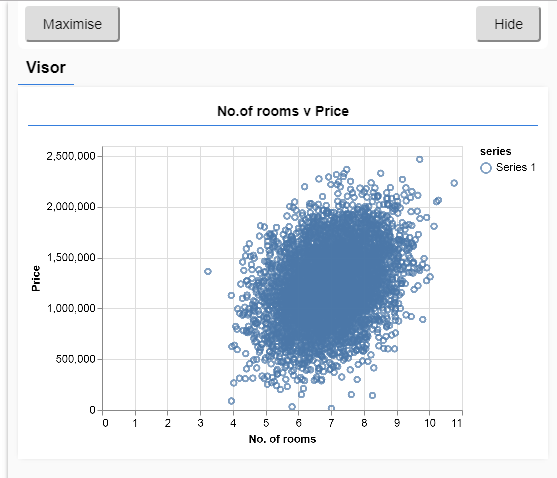
散點圖
通常,在處理資料時,最好找到方法來檢視資料,並在必要時對其進行清理。視覺化資料可以讓我們瞭解模型是否可以學習資料的任何結構。
從上面的圖中可以看出,房間數量與價格之間存在正相關關係,即隨著房間數量的增加,房屋價格普遍上漲。
第三步:建立待培訓的模型
這一步我們將編寫程式碼來構建機器學習模型。模型主要基於此程式碼進行架構,所以這是一個比較重要的步驟。機器學習模型接受輸入,然後產生輸出。對於tensorflow.js,我們必須構建神經網路。
將以下函式新增到script.js檔案中以定義模型。
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single hidden layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
這是我們可以在tensorflow.js中定義的最簡單的模型之一,我們來試下簡單分解每一行。
例項化模型
const model = tf.sequential();
這將例項化一個tf.model物件。這個模型是連續的,因為它的輸入直接流向它的輸出。其他型別的模型可以有分支,甚至可以有多個輸入和輸出,但在許多情況下,你的模型是連續的。
新增層
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
這為我們的網路添加了一個隱藏層。因為這是網路的第一層,所以我們需要定義我們的輸入形狀。輸入形狀是[1],因為我們有1這個數字作為輸入(給定房間的房間數)。
單位(連結)設定權重矩陣在層中的大小。在這裡將其設定為1,我們可以說每個資料輸入特性都有一個權重。
model.add(tf.layers.dense({units: 1}));
上面的程式碼建立了我們的輸出層。我們將單位設定為1,因為我們要輸出1這個數字。
建立例項
將以下程式碼新增到前面定義的執行函式中。
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
這樣可以建立例項模型,並且在網頁上有顯示層的摘要。
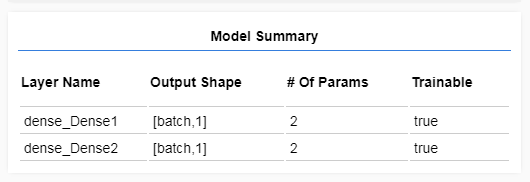
步驟4:為建立準備資料
為了獲得TensorFlow.js的效能優勢,使培訓機器學習模型實用化,我們需要將資料轉換為Tensors。
將以下程式碼新增到script.js檔案中。
function convertToTensor(data) {
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.rooms)
const labels = data.map(d => d.price);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
接下來,我們可以分析一下將會出現什麼情況。
隨機播放資料
// Step 1. Shuffle the data
tf.util.shuffle(data);
在訓練模型的過程中,資料集被分成更小的集合,每個集合稱為一個批。然後將這些批次送入模型執行。整理資料很重要,因為模型不應該一次又一次地得到相同的資料。如果模型一次又一次地得到相同的資料,那麼模型將無法歸納資料,併為執行期間收到的輸入提供指定的輸出。洗牌將有助於在每個批次中擁有各種資料。
轉換為Tensor
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.rooms)
const labels = data.map(d => d.price);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
這裡我們製作了兩個陣列,一個用於輸入示例(房間條目數),另一個用於實際輸出值(在機器學習中稱為標籤,在我們的例子中是每個房子的價格)。然後我們將每個陣列資料轉換為一個二維張量。
規範化資料
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
接下來,我們規範化資料。在這裡,我們使用最小-最大比例將資料規範化為數值範圍0-1。規範化很重要,因為您將使用tensorflow.js構建的許多機器學習模型的內部設計都是為了使用不太大的數字。規範化資料以包括0到1或-1到1的公共範圍。
返回資料和規範化界限
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
我們可以在執行期間保留用於標準化的值,這樣我們就可以取消標準化輸出,使其恢復到原始規模,我們就可以用同樣的方式規範化未來的輸入資料。
步驟5:執行模型
通過建立模型例項、將資料表示為張量,我們可以準備開始執行模型。
將以下函式複製到script.js檔案中。
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 28;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
我們把它分解一下。
準備執行
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
我們必須在訓練前“編譯”模型。要做到這一點,我們必須明確一些非常重要的事情:
優化器:這是一個演算法,它可以控制模型的更新,就像上面看到的例子一樣。TensorFlow.js中有許多可用的優化器。這裡我們選擇了Adam優化器,因為它在實踐中非常有效,不需要進行額外配置。
損失函式:這是一個函式,它用於檢測模型所顯示的每個批(資料子集)方面完成的情況如何。在這裡,我們可以使用meansquaredrror將模型所做的預測與真實值進行比較。
度量:這是我們要在每個區塊結束時用來計算的度量陣列。我們可以用它計算整個訓練集的準確度,這樣我們就可以檢查自己的執行結果了。這裡我們使用mse,它是meansquaredrror的簡寫。這是我們用於損失函式的相同函式,也是迴歸任務中常用的函式。
const batchSize = 28;
const epochs = 50;
接下來,我們選擇一個批量大小和一些時間段:
batchSize指的是模型在每次執行迭代時將看到的資料子集的大小。常見的批量大小通常在32-512之間。對於所有問題來說,並沒有一個真正理想的批量大小,描述各種批量大小的精確方式這一知識點本教程沒有相關講解,對這些有興趣可以通過別的渠道進行了解學習。
epochs指的是模型將檢視你提供的整個資料集的次數。在這裡,我們通過資料集進行50次迭代。
啟動列車環路
return model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{
height: 200,
callbacks: ['onEpochEnd']
}
)
});
model.fit是我們呼叫的啟動迴圈的函式。它是一個非同步函式,因此我們返回它給我們的特定值,以便呼叫者可以確定執行結束時間。
為了監控執行進度,我們將一些回撥傳遞給model.fit。我們使用tfvis.show.fitcallbacks生成函式,這些函式可以為前面指定的“損失”和“毫秒”度量繪製圖表。
把它們放在一起
現在我們必須呼叫從執行函式定義的函式。
將以下程式碼新增到執行函式的底部。
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
重新整理頁面時,幾秒鐘後,你應該會看到圖形正在更新。
這些是由我們之前建立的回撥建立的。它們在每個時代結束時顯示丟失(在最近的批處理上)和毫秒(在整個資料集上)。
當訓練一個模型時,我們希望看到損失減少。在這種情況下,因為我們的度量是一個誤差度量,所以我們希望看到它也下降。
第6步:做出預測
既然我們的模型經過了訓練,我們想做一些預測。讓我們通過觀察它預測的低到高數量房間的統一範圍來評估模型。
將以下函式新增到script.js檔案中
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.rooms, y: d.price,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'No. of rooms',
yLabel: 'Price',
height: 300
}
);
}
在上面的函式中需要注意的一些事情。
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
我們生成100個新的“示例”以提供給模型。model.predict是我們如何將這些示例輸入到模型中的。注意,他們需要有一個類似的形狀([num_的例子,num_的特點每個_的例子])當我們做培訓時。
// Un-normalize the data
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
為了將資料恢復到原始範圍(而不是0–1),我們使用規範化時計算的值,但只需反轉操作。
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.datasync()是一種方法,我們可以使用它來獲取儲存在張量中的值的typedarray。這允許我們在常規的javascript中處理這些值。這是通常首選的.data()方法的同步版本。
最後,我們使用tfjs-vis來繪製原始資料和模型中的預測。
將以下程式碼新增到執行函式中。
testModel(model, data, tensorData);
重新整理頁面,現在已經完成啦!
現在你已經學會使用tensorflow.js建立一個簡單的機器學習模型了。這裡是Github儲存庫供參考。
結論
我開始接觸這些是因為機器學習的概念非常吸引我,還有就是我想看看有沒有方法可以讓它在前端開發中實現,我很高興發現tensorflow.js庫可以幫助我實現我的目標。這只是前端開發中機器學習的開始,TensorFlow.js還可以完成很多工作。謝謝你的閱讀!
本文由阿里云云棲社群組織翻譯。
文章原標題《JavaScript for Machine Learning using TensorFlow.js》作者:Priyesh Patel
譯者:麼凹 審校:Viola
原文連結
本文為雲棲社群原創內容,未經