
併發容器學習—LinkedTransferQueue
一、LinkedTransferQueue併發容器
1.LinkedTransferQueue的底層實現
LinkedTransferQueue是一個底層資料結構由連結串列實現的無界阻塞佇列,它與SynchronousQueue中公平模式的實現TransferQueue及其相似,LinkedTransferQueue中儲存的也是操作而不是資料元素。可以對比著學習,更容易理解。先來看看LinkedTransferQueue結點的定義:
static final class Node { //用於標識結點的操作型別,true表示put操作,false表示take操作 final boolean isData; //結點的資料域,take型別的操作,該值為null,配對後則為put中的資料 //put型別的操作,該值為要轉移的資料 volatile Object item; //當前結點的後繼結點 volatile Node next; //等待的執行緒 volatile Thread waiter; // null until waiting //CAS方式更新後繼結點 final boolean casNext(Node cmp, Node val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } //CAS方式更新資料域 final boolean casItem(Object cmp, Object val) { // assert cmp == null || cmp.getClass() != Node.class; return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); } //構造方法 Node(Object item, boolean isData) { UNSAFE.putObject(this, itemOffset, item); // relaxed write this.isData = isData; } //移除出佇列,方便GC final void forgetNext() { UNSAFE.putObject(this, nextOffset, this); } //取消結點,就是本次取消操作 final void forgetContents() { UNSAFE.putObject(this, itemOffset, this); UNSAFE.putObject(this, waiterOffset, null); } //判斷結點的操作是否已經被匹配了,結點的操作被取消也包含在匹配當中 //也就是說這個操作若是被取消了,也認為是匹配過的 final boolean isMatched() { Object x = item; return (x == this) || ((x == null) == isData); } //判斷當前結點的操作是不是未匹配過的REQUEST型別(take)的結點,true代表是 final boolean isUnmatchedRequest() { return !isData && item == null; } //判斷結點的操作型別與其資料(item的值)是否相符合, //例如take操作item值應該是null,put操作item則應該是資料 final boolean cannotPrecede(boolean haveData) { boolean d = isData; Object x; return d != haveData && (x = item) != this && (x != null) == d; } //嘗試匹配一個數據結點,用在移除結點的方法中 final boolean tryMatchData() { // assert isData; Object x = item; if (x != null && x != this && casItem(x, null)) { LockSupport.unpark(waiter); return true; } return false; } // Unsafe mechanics private static final sun.misc.Unsafe UNSAFE; private static final long itemOffset; private static final long nextOffset; private static final long waiterOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = Node.class; itemOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("item")); nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); waiterOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("waiter")); } catch (Exception e) { throw new Error(e); } } }
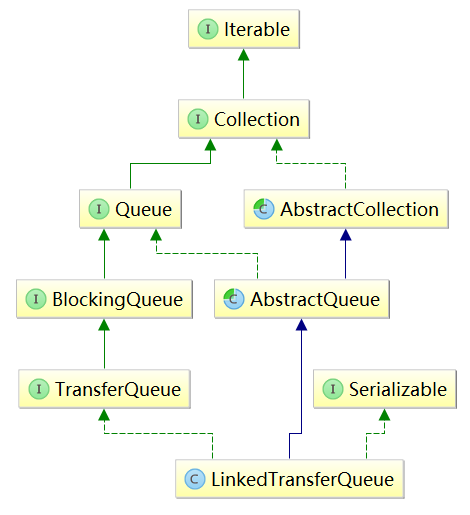
2.LinkedTransferQueue的繼承關係
LinkedTransferQueue的繼承關係如下圖所示,這麼多的父類及介面中,只有一個TransferQueue介面未接觸過,下面我們先來看看這個介面是幹什麼的。
public interface TransferQueue<E> extends BlockingQueue<E> { //嘗試轉移一個數據給一個正在等待消費者,如果沒有等待的消費者立即返回false //轉移失敗的話,這個操作是不會入隊等待被匹配的 boolean tryTransfer(E e); //轉移一個數據給一個消費者,若沒有正在等待的消費者,那麼該轉移操作會阻塞 //等待,或發生異常 void transfer(E e) throws InterruptedException; //在一定時間內嘗試轉移資料給一個消費者,如果沒有正在等待的消費者,那就 //一直嘗試到超時為止 boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException; //是否有消費者在等待 boolean hasWaitingConsumer(); //獲取等待的消費者數量 int getWaitingConsumerCount(); }
3.LinkedTransferQueue中重要的屬性及構造方法
public class LinkedTransferQueue<E> extends AbstractQueue<E> implements TransferQueue<E>, java.io.Serializable { //當前計算機CPU核心數是否大於1 private static final boolean MP = Runtime.getRuntime().availableProcessors() > 1; //結點為佇列中第一個waiter時的自旋次數 private static final int FRONT_SPINS = 1 << 7; //前驅結點正在處理,當前結點需要自旋的次數 private static final int CHAINED_SPINS = FRONT_SPINS >>> 1; //佇列進行清理的閾值 static final int SWEEP_THRESHOLD = 32; //佇列頭結點 transient volatile Node head; //佇列尾結點 private transient volatile Node tail; //移除結點連結失敗(修改結點的next失敗)的次數,當該值大於SWEEP_THRESHOLD //時,會對隊裡進行一次清理,清理掉哪些無效的結點 private transient volatile int sweepVotes; //下面四個值,用於標識xfer方法的型別 /** * NOW:代表不等待消費者,直接返回結果的型別。poll方法和tryTransfer方法中使用 * ASYNC:表示非同步操作,直接新增資料元素到隊尾,不等待匹配,用於offer,add,put方法中 * SYNC:同步操作,等待資料元素被消費者接受,用於take,transfer方法中 * TIMED:延時操作,等待一定時間後在返回匹配的結果,用於待超時時間的poll和tryTransfer方法中 */ private static final int NOW = 0; // for untimed poll, tryTransfer private static final int ASYNC = 1; // for offer, put, add private static final int SYNC = 2; // for transfer, take private static final int TIMED = 3; // for timed poll, tryTransfer public LinkedTransferQueue() { } public LinkedTransferQueue(Collection<? extends E> c) { this(); addAll(c); } }
4.LinkedTransferQueue入隊操作
LinkedTransferQueue中的入隊方法包含有offer,put及add三種,這三個方法本質是都是一樣的,都是呼叫的同一個方法且引數也都一樣,並且因為LinkedTransferQueue是個無界阻塞佇列,容量沒有限制,因此不會出現入隊等待的現象。
public void put(E e) {
xfer(e, true, ASYNC, 0);
}
public boolean offer(E e, long timeout, TimeUnit unit) {
xfer(e, true, ASYNC, 0);
return true;
}
public boolean offer(E e) {
xfer(e, true, ASYNC, 0);
return true;
}
public boolean add(E e) {
xfer(e, true, ASYNC, 0);
return true;
}5.xfer方法分析
xfer方法是LinkedTransferQueue種最核心的一個方法,將其理解清楚,那麼LinkedTransferQueue佇列也就明白了。LinkedTransferQueue與SynchronousQueue中公平模式的實現TransferQueue是一樣的,佇列中存放的不是資料,而是操作(取出資料的操作take和放入資料的操作put)。佇列中既可以存放take操作也可以存放put操作,但是佇列中不能同時存在兩種不同的操作,因為不同的操作會觸發佇列進行配對(操作出隊)。
知道了這些我們再來看xfer方法的大致流程(超時等待部分和操作取消部分暫不分析,等分析原始碼時在說):當佇列為空時,如果有一個執行緒執行take操作,此時對列中是沒有對應的put操作與之匹配的,那麼這個take操作就會入隊,同時阻塞(也可能是自旋)執行這個操作的執行緒以等待匹配操作的到來;同理,空佇列時來的是一個put操作,那麼這個put操作也要入隊阻塞等待匹配的take操作到來。而當佇列不為空時(假設佇列中都是take操作),某一執行緒執行put操作,此時佇列檢測到來了一個與佇列中存放的操作相匹配的操作,那麼就會將隊首操作與到來的操作進行匹配,匹配成功,就會喚醒隊首操作所在的執行緒,同時將已經匹配度額操作移除出隊;而若是某一執行緒執行的是與隊裡中相同的操作,那麼就將該操作直接新增到隊尾。
//1.當e!=null 且haveData為true,how為ASYNC,nanos==0,表示沒有超時設定的立即返回的放入資料的操作(put,add,offer)
//2.當e==null 且haveData為false,how為SYNC,nanos==0,表示沒有超時設定的等待匹配到放入資料的操作(take)
//3.當e!=null 且haveData為true,how為SYNC,nanos==0,表示沒有超時設定的等待匹配到取出資料的操作(transfer)
//4.當e!=null 且haveData為true,how為TIMED,nanos>0,表示設定在超時等待時間內匹配取出資料的
//操作(tryTransfer(E e, long timeout, TimeUnit unit))
//5.當e==null 且haveData為false,how為TIMED,nanos>0,表示設定在超時等待時間內匹配放入資料的
//操作(poll(long timeout, TimeUnit unit))
//6.當e!=null 且haveData為true,how為NOW,nanos==0,表示立即匹配取出資料的操作(tryTransfer)
//7.當e==null 且haveData為false,how為NOW,nanos==0,表示立即匹配放入資料的操作(poll)
private E xfer(E e, boolean haveData, int how, long nanos) {
//判斷本次操作是不是放入資料的操作型別,若是則e不能為null
if (haveData && (e == null))
throw new NullPointerException();
Node s = null; // the node to append, if needed
retry:
for (;;) { // restart on append race
//從head開始匹配
for (Node h = head, p = h; p != null;) { // find & match first node
boolean isData = p.isData; //獲取隊首結點的操作型別
Object item = p.item; //獲取隊首的資料
//判斷隊首結點是否已經被取消或匹配過了且隊首結點的操作型別與其資料內容是否一致
//isData為true對應put操作,則item不能為null,反之item必須為null。
//因此,若是不一致說明p已經不是隊首了,需要重新查詢隊首
if (item != p && (item != null) == isData) { // unmatched
//此處判斷本次操作應該是入隊操作還是匹配操作,即判斷與隊首的操作型別是否一致
//若本次操作與佇列中的操作型別(都是put或都是take)相同,那麼需要將本次操作入隊
//若是不同,那麼需要將隊首結點的操作與本次操作匹配
if (isData == haveData) // can't match
break; //操作型別相同,退出當前迴圈,去執行入隊步驟
//到此,說明隊首操作與本次操作時相互匹配的,那麼接下來需要做配對之後的工作
//嘗試修改p中資料item為e,若修改成功,說明操作匹配成功
//若是修改失敗,說明別其他執行緒搶先匹配了,那麼就往佇列後繼續查詢匹配
if (p.casItem(item, e)) { // match
//本次操作已經與p匹配成功,那麼p之前的結點要麼是被匹配過,要麼已經被取消
//都不能再做為head了,因此,這裡需要將head更新
for (Node q = p; q != h;) {
//獲取後繼結點
Node n = q.next; // update by 2 unless singleton
//判斷head是否還是h,若是,說明head還沒被其他執行緒更新過,那當前執行緒可以嘗試更新
//若是更新成功,說明h結點已經被移除出隊了,那麼就需要將其後繼指標指向自身代表
//這個結點已被移除出隊,方便GC回收
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
//到這說明head已經被更新過,或是當前執行緒要更新head失敗,那麼就重新獲取head並判斷
//head是否為null(是否是空佇列),若是則直接結束迴圈;若不是,再繼續判斷其後繼結點
//是否為null(head是否是佇列中最後一個結點),若是也直接結束迴圈(不需要再繼續嘗試
//更新head);若不是,在判斷這個後繼結點是否已經匹配過,若未匹配,那麼也放棄更新head
//這裡可以總結出,head更新的要求:head不會隨著隊首被匹配就立即更新,head的更新會滯後
//只有當head及其後繼都被匹配後,才會對head進行匹配;也就是說佇列中要有至少兩個結點匹配過
//會觸發head的更新(即鬆弛度>2才更新head)
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter); //p結點匹配成功,喚醒等待該結點的執行緒
return LinkedTransferQueue.<E>cast(item);
}
}
//往p的後繼繼續查詢未匹配的結點
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
//到這說明佇列中的操作與本次操作相同,只能將操作入隊
//判斷本次操作的模式,NOw為不等待,立即返回的模式
if (how != NOW) { // No matches available
//s未初始化的話,進行初始化
if (s == null)
s = new Node(e, haveData);
Node pred = tryAppend(s, haveData); //嘗試新增到隊尾,並返回其前驅
if (pred == null) //返回前驅為null,說明新增失敗,重新開始
continue retry; // lost race vs opposite mode
//新增的結點不為非同步模式,說明是同步或超時模式,那麼要等待匹配
//若為非同步模式,則不需要等待匹配,因為非同步模式必然是add,offer,put
//三個方法,不需要等待
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos);
}
return e; // not waiting
}
}
//結點自環
final void forgetNext() {
UNSAFE.putObject(this, nextOffset, this);
}
//嘗試新增結點到隊尾
private Node tryAppend(Node s, boolean haveData) {
for (Node t = tail, p = t;;) { // move p to last node and append
Node n, u; // temps for reads of next & tail
//判斷佇列是否為空,為空的話,直接更新head結點為s後結束,即空佇列直接入隊
if (p == null && (p = head) == null) {
if (casHead(null, s))
return s; // initialize
}
//判斷結點是否符合入隊要求,即驗證s結點的操作型別與p是否相同
else if (p.cannotPrecede(haveData))
return null; //不同,直接返回null
//判斷p是否有後繼,新增結點是要新增到隊尾的,而tail是可能滯後於隊尾的,
//且其他執行緒也可能搶先更新隊尾,因此若p的後繼不為null,說明當前p不是真正的
//隊尾,需要推進查詢隊尾。
else if ((n = p.next) != null)
p = p != t && t != (u = tail) ? (t = u) : (p != n) ? n : null;
//n為null,說明找到隊尾了,此時需要將p的後繼更新成s,若是更新失敗說明有其
//它執行緒搶先了,那麼就重新獲取隊尾,再嘗試
else if (!p.casNext(null, s))
p = p.next; // 繼續查詢隊尾
//成功將s入隊
else {
//此時,若p不等t,說明t不是隊尾,可以看看tail需不需要更新
if (p != t) { // update if slack now >= 2
/**
* 判斷是否需要更新tail,若是當前的tail離
* 真正的隊尾不超過2個結點,那就暫時不更新tail
* 若是超過的話,就更新tail
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t);
}
return p;
}
}
}
//阻塞或自旋等待匹配
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
//計算截止時間
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread(); //獲取當前執行緒
int spins = -1; // initialized after first item and cancel checks
ThreadLocalRandom randomYields = null; // bound if needed
//死迴圈
for (;;) {
Object item = s.item; //s結點的資料
//判斷s是否被匹配過,未匹配時item==e,匹配過或取消後item就會改變
if (item != e) { // matched
// assert item != s;
//s被匹配過,那麼需要將item設為s本身,且waiter要恢復成null
s.forgetContents(); // avoid garbage
return LinkedTransferQueue.<E>cast(item); //返回資料
}
//判斷s所在的執行緒是否被中斷過或者超時時間是否到了,那麼就需要取消本次s
//結點對應的操作了(將s.item設為s)
if ((w.isInterrupted() || (timed && nanos <= 0)) &&
s.casItem(e, s)) { // cancel
unsplice(pred, s); //將s移除出佇列
return e;
}
//下面都是進行的超時阻塞或者自旋操作
//判斷自旋次數是否初始化過
if (spins < 0) { // establish spins at/near front
//初始化自旋次數,即計算自旋次數
if ((spins = spinsFor(pred, s.isData)) > 0)
randomYields = ThreadLocalRandom.current();
}
else if (spins > 0) { // spin
--spins; //自旋次數遞減
// 生成隨機數來讓出CPU時間
if (randomYields.nextInt(CHAINED_SPINS) == 0)
Thread.yield(); // occasionally yield
}
else if (s.waiter == null) {
s.waiter = w; //設定等待執行緒
}
else if (timed) {
//計算超時等待時間
nanos = deadline - System.nanoTime();
if (nanos > 0L)
LockSupport.parkNanos(this, nanos); //超時阻塞
}
else {
LockSupport.park(this); //阻塞
}
}
}
//將s結點移除出佇列,即解除和前驅結點的連結
final void unsplice(Node pred, Node s) {
//將s.item設為s本身,且waiter要恢復成null
s.forgetContents(); // forget unneeded fields
//當s的前驅不為null,且前驅與s不相同的條件下才能進行解除連結
if (pred != null && pred != s && pred.next == s) {
Node n = s.next; //獲取s結點的後繼
//判斷s是否有後繼(s是否為隊尾),若s有後繼那麼後繼是不是s本身(s是否已匹配
//或取消了),若後繼不是s自身,那麼就嘗試將pred的後繼結點更新成s的後繼n,若
//是更新成功,再判斷pred是否已經被匹配過或取消了
if (n == null || (n != s && pred.casNext(s, n) && pred.isMatched())) {
//更新head
for (;;) { // check if at, or could be, head
Node h = head; //獲取head
//h為pred或s或佇列已空,那就不需要更新了,直接返回
if (h == pred || h == s || h == null)
return; // at head or list empty
//若是h未被匹配過,說明不需要更新,退出當前迴圈
if (!h.isMatched())
break;
//獲取h的後繼
Node hn = h.next;
if (hn == null)
return; // now empty
//只要h未被匹配或取消,就嘗試更新head
if (hn != h && casHead(h, hn))
//將h結點移除出隊,h.next==h
h.forgetNext(); // advance head
}
//s節點被移除後,需要記錄刪除的操作次數,如果超過閥值,則需要清理佇列
if (pred.next != pred && s.next != s) { // 重新檢查移除是否成功
for (;;) { // sweep now if enough votes
int v = sweepVotes; //返回當前刪除次數的記錄
//判斷是否超過閾值,沒超過就更新記錄,超過就將記錄恢復為0
//並且清理佇列
if (v < SWEEP_THRESHOLD) {
if (casSweepVotes(v, v + 1))
break;
}
else if (casSweepVotes(v, 0)) {
sweep(); //清理佇列
break;
}
}
}
}
}
}
//清理佇列
private void sweep() {
//遍歷佇列
for (Node p = head, s, n; p != null && (s = p.next) != null; ) {
//判斷s是否被匹配過,未被匹配過就繼續向後遍歷
if (!s.isMatched())
// Unmatched nodes are never self-linked
p = s;
//s節點被匹配,但是是尾節點,則退出迴圈,隊尾就算被匹配了也不能直接
//移除
else if ((n = s.next) == null) // trailing node is pinned
break;
//判斷s是否已經被移除了,若是,則重新從head開始清理
else if (s == n) // stale
// No need to also check for p == s, since that implies s == n
p = head;
else
p.casNext(s, n); //移除s出佇列
}
}以上就是xfer的全部過程了,一個xfer方法直接包含了LinkedTransferQueue的所有功能,不僅add,put,offer方法是由其實現的,其他的如poll,take,transfer,tryTransfer方法也均是由其實現的,只不過引數不同:
public boolean tryTransfer(E e) {
return xfer(e, true, NOW, 0) == null;
}
public void transfer(E e) throws InterruptedException {
if (xfer(e, true, SYNC, 0) != null) {
Thread.interrupted(); // failure possible only due to interrupt
throw new InterruptedException();
}
}
public boolean tryTransfer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (xfer(e, true, TIMED, unit.toNanos(timeout)) == null)
return true;
if (!Thread.interrupted())
return false;
throw new InterruptedException();
}
public E take() throws InterruptedException {
E e = xfer(null, false, SYNC, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = xfer(null, false, TIMED, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}
public E poll() {
return xfer(null, false, NOW, 0);
}6.LinkedTransferQueue中主要方法流程
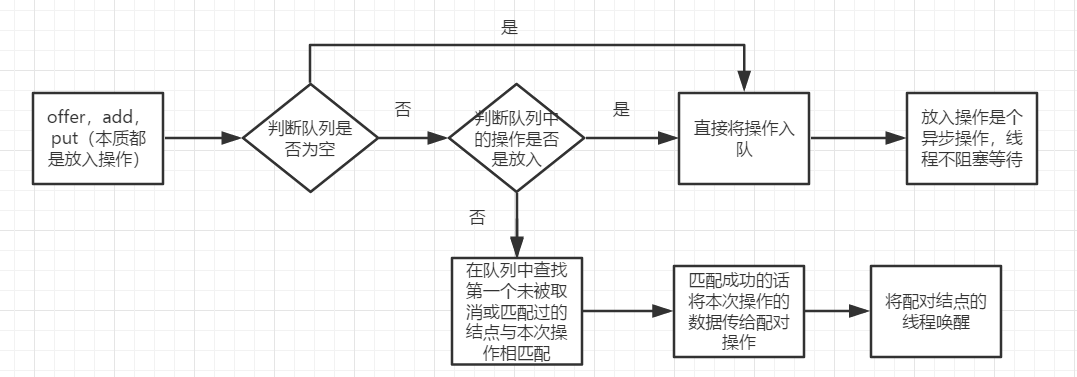
1.offer,add,put三個非同步放入資料的操作的大致過程如下:
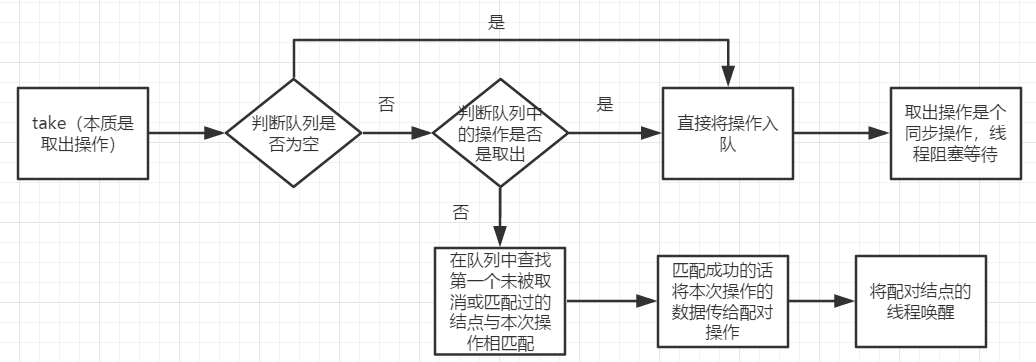
2.take同步取出資料的大致流程如下:
3.transfer同步放入資料的流程大致如下:

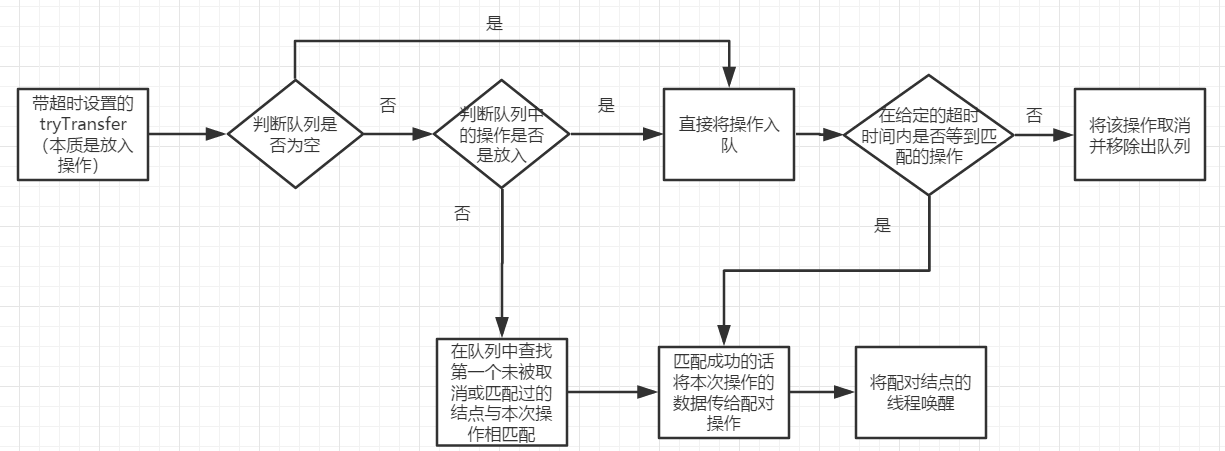
4.tryTransfer帶超時設定的放入資料的流程大致如下:
5.poll帶超時設定的取出資料的流程大致如下:
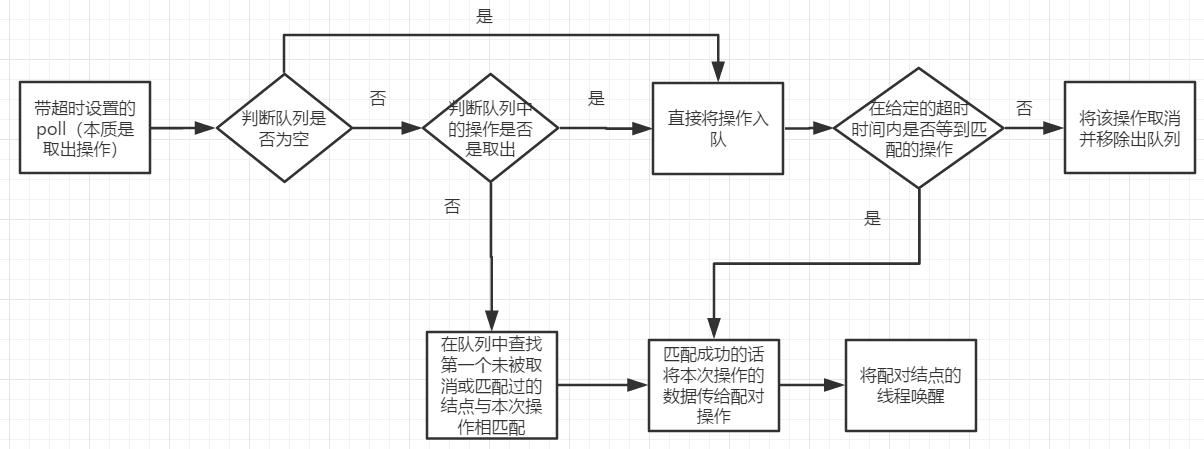
6.tryTransfer不做任何等待放入資料(只做一次放入資料的嘗試,失敗直接結束)的流程大致如下:
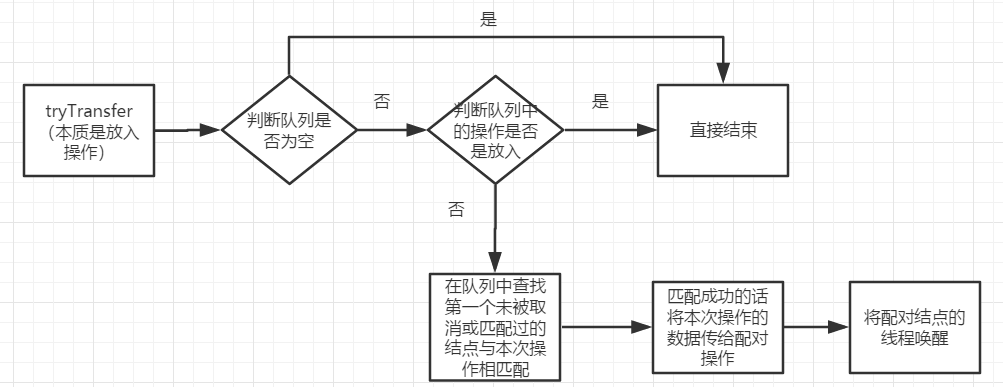
7.poll只進行一次取出資料的操作,失敗直接返回null,大致過程如下:
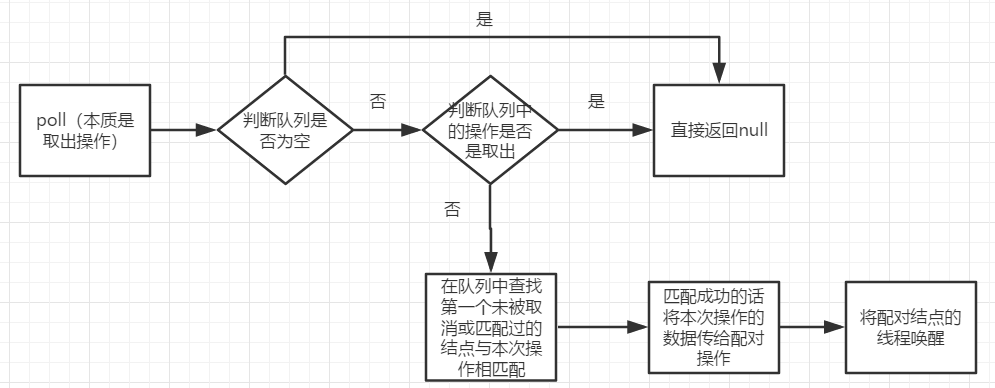
7.其他方法
//查詢佇列中第一個item不為null或結點本身的結點,將其item返回,不移除出佇列
public E peek() {
return firstDataItem();
}
//遍歷佇列查詢item不為null也不指向結點自身的結點,返回其item
private E firstDataItem() {
//遍歷佇列
for (Node p = head; p != null; p = succ(p)) {
Object item = p.item;
if (p.isData) {
if (item != null && item != p)
return LinkedTransferQueue.<E>cast(item);
}
else if (item == null)
return null;
}
return null;
}
//獲取結點的後繼,若後繼為自身(即已被移除出隊),那麼返回head
final Node succ(Node p) {
Node next = p.next;
return (p == next) ? head : next;
}
//返回佇列中的結點數
public int size() {
return countOfMode(true);
}
//計算結點數
private int countOfMode(boolean data) {
int count = 0;
//遍歷佇列計算有效的結點數
for (Node p = head; p != null; ) {
if (!p.isMatched()) {
if (p.isData != data)
return 0;
if (++count == Integer.MAX_VALUE) // saturated
break;
}
Node n = p.next;
if (n != p)
p = n;
else {
count = 0;
p = head;
}
}
return count;
}
//刪除佇列查詢到的第一個item為o的結點
public boolean remove(Object o) {
return findAndRemove(o);
}
private boolean findAndRemove(Object e) {
if (e != null) {
//遍歷佇列查詢刪除
for (Node pred = null, p = head; p != null; ) {
Object item = p.item;
if (p.isData) {
//判斷結點是否是需要刪除的資料
if (item != null && item != p && e.equals(item) &&
p.tryMatchData()) {
unsplice(pred, p); //將結點移除出佇列
return true;
}
}
else if (item == null) //item為null,說明佇列中都是取出資料的操作,不可能有e了
break;
pred = p;
if ((p = p.next) == pred) { // stale
pred = null;
p = head;
}
}
}
return false;
}