
大資料(hadoop-mapreduce程式碼及程式設計模型講解)
阿新 • • 發佈:2019-05-29
MapReduce程式設計模型
MapReduce將整個執行過程分為兩個階段: Map 階段和Reduce階段
Map階段由一定數量的Map Task組成
輸入資料格式解析: InputFormat
輸入資料處理: Mapper
資料分組: Partitioner
Reduce階段由一定數量的Reduce Task組成
資料遠端拷貝
資料按照key排序
資料處理:Reducer
資料輸出格式:OutputFormat
Map階段
InputFormat(預設TextInputFormat)
Mapper
Combiner(local Reducer)
Partitioner
Reduce階段
Reducer
OutputFormat(預設TextOutputFormat)
Java程式設計介面
Java程式設計介面組成;
舊API:所在java包: org.apache.hadoop.mapred
新API:所在java包: org.apache.hadoop.mapreduce
新API具有更好的擴充套件性;
兩種程式設計介面只是暴露給使用者的形式不同而已,內部執行引擎是一樣的;
Java新舊API
從Hadoop1.0.0開始,所有發行版均包含新舊兩類API;
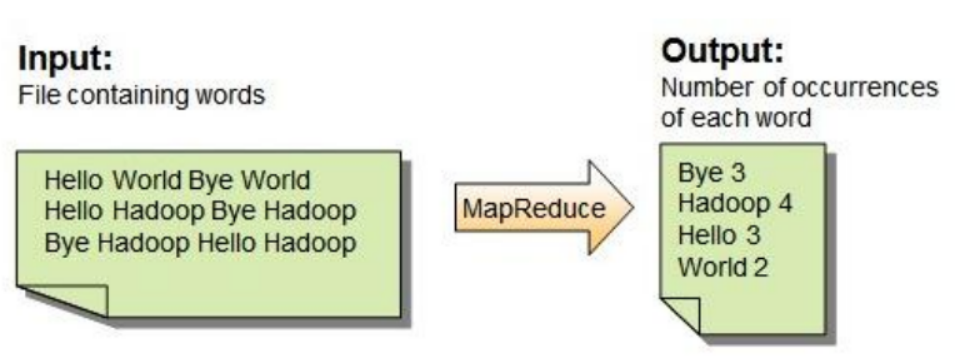
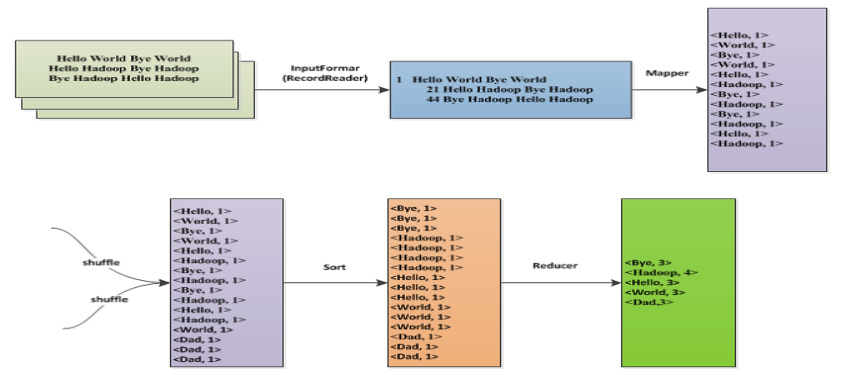
例項1: WordCount問題
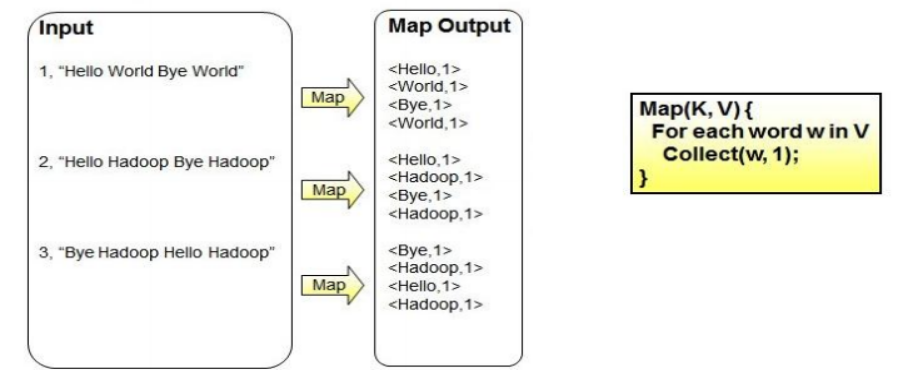
WordCount問題—map階段
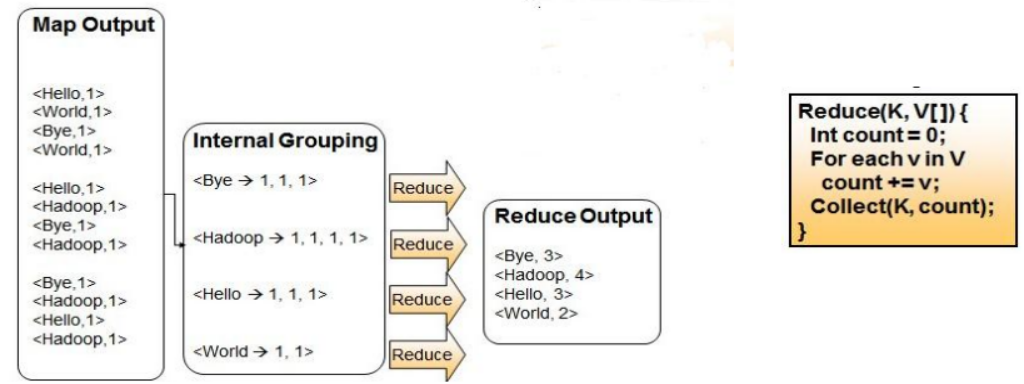
WordCount問題—reduce階段
WordCount問題—mapper設計與實現

WordCount問題—reducer設計與實現

WordCount問題—資料流
示例程式碼
package com.vip; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 單詞統計 * @author huang * */ public class WordCountTest { public static class MyMapper extends Mapper<Object, Text, Text, IntWritable>{ //先來定義兩個輸出,k2,v2 Text k2 = new Text() ; IntWritable v2 = new IntWritable() ; /* * hello you * hello me * * 1.<k1,v2> 就是<0,hello you>,<10,hello me>這樣得形式 * 通過map函式轉換為 * 2.<k2,v2>--> <hello,1><you,1><hello,1><me,1> * */ @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { //對每一行得資料進行處理,拿到單詞 String[] words = value.toString().split(" "); for (String word : words) { k2.set(word); //word就是每行得單詞 v2.set(1); //每個單詞出現得次數就是1 context.write(k2, v2); //輸出 } } } //3.對輸出得所有得k2,v2進行分割槽partition //4.通過shuffle階段之後結果是<hello,{1,1}><me,{1}><you,{1}> //3,4階段都是hadoop框架本身幫我們完成了 //reduce public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //先來定義兩個輸出 IntWritable v3 = new IntWritable() ; int count = 0 ; for (IntWritable value : values) { count += value.get() ; } v3.set(count); //輸出結果資料 context.write(key, v3); } } //我們已經完成了主要得map和reduce的函式編寫,把他們組裝起來交給mapreduce去執行 public static void main(String[] args) throws Exception { //載入配置資訊 Configuration conf = new Configuration() ; //設定任務 Job job = Job.getInstance(conf, "word count") ; job.setJarByClass(WordCountTest.class); //指定job要使用得mapper/reducer業務類 job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); //指定最終輸出得資料得kv型別 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //指定job得輸入原始檔案所在目錄 FileInputFormat.addInputPath(job, new Path(args[0])); //指定job得輸出結果所在目錄 FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1) ; } }
package com.vip;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
//求最大值
public class MapReduceCaseMax extends Configured implements Tool{
//編寫map
public static class MaxMapper extends Mapper<Object, Text, LongWritable, NullWritable>{
//定義一個最小值
long max = Long.MIN_VALUE ;
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//切割字串,預設分隔符空格,製表符
StringTokenizer st = new StringTokenizer(value.toString()) ;
while(st.hasMoreTokens()){
//獲取兩個值
String num1 = st.nextToken() ;
String num2 = st.nextToken() ;
//轉換型別
long n1 = Long.parseLong(num1) ;
long n2 = Long.parseLong(num2) ;
//判斷比較
if(n1 > max){
max = n1 ;
}
if(n2 > max){
max = n2 ;
}
}
}
//
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
}
}
@Override
public int run(String[] args) throws Exception {
/*設定任務和主類*/
Job job = Job.getInstance(getConf(), "MaxFiles") ;
job.setJarByClass(MapReduceCaseMax.class);
/*設定map方法的類*/
job.setMapperClass(MaxMapper.class);
/*設定輸出的key和value的型別*/
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(NullWritable.class);
/*設定輸入輸出引數*/
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
/*提交作業到叢集並等待任務完成*/
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1 ;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new MapReduceCaseMax(), args) ;
System.exit(res);
}
}