
大資料案例(七)——MapReduce之map端表合併(Distributedcache)
一、前期準備
- 由於本案例是在案例六的基礎上做的優化,所以需求及資料輸入輸出請參考案例六;初次之外需要拷貝pd.txt檔案在本地電腦J盤的根目錄下以做參考
- 本案例只需要上傳order.txt到HDFS上即可-"/user/hadoop/order_productv2/input"
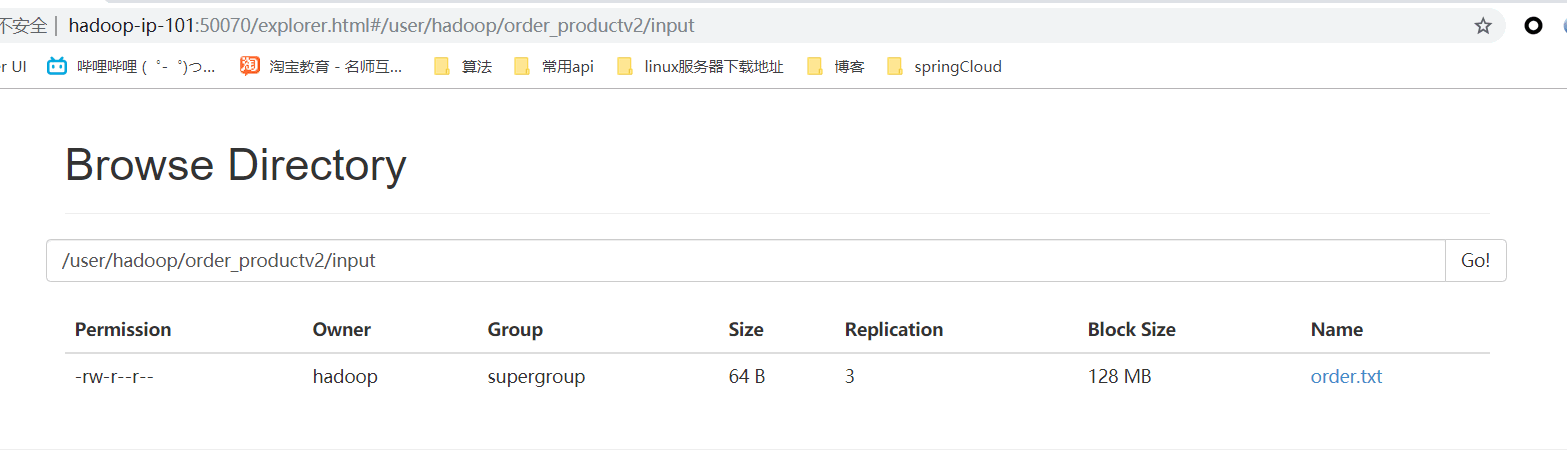
二、程式碼
- DistributedCacheDriver.java
package com.ittzg.hadoop.orderproductv2; import com.ittzg.hadoop.orderproduct.OrderAndProductBean; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.HashMap; import java.util.Map; /** * @email: [email protected] * @author: ittzg * @date: 2019/7/6 20:46 */ public class DistributedCacheDriver { public static class DistributedCacheMapper extends Mapper<LongWritable,Text,OrderAndProductBean,NullWritable>{ Map<String,String> map = new HashMap<String,String>(); @Override protected void setup(Context context) throws IOException, InterruptedException { //獲取快取在中的檔案 BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("j:/pd.txt"))); String line; while(StringUtils.isNotEmpty(line = reader.readLine())){ // 2 切割 String[] fields = line.split("\t"); // 3 快取資料到集合 System.out.println(fields[0]+":"+fields[0].trim().length()); map.put(fields[0], fields[1]); } // 4 關流 reader.close(); } OrderAndProductBean orderAndProductBean= new OrderAndProductBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { System.out.println(map.toString()); String line = value.toString(); String[] split = line.split("\t"); orderAndProductBean.setOrderId(split[0]); orderAndProductBean.setPdId(split[1]); orderAndProductBean.setAccount(split[2]); orderAndProductBean.setPdName(map.get(split[1])); orderAndProductBean.setFlag("0"); context.write(orderAndProductBean,NullWritable.get()); } } public static class OrderProDuctReduce extends Reducer<OrderAndProductBean,NullWritable,OrderAndProductBean,NullWritable>{ @Override protected void reduce(OrderAndProductBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } } public static void main(String[] args) throws Exception{ // 設定輸入輸出路徑 String input = "hdfs://hadoop-ip-101:9000/user/hadoop/order_productv2/input"; String output = "hdfs://hadoop-ip-101:9000/user/hadoop/order_productv2/output"; Configuration conf = new Configuration(); conf.set("mapreduce.app-submission.cross-platform","true"); Job job = Job.getInstance(conf); // job.setJar("F:\\big-data-github\\hadoop-parent\\hadoop-order-product\\target\\hadoop-order-product-1.0-SNAPSHOT.jar"); job.setMapperClass(DistributedCacheMapper.class); job.setReducerClass(OrderProDuctReduce.class); job.setMapOutputKeyClass(OrderAndProductBean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(OrderAndProductBean.class); job.setOutputValueClass(NullWritable.class); // 6 載入快取資料 job.addCacheFile(new URI("file:/j:/pd.txt")); FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop"); Path outPath = new Path(output); if(fs.exists(outPath)){ fs.delete(outPath,true); } FileInputFormat.addInputPath(job,new Path(input)); FileOutputFormat.setOutputPath(job,outPath); boolean bool = job.waitForCompletion(true); System.exit(bool?0:1); } }
三、執行結果
- 網頁瀏覽
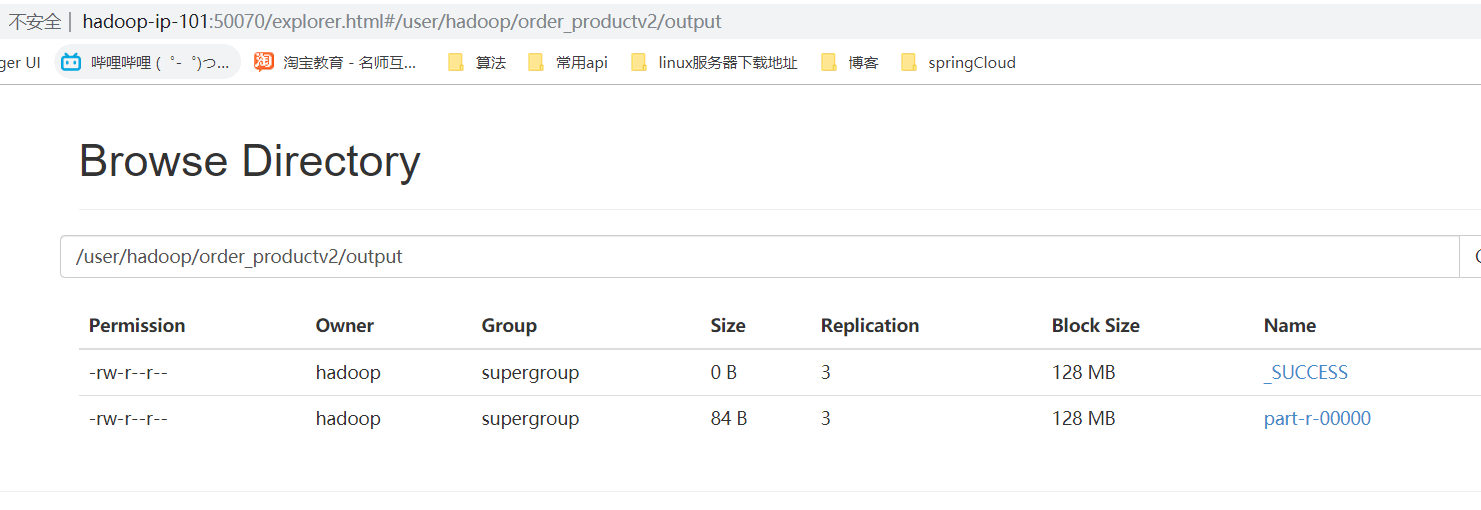
- 檔案內容下載瀏覽
相關推薦
大資料案例(七)——MapReduce之map端表合併(Distributedcache)
一、前期準備 由於本案例是在案例六的基礎上做的優化,所以需求及資料輸入輸出請參考案例六;初次之外需要拷貝pd.txt檔案在本地電腦J盤的根目錄下以做參考 本案例只需要上傳order.txt到HDFS上即可-"/user/hadoop/order_productv2/input" 二
大資料案例(四)——MapReduce將檔案按照訂單號分成若干個小檔案
一、需求:將檔案按照訂單號分成若干個小檔案 二、資料準備 資料準備 Order_0000001 Pdt_01 222.8 Order_0000002 Pdt_05 722.4 Order_0000001 Pdt_05 25.8 Order_0000003 Pdt_01 222.8 Order_
Thinking in BigData(八)大資料Hadoop核心架構HDFS+MapReduce+Hbase+Hive內部機理詳解
純乾貨:Hadoop核心架構HDFS+MapReduce+Hbase+Hive內部機理詳解。 通過這一階段的調研總結,從內部機理的角度詳細分析,HDFS、MapReduce、Hbase、Hive是如何執行,以及基於Hadoop資料倉庫的構建和分散式資
大資料各子專案的環境搭建之建立與刪除軟連線(博主推薦)
建立軟連線,好處可以處理多個版本的需要,方便環境變數的配置。相當於windows下的快捷方式! 博主,我這裡以jdk為例,對於大資料的其他子專案的搭建,一樣的操作。方便!這裡我不多贅述。 如何建立jdk1.7版本的軟連結? [[email protect
Spark修煉之道(基礎篇)——Linux大資料開發基礎:第十三節:Shell程式設計入門(五)
本節主要內容 while expression do command command done (1)計數器格式 適用於迴圈次數已知或固定時 root@sparkslave02:~/ShellLearning/Chapter13# vim w
大資料案例(九)——自定義Outputformat
一、概述 要在一個mapreduce程式中根據資料的不同輸出兩類結果到不同目錄,這類靈活的輸出需求可以通過自定義outputformat來實現。 自定義outputformat, 改寫recordwriter,具體改寫輸出資料的方法write() 二、案例需求 需求:過濾輸入的log日誌中是否包含ba
在cm安裝的大資料管理平臺中整合impala之後讀取hive表中的資料的設定(hue當中執行impala的資料查詢)
今天裝了CM叢集,在叢集當中集成了impala,hive。然後一直覺得認為impala自動共享hive的元資料,最後發現好像並不是這樣的,需要經過一個同步元資料的操作才能實現資料的同步。 具體的做法如下: (1)安裝好hive和impala,然後在hive當中建立目標資料庫,建立一張表
《Oracle大資料解決方案》學習筆記4——選擇Appliance的理由(Why an Appliance?)
雖然這章的內容有點像Oracled的市場宣傳資料,但也因此學習了一些大資料相關硬體的知識。 1. Oracle大資料機(Big Data Appliance)X3-2硬體規格(全機架配置,18個節點) 2. Oracle大資料機全機架配置環境規格 3. Orac
Hadoop學習記錄(七、MapReduce檔案分解與合成)
1.將若干個小檔案打包成順序檔案 public class SmallFilesToSequenceFileConverter extends Configured implements Tool { static class SequenceFileMapper
機器學習和python學習之路史上吐血整理機器學習python大資料技術書從入門到進階最全本(書籍推薦珍藏版)
“機器學習/深度學習並不需要很多數學基礎!”也許你在不同的地方聽過不少類似這樣的說法。對於鼓勵數學基礎不好的同學入坑機器學習來說,這句話是挺不錯的。不過,機器學習理論是與統計學、概率論、電腦科學、演算法等方面交叉的領域,對這些技術有一個全面的數學理解對理解演算法的內部工作機
大資料崗位集合——架構師、基礎研發、平臺研發(高階、資深)上海、北京、蘇州**
我是獵頭聞慄,以下是目前最新大資料類崗位,如果有感興趣的同學歡迎及時聯絡我 電話(微信)15809212974 簡歷傳送郵箱:[email protected] 【職位1】:大資料基礎架構研發工程師 【地點】:蘇州 【公司】:思必馳——專注智慧硬體的語
最新大資料24期實戰專案 9天 附課件原始碼(完整版)
課程目錄: 第一天: 01.傳統廣告回顧 02.幾個問題思考 03.廣告的表現形式 04.名詞解釋 05.DSP原理圖 06.DSP業務流程 07.DMP專案背景 08.DMP業務流程----重要 09.日誌格式介紹 10.需求一日誌轉parquet檔案 第二天: 01.
大資料案例之OD線分析
我們從網路上爬取了2013年到2017年芝加哥每一輛計程車的每一單行程資料,資料內容示例如圖一,包含了計程車ID,行程ID,上下車時間,上下車座標,行程耗時,費用以及支付方式等資訊。有了這些資料,我們就可以對其進行資料探勘分析,找到打車需求最旺的區域
linux核心分析--核心中使用的資料結構之雜湊表hlist(三)
前言: 1.基本概念: 散列表(Hash table,也叫雜湊表),是根據關鍵碼值(Key value)而直接進行訪問的資料結構。也就是說,它通過把關鍵碼值對映到表中一個位置來訪問記錄,以加快查詢的速度。這個對映函式叫做雜湊函式,存放記錄的陣列叫做散列表。 2. 常用的構造雜湊函式的方法
Hadoop原始碼分析(2)————MapReduce之MapTask
MapTask(Hadoop2.7.3) MapTask.java繼承於Task,是hadoop中Map節點主要所做的主要流程。 一般被jvmtask初始化或者在MapTaskAttemptImpl被初始化。其主要流程寫在run()方法中。 run()方法
程序猿的量化交易之路(27)--Cointrader之PriceData價格數據(14)
time abstract ansi crypto ket pub return nds set 轉載須註明出處:http://blog.csdn.net/minimicall?viewmode=contents,http://cloudtrade.top/ Pr
POJ 3468 A Simple Problem with Integers(線段樹模板之區間增減更新 區間求和查詢)
return string ali accept numbers other map nts contain A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 13107
學習大資料技術,Hive實踐分享之儲存和壓縮的坑
在學習大資料技術的過程中,HIVE是非常重要的技術之一,但我們在專案上經常會遇到一些儲存和壓縮的坑,本文通過科多大資料的武老師整理,分享給大家。 大家都知道,由於叢集資源有限,我們一般都會針對資料檔案的「儲存結構」和「壓縮形式」進行配置優化。在我實際檢視以後,發現叢集的檔案儲存格式為Parque
【大資料入門二——yarn和mapreduce】
連續幾天夜裡加餐,讓我想起了新兵連的夜訓,在你成為合格戰士之前,你必須經歷新兵連的過程,,,,其實每個行業都有一個屬於它自己的新兵連,不經歷此處的磨練,你難以在這個行業立足,我承認先天的資本,但我更相信後天的努力,也許有的人奮鬥一生都沒有達到他人的起點,我為他人荒廢人生而感到可恥,為此人奮鬥
細說Mammut大資料系統測試環境Docker遷移之路
歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 前言 最近幾個月花了比較多精力在專案的測試環境Docker遷移上,從最初的docker“門外漢”到現在組裡的同學(大部分測試及少數的開發)都可以熟練地使用docker環境開展測試工作,中間也積累了一些經驗和踩過不少坑,藉此2017覆盤的機會,總結一下整個環