
阿里雲InfluxDB® Raft HybridStorage實現方案
背景
阿里雲InfluxDB®是阿里雲基於開源版InfluxDB打造的一款時序資料庫產品,提供更穩定的持續執行狀態、更豐富強大的時序資料計算能力。在現有的單節點版本之外,阿里雲InfluxDB®團隊還將推出多節點的高可用版本。
我們知道現有的開源版InfluxDB只提供單節點的能力,早期開源的叢集版本功能不完善、且社群不再提供更新與支援。經過對官網商業版InfluxDB現有文件的研究,我們猜測在商業版InfluxDB叢集方案中,meta資訊叢集是基於一致性協議Raft做同步的,而資料是非同步複製的。這種分離的方式雖然有優點,但也引起了一系列的一致性問題,在一些公開的文件中,官方也承認這種資料複製方案並不令人滿意。
因此,團隊在參考多項技術選型後,決定採用最為廣泛使用並有較長曆史積累的ETCD/Raft作為核心元件實現阿里雲InfluxDB®的Raft核心,對使用者所有的寫入或一致性讀請求直接進行Raft同步(不做meta資訊同步與資料寫入在一致性過程中的拆分),保證多節點高可用版本擁有滿足強一致性要求的能力。
有幸筆者參與到多節點的高可用版本的開發中,期間遇到非常多的挑戰與困難。其中一項挑戰是ETCD的Raft框架移植過程中,在移除了ETCD自身較為複雜、對時序資料庫沒有太多作用的Raft日誌模組後,所帶來的一系列問題。本文就業界Raft日誌的幾種不同實現方案做討論,並提出一種自研的Raft HybridStorage方案。
業內方案
ETCD
由於我們採用了ETCD/Raft的方案,繞不開討論一下ETCD本家的Raft日誌實現方式。
官網對Raft的基本處理流程總結參考下圖所示,協議細節本文不做擴充套件:
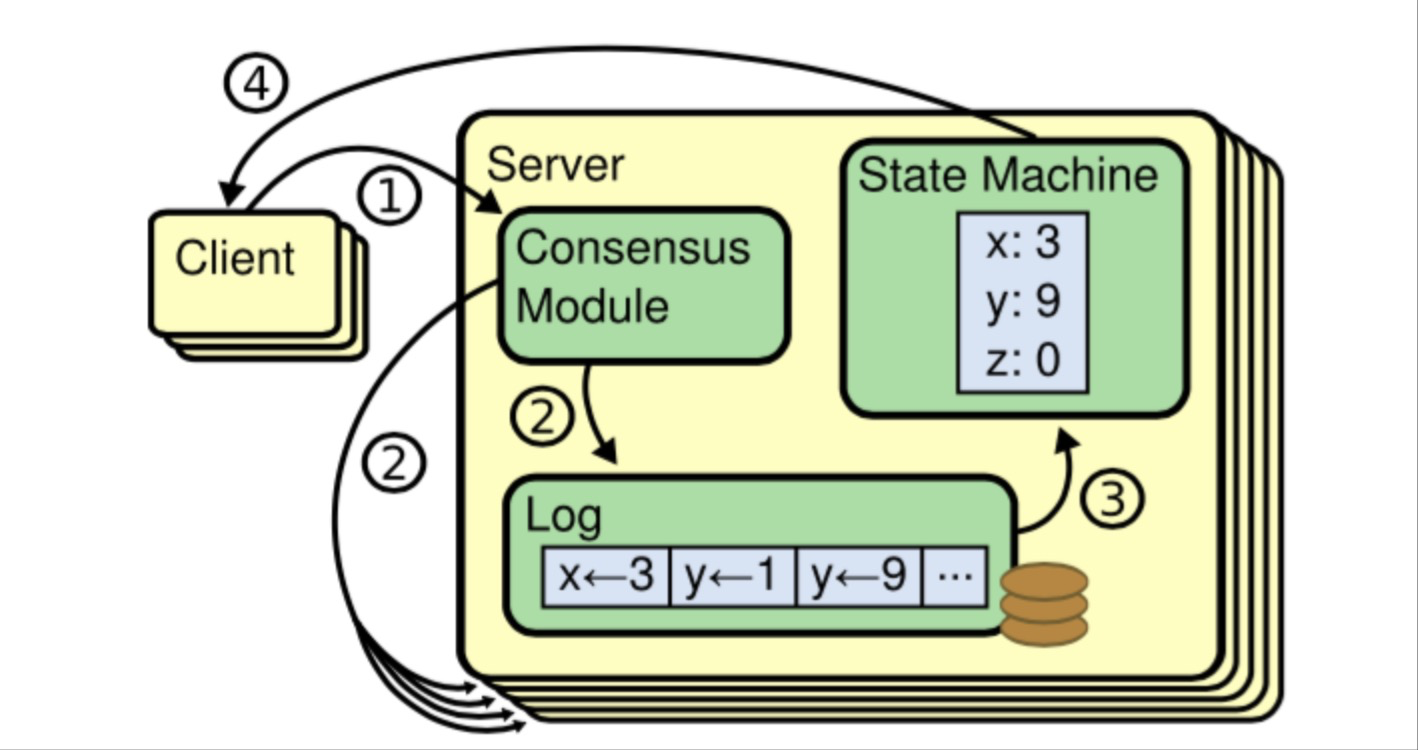
對於ETCD的Raft日誌,主要包含兩個主要部分:檔案部分(WAL)、記憶體儲存部分(MemoryStorage)。
檔案部分(WAL),是ETCD Raft過程所用的日誌檔案。Raft過程中收到的日誌條目,都會記錄在WAL日誌檔案中。該檔案只會追加,不會重寫和覆蓋。
記憶體儲存部分(MemoryStorage),主要用於儲存Raft過程用到的日誌條目一段較新的日誌,可能包含一部分已共識的日誌和一些尚未共識的日誌條目。由於是記憶體維護,可以靈活的重寫替換。MemoryStorage有兩種方式清理釋放記憶體:第一種是compact操作,對appliedId之前的日誌進行清理,釋放記憶體;第二種是週期snapshot操作,該操作會建立snapshot那一時刻的ETCD全域性資料狀態並持久化,同時清理記憶體中的日誌。
在最新的ETCD 3.3程式碼倉庫中,ETCD已經將Raft日誌檔案部分(WAL)和Raft日誌記憶體儲存部分(MemoryStorage)都抽象提升到了與Raft節點(Node)、Raft節點id以及Raft叢集其他節點資訊(*membership.RaftCluster)平級的Server層級,這與老版本的ETCD程式碼架構有較大區別,在老版本中Raft WAL與MemoryStorage都僅僅只是Raft節點(Node)的成員變數。
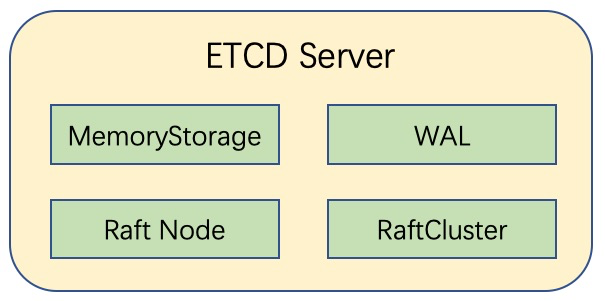
一般情況下,一條Raft日誌的檔案部分與記憶體儲存部分配合產生作用,寫入時先寫進WAL,保證持久化;隨之馬上追加到MemoryStorage中,保證熱資料的高效讀取。
無論是檔案部分還是記憶體儲存部分,其儲存的主要資料結構一致,都是raftpb.Entry。一條log Entry主要包含以下幾個資訊:
| 引數 | 描述 |
|---|---|
| Term | leader的任期號 |
| Index | 當前日誌索引 |
| Type | 日誌型別 |
| Data | 日誌內容 |
此外,ETCD Raft日誌的檔案部分(WAL)還會儲存針對ETCD設計的一些額外資訊,比如日誌型別、checksum等等。
CockroachDB
CockroachDB是一款開源的分散式資料庫,具有NoSQL對海量資料的儲存管理能力,又保持了傳統資料庫支援的ACID和SQL等,還支援跨地域、去中 心、高併發、多副本強一致和高可用等特性。
CockroachDB的一致性機制也是基於Raft協議:單個Range的多個副本通過Raft協議進行資料同步。Raft協議將所有的請求以Raft Log的形式序列化並由Leader同步給Follower,當絕大多數副本寫Raft Log成功後,該Raft Log會標記為Committed狀態,並Apply到狀態機。
我們來分析一下CockroachDB Raft機制的關鍵程式碼,可以很明顯的觀察到也是從鼻祖ETCD的Raft框架移植而來。但是CockroachDB刪除了ETCD Raft日誌的檔案儲存部分,將Raft日誌全部寫入RocksDB,同時自研一套熱資料快取(raftentry.Cache),利用raftentry.Cache與RocksDB自身的讀寫能力(包括RocksDB的讀快取)來保證對日誌的讀寫效能。
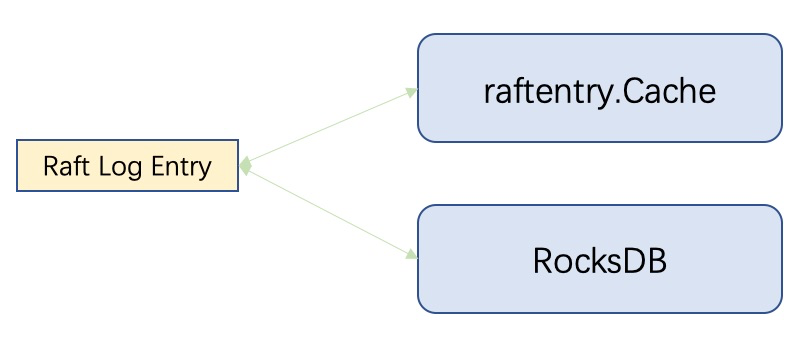
此外,Raft流程中的建立snapshot操作也是直接儲存到RocksDB。這樣實現的原因,個人推測是可能由於CockroachDB底層資料儲存使用的就是RocksDB,直接使用RocksDB的能力讀寫WAL或者存取snapshot相對簡單,不需要再額外開發適用於CockroachDB特性的Raft日誌模組了。
自研HybridStorage
移除snapshot
在阿里雲InfluxDB多節點高可用方案實現過程中,我們採用了ETCD/Raft作為核心元件,根據移植過程中的探索與InfluxDB實際需要,移除了原生的snapshot過程。同時放棄原生的日誌檔案部分WAL,而改用自研方案。
為什麼移除snapshot呢?原來在Raft的流程中,為了防止Raft日誌的無限增加,會每隔一段時間做snapshot,早於snapshot index的Raft日誌請求,將直接用snapshot迴應。然而我們的單Raft環架構如果要做snapshot,就是對整個InfluxDB做,將非常消耗資源和影響效能,而且過程中要鎖死整個InfluxDB,這都是不能讓人接受的。所以我們暫時不啟用snapshot功能,而是儲存固定數量的、較多的Raft日誌檔案備用。
自研的Raft日誌檔案模組會週期清理最早的日誌防止磁碟開銷過大,當某個節點下線的時間並不過長時,其他正常節點上儲存的日誌檔案如果充足,則足夠滿足它追取落後的資料。但如果真的發生單節點宕機太長,正常節點的日誌檔案已出現被清理而不足故障節點追取資料時,我們將利用InfluxDB的backup和restore工具,將落後節點還原至被Raft日誌涵蓋的較新的狀態,然後再做追取。
在我們的場景下,ETCD自身的WAL模組並不適用於InfluxDB。ETCD的WAL是純追加模式的,當故障恢復時,正常節點要相應落後節點的日誌請求時,就有必要分析並提取出相同index且不同term中那條最新的日誌,同時InfluxDB的一條entry可能包含超過20M的時序資料,這對於非kv模式的時序資料庫而言是非常大的磁碟開銷。
HybridStorage設計
我們自研的Raft日誌模組命名為HybridStorage,即意為記憶體與檔案混合存取,記憶體保留最新熱資料,檔案保證全部日誌落盤,記憶體、檔案追加操作高度一致。
HybridStorage的設計思路是這樣的:
(1)保留MemoryStorage:為了保持熱資料的讀取效率,記憶體中的MemoryStorage會保留作為熱資料cache提升效能,但是週期清理其中最早的資料,防止記憶體消耗過大。
(2)重新設計WAL:WAL不再是像ETCD那樣的純追加模式、也不需要引入類似RocksDB這樣重的讀寫引擎。新增的日誌在MemoryStorage與WAL都會儲存,WAL檔案中最新內容始終與MemoryStorage保持完全一致。
一般情況下,HybridStorage新增不同index的日誌條目時,需要在寫記憶體日誌時同時操作檔案執行類似的增減。正常寫入流程如下圖所示:
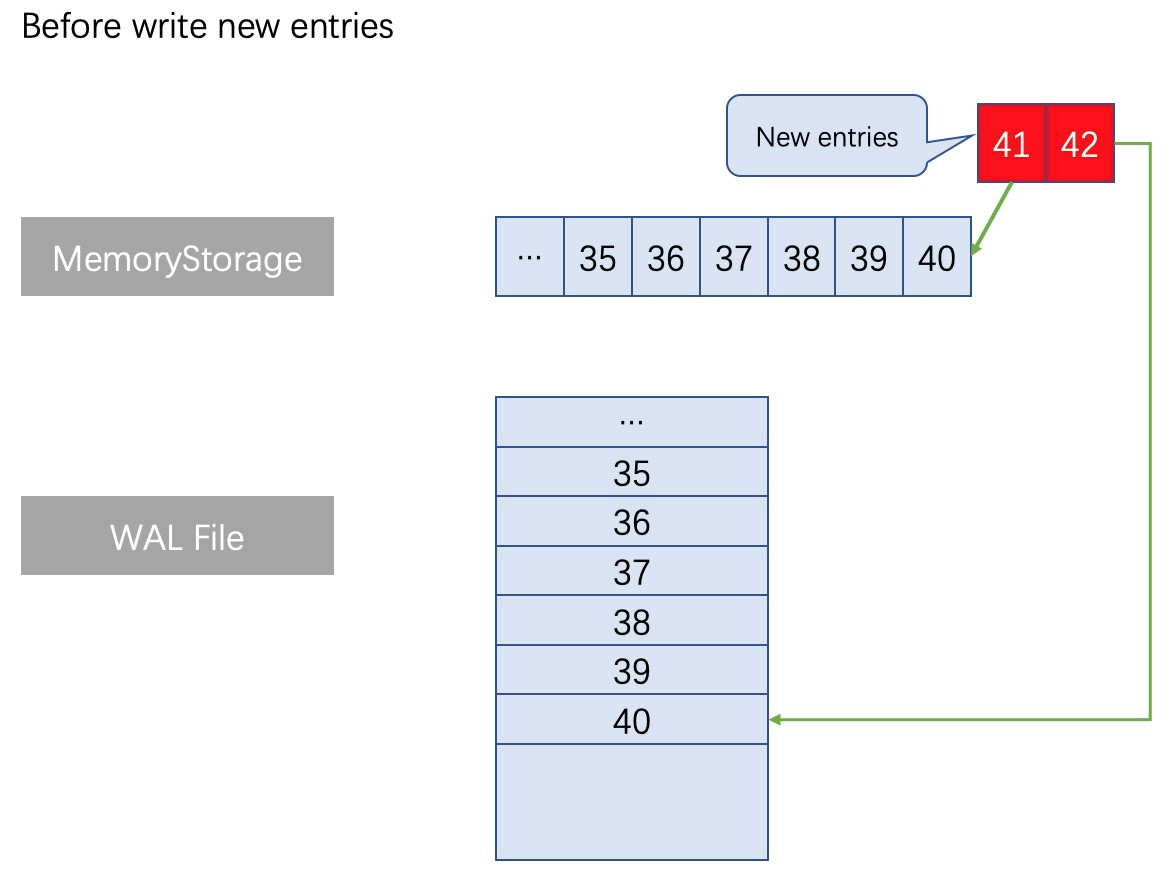
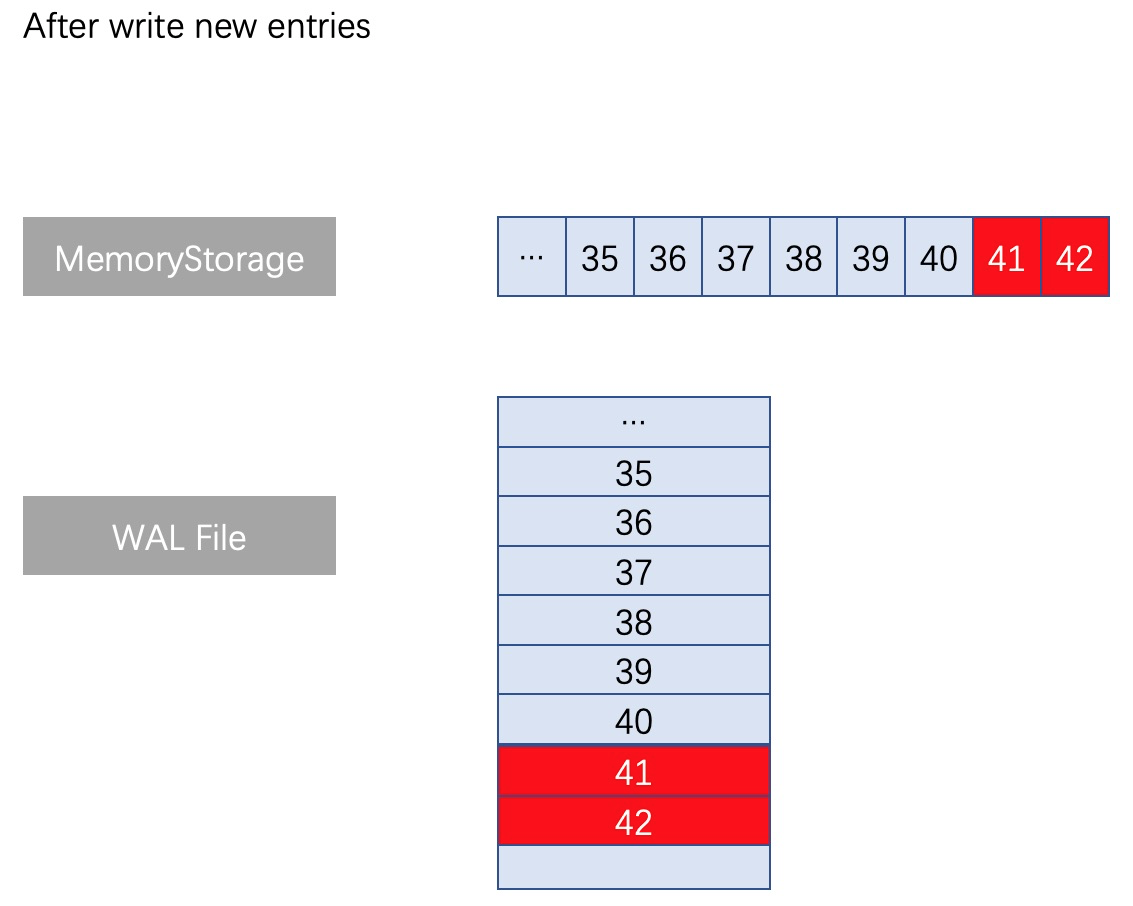
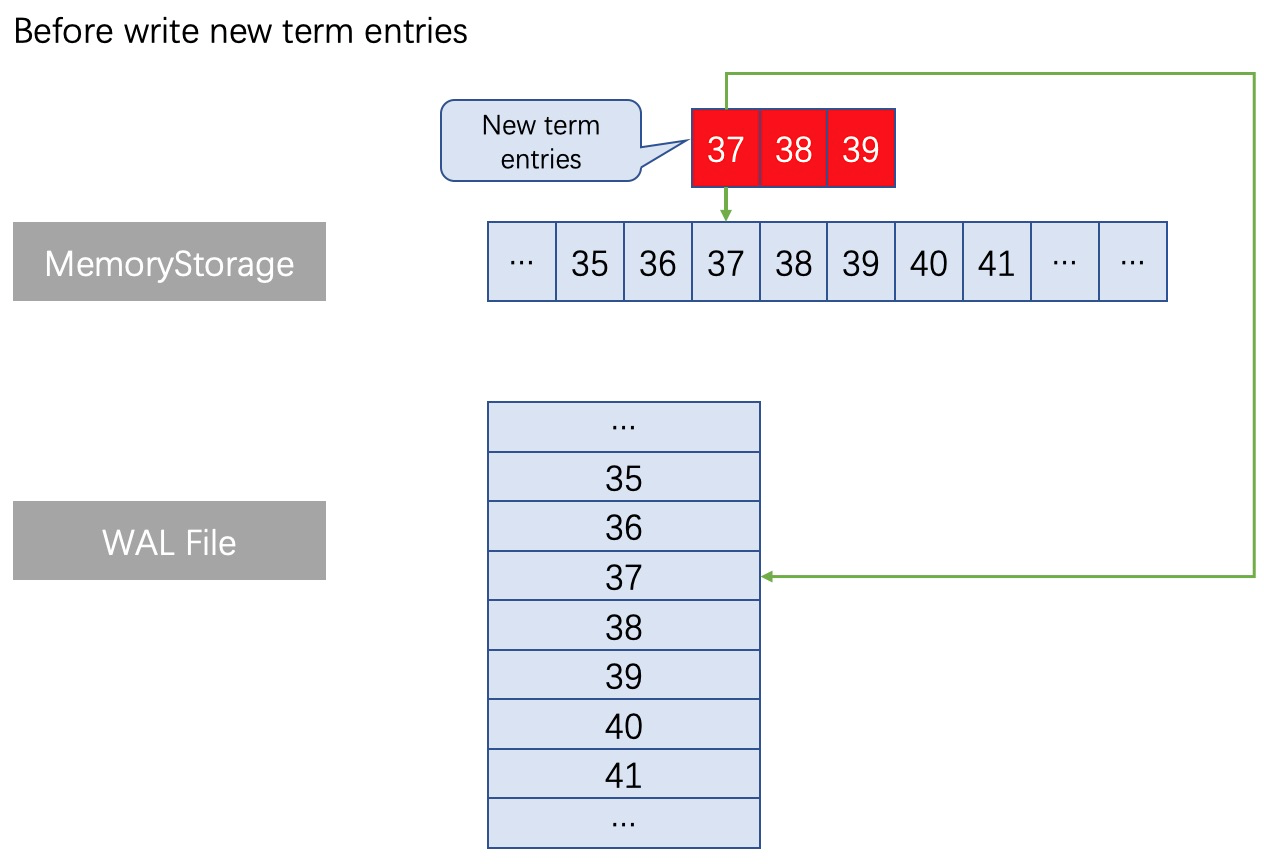
當出現了同index不同term的日誌條目的情況,此時執行truncate操作,截斷對應檔案位置之後一直到檔案尾部的全部日誌,然後重新用append方式寫入最新term編號的日誌,操作邏輯上十分清晰,不存在Update檔案中間的某個位置的操作。
例如在一組Raft日誌執行append操作時,出現瞭如下圖所示的同index(37、38、39)不同term的日誌條目的情況。在MemoryStorage的處理方式是:找到對應index位置的記憶體位置(記憶體位置37),並拋棄從位置A以後的全部舊日誌佔用的記憶體資料(因為在Raft機制中,這種情況下記憶體位置37以後的那些舊日誌都是無效的,無需保留),然後拼接上本次append操作的全部新日誌。在自研WAL也需要執行類似的操作,找到WAL檔案中對應index的位置(檔案位置37),刪除從檔案位置37之後的所有檔案內容,並寫入最新的日誌。如下圖分析:
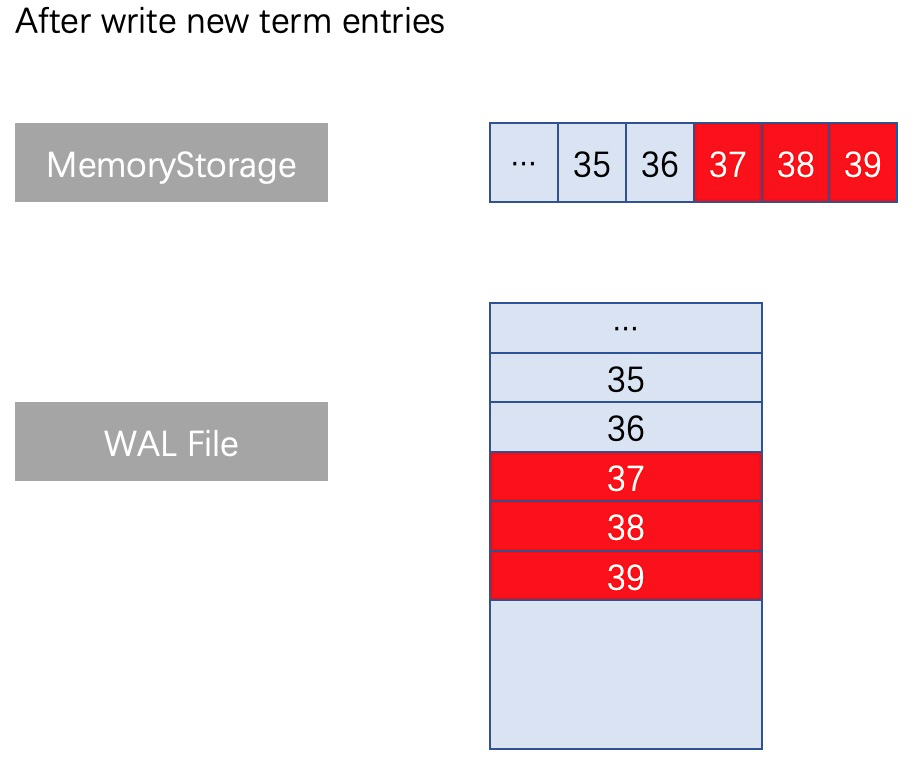
方案對比
ETCD的方案,Raft日誌有2個部分,檔案與記憶體,檔案部分因為只有追加模式,因此並不是每一條日誌都是有效的,當出現同index不同term的日誌條目時,只有最新的term之後的日誌是生效的。配合snapshot機制,非常適合ETCD這樣的kv儲存系統。但對於InfluxDB高可用版本而言,snapshot將非常消耗資源和影響效能,而且過程中要鎖死整個InfluxDB。同時,一次Raft流程的一條entry可能包含超過20M的時序資料。所以這種方案不適合。
CockroachDB的方案,看似偷懶使用了RocksDB的能力,但因其底層儲存引擎也是RocksDB,所以無何厚非。但對於我們這樣需要Raft一致性協議的時序資料庫而言,引入RocksDB未免過重了。
自研的Raft HybridStorage是比較符合阿里雲InfluxDB®的場景的,本身模組設計輕便簡介,記憶體保留了熱資料快取,檔案使用接近ETCD append only的方式,遇到同index不同term的日誌條目時執行truncate操作,刪除冗餘與無效資料,降低了磁碟壓力。
總結
本文對比了業內常見的兩種Raft日誌的實現方案,也展示了阿里雲InfluxDB®團隊自研的HybridStorage方案。在後續開發過程中,團隊內還會對自研Raft HybridStorage進行多項優化,例如非同步寫、日誌檔案索引、讀取邏輯優化等等。也歡迎讀者提出自己的解決方案。相信阿里雲InfluxDB®團隊在技術積累與沉澱方面會越做越好,成為時序資料庫技術領導者。
作者:德施
原文連結
本文為雲棲社群原創內容,未經