
helm安裝kafka叢集並測試其高可用性
介紹
Kafka是由Apache軟體基金會開發的一個開源流處理平臺,由Scala和Java編寫。Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者在網站中的所有動作流資料。 這種動作(網頁瀏覽,搜尋和其他使用者的行動)是在現代網路上的許多社會功能的一個關鍵因素。 這些資料通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 對於像Hadoop一樣的日誌資料和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka的目的是通過Hadoop的並行載入機制來統一線上和離線的訊息處理,也是為了通過叢集來提供實時的訊息。
一、KAFKA
體系結構圖:

- Producer: 生產者,也就是傳送訊息的一方。生產者負責建立訊息,通過zookeeper找到broker,然後將其投遞到 Kafka 中。
- Consumer: 消費者,也就是接收訊息的一方。通過zookeeper找對應的broker 進行消費,進而進行相應的業務邏輯處理。
- Broker: 服務代理節點。對於 Kafka 而言,Broker 可以簡單地看作一個獨立的 Kafka 服務節點或 Kafka 服務例項。大多數情況下也可以將 Broker 看作一臺 Kafka 伺服器,前提是這臺伺服器上只部署了一個 Kafka 例項。一個或多個 Broker 組成了一個 Kafka 叢集。一般而言,我們更習慣使用首字母小寫的 broker 來表示服務代理節點
Send訊息流程圖:
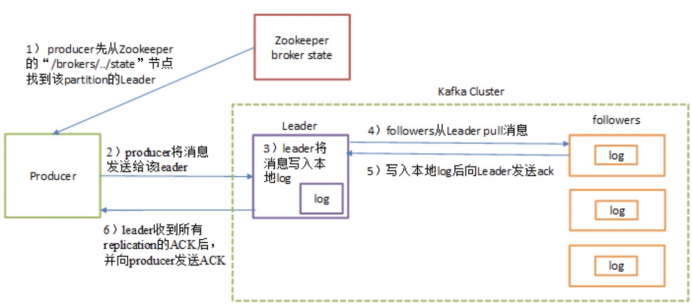
Kafka多副本(Replica)機制:
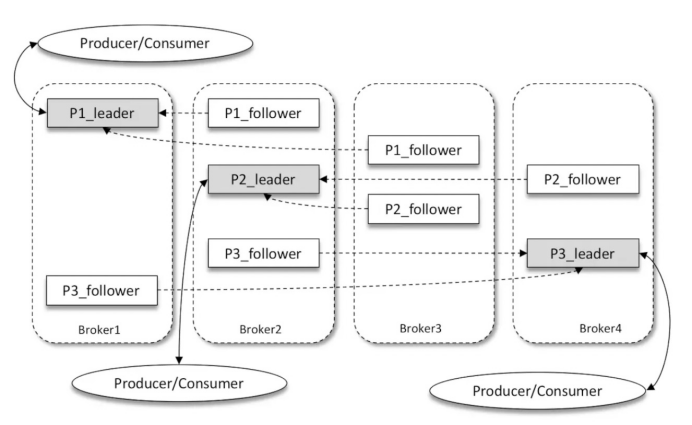
如上圖所示,Kafka 叢集中有4個 broker,某個主題中有3個分割槽,且副本因子(即副本個數)也為3,如此每個分割槽便有1個 leader 副本和2個 follower 副本。生產者和消費者只與 leader 副本進行互動,而 follower 副本只負責訊息的同步,很多時候 follower 副本中的訊息相對 leader 副本而言會有一定的滯後。
二、Zookeeper
ZooKeeper是一個分散式的,開放原始碼的分散式應用程式協調服務,是Google的Chubby一個開源的實現,是Hadoop和Hbase的重要元件。它是一個為分散式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務、分散式同步、組服務等。
原理:
ZooKeeper是以Fast Paxos演算法為基礎的,Paxos 演算法存在活鎖的問題,即當有多個proposer交錯提交時,有可能互相排斥導致沒有一個proposer能提交成功,而Fast Paxos作了一些優化,通過選舉產生一個leader (領導者),只有leader才能提交proposer,具體演算法可見Fast Paxos。因此,要想弄懂ZooKeeper首先得對Fast Paxos有所瞭解。 ZooKeeper的基本運轉流程: 1、選舉Leader。 2、同步資料。 3、選舉Leader過程中演算法有很多,但要達到的選舉標準是一致的。 4、Leader要具有最高的執行ID,類似root許可權。 5、叢集中大多數的機器得到響應並接受選出的Leader。高可以用架構圖:
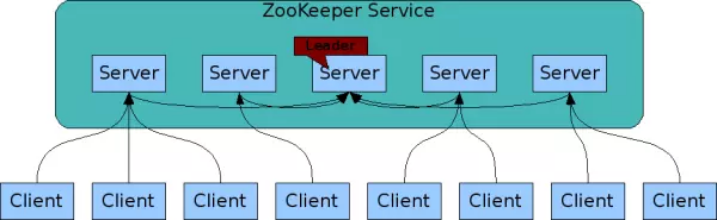
圖中每一個Server代表一個安裝Zookeeper服務的伺服器。組成 ZooKeeper 服務的伺服器都會在記憶體中維護當前的伺服器狀態,並且每臺伺服器之間都互相保持著通訊。叢集間通過 Zab 協議(Zookeeper Atomic Broadcast)來保持資料的一致性。
三、部署kafka&zookeeper叢集
我們選擇的是官方的chart地址:https://github.com/helm/charts/tree/master/incubator/kafka
1)編寫自己的values.yaml檔案(注意我的storageClass是已經做好了的nfs儲存)
imageTag: "5.2.2"
resources:
limits:
cpu: 2
memory: 4Gi
requests:
cpu: 1
memory: 2Gi
kafkaHeapOptions: "-Xmx2G -Xms2G"
persistence:
enabled: true
storageClass: "managed-nfs-storage"
size: "40Gi"
zookeeper:
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 100m
memory: 536Mi
persistence:
enabled: true
storageClass: "managed-nfs-storage"
size: "10Gi"
2)安裝kafka
新增chart倉庫:
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
部署
$ helm install --name kafka -f values.yaml incubator/kafka
最後我們能看到:

四、測試kafka高可用性
1)根據提示建立一個測試客戶端
apiVersion: v1
kind: Pod
metadata:
name: testclient
namespace: sscp-test
spec:
containers:
- name: kafka
image: solsson/kafka:0.11.0.0
command:
- sh
- -c
- "exec tail -f /dev/null"
Once you have the testclient pod above running, you can list all kafka
topics with:
kubectl -n sscp-test exec testclient -- kafka-topics --zookeeper kafka-test-zookeeper:2181 --list

To create a new topic:
kubectl -n sscp-test exec testclient -- kafka-topics --zookeeper kafka-test-zookeeper:2181 --topic test1 --create --partitions 1 --replication-factor 1

To listen for messages on a topic:
kubectl -n sscp-test exec -ti testclient -- for x in {1..1000}; do echo $x; sleep 2; done | kafka-console-producer --broker-list kafka-test-headless:9092 --topic test1
To stop the listener session above press: Ctrl+C
To start an interactive message producer session:
kubectl -n sscp-test exec -ti testclient -- kafka-console-producer --broker-list kafka-test-headless:9092 --topic test1
To create a message in the above session, simply type the message and press "enter"
To end the producer session try: Ctrl+C
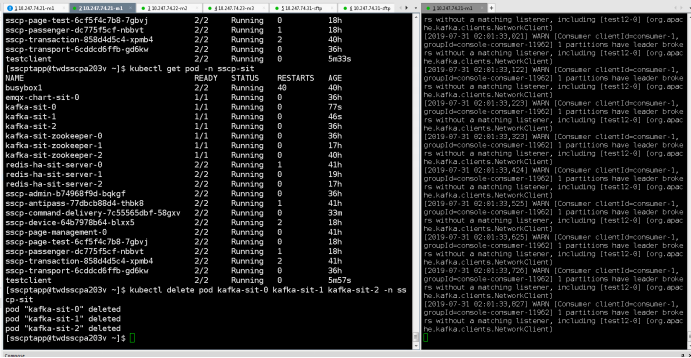
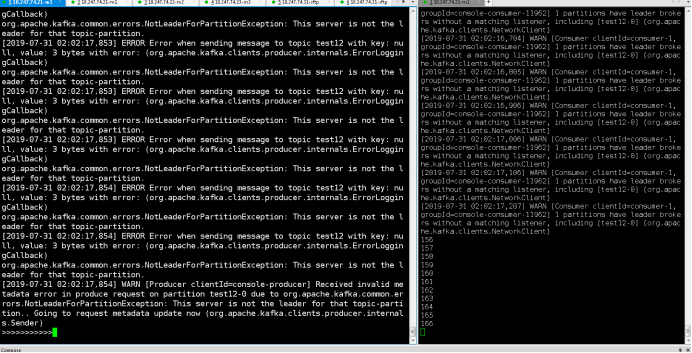
注意:有三個kafka節點,訊息要發三個副本才能保持其高可用!!!
五、測試Zookeeper高可用性
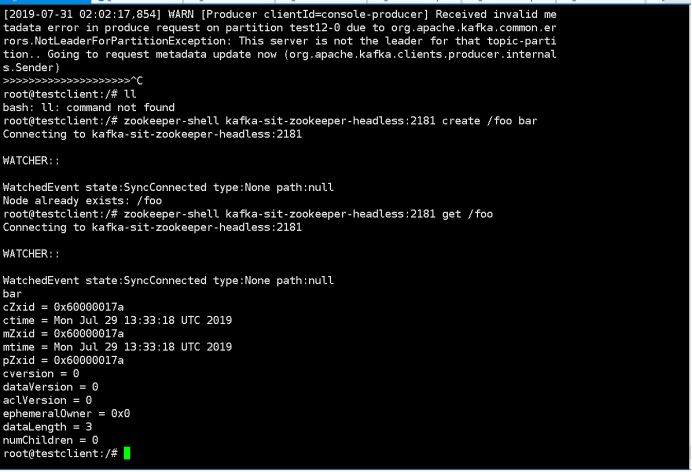
1.Create a node by command below:
“kubectl exec -it testclient bash -n sscp-test”
“zookeeper-shell kafka-test-zookeeper-headless:2181 create /foo bar”
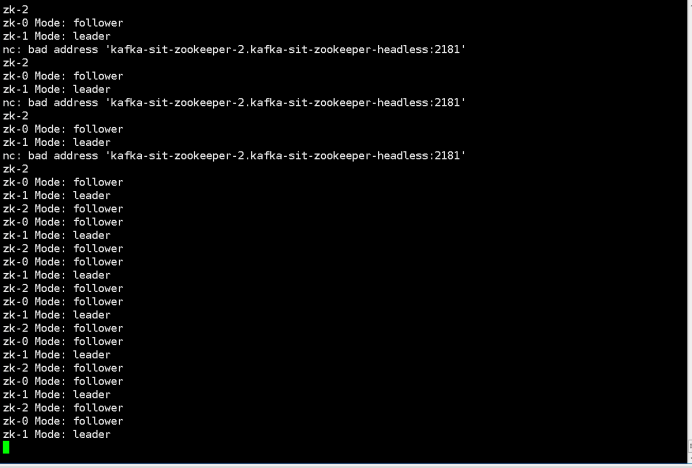
2. Check zookeeper status
Watch existing members:
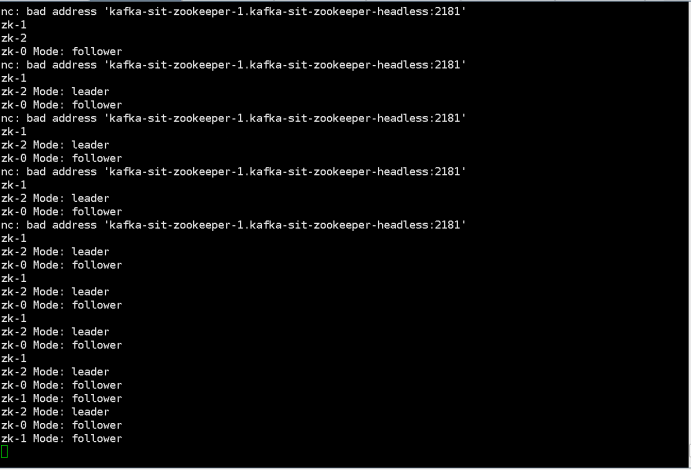
$ kubectl run --attach bbox --image=busybox --restart=Never -- sh -c 'while true; do for i in 0 1 2; do echo zk-${i} $(echo stats | nc kafka-zookeeper-${i}.kafka-zookeeper-headless:2181 | grep Mode); sleep 1; done; done'
zk-2 Mode: follower
zk-0 Mode: follower
zk-1 Mode: leader
zk-2 Mode: follower
3.kill the leader by command below:
“Kubectl delete pod kafka-test-zookeeper-1”
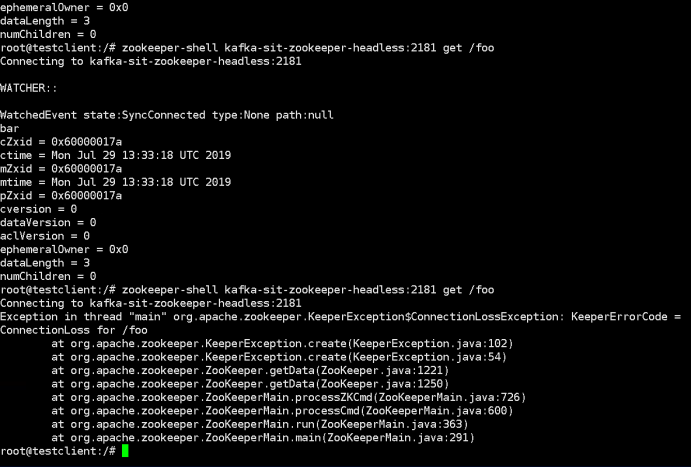
4.Check the previously inserted key by command below:
““kubectl exec -it testclient bash -n sscp-test”
“zookeeper-shell kafka-test-zookeeper-headless:2181 get /foo”
&n