
生成對抗網路(GAN)是幹什麼用的?
什麼是生成對抗網路?生成式對抗網路(GAN, Generative Adversarial Networks )是一種深度學習模型,是近年來複雜分佈上無監督學習最具前景的方法之一。模型通過框架中(至少)兩個模組:生成模型(Generative Model)和判別模型(Discriminative Model)的互相博弈學習產生相當好的輸出。原始 GAN 理論中,並不要求 G 和 D 都是神經網路,只需要是能擬合相應生成和判別的函式即可。但實用中一般均使用深度神經網路作為 G 和 D 。一個優秀的GAN應用需要有良好的訓練方法,否則可能由於神經網路模型的自由性而導致輸出不理想。
一個典型的生成對抗網路模型大概長這個樣子:
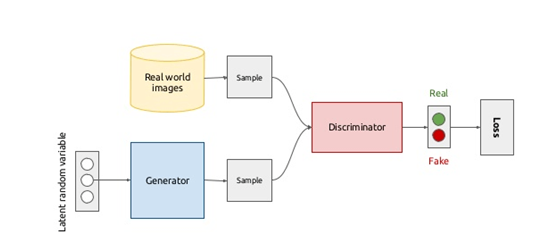
我們先來理解下GAN的兩個模型要做什麼。
首先判別模型,就是圖中右半部分的網路,直觀來看就是一個簡單的神經網路結構,輸入就是一副影象,輸出就是一個概率值,用於判斷真假使用(概率值大於0.5那就是真,小於0.5那就是假),真假也不過是人們定義的概率而已。
其次是生成模型,生成模型要做什麼呢,同樣也可以看成是一個神經網路模型,輸入是一組隨機數Z,輸出是一個影象,不再是一個數值而已。從圖中可以看到,會存在兩個資料集,一個是真實資料集,這好說,另一個是假的資料集,那這個資料集就是有生成網路造出來的資料集。好了根據這個圖我們再來理解一下GAN的目標是要幹什麼:
判別網路的目的:就是能判別出來屬於的一張圖它是來自真實樣本集還是假樣本集。假如輸入的是真樣本,網路輸出就接近
生成網路的目的:生成網路是造樣本的,它的目的就是使得自己造樣本的能力盡可能強,強到什麼程度呢,你判別網路沒法判斷我是真樣本還是假樣本。
因此辨別網路的作用就是對噪音生成的資料辨別他為假的,對真實的資料辨別他為真的。
而生成網路的損失函式就是使得對於噪音資料,經過辨別網路之後的辨別結果是真的,這樣就能達到生成真實影象的目的。
這裡會感覺比較饒,這也是生成對抗網路的難點所在,理解了這點,整個生成對抗網路模型也就理解了。
- 工作模式
一般的工作流程很簡單直接:
1. 取樣訓練樣本的一個 minibatch
2. 得到一個生成樣本 minibatch,然後計算它們的鑑別器分數;
3. 使用這兩個步驟累積的梯度執行一次更新。
下一個訣竅是避免使用稀疏梯度,尤其是在生成器中。只需將特定的層換成它們對應的「平滑」的類似層就可以了,比如:
1.ReLU 換成 LeakyReLU
2. 最大池化換成平均池化、卷積+stride
3.Unpooling 換成去卷積
兩個主要網路模型,一個是生成器模型,一個是辨別器模型。
辨別器模型要辨別兩種資料來源,一種是真實資料,一種是生成器生成的資料。這裡可以分成兩個辨別器模型,設定reuse=True來共享模型引數。
2、程式碼
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
# TODO:資料準備
mnist = input_data.read_data_sets('data')
# TODO:獲得輸入資料
def get_inputs(noise_dim, image_height, image_width, image_depth):
# 真實資料
inputs_real = tf.placeholder(tf.float32, [None, image_height, image_width, image_depth], name='inputs_real')
# 噪聲資料
inputs_noise = tf.placeholder(tf.float32, [None, noise_dim], name='inputs_noise')
return inputs_real, inputs_noise
# TODO:生成器
def get_generator(noise_img, output_dim, is_train=True, alpha=0.01):
with tf.variable_scope("generator", reuse=(not is_train)):
# 100 x 1 to 4 x 4 x 512
# 全連線層
layer1 = tf.layers.dense(noise_img, 4 * 4 * 512)
layer1 = tf.reshape(layer1, [-1, 4, 4, 512])
# batch normalization
layer1 = tf.layers.batch_normalization(layer1, training=is_train)
# Leaky ReLU
layer1 = tf.maximum(alpha * layer1, layer1)
# dropout
layer1 = tf.nn.dropout(layer1, keep_prob=0.8)
# 4 x 4 x 512 to 7 x 7 x 256
layer2 = tf.layers.conv2d_transpose(layer1, 256, 4, strides=1, padding='valid')
layer2 = tf.layers.batch_normalization(layer2, training=is_train)
layer2 = tf.maximum(alpha * layer2, layer2)
layer2 = tf.nn.dropout(layer2, keep_prob=0.8)
# 7 x 7 256 to 14 x 14 x 128
layer3 = tf.layers.conv2d_transpose(layer2, 128, 3, strides=2, padding='same')
layer3 = tf.layers.batch_normalization(layer3, training=is_train)
layer3 = tf.maximum(alpha * layer3, layer3)
layer3 = tf.nn.dropout(layer3, keep_prob=0.8)
# 14 x 14 x 128 to 28 x 28 x 1
logits = tf.layers.conv2d_transpose(layer3, output_dim, 3, strides=2, padding='same')
# MNIST原始資料集的畫素範圍在0-1,這裡的生成圖片範圍為(-1,1)
# 因此在訓練時,記住要把MNIST畫素範圍進行resize
outputs = tf.tanh(logits)
return outputs
# TODO:判別器
def get_discriminator(inputs_img, reuse=False, alpha=0.01):
with tf.variable_scope("discriminator", reuse=reuse):
# 28 x 28 x 1 to 14 x 14 x 128
# 第一層不加入BN
layer1 = tf.layers.conv2d(inputs_img, 128, 3, strides=2, padding='same')
layer1 = tf.maximum(alpha * layer1, layer1)
layer1 = tf.nn.dropout(layer1, keep_prob=0.8)
# 14 x 14 x 128 to 7 x 7 x 256
layer2 = tf.layers.conv2d(layer1, 256, 3, strides=2, padding='same')
layer2 = tf.layers.batch_normalization(layer2, training=True)
layer2 = tf.maximum(alpha * layer2, layer2)
layer2 = tf.nn.dropout(layer2, keep_prob=0.8)
# 7 x 7 x 256 to 4 x 4 x 512
layer3 = tf.layers.conv2d(layer2, 512, 3, strides=2, padding='same')
layer3 = tf.layers.batch_normalization(layer3, training=True)
layer3 = tf.maximum(alpha * layer3, layer3)
layer3 = tf.nn.dropout(layer3, keep_prob=0.8)
# 4 x 4 x 512 to 4*4*512 x 1
flatten = tf.reshape(layer3, (-1, 4 * 4 * 512))
logits = tf.layers.dense(flatten, 1)
outputs = tf.sigmoid(logits)
return logits, outputs
# TODO: 目標函式
def get_loss(inputs_real, inputs_noise, image_depth, smooth=0.1):
g_outputs = get_generator(inputs_noise, image_depth, is_train=True)
d_logits_real, d_outputs_real = get_discriminator(inputs_real)
d_logits_fake, d_outputs_fake = get_discriminator(g_outputs, reuse=True)
# 計算Loss
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,labels=tf.ones_like(d_outputs_fake) * (1 - smooth)))
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,labels=tf.ones_like(d_outputs_real) * (1 - smooth)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,labels=tf.zeros_like(d_outputs_fake)))
d_loss = tf.add(d_loss_real, d_loss_fake)
return g_loss, d_loss
# TODO:優化器
def get_optimizer(g_loss, d_loss, learning_rate=0.001):
train_vars = tf.trainable_variables()
g_vars = [var for var in train_vars if var.name.startswith("generator")]
d_vars = [var for var in train_vars if var.name.startswith("discriminator")]
# Optimizer
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
g_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars)
d_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars)
return g_opt, d_opt
# 顯示圖片
def plot_images(samples):
fig, axes = plt.subplots(nrows=5, ncols=5, sharex=True, sharey=True, figsize=(7, 7))
for img, ax in zip(samples, axes.flatten()):
ax.imshow(img.reshape((28, 28)), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
fig.tight_layout(pad=0)
plt.show()
def show_generator_output(sess, n_images, inputs_noise, output_dim):
noise_shape = inputs_noise.get_shape().as_list()[-1]
# 生成噪聲圖片
examples_noise = np.random.uniform(-1, 1, size=[n_images, noise_shape])
samples = sess.run(get_generator(inputs_noise, output_dim, False),
feed_dict={inputs_noise: examples_noise})
result = np.squeeze(samples, -1)
return result
# TODO:開始訓練
# 定義引數
batch_size = 64
noise_size = 100
epochs = 5
n_samples = 25
learning_rate = 0.001
def train(noise_size, data_shape, batch_size, n_samples):
# 儲存loss
losses = []
steps = 0
inputs_real, inputs_noise = get_inputs(noise_size, data_shape[1], data_shape[2], data_shape[3])
g_loss, d_loss = get_loss(inputs_real, inputs_noise, data_shape[-1])
print("FUNCTION READY!!")
g_train_opt, d_train_opt = get_optimizer(g_loss, d_loss, learning_rate)
print("TRAINING....")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 迭代epoch
for e in range(epochs):
for batch_i in range(mnist.train.num_examples // batch_size):
steps += 1
batch = mnist.train.next_batch(batch_size)
batch_images = batch[0].reshape((batch_size, data_shape[1], data_shape[2], data_shape[3]))
# scale to -1, 1
batch_images = batch_images * 2 - 1
# noise
batch_noise = np.random.uniform(-1, 1, size=(batch_size, noise_size))
# run optimizer
sess.run(g_train_opt, feed_dict={inputs_real: batch_images,
inputs_noise: batch_noise})
sess.run(d_train_opt, feed_dict={inputs_real: batch_images,
inputs_noise: batch_noise})
if steps % 101 == 0:
train_loss_d = d_loss.eval({inputs_real: batch_images,
inputs_noise: batch_noise})
train_loss_g = g_loss.eval({inputs_real: batch_images,
inputs_noise: batch_noise})
losses.append((train_loss_d, train_loss_g))
print("Epoch {}/{}....".format(e + 1, epochs),
"Discriminator Loss: {:.4f}....".format(train_loss_d),
"Generator Loss: {:.4f}....".format(train_loss_g))
if e % 1 == 0:
# 顯示圖片
samples = show_generator_output(sess, n_samples, inputs_noise, data_shape[-1])
plot_images(samples)
with tf.Graph().as_default():
train(noise_size, [-1, 28, 28, 1], batch_size, n_samples)
print("OPTIMIZER END!!")