
微服務的資料庫設計
單獨的資料庫:
微服務設計的一個關鍵是資料庫設計,基本原則是每個服務都有自己單獨的資料庫,而且只有微服務本身可以訪問這個資料庫。它是基於下面三個原因。
- 優化服務介面:微服務之間的介面越小越好,最好只有服務呼叫介面(RPC或訊息),沒有其他介面。如果微服務不能獨享自己的資料庫,那麼資料庫也變成了介面的一部分,這大大拓展了介面範圍。
- 錯誤診斷:生產環境中的錯誤大部分都是和資料庫有關的,要麼是資料出了問題,要麼是資料庫的使用方式出了問題。當你不能完全控制資料庫的訪問時,會有各種各樣的錯誤發生。它可能是別的程式直接連到你的資料庫或者是其他部門直接用客戶端訪問資料庫的資料,而這些都是在程式中查不到的,增加了錯誤排查難度。如果是程式中的問題,只要修改了程式碼,那麼這個錯誤就不會再有。而上面提到的錯誤,你永遠都沒法預測它們什麼時候還會再次發生。
- 效能調優:效能調優也是一樣,你需要對資料庫有全權控制才能保證它的效能。如果其他部門一定要訪問資料庫,而且只是查詢的話,那麼可以另外建立一份只讀資料庫,讓他們在另一個庫中查詢,這樣才不會影響到你的庫。
理想的設計是你的資料庫只有你的服務能訪問,你也只調用自己資料庫中的資料,所有對別的微服務的訪問都通過服務呼叫來實現(請參閱“微服務之間呼叫的最佳設計“)。當然,在實際應用中,單純的服務呼叫可能不能滿足效能或其他要求,不同的微服務都多少需要共享一些資料。
共享資料:
微服務之間的資料共享可以有下四種方式。
靜態表:
有一些靜態的資料庫表,例如國家,可能會被很多程式用到,而且程式內部需要對國家這個表做連線(join)生成終端使用者展示資料,這樣用微服務呼叫的方式就效率不高,影響效能。一個辦法是在每個微服務中配置一個這樣的表,它是隻讀的,這樣就可以做資料庫連線了。當然你需要保證資料同步。這個方案在多數情況下都是可以接受的,因為以下兩點:
- 靜態的資料庫表結構基本不變:因為一旦表結構變了,你不但要更改所有微服務的資料庫表,還要修改所有微服務的程式。
- 資料庫表中的資料變化不頻繁:這樣資料同步的工作量不大。另外當你同步資料庫時總會有延遲,如果資料變化不頻繁那麼你有很多同步方式可供選擇。
只讀業務資料訪問:
如果你需要讀取別的資料庫裡的動態業務資料, 理想的方式是服務呼叫。如果你只是呼叫其他微服務做一些計算,一般情況下效能都是可以接受的。如果你需要做資料的連線,那麼你可以用程式程式碼來做,而不是用SQL語句。如果測試之後效能不能滿足要求,那你可以考慮在自己的資料庫裡建一套只讀資料表。資料同步方式大致有兩種。如果是事件驅動方式,就用發訊息的方式進行同步,如果是RPC方式,就用資料庫本身提供的同步方式或者第三方同步軟體。
通常情況下,你可能只需要其他資料庫的幾張表,每張表只需要幾個欄位。這時,其他資料庫是資料的最終來源,控制所有寫操作以及相應的業務驗證邏輯,我們叫它主表。你的只讀庫可以叫從表。 當一條資料寫入主表後,會發一條廣播訊息,所有擁有從表的微服務監聽訊息並更新只讀表中的資料。但這時你要特別小心,因為它的危險性要比靜態表大得多。第一它的表結構變更會更頻繁,而且它的變更完全不受你控制。第二業務資料不像靜態表,它是經常更新的,這樣對資料同步的要求就比較高。要根據具體的業務需求來決定多大的延遲是可以接受的。
另外它還有兩個問題:
- 資料的容量:資料庫中的資料量是影響效能的主要因素。因為這個資料是外來的,不利於掌握它的流量規律,很難進行容量規劃,也不能更好地進行效能調優。
- ** 介面外洩**:微服務之間的介面本來只有服務呼叫介面,這時你可以對內部程式和資料庫做任何更改,而不影響其他服務。現在資料庫表結構也變成了介面的一部分。介面一旦釋出之後,基本是不能更改的,這大大限制了你的靈活性。幸運的是因為另外建了一套表,有了一個緩衝,當主表修改時,從表也許不需要同步更新。
除非你能用服務呼叫(沒有本地只讀資料庫)的方式完成所有功能,不然不管你是用RPC方式還是事件驅動方式進行微服務整合,上面提到的問題都是不可避免的。但是你可以通過合理規劃資料庫更改,來減少上面問題帶來的影響,下面將會詳細講解。
讀寫業務資料訪問:
這是最複雜的一種情況。一般情況下,你有一個表是主表,而其他表是從表。主表包含主要資訊,而且這些主要資訊被複制到從表,但微服務會有額外欄位需要寫入從表。這樣本地微服務對從表就既有讀也有寫的操作。而且主表和從表有一個先後次序的關係。從表的主鍵來源於主表,因此一定先有主表,再有從表。
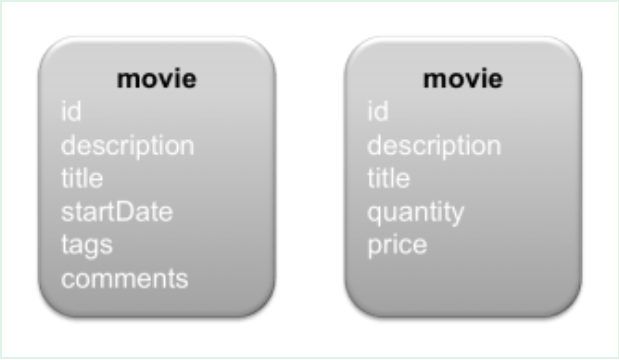
圖片來源
上圖是例子。假設我們有兩個與電影有關的微服務,一個是電影論壇,使用者可以發表對電影的評論。另一個是電影商店。“movie”是共享表,左邊的一個是電影論壇庫,它的“movie”表是主表。右邊的是電影商店庫,它的“movie”表是從表。它們共享“id”欄位(主鍵)。主表是資料的主要來源,但從表裡的“quantity”和“price”欄位主表裡面沒有。主表插入資料後,發訊息,從表接到訊息,插入一條資料到本地“movie”表。並且從表還會修改表裡的“quantity”和“price”欄位。在這種情況下,要給每一個欄位分配一個唯一源頭(微服務),只有源頭才有權利主動更改欄位,其他微服務只能被動更改(接收源頭髮出的更改訊息之後再改)。在本例子中, “quantity”和“price”欄位的源頭是右邊的表,其他的欄位的源頭都是左邊的表。本例子中“quantity”和“price”只在從表中存在,因此資料寫入是單向的,方向是主表到從表。如果主表也需要這些欄位,那麼它們還要被回寫,那資料寫入就變成雙向的。
直接訪問其它資料庫:
這種方式是要絕對禁止的。生產環境中的許多程式錯誤和效能問題都是由這種方式產生的。上面的三種方式由於是另外新建了本地只讀資料庫表,產生了資料庫的物理隔離,這樣一個數據庫的效能問題不會影響到另一個。另外,當主庫中的表結構更改時,你可以暫時保持從庫中的表不變,這樣程式還可以執行。如果直接訪問別人的庫,主庫一修改,別的微服務程式馬上就會報錯。請參閱ApplicationDatabase。
向後相容的資料庫更新:
從上面的論述可以看出,資料庫表結構的修改是一個影響範圍很廣的事情。在微服務架構中,共享的表在別的服務中也會有一個只讀的拷貝。現在當你要更改表結構時,還需要考慮到對別的微服務的影響。當在單體(Monolithic)架構中,為了保證程式部署能夠回滾,資料庫的更新是向後相容的。需要相容性的另一個原因是支援藍綠髮布(Blue-Green Deployment)。在這種部署方式中,你同時擁有新舊版本的程式碼,由負載均衡來決定每一個請求指向那個版本。它們可以共享一個數據庫(這就要求資料庫是向後相容的),也可以使用不同的資料。資料庫的更新簡單來講有以下幾種型別:
- 增加表或欄位:如果欄位可取空值,這個操作是向後相容的。如果是非空值就要插入一個預設值。
- 刪除表或欄位:可先暫時保留被刪除表或欄位,經過幾個版本之後再刪除。
- 修改欄位名:新增加一個欄位,把資料從舊欄位拷貝到新欄位,用資料庫觸發器(或程式)同步舊欄位和新欄位(供過渡時期使用)。 然後再在幾個版本之後把原來的欄位刪除(請參閱Update your Database Schema Without Downtime)。
- 修改表名:如果資料庫支援可更新檢視,最簡單的辦法是先修改表的名字,然後建立一個可更新檢視指向原來的表(請參閱Evolutionary Database Design )。如果資料庫不支援可更新檢視,使用的方法與修改欄位名相似,需要建立新的表並做資料同步。
- 修改欄位型別:與修改欄位名幾乎相同,只是在拷貝資料時,需要做資料型別轉換。
向後相容的資料庫更新的好處是,當程式部署出現問題時,如需進行回滾。只要回滾程式就行了,而不必回滾資料庫。回滾時一般只回滾一個版本。凡是需要刪除的表或欄位在本次部署時都不做修改,等到一個或幾個版本之後,確認沒有問題了再刪除。它的另一個好處就是不會對其他微服務中的共享表產生立刻的直接影響。當本微服務升級後,其他微服務可以評估這些資料庫更新帶來的影響再決定是否需要做相應的程式或資料庫修改。
跨服務事物:
微服務的一個難點是如何實現跨服務的事物支援。兩階段提交(Two-Phase Commit)已被證明效能上不能滿足需求,現在基本上沒有人用。被一致認可的方法叫Saga。它的原理是為事物中的每個操作寫一個補償操作(Compensating Transaction),然後在回滾階段挨個執行每一個補償操作。示例如下圖,在一個事物中共有3個操作T1,T2,T3。每一個操作要定義一個補償操作,C1,C2,C3。事物執行時是按照正向順序先執行T1,當回滾時是按照反向順序先執行C3。 事物中的每一個操作(正向操作和補償操作)都被包裝成一個命令(Command),Saga執行協調器(Saga Execution Coordinator (SEC))負責執行所有命令。在執行之前,所有的命令都會按順序被存入日誌中,然後Saga執行協調器從日誌中取出命令,依次執行。當某個執行出現錯誤時,這個錯誤也被寫入日誌,並且所有正在執行的命令被停止,開始回滾操作。
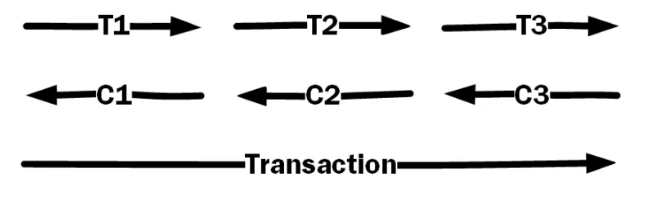
圖片來源
Saga放鬆了對一致性(Consistency)的要求,它能保證的是最終一致性(Eventual Consistency),因此在事物執行過程中資料是不一致的,並且這種不一致會被別的程序看到。在生活中,大多數情況下,我們對一致性的要求並沒有那麼高,短暫的不一致性是可以接收的。例如銀行的轉賬操作,它們在執行過程中都不是在一個數據庫事物裡執行的,而是用記賬的方式分成兩個動作來執行,保證的也是最終一致性。
Saga的原理看起來很簡單,但要想正確的實施還是有一定難度的。它的核心問題在於對錯誤的處理,要把它完全講明白需要另寫一遍文章,我現在只講一下要點。網路環境是不可靠的,正在執行的命令可能很長時間都沒有返回結果,這時,第一,你要設定一個超時。第二,因為你不知道沒有返回值的原因是,已經完成了命令但網路出了問題,還是沒完成就犧牲了,因此不知道是否要執行補償操作。這時正確的做法是重試原命令,直到得到完成確認,然後再執行補償操作。但這對命令有一個要求,那就是這個操作必須是冪等的(Idempotent),也就是說它可以執行多次,但最終結果還是一樣的。
另外,有些操作的補償操作比較容易生成,例如付款操作,你只要把錢款退回就可以了。但有些操作,像發郵件,完成之後就沒有辦法回到之前的狀態了,這時就只能再發一個郵件更正以前的資訊。因此補償操作不一定非要返回到原來的狀態,而是抵消掉原來操作產生的效果。如果想了解更多,請看這裡.
微服務的拆分:
我們原來的程式大多數都是單體程式,但現在要把它拆分成微服務,應該怎樣做才能降低對現有應用的影響呢?
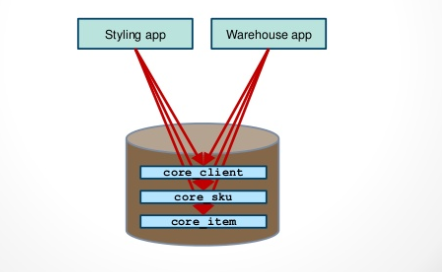
圖片來源
我們用上面的圖來做例子。它共有兩個程式,一個是“Styling app”,另一個是“Warehouse app”,它們共享圖中下面的資料庫,庫裡有三張表,“core client”,“core sku”,“core item”。
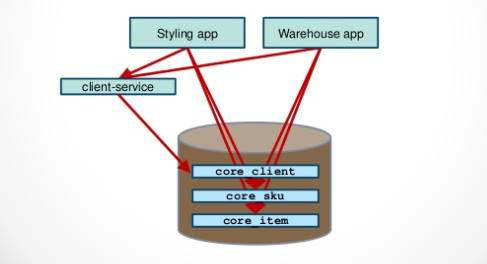
圖片來源
假設我們要拆分出來一個微服務叫“client-service”,它需要訪問“core client”表。第一步,我們先把程式從原來的程式碼裡拆分出來,變成一個服務. 資料庫不動,這個服務仍然指向原來的資料庫。其他程式不再直接訪問這個服務管理的表,而是通過服務呼叫或另建共享表來獲取資料。
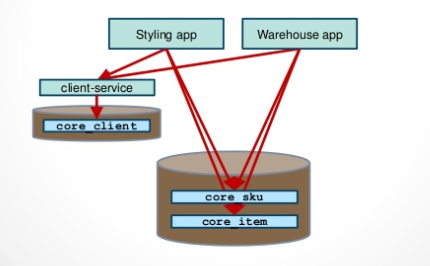
圖片來源
第二步,再把服務的資料庫表拆分出來,這時微服務就擁有它自己的資料庫了,而不再需要原來的共享資料庫了。這時就成了一個真正意義上的的微服務。
上面只講了拆分一個微服務,如果有多個需要拆分,則需一個一個按照上面講的方法依次進行。
另外,Martin Fowler在他的文章"Break Monolith into Microservices"裡有一個很好的建議。那就是,當你把服務從單體程式裡拆分時,不要只想著把程式碼拆分出來。因為現在的需求可能已經跟原來有所不同,原先的設計可能也不太適用了。而且,技術也已更新,程式碼也要作相應的改造。更好的辦法是重寫原來的功能(而不是重寫原來的程式碼),把重點放在拆分業務功能上,而不是拆分程式碼上,用新的設計和技術來實現這個業務功能。
結論:
資料庫設計是微服務設計的一個關鍵點,基本原則是每個微服務都有自己單獨的資料庫,而且只有微服務本身可以訪問這個資料庫。微服務之間的資料共享可以通過服務呼叫,或者主、從表的方式實現。在共享資料時,要找到合適的同步方式。在微服務架構中,資料庫的修改影響廣泛,需要保證這種修改是向後相容的。實現跨服務事物的標準方法是Saga。當把單體程式拆分成微服務時,可以分步進行,以減少對現有程式的影響。
索引:
- 微服務之間呼叫的最佳設計
- ApplicationDatabase
- Update your Database Schema Without Downtime
- Evolutionary Database Design
- Fault-Tolerance and Data Consistency Using Distributed Sagas
- Distributed Sagas: A Protocol for Coordinating Microservices - Caitie McCaffrey - JOTB17
- Managing Data in Microservices
- How to break a Monolith into Microservices
本文由部落格一文多發平臺 OpenWrite 釋出!