
一篇文章徹底搞懂snowflake演算法及百度美團的最佳實踐
寫在前面的話
一提到分散式ID自動生成方案,大家肯定都非常熟悉,並且立即能說出自家拿手的幾種方案,確實,ID作為系統資料的重要標識,重要性不言而喻,而各種方案也是歷經多代優化,請允許我用這個視角對分散式ID自動生成方案進行分類:
實現方式
- 完全依賴資料來源方式
ID的生成規則,讀取控制完全由資料來源控制,常見的如資料庫的自增長ID,序列號等,或Redis的INCR/INCRBY原子操作產生順序號等。
- 半依賴資料來源方式
ID的生成規則,有部分生成因子需要由資料來源(或配置資訊)控制,如snowflake演算法。
- 不依賴資料來源方式
ID的生成規則完全由機器資訊獨立計算,不依賴任何配置資訊和資料記錄,如常見的UUID,GUID等
實踐方案
實踐方案適用於以上提及的三種實現方式,可作為這三種實現方式的一種補充,旨在提升系統吞吐量,但原有實現方式的侷限性依然存在。
- 實時獲取方案
顧名思義,每次要獲取ID時,實時生成。
簡單快捷,ID都是連續不間斷的,但吞吐量可能不是最高。
- 預生成方案
預先生成一批ID放在資料池裡,可簡單自增長生成,也可以設定步長,分批生成,需要將這些預先生成的資料,放在儲存容器裡(JVM記憶體,Redis,資料庫表均可)。
可以較大幅度地提升吞吐量,但需要開闢臨時儲存空間,斷電宕機後可能會丟失已有ID,ID可能有間斷。
方案簡介
以下對目前流行的分散式ID方案做簡單介紹
- 資料庫自增長ID
屬於完全依賴資料來源的方式,所有的ID儲存在資料庫裡,是最常用的ID生成辦法,在單體應用時期得到了最廣泛的使用,建立資料表時利用資料庫自帶的auto_increment作主鍵,或是使用序列完成其他場景的一些自增長ID的需求。
- 優點:非常簡單,有序遞增,方便分頁和排序。
- 缺點:分庫分表後,同一資料表的自增ID容易重複,無法直接使用(可以設定步長,但侷限性很明顯);效能吞吐量整個較低,如果設計一個單獨的資料庫來實現 分散式應用的資料唯一性,即使使用預生成方案,也會因為事務鎖的問題,高併發場景容易出現單點瓶頸。
- 適用場景:單資料庫例項的表ID(包含主從同步場景),部分按天計數的流水號等;分庫分表場景、全系統唯一性ID場景不適用。
- Redis生成ID
也屬於完全依賴資料來源的方式,通過Redis的INCR/INCRBY自增原子操作命令,能保證生成的ID肯定是唯一有序的,本質上實現方式與資料庫一致。
- 優點:整體吞吐量比資料庫要高。
- 缺點:Redis例項或叢集宕機後,找回最新的ID值有點困難。
- 適用場景:比較適合計數場景,如使用者訪問量,訂單流水號(日期+流水號)等。
- UUID、GUID生成ID
UUID:按照OSF制定的標準計算,用到了乙太網卡地址、納秒級時間、晶片ID碼和許多可能的數字。由以下幾部分的組合:當前日期和時間(UUID的第一個部分與時間有關,如果你在生成一個UUID之後,過幾秒又生成一個UUID,則第一個部分不同,其餘相同),時鐘序列,全域性唯一的IEEE機器識別號(如果有網絡卡,從網絡卡獲得,沒有網絡卡以其他方式獲得)
GUID:微軟對UUID這個標準的實現。UUID還有其它各種實現,不止GUID一種,不一一列舉了。
這兩種屬於不依賴資料來源方式,真正的全球唯一性ID
- 優點:不依賴任何資料來源,自行計算,沒有網路ID,速度超快,並且全球唯一。
- 缺點:沒有順序性,並且比較長(128bit),作為資料庫主鍵、索引會導致索引效率下降,空間佔用較多。
- 適用場景:只要對儲存空間沒有苛刻要求的都能夠適用,比如各種鏈路追蹤、日誌儲存等。
4、snowflake演算法(雪花演算法)生成ID
屬於半依賴資料來源方式,原理是使用Long型別(64位),按照一定的規則進行填充:時間(毫秒級)+叢集ID+機器ID+序列號,每部分佔用的位數可以根據實際需要分配,其中叢集ID和機器ID這兩部分,在實際應用場景中要依賴外部引數配置或資料庫記錄。
- 優點:高效能、低延遲、去中心化、按時間有序
- 缺點:要求機器時鐘同步(到秒級即可)
- 適用場景:分散式應用環境的資料主鍵
雪花ID演算法聽起來是不是特別適用分散式架構場景?照目前來看是的,接下來我們重點講解它的原理和最佳實踐。
snowflake演算法實現原理
snowflake演算法來源於Twitter,使用scala語言實現,利用Thrift框架實現RPC介面呼叫,最初的專案起因是資料庫從mysql遷移到Cassandra,Cassandra沒有現成可用 的ID生成機制,就催生了這個專案,現有的github原始碼有興趣可以去看看。
snowflake演算法的特性是有序、唯一,並且要求高效能,低延遲(每臺機器每秒至少生成10k條資料,並且響應時間在2ms以內),要在分散式環境(多叢集,跨機房)下使用,因此snowflake演算法得到的ID是分段組成的:
- 與指定日期的時間差(毫秒級),41位,夠用69年
- 叢集ID + 機器ID, 10位,最多支援1024臺機器
- 序列,12位,每臺機器每毫秒內最多產生4096個序列號
如圖所示:

- 1bit:符號位,固定是0,表示全部ID都是正整數
- 41bit:毫秒數時間差,從指定的日期算起,夠用69年,我們知道用Long型別表示的時間戳是從1970-01-01 00:00:00開始算起的,咱們這裡的時間戳可以指定日期,如2019-10-23 00:00:00
- 10bit:機器ID,有異地部署,多叢集的也可以配置,需要線下規劃好各地機房,各叢集,各例項ID的編號
- 12bit:序列ID,前面都相同的話,最多可以支援到4096個
以上的位數分配只是官方建議的,我們可以根據實際需要自行分配,比如說我們的應用機器數量最多也就幾十臺,但併發數很大,我們就可以將10bit減少到8bit,序列部分從12bit增加到14bit等等
當然每部分的含義也可以自由替換,如中間部分的機器ID,如果是雲端計算、容器化的部署環境,隨時有擴容,縮減機器的操作,通過線下規劃去配置例項的ID不太現實,就可以替換為例項每重啟一次,拿一次自增長的ID作為該部分的內容,下文會講解。
github上也有大神用Java做了snowflake最基本的實現,這裡直接檢視原始碼:
snowflake java版原始碼
/**
* twitter的snowflake演算法 -- java實現
*
* @author beyond
* @date 2016/11/26
*/
public class SnowFlake {
/**
* 起始的時間戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分佔用的位數
*/
private final static long SEQUENCE_BIT = 12; //序列號佔用的位數
private final static long MACHINE_BIT = 5; //機器標識佔用的位數
private final static long DATACENTER_BIT = 5;//資料中心佔用的位數
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //資料中心
private long machineId; //機器標識
private long sequence = 0L; //序列號
private long lastStmp = -1L;//上一次時間戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 產生下一個ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒內,序列號自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列數已經達到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒內,序列號置為0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //時間戳部分
| datacenterId << DATACENTER_LEFT //資料中心部分
| machineId << MACHINE_LEFT //機器標識部分
| sequence; //序列號部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}基本上通過位移操作,將每段含義的數值,移到相應的位置上,如機器ID這裡由資料中心+機器標識組成,所以,機器標識向左移12位,就是它的位置,資料中心的編號向左移17位,時間戳的值向左移22位,每部分佔據自己的位置,各不干涉,由此組成一個完整的ID值。
這裡就是snowflake最基礎的實現原理,如果有些java基礎知識不記得了建議查一下資料,如二進位制-1的表示是0xffff(裡面全是1),<<表示左移操作,-1<<5等於-32,異或操作-1 ^ (-1 << 5)為31等等。
瞭解snowflake的基本實現原理,可以通過提前規劃好機器標識來實現,但目前的分散式生產環境,借用了多種雲端計算、容器化技術,例項的個數隨時有變化,還需要處理伺服器例項時鐘回撥的問題,固定規劃ID然後通過配置來使用snowflake的場景可行性不高,一般是自動啟停,增減機器,這樣就需要對snowflake進行一些改造才能更好地應用到生產環境中。
百度uid-generator專案
UidGenerator專案基於snowflake原理實現,只是修改了機器ID部分的定義(例項重啟的次數),並且64位bit的分配支援配置,官方提供的預設分配方式如下圖:

Snowflake演算法描述:指定機器 & 同一時刻 & 某一併發序列,是唯一的。據此可生成一個64 bits的唯一ID(long)。
- sign(1bit) 固定1bit符號標識,即生成的UID為正數。
- delta seconds (28 bits)
當前時間,相對於時間基點"2016-05-20"的增量值,單位:秒,最多可支援約8.7年 - worker id (22 bits) 機器id,最多可支援約420w次機器啟動。內建實現為在啟動時由資料庫分配,預設分配策略為用後即棄,後續可提供複用策略。
- sequence (13 bits) 每秒下的併發序列,13 bits可支援每秒8192個併發。
具體的實現有兩種,一種是實時生成ID,另一種是預先生成ID方式
- DefaultUidGenerator
- 啟動時向資料庫WORKER_NODE表插入當前例項的IP,Port等資訊,再獲取該資料的自增長ID作為機器ID部分。
簡易流程圖如下:
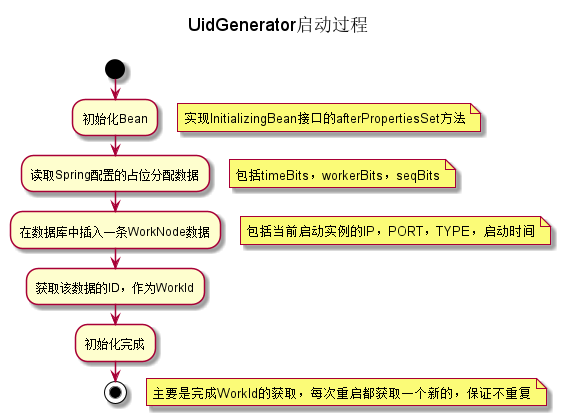
- 提供獲取ID的方法,並且檢測是否有時鐘回撥,有回撥現象直接丟擲異常,當前版本不支援時鐘順撥後漂移操作。簡易流程圖如下:
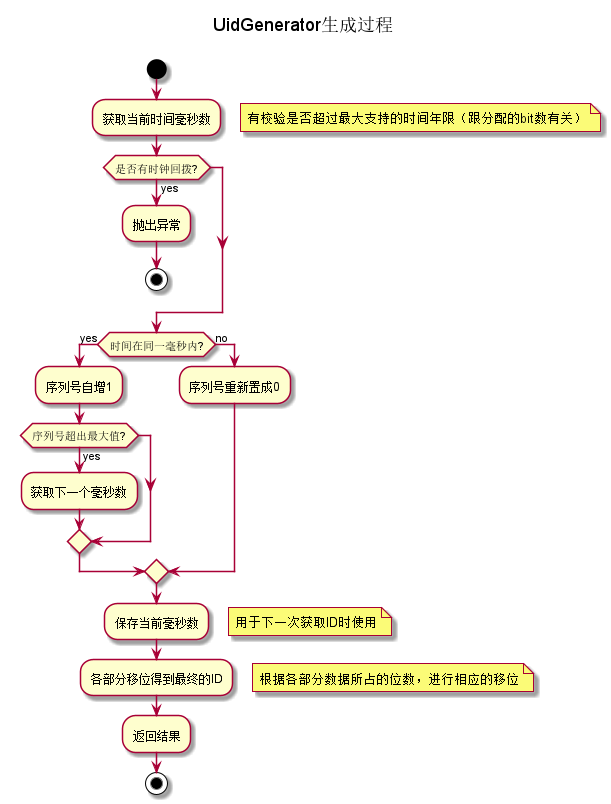
核心程式碼如下:
/**
* Get UID
*
* @return UID
* @throws UidGenerateException in the case: Clock moved backwards; Exceeds the max timestamp
*/
protected synchronized long nextId() {
long currentSecond = getCurrentSecond();
// Clock moved backwards, refuse to generate uid
if (currentSecond < lastSecond) {
long refusedSeconds = lastSecond - currentSecond;
throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds);
}
// At the same second, increase sequence
if (currentSecond == lastSecond) {
sequence = (sequence + 1) & bitsAllocator.getMaxSequence();
// Exceed the max sequence, we wait the next second to generate uid
if (sequence == 0) {
currentSecond = getNextSecond(lastSecond);
}
// At the different second, sequence restart from zero
} else {
sequence = 0L;
}
lastSecond = currentSecond;
// Allocate bits for UID
return bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence);
}- CachedUidGenerator
機器ID的獲取方法與上一種相同,這種是預先生成一批ID,放在一個RingBuffer環形數組裡,供客戶端使用,當可用資料低於閥值時,再次呼叫批量生成方法,屬於用空間換時間的做法,可以提高整個ID的吞吐量。
- 與DefaultUidGenerator相比較,初始化時多了填充RingBuffer環形陣列的邏輯,簡單流程圖如下:
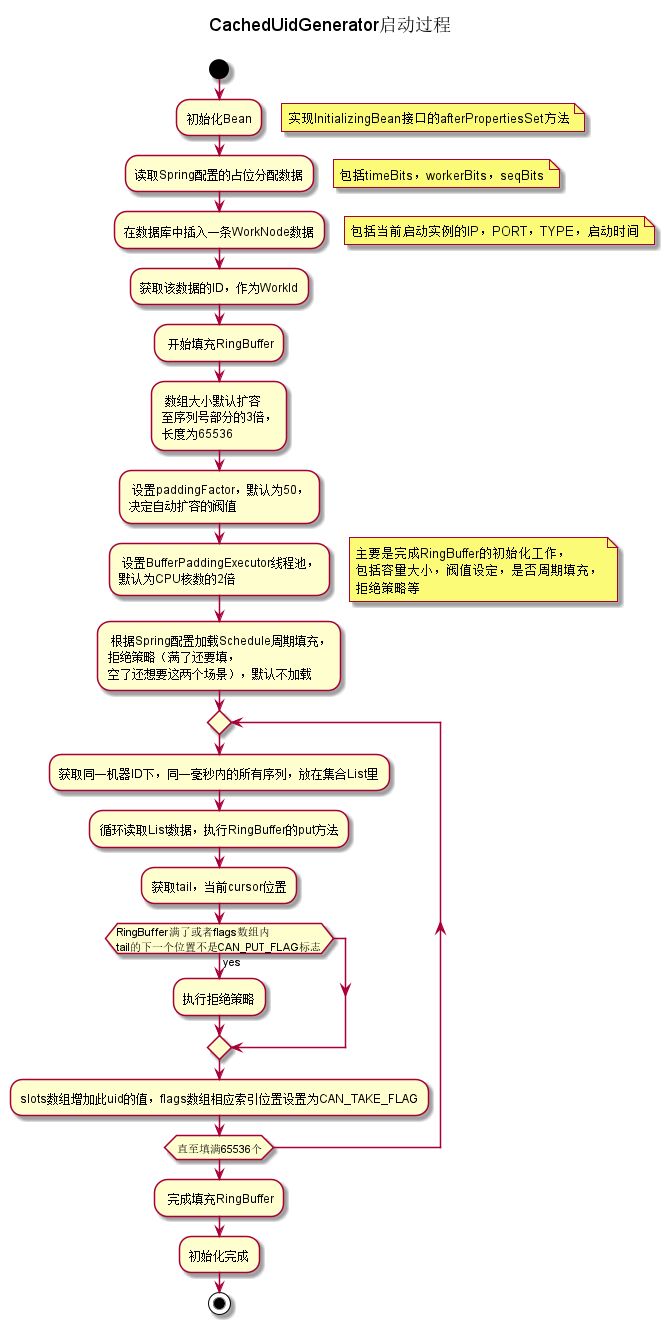
核心程式碼:
/**
* Initialize RingBuffer & RingBufferPaddingExecutor
*/
private void initRingBuffer() {
// initialize RingBuffer
int bufferSize = ((int) bitsAllocator.getMaxSequence() + 1) << boostPower;
this.ringBuffer = new RingBuffer(bufferSize, paddingFactor);
LOGGER.info("Initialized ring buffer size:{}, paddingFactor:{}", bufferSize, paddingFactor);
// initialize RingBufferPaddingExecutor
boolean usingSchedule = (scheduleInterval != null);
this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, this::nextIdsForOneSecond, usingSchedule);
if (usingSchedule) {
bufferPaddingExecutor.setScheduleInterval(scheduleInterval);
}
LOGGER.info("Initialized BufferPaddingExecutor. Using schdule:{}, interval:{}", usingSchedule, scheduleInterval);
// set rejected put/take handle policy
this.ringBuffer.setBufferPaddingExecutor(bufferPaddingExecutor);
if (rejectedPutBufferHandler != null) {
this.ringBuffer.setRejectedPutHandler(rejectedPutBufferHandler);
}
if (rejectedTakeBufferHandler != null) {
this.ringBuffer.setRejectedTakeHandler(rejectedTakeBufferHandler);
}
// fill in all slots of the RingBuffer
bufferPaddingExecutor.paddingBuffer();
// start buffer padding threads
bufferPaddingExecutor.start();
}public synchronized boolean put(long uid) {
long currentTail = tail.get();
long currentCursor = cursor.get();
// tail catches the cursor, means that you can't put any cause of RingBuffer is full
long distance = currentTail - (currentCursor == START_POINT ? 0 : currentCursor);
if (distance == bufferSize - 1) {
rejectedPutHandler.rejectPutBuffer(this, uid);
return false;
}
// 1. pre-check whether the flag is CAN_PUT_FLAG
int nextTailIndex = calSlotIndex(currentTail + 1);
if (flags[nextTailIndex].get() != CAN_PUT_FLAG) {
rejectedPutHandler.rejectPutBuffer(this, uid);
return false;
}
// 2. put UID in the next slot
// 3. update next slot' flag to CAN_TAKE_FLAG
// 4. publish tail with sequence increase by one
slots[nextTailIndex] = uid;
flags[nextTailIndex].set(CAN_TAKE_FLAG);
tail.incrementAndGet();
// The atomicity of operations above, guarantees by 'synchronized'. In another word,
// the take operation can't consume the UID we just put, until the tail is published(tail.incrementAndGet())
return true;
}- ID獲取邏輯,由於有RingBuffer這個緩衝陣列存在,獲取ID直接從RingBuffer取出即可,同時RingBuffer自身校驗何時再觸發重新批量生成即可,這裡獲取的ID值與DefaultUidGenerator的明顯區別是,DefaultUidGenerator獲取的ID,時間戳部分就是當前時間的,CachedUidGenerator裡獲取的是填充時的時間戳,並不是獲取時的時間,不過關係不大,都是不重複的,一樣用。簡易流程圖如下:
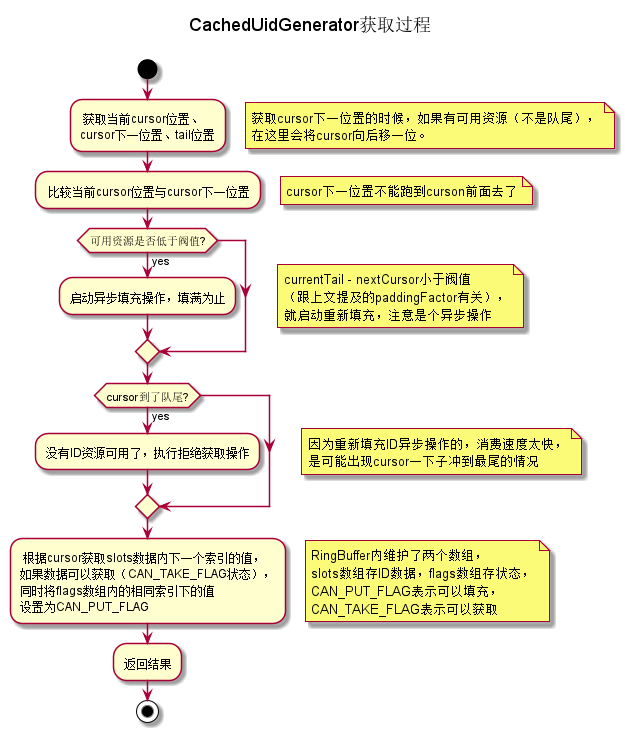
核心程式碼:
public long take() {
// spin get next available cursor
long currentCursor = cursor.get();
long nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1);
// check for safety consideration, it never occurs
Assert.isTrue(nextCursor >= currentCursor, "Curosr can't move back");
// trigger padding in an async-mode if reach the threshold
long currentTail = tail.get();
if (currentTail - nextCursor < paddingThreshold) {
LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail,
nextCursor, currentTail - nextCursor);
bufferPaddingExecutor.asyncPadding();
}
// cursor catch the tail, means that there is no more available UID to take
if (nextCursor == currentCursor) {
rejectedTakeHandler.rejectTakeBuffer(this);
}
// 1. check next slot flag is CAN_TAKE_FLAG
int nextCursorIndex = calSlotIndex(nextCursor);
Assert.isTrue(flags[nextCursorIndex].get() == CAN_TAKE_FLAG, "Curosr not in can take status");
// 2. get UID from next slot
// 3. set next slot flag as CAN_PUT_FLAG.
long uid = slots[nextCursorIndex];
flags[nextCursorIndex].set(CAN_PUT_FLAG);
// Note that: Step 2,3 can not swap. If we set flag before get value of slot, the producer may overwrite the
// slot with a new UID, and this may cause the consumer take the UID twice after walk a round the ring
return uid;
}另外有個細節可以瞭解一下,RingBuffer的資料都是使用陣列來儲存的,考慮CPU Cache的結構,tail和cursor變數如果直接用原生的AtomicLong型別,tail和cursor可能會快取在同一個cacheLine中,多個執行緒讀取該變數可能會引發CacheLine的RFO請求,反而影響效能,為了防止偽共享問題,特意填充了6個long型別的成員變數,加上long型別的value成員變數,剛好佔滿一個Cache Line(Java物件還有8byte的物件頭),這個叫CacheLine補齊,有興趣可以瞭解一下,原始碼如下:
public class PaddedAtomicLong extends AtomicLong {
private static final long serialVersionUID = -3415778863941386253L;
/** Padded 6 long (48 bytes) */
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
/**
* Constructors from {@link AtomicLong}
*/
public PaddedAtomicLong() {
super();
}
public PaddedAtomicLong(long initialValue) {
super(initialValue);
}
/**
* To prevent GC optimizations for cleaning unused padded references
*/
public long sumPaddingToPreventOptimization() {
return p1 + p2 + p3 + p4 + p5 + p6;
}
}以上是百度uid-generator專案的主要描述,我們可以發現,snowflake演算法在落地時有一些變化,主要體現在機器ID的獲取上,尤其是分散式叢集環境下面,例項自動伸縮,docker容器化的一些技術,使得靜態配置專案ID,例項ID可行性不高,所以這些轉換為按啟動次數來標識。
美團ecp-uid專案
在uidGenerator方面,美團的專案原始碼直接整合百度的原始碼,略微將一些Lambda表示式換成原生的java語法,例如:
// com.myzmds.ecp.core.uid.baidu.impl.CachedUidGenerator類的initRingBuffer()方法
// 百度原始碼
this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, this::nextIdsForOneSecond, usingSchedule);
// 美團原始碼
this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, new BufferedUidProvider() {
@Override
public List<Long> provide(long momentInSecond) {
return nextIdsForOneSecond(momentInSecond);
}
}, usingSchedule);並且在機器ID生成方面,引入了Zookeeper,Redis這些元件,豐富了機器ID的生成和獲取方式,例項編號可以儲存起來反覆使用,不再是資料庫單調增長這一種了。
結束語
本篇簡單介紹了snowflake演算法的原理及落地過程中的改造,在此學習了優秀的開原始碼,並挑出部分進行了簡單的示例,美團的ecp-uid專案不但集成了百度現有的UidGenerator演算法,原生的snowflake演算法,還包含優秀的leaf segment演算法,鑑於篇幅沒有詳盡描述。文章內有任何不正確或不詳盡之處請留言指出,謝謝。
專注Java高併發、分散式架構,更多技術乾貨分享與心得,請關注公眾號:Java架構社群

相關推薦
一篇文章徹底搞懂snowflake演算法及百度美團的最佳實踐
寫在前面的話 一提到分散式ID自動生成方案,大家肯定都非常熟悉,並且立即能說出自家拿手的幾種方案,確實,ID作為系統資料的重要標識,重要性不言而喻,而各種方案也是歷經多代優化,請允許我用這個視角對分散式ID自動生成方案進行分類: 實現方式 完全依賴資料來源方式 ID的生成規則,讀取控制完全由資料來源控制,
一篇文章徹底搞懂es6 Promise
app .org image status end .json apple objects 同步 前言 Promise,用於解決回調地獄帶來的問題,將異步操作以同步的操作編程表達出來,避免了層層嵌套的回調函數。 既然是用來解決回調地獄的問題,那首先來看下什麽是回調地獄
一篇文章徹底搞懂Java虛擬機器
概念: 虛擬機器:指以軟體的方式模擬具有完整硬體系統功能、執行在一個完全隔離環境中的完整計算機系統 ,是物理機的軟體實現。常用的
一篇文章徹底搞懂Java的大Class到底是什麼
作者在之前工作中,面試過很多求職者,發現有很多面試者對Java的 `Class` 搞不明白,理解的不到位,一知半解,一到用的時候,就不太會用。 因為自己本身以前剛學安卓的時候,甚至做安卓2,3年後,也是對 java的 `Class`不是太清楚,所以想寫一篇關於Java `Class` 的文章,沒有那麼多專業
一篇文章徹底搞定所有GC面試問題
眾所周知,在C++,記憶體的管理是程式設計師的任務,包括物件的建立和回收(記憶體的申請和釋放),而在java中,我們可以通過以下四種方式建立物件(面試考點): new關鍵字建立物件 clone方法克隆產生物件 反序列化獲得物件 通過反射建立物件 而
一篇文章徹底讀懂HashMap之HashMap原始碼解析(下)
put函式原始碼解析 //put函式入口,兩個引數:key和value public V put(K key, V value) { /*下面分析這個函式,注意前3個引數,後面 2個引數這裡不太重要,因為所有的put 操作後面的2個引數預設值都一樣 */
一篇文章徹底讀懂HashMap之HashMap原始碼解析(上)
就身邊同學的經歷來看,HashMap是求職面試中名副其實的“明星”,基本上每一加公司的面試多多少少都有問到HashMap的底層實現原理、原始碼等相關問題。 在秋招面試準備過程中,博主閱讀過很多關於HashMap原始碼分析的文章,漫長的拼湊式閱讀之後,博主沒有看到過
JDK8 HashMap原始碼解析,一篇文章徹底讀懂HashMap
在秋招面試準備中博主找過很多關於HashMap的部落格,但是秋招結束後回過頭來看,感覺沒有一篇全面、通俗易懂的講解HashMap文章(可能是博主沒有找到),所以在秋招結束後,寫下了這篇文章,盡最大的努力把HashMap原始碼講解的通俗易懂,並且儘量涵蓋面試中HashM
10年架構師圖解單鏈表,一篇圖文徹底搞懂
§單鏈表的定義 每一個節點都有一個向後的指標(引用)指向下一個節點,最後一個節點指向NULL表示結束,有一個Head(頭)指標指向第一個節點表示開始。如下圖: §單鏈表的特點 耗子戴眼鏡,鼠目寸光 我們只能拿到頭節點,(在不逐個遍歷的情況下),後面還有多
一篇文章徹底弄懂Base64編碼原理
電子郵件 日常使用 byte 課程 sms 不能 class 打印 底層實現 在互聯網中的每一刻,你可能都在享受著Base64帶來的便捷,但對於Base64的基礎原理又了解多少?今天這篇博文帶領大家了解一下Base64的底層實現。 Base64的由來 目前Bas
一篇文章快速搞懂 Atomic(原子整數/CAS/ABA/原子引用/原子陣列/LongAdder)
前言 相信大部分開發人員,或多或少都看過或寫過併發程式設計的程式碼。併發關鍵字除了Synchronized,還有另一大分支Atomic。如果大家沒聽過沒用過先看基礎篇,如果聽過用過,請滑至底部看進階篇,深入原始碼分析。 提出問題:int執行緒安全嗎? 看過Synchronized相關文章的小夥伴應該知道其是不
git使用教程-一篇文章全搞定哦
Git使用教程 Git是什麼 文章轉載自 程式碼飛:https://code.bywind.cn/2018/07/14/170/ Git是一個開源的分散式版本控制系統,用於敏捷高效地處理任何或小或大的專案。 Git是 Linus Torvalds 為了幫助管理 Li
一篇文章徹底弄明白java中的二進位制運算
在java中的二進位制運算子有:<<(左移保留符號位), >>(右移保留符號位), >>>(右移,符號位也一起移動), ~(按位取反), ^(異或,相同為0,不同為1), &(邏輯與) ,|(邏輯或),下面我們就來一個一個解釋
一篇文章徹底瞭解清楚什麼是負載均衡
負載均衡是高可用網路基礎架構的的一個關鍵組成部分,有了負載均衡,我們通常可以將我們的應用伺服器部署多臺,然後通過負載均衡將使用者的請求分發到不同的伺服器用來提高網站、應用、資料庫或其他服務的效能以及可靠性。 為什麼要引入負載均衡 先看一個沒有負載均衡機制的web架
一篇文章徹底瞭解小程式
小程式 基礎知識 小程式實現原理 微信 iOS 執行在 webkit(蘋果開源的瀏覽器核心),Android 執行在 X5(QQ瀏覽器核心)。 支付寶 小程式呼叫系統的 API 小程式的架構 小程式與 Andro
一篇文章完全搞清楚 scoket read/write 返回碼、阻塞與非阻塞、異常處理 等讓你頭疼已久的問題
我認為,想要熟練掌握Linux下的TCP/IP網路程式設計,至少有三個層面的知識需要熟悉: 1. TCP/IP協議(如連線的建立和終止、重傳和確認、滑動視窗和擁塞控制等等) 2. Socket I/O系統呼叫(重點如read/write),這是TCP/IP協議在應用層表現出來的行為。 3. 編寫Perfo
探祕Netty7:一篇文章,讀懂Netty的高效能架構之道
Netty是一個高效能、非同步事件驅動的NIO框架,它提供了對TCP、UDP和檔案傳輸的支援,作為一個非同步NIO框架,Netty的所有IO操作都是非同步非阻塞的,通過Future-Listener機制,使用者可以方便的主動獲取或者通過通知機制獲得IO操作結果。 作為當前最流
一篇文章能夠看懂基礎源代碼之JAVA篇
不可 condition 多個 訪問權限 自增 一個數 abs gen amp java程序開發使用的工具類包:JDK(java development kit)java程序運行需要使用的虛擬機:JVM,只需要安裝JRE (java runtime environment)
一篇文章徹底理解Redis持久化:RDB和AOF
 ### 為什麼需要持久化? Redis對資料的操作都是基於記憶體的,當遇到了程序退出、伺服器宕機等意外情況,如果沒有持久化機
一篇文章透徹解讀聚類分析及案例實操
1 聚類分析介紹 1.1 基本概念 聚類就是一種尋找資料之間一種內在結構的技術。聚類把全體資料例項組織成一些相似組,而這些相似組被稱作聚類。處於相同聚類中的資料例項彼此相同,處於不同聚類中的例項彼此不同。聚類技術通常又被稱為無監督學習,因為與監督學習不同,在聚類中那