
基於Storm的WordCount
Storm WordCount 工作過程
Storm 版本:
1、Spout 從外部資料來源中讀取資料,隨機發送一個元組物件出去;
2、SplitBolt 接收 Spout 中輸出的元組物件,將元組中的資料切分成單詞,並將切分後的單詞發射出去;
3、WordCountBolt 接收 SplitBolt 中輸出的單詞陣列,對裡面單詞的頻率進行累加,將累加後的結果輸出。
Java 版本:
1、讀取檔案中的資料,一行一行的讀取;
2、將讀到的資料進行切割;
3、對切割後的陣列中的單詞進行計算。
Hadoop 版本:
1、按行讀取檔案中的資料;
2、在 Mapper()函式中對每一行的資料進行切割,並輸出切割後的資料陣列;
原始碼
storm的配置、eclipse裡maven的配置以及建立專案部分省略。
Mainclass
package com.test.stormwordcount; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; public class MainClass { public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException { //建立一個 TopologyBuilder TopologyBuilder tb = new TopologyBuilder(); tb.setSpout("SpoutBolt", new SpoutBolt(), 2); tb.setBolt("SplitBolt", new SplitBolt(), 2).shuffleGrouping("SpoutBolt"); tb.setBolt("CountBolt", new CountBolt(), 4).fieldsGrouping("SplitBolt", new Fields("word")); //建立配置 Config conf = new Config(); //設定 worker 數量 conf.setNumWorkers(2); //提交任務 //叢集提交 //StormSubmitter.submitTopology("myWordcount", conf, tb.createTopology()); //本地提交 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("myWordcount", conf, tb.createTopology()); } }
SplitBolt 部分
package com.test.stormwordcount; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class SplitBolt extends BaseRichBolt{ OutputCollector collector; /** * 初始化 */ public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } /** * 執行方法 */ public void execute(Tuple input) { String line = input.getString(0); String[] split = line.split(" "); for (String word : split) { collector.emit(new Values(word)); } } /** * 輸出 */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word")); } }
CountBolt 部分
package com.test.stormwordcount;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
public class CountBolt extends BaseRichBolt{
OutputCollector collector;
Map<String, Integer> map = new HashMap<String, Integer>();
/** * 初始化 */
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/** * 執行方法 */
public void execute(Tuple input) {
String word = input.getString(0);
if(map.containsKey(word)){
Integer c = map.get(word);
map.put(word, c+1);
}else{
map.put(word, 1);
}
//測試輸出
System.out.println("結果:"+map);
}
/** * 輸出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
} SpoutBolt 部分
package com.test.stormwordcount;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class SpoutBolt extends BaseRichSpout{
SpoutOutputCollector collector;
/** * 初始化方法 */
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/** * 重複呼叫方法 */
public void nextTuple() {
collector.emit(new Values("hello world this is a test"));
}
/** * 輸出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("test"));
}
} POM.XML 檔案內容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.test</groupId>
<artifactId>stormwordcount</artifactId>
<version>0.9.6</version>
<packaging>jar</packaging>
<name>stormwordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.test.stormwordcount.MainClass</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>遇到的問題
基於Storm的WordCount需要eclipse安裝了maven外掛,之前的大資料實踐安裝的eclipse版本為Eclipse IDE for Eclipse Committers4.5.2,這個版本不自帶maven外掛,後續安裝失敗了幾次(網上很多的教程都已經失效),這裡分享一下我成功安裝的方法:
使用連結下載,Help->Install New SoftWare
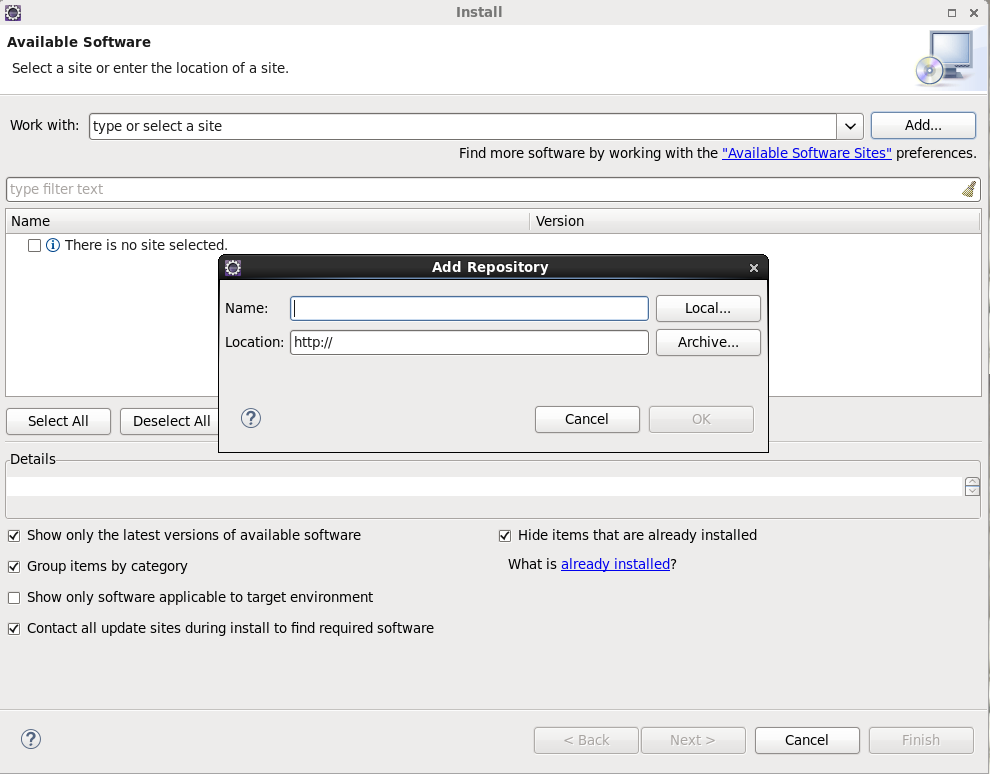
點選Add,name輸入隨意,在location輸入下載eclipse的maven外掛,下載地址可以這樣獲取
點選連線:http://www.eclipse.org/m2e/index.html 進入網站後點擊download,拉到最下面可以看到很多eclipse maven外掛的版本和釋出時間,選在適合eclipse的版本複製連結即可。建議取消選中Contack all update sites during install to find required software(耗時太久)。
但是安裝成功後還是無法配置(這裡原因不太清楚,沒找到解決辦法),就直接上官網換成自己maven外掛的JavaEE IDE了...
後續的maven的配置這些都比較順利,第一次建立maven-archetype-quickstat專案報錯,試了網上很多辦法都還沒成功,然後開啟 Windows->Preferencs->Maven->Installation發現之前配置了的maven的安裝路徑沒了...重新配置了下就可以建立專案了。
最後執行成功的結果:

相關推薦
SOA與基於CDIF的API的聯動
網絡協議 sca 流行 大發 一致性 ice 們的 硬件 形象 幾千年來,巴別塔的故事一直是人類面對的一個核心的困境。為了交流和溝通我們人類創造出語言,但溝通與交流仍然存在障礙……相同語言之間的溝通依語境的不同,尚且存在巨大的鴻溝,
python基礎之socket編程-------基於tcp的套接字實現遠程執行命令的操作
logs lose stream res std 遠程控制 python log out 遠程實現cmd功能: import socket import subprocess phone=socket.socket(socket.AF_INET,socket.SOC
國家商用password(五)基於SM2的軟件授權碼生成及校驗
clas 信息 ecp register 方法 序列號 mod 生成 pub 將公開密鑰算法作為軟件註冊算法的優點是Cracker非常難通過跟蹤驗證算法得到註冊機。以下。將介紹使用SM2國密算法進行軟件註冊的方法。 生成授權碼 選擇SM2橢圓曲線參數(P,a,b,N,
day39-Spring 08-Spring的AOP:基於AspectJ的註解
ima spring mage 開發 技術 asp day3 cnblogs ring 基於AspectJ的註解的開發要重點掌握. day39-Spring 08-Spring的AOP:基於AspectJ的註解
從零開始——基於角色的權限管理01(補充)
itl jsp mage logs log sonar class htm -1 此博文較為詳細的介紹從零開始——基於角色的權限管理01文中的兩個部分的流程(解釋代碼)。 1) index.jsp中提交跳轉action action的login,獲取jsp頁面傳
Web驗證碼圖片的生成-基於Java的實現
submit esc page resp ioe 代碼 oge cnblogs pro 驗證碼圖片是由程序動態產生的,每次訪問的內容都是隨機的。那麽如何采用程序動態產生圖片,並能夠顯示在客戶端頁面中呢?原理很簡單,對於java而言,我們首先開發一個Servlet,這個Se
基於OpenGL編寫一個簡易的2D渲染框架-04 繪制圖片
著色器 drawtext 結構 渲染 images ron renderer make 制圖 閱讀文章前需要了解的知識,紋理:https://learnopengl-cn.github.io/01%20Getting%20started/06%20Textures/
聊天程序(基於Socket、Thread)
客戶端信息 -- 聊天程序 soc 數組 net 運行 人的 圖解 聊天程序簡述 1、目的:主要是為了闡述Socket,以及應用多線程,本文側重Socket相關網路編程的闡述。如果您對多線程不了解,大家可以看下我的上一篇博文淺解多線程 。 2、功能:此聊天程序功能實現了服
day39-Spring 11-Spring的AOP:基於AspectJ的XML配置方式
asp 技術 mage bsp aop src xml配置方式 img aspectj day39-Spring 11-Spring的AOP:基於AspectJ的XML配置方式
基於upd的socketserver,即udp的多線程
rip strip() pri socket send while handle for hand 服務端 #udp服務端多進程import socketserverclass My_server(socketserver.BaseRequestHandler): d
基於udp的socket
nco utf utf-8 decode dcl 收發信息 是否 客戶端 用戶 服務端 #udp叫用戶數據報協議,它不會出現粘包形象,但會出現信息缺失#udp服務端單進程‘‘‘import socketudpserver =socket.socket(socket.AF_I
基於tcp的socketserver,即tcp的多線程
握手 for 數據 ket 函數 線程 listen utf-8 thread tcp是數據流式的,它的收發信息,是通過管道的.在進行鏈接時,必須雙方同時答應,故有三次握手,四次斷開機制服務端import socketserver #用於進行都並發,即服務端能同時接收多個
Asp.net基於session實現購物車的方法
lai 程序 clas contain ext info border mode man 本文實例講述了asp.net基於session實現購物車的方法。分享給大家供大家參考,具體如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1
2.3 基於寬度優先搜索的網頁爬蟲原理講解
什麽 每一個 empty 目錄 except open 要求 and ref 上一節我們下載並使用了寬度優先的爬蟲,這一節我們來具體看一下這個爬蟲的原理。 首先,查看HTML.py的源代碼。 第一個函數: def get_html(url): try:
基於矢量數據的逆地理編碼功能實現
逆地理編碼 地圖矢量數據 地圖地物搜索 地圖範圍搜索 地圖框選搜索 地理編碼和逆地理編碼概述地理編碼,是指將大家熟悉的地址文字描述,轉換為經緯度,如輸入某某省、某某市、某某路,在地圖上根據經緯度定位到輸入的地圖上的某個點,直觀的顯示所在位置。逆地理編碼是指將經緯度轉化為大家都能看懂文字描述
簡單的登錄基於代碼的
上帝 logs password 賬號密碼 com 購物平臺 .com class usr 1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import getpass 5 print(‘歡迎來到不知
基於OpenGL編寫一個簡易的2D渲染框架-05 渲染文本
new 坐標 false 證明 ont 獲取 simple 了解 param 閱讀文章前需要了解的知識:文本渲染 https://learnopengl-cn.github.io/06%20In%20Practice/02%20Text%20Rendering/ 簡要步
基於Cocos2dx + box2d 實現的憤慨的小鳥Demo
space 程序 box nbsp 源碼 source span cocos2 lan 1. Demo初始界面 2. 遊戲界面 3. 精確碰撞檢測 4. 下載 壓縮文件文件夾 AngryBird source 憤慨的小鳥Demo源碼,基於C
擼代碼--linux進程通信(基於共享內存)
-- log pac 字符指針 clas fcn eno csdn printf 1.實現親緣關系進程的通信,父寫子讀 思路分析:1)首先我們須要創建一個共享內存。 2)父子進程的創建要用到fork函數。fork函數創建後,兩
pyDash:一個基於 web 的 Linux 性能監測工具
亮顯 依賴關系 stat 運行 tld 下一個 google avi 查看 pyDash 是一個輕量且基於 web 的 Linux 性能監測工具,它是用 Python 和 Django 加上 Chart.js 來寫的。經測試,在下面這些主流 Linux 發行版上可運行:Ce