
小白學 Python 爬蟲(26):為啥上海二手房你都買不起

人生苦短,我用 Python
前文傳送門:
小白學 Python 爬蟲(1):開篇
小白學 Python 爬蟲(2):前置準備(一)基本類庫的安裝
小白學 Python 爬蟲(3):前置準備(二)Linux基礎入門
小白學 Python 爬蟲(4):前置準備(三)Docker基礎入門
小白學 Python 爬蟲(5):前置準備(四)資料庫基礎
小白學 Python 爬蟲(6):前置準備(五)爬蟲框架的安裝
小白學 Python 爬蟲(7):HTTP 基礎
小白學 Python 爬蟲(8):網頁基礎
小白學 Python 爬蟲(9):爬蟲基礎
小白學 Python 爬蟲(10):Session 和 Cookies
小白學 Python 爬蟲(11):urllib 基礎使用(一)
小白學 Python 爬蟲(12):urllib 基礎使用(二)
小白學 Python 爬蟲(13):urllib 基礎使用(三)
小白學 Python 爬蟲(14):urllib 基礎使用(四)
小白學 Python 爬蟲(15):urllib 基礎使用(五)
小白學 Python 爬蟲(16):urllib 實戰之爬取妹子圖
小白學 Python 爬蟲(17):Requests 基礎使用
小白學 Python 爬蟲(18):Requests 進階操作
小白學 Python 爬蟲(19):Xpath 基操
小白學 Python 爬蟲(20):Xpath 進階
小白學 Python 爬蟲(21):解析庫 Beautiful Soup(上)
小白學 Python 爬蟲(22):解析庫 Beautiful Soup(下)
小白學 Python 爬蟲(23):解析庫 pyquery 入門
小白學 Python 爬蟲(24):2019 豆瓣電影排行
小白學 Python 爬蟲(25):爬取股票資訊
引言
看到題目肯定有同學會問,為啥不包含新房,emmmmmmmmmmm
說出來都是血淚史啊。。。

小編已經哭暈在廁所,那位同學趕緊醒醒,太陽還沒下山呢。
別看不起二手房,說的好像大家都買得起一樣。

分析
淡不多扯,先進入正題,目標頁面的連結小編已經找好了:https://sh.lianjia.com/ershoufang/pg1/ 。

房源數量還是蠻多的麼,今年正題房產行業不景氣,據說 房價都不高。
小編其實是有目的的,畢竟也來上海五年多了,萬一真的爬出來的資料看到有合適,對吧,順便也能幫大家探個路。

首先還是分析頁面的連結資訊,其實已經很明顯了,在連結最後一欄有一個 pg1 ,小編猜應該是 page1 的意思,不信換成 pg2 試試看,很顯然的麼。
隨便開啟一個房屋頁面進到內層頁面,看下資料:
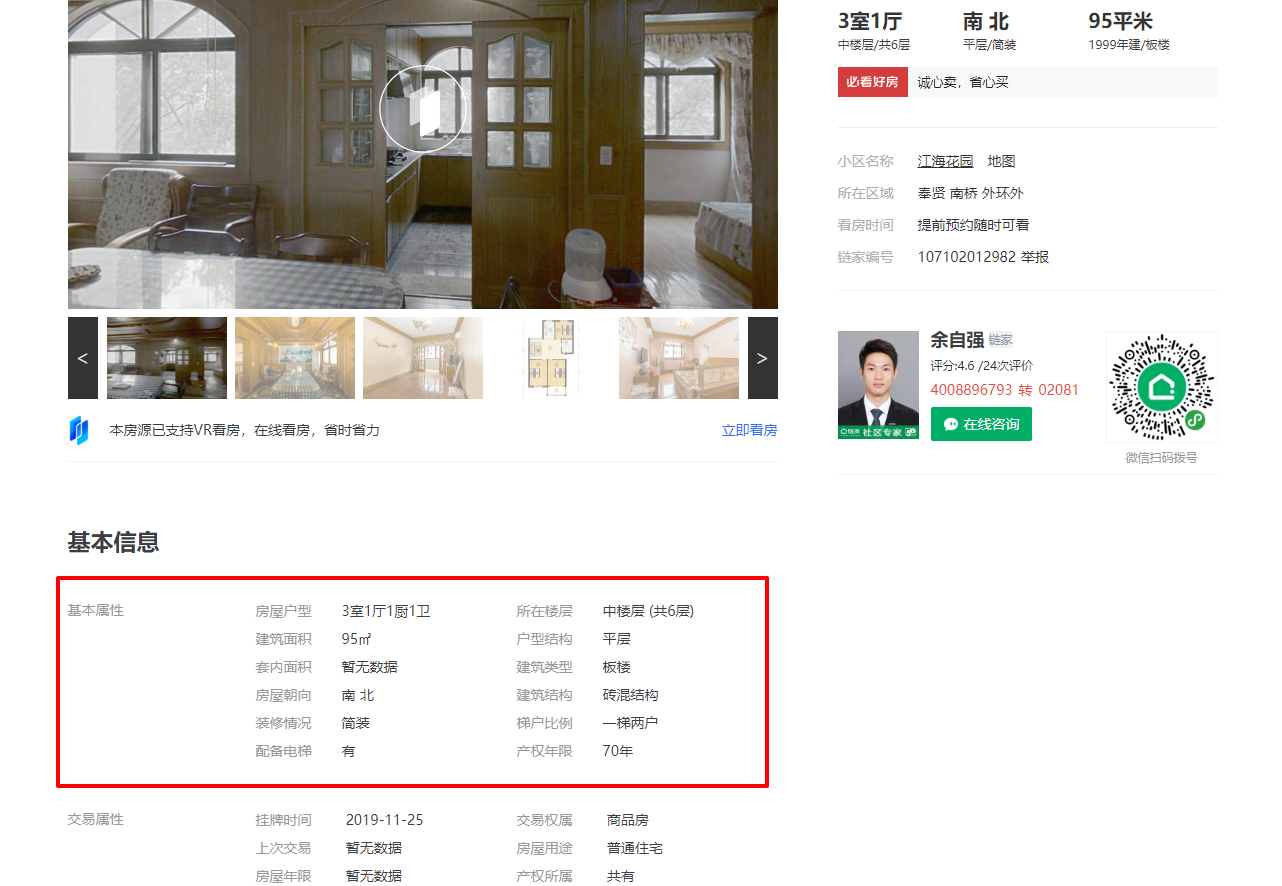
資料還是很全面的嘛,那詳細資料就從這裡取了。
順便再看下詳情頁的連結:https://sh.lianjia.com/ershoufang/107102012982.html 。
這個編號從哪裡來?
小編敢保證在外層列表頁的 DOM 結構裡肯定能找到。

這就叫老司機的直覺,秀不秀就完了。

擼程式碼
思想還是老思想,先將外層列表頁的資料構建一個列表,然後通過迴圈那個列表爬取詳情頁,將獲取到的資料寫入 Mysql 中。
本篇所使用到的請求庫和解析庫還是 Requests 和 pyquery 。
別問為啥,問就是小編喜歡。
因為簡單。

還是先定義一個爬取外層房源列表的方法:
def get_outer_list(maxNum):
list = []
for i in range(1, maxNum + 1):
url = 'https://sh.lianjia.com/ershoufang/pg' + str(i)
print('正在爬取的連結為: %s' %url)
response = requests.get(url, headers=headers)
print('正在獲取第 %d 頁房源' % i)
doc = PyQuery(response.text)
num = 0
for item in doc('.sellListContent li').items():
num += 1
list.append(item.attr('data-lj_action_housedel_id'))
print('當前頁面房源共 %d 套' %num)
return list這裡先獲取房源的那個 id 編號列表,方便我們下一步進行連線的拼接,這裡的傳入引數是最大頁數,只要不超過實際頁數即可,目前最大頁數是 100 頁,這裡最大也只能傳入 100 。
房源列表獲取到以後,接著就是要獲取房源的詳細資訊,這次的資訊量有點大,解析起來稍有費勁兒:
def get_inner_info(list):
for i in list:
try:
response = requests.get('https://sh.lianjia.com/ershoufang/' + str(i) + '.html', headers=headers)
doc = PyQuery(response.text)
# 基本屬性解析
base_li_item = doc('.base .content ul li').remove('.label').items()
base_li_list = []
for item in base_li_item:
base_li_list.append(item.text())
# 交易屬性解析
transaction_li_item = doc('.transaction .content ul li').items()
transaction_li_list = []
for item in transaction_li_item:
transaction_li_list.append(item.children().not_('.label').text())
insert_data = {
"id": i,
"danjia": doc('.unitPriceValue').remove('i').text(),
"zongjia": doc('.price .total').text() + '萬',
"quyu": doc('.areaName .info').text(),
"xiaoqu": doc('.communityName .info').text(),
"huxing": base_li_list[0],
"louceng": base_li_list[1],
"jianmian": base_li_list[2],
"jiegou": base_li_list[3],
"taoneimianji": base_li_list[4],
"jianzhuleixing": base_li_list[5],
"chaoxiang": base_li_list[6],
"jianzhujiegou": base_li_list[7],
"zhuangxiu": base_li_list[8],
"tihubili": base_li_list[9],
"dianti": base_li_list[10],
"chanquan": base_li_list[11],
"guapaishijian": transaction_li_list[0],
"jiaoyiquanshu": transaction_li_list[1],
"shangcijiaoyi": transaction_li_list[2],
"fangwuyongtu": transaction_li_list[3],
"fangwunianxian": transaction_li_list[4],
"chanquansuoshu": transaction_li_list[5],
"diyaxinxi": transaction_li_list[6]
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(i, ':寫入完成')
except:
print(i, ':寫入異常')
continue兩個最關鍵的方法已經寫完了,接下來看下小編的成果:
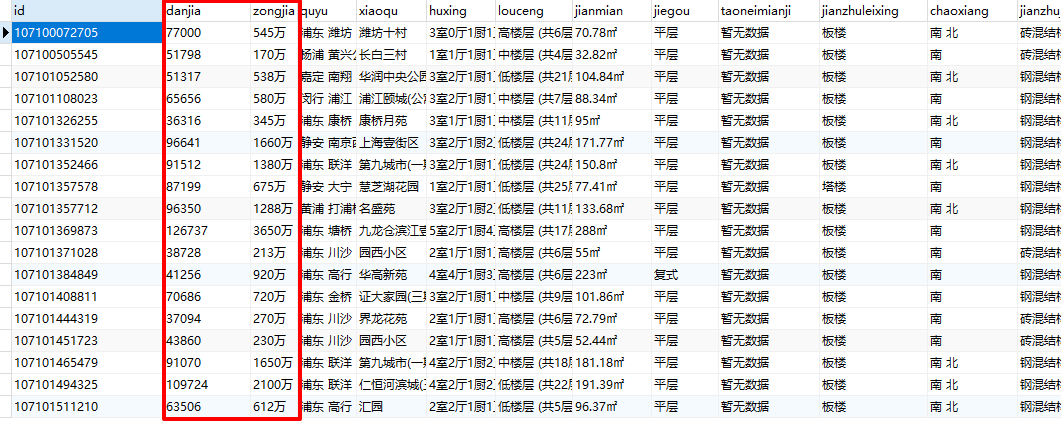
這個價格看的小編血壓有點高。

果然還是我大魔都,不管幾手房,價格看看就好。
小結
從結果可以看出來,鏈家雖然是說的有 6W 多套房子,實際上我們從頁面上可以爬取到的攏共也就只有 3000 套,遠沒有達到我們想要的所有的資料。但是小編增加篩選條件,房源總數確實也是會變動的,應該是做了強限制,最多隻能展示 100 頁的資料,防止資料被完全爬走。
套路還是很深的,只要不把資料放出來,泥萌就不要想能爬到我的資料。對於一般使用者而言,能看到前面的一些資料也足夠了,估計也沒幾個人會翻到最後幾頁去看資料。

本篇的程式碼就到這裡了,如果有需要獲取全部程式碼的,可以訪問程式碼倉庫獲取。
示例程式碼
本系列的所有程式碼小編都會放在程式碼管理倉庫 Github 和 Gitee 上,方便大家取用。
示例程式碼-Github
示例程式碼-Gi