
大規模機器叢集-故障自動處理(二)
本篇開始介紹具體的實現過程,為表述方便,先定義一些名詞,
-
AutoRepairSystem: 故障自動維修系統, 縮寫為ARS
-
原子操作:任務的最小操作,機器任務通常是指重啟、重灌
-
運維人員:運維工程師= SRE = OP,系統工程師 = sys
-
遠端管理工具: 遠端控制操作物理機器的工具,如ipmi、ilo
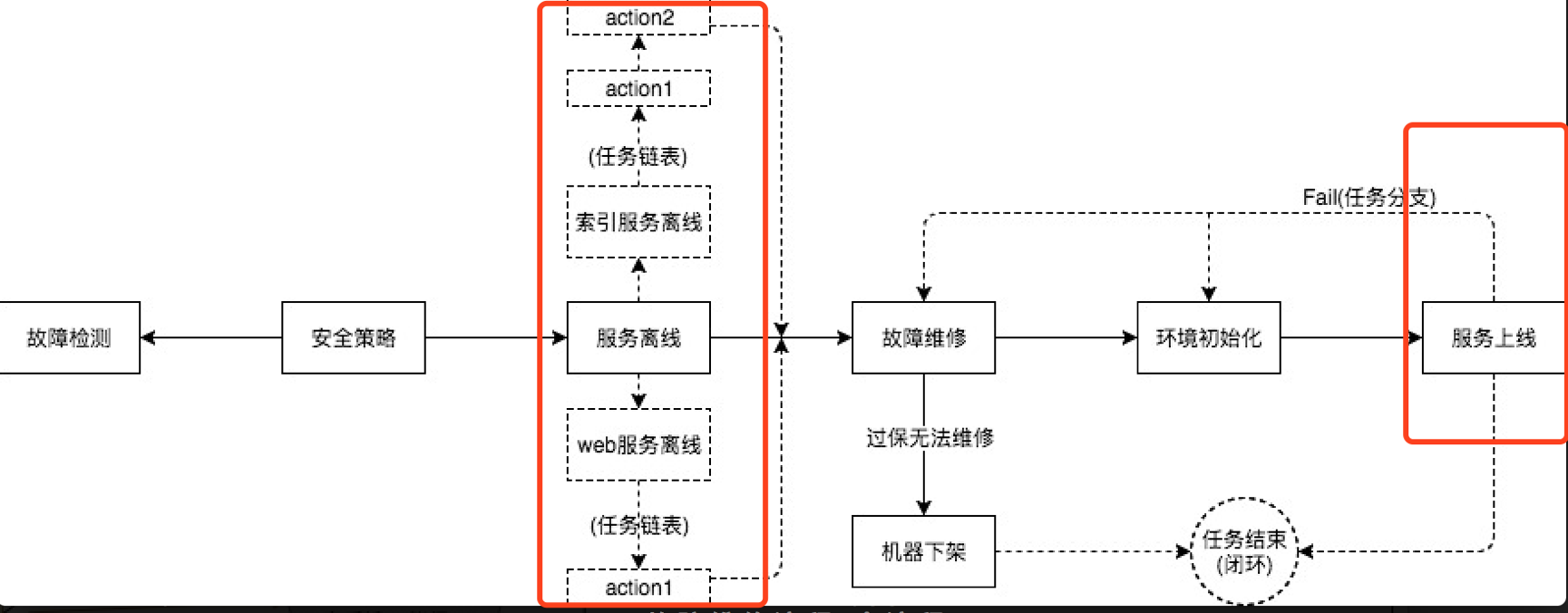
先來看ARS的整體檢視和流程圖,
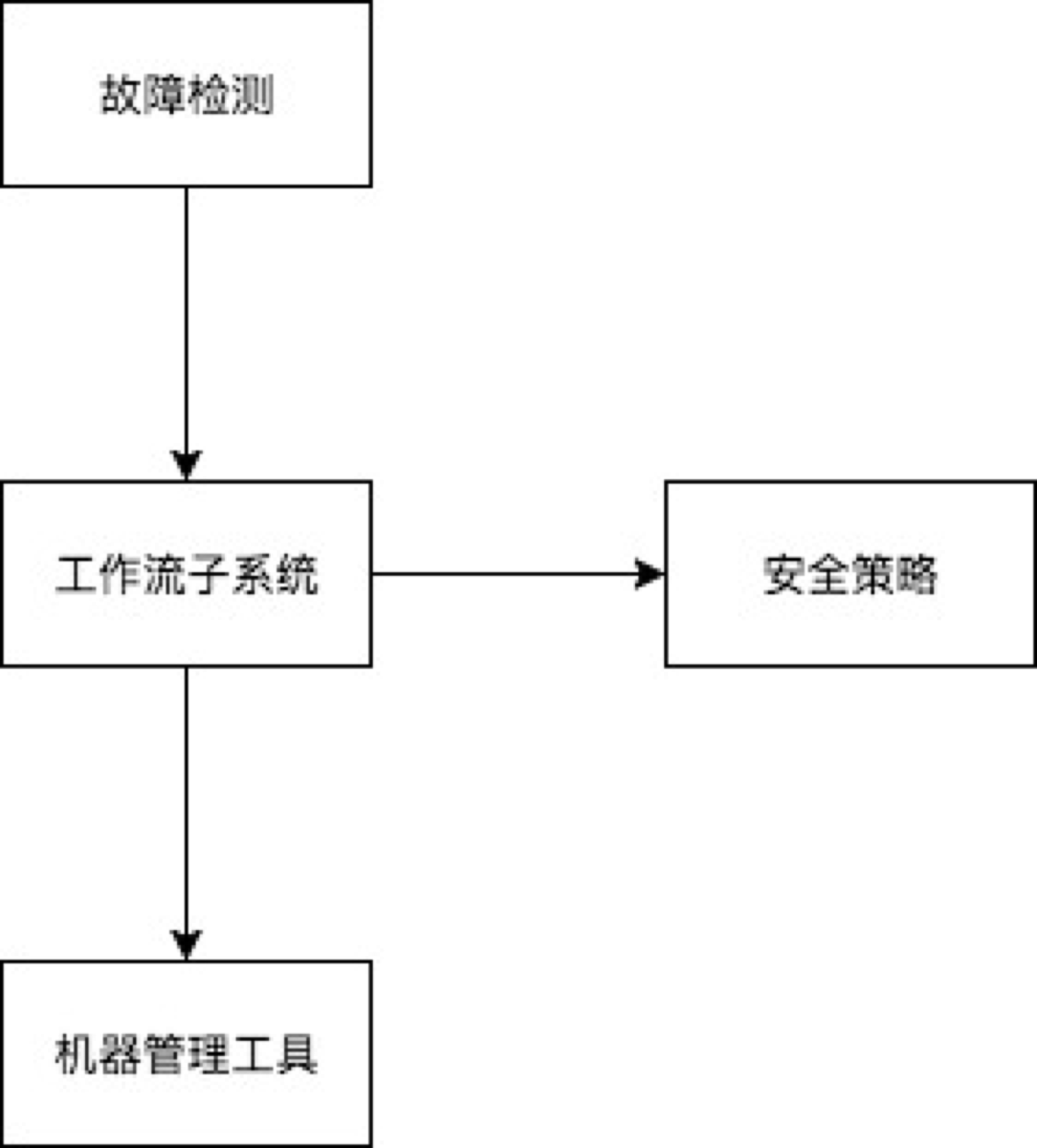

ARS的工作流程,
-
故障檢測: 每5分鐘發起一次故障檢測,獲取當前時刻整個叢集的故障機器列表,推送到工作流子系統
-
安全策略: 遍歷故障機器列表,依次執行安全策略,過濾不符合要求的機器,得到一個可安全執行重啟、重灌的機器列表
-
服務離線: 遍歷可安全操作的機器列表,執行服務離線
-
故障維修: 服務離線後,發起重啟、維修操作,輪詢機器狀態,直至重啟成功或維修完成
-
環境初始化: 執行環境初始化,保證機器環境符合業務需求
-
服務上線: 恢復服務,檢查服務達到可服務狀態,流程結束
接下來將介紹工作流子系統,這是所有具體操作任務執行的基礎;
再依次介紹上述流程中的關鍵環節: 服務上下線,故障檢測,安全策略,維修工具及SLA;
然後通過一個線上例子,說明整體的工作流程;
最後分享系統上線後的執行資料。
2.1 工作流子系統
工作流最基本的功能,是驅動一系列預定義任務順序執行,達到明確的結束狀態;在機器故障自動處理這個問題域裡,對工作流還有閉環、擴充套件性的要求(詳見第一篇的分析).
經過分析統計機器相關的操作任務, 比如機器重啟、重灌、初始化環境、啟動/停止服務、檢視資訊等,抽象出機器操作的任務模型,即”對一組機器執行相同的任務,且任務可以進一步拆分為一系列更小的原子操作組合”,如圖所示,
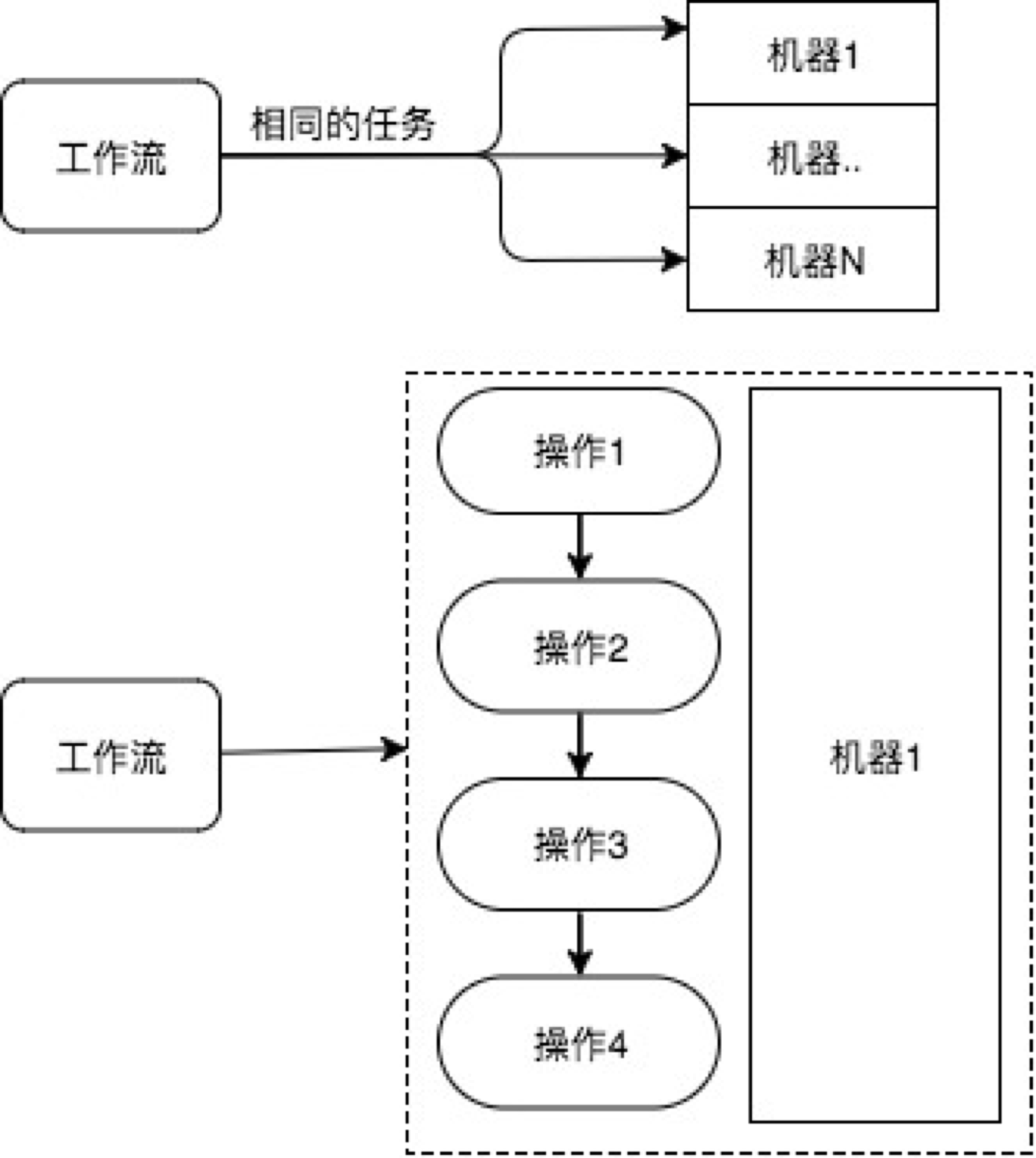
上圖表示對一組機器執行相同的任務,下圖表示,這個任務具體有4個原子操作。
由此,我們可以定義工作流的幾個關鍵類,以及他們的關係,
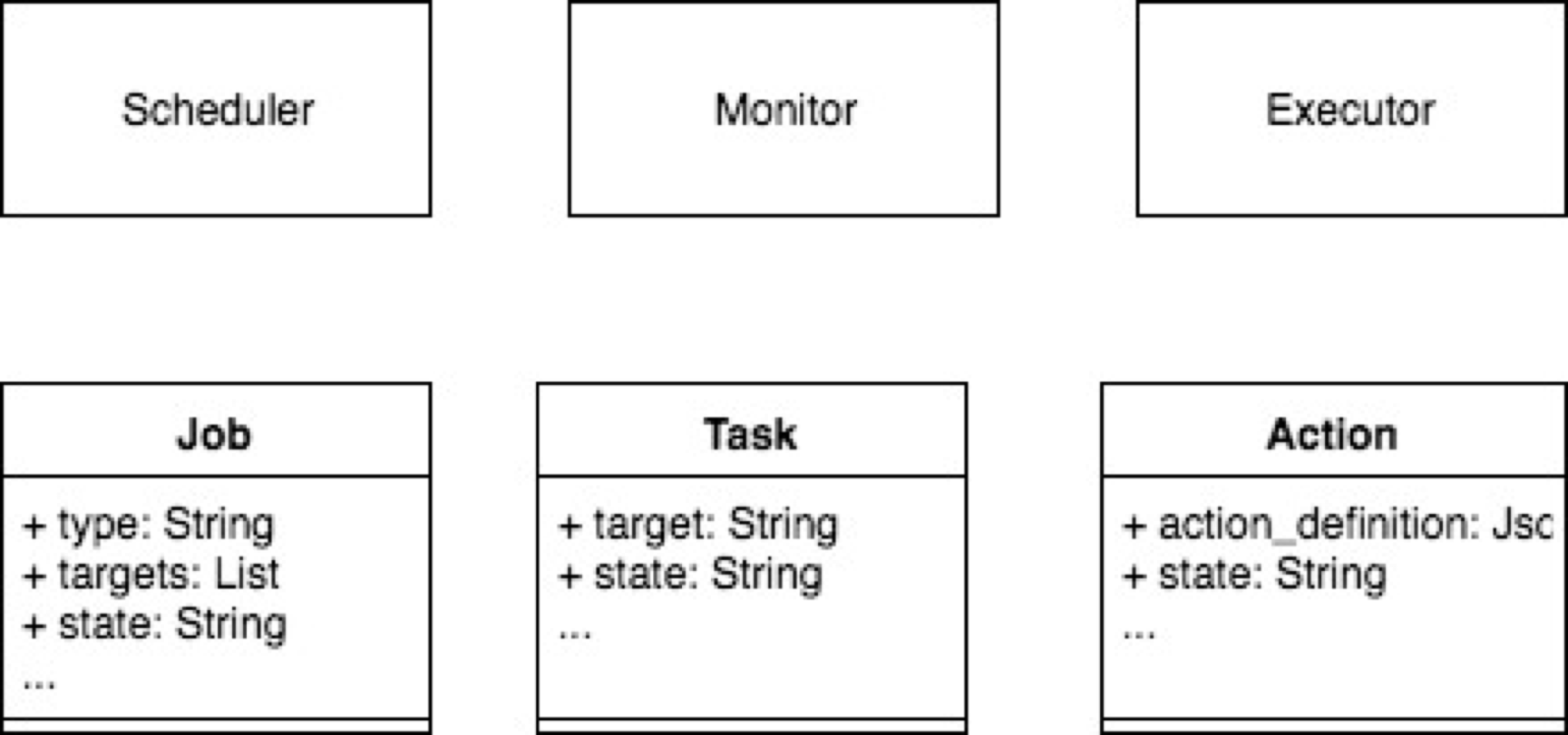
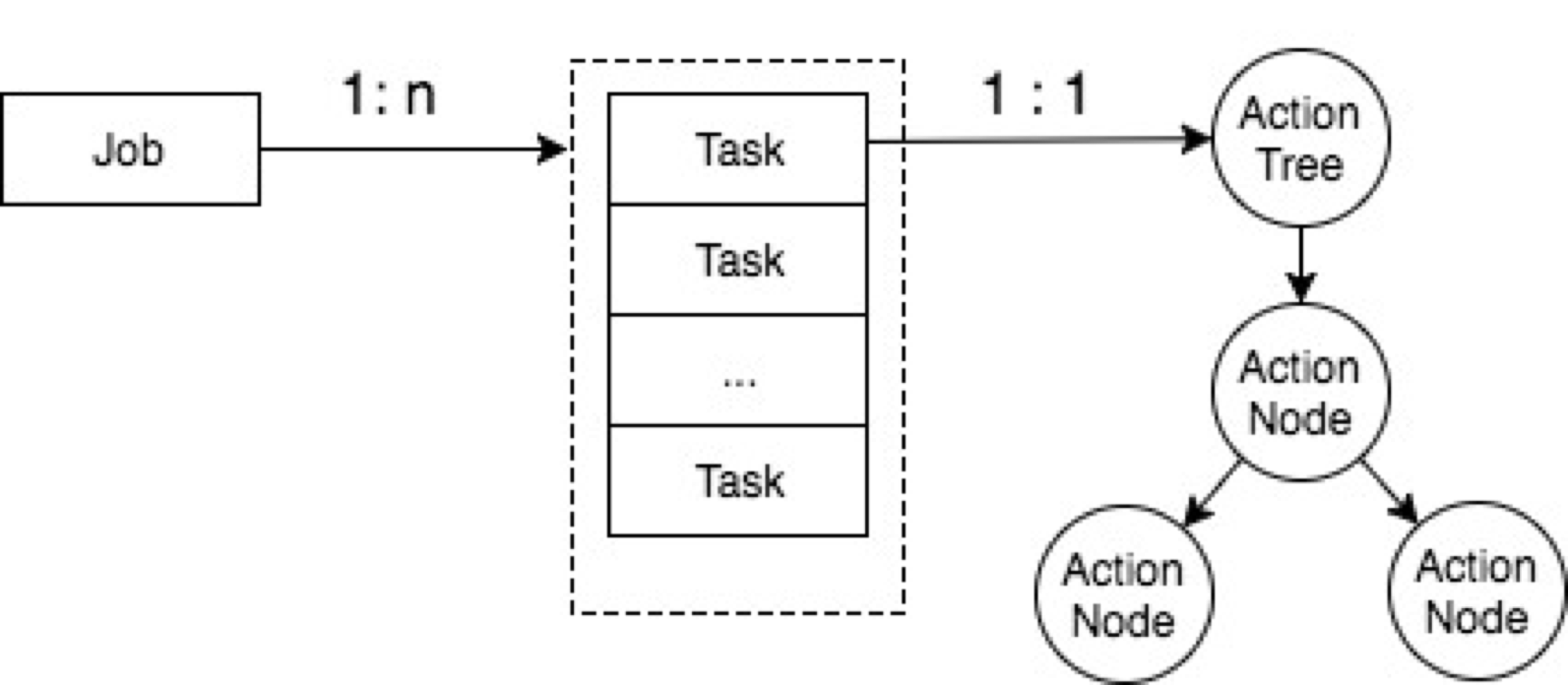
注:為了簡化表述,這裡只列出和流程執行、任務分支、通用性相關的欄位和邏輯,工作流子系統的完整資訊,後續會另寫文章介紹。
-
Job,定義了任務型別以及要操作的目標集合
-
Task,定義了一個具體的操作目標,以及action_tree的root節點
-
Action,定義了業務邏輯的內容和載入方式
-
Scheduler, 排程Job的執行
-
Monitor, 監控 Job、Task、Action 的狀態
-
Executor, 控制Job下的task/action 的執行順序、併發等
接下來重點看看工作流系統是如何達到前文提到的擴充套件性、閉環要求的。
第一點,擴充套件性。
擴充套件性需求,最初來自於不同服務上下線操作的差異,主要是有狀態服務。
它們之間的差異,體現在操作步驟的數量和順序不同。例如,
-
推薦模型服務,要求先尋找可用的機器資源,在新資源上部署相同版本的服務,啟動服務載入資料,判斷資料載入進度,直到達到某個閾值,才算是完成“遷移”,此時才達到可維修的狀態
-
Docker服務,相對簡單,只需向docker發起遷移命令,等待docker返回遷移進度,遷移完成後即可維修
-
Hadoop服務,主要痛點在磁碟故障上,要求維修過程中不能長時間停服,所以維修邏輯很複雜,要先停止本機服務,umount故障磁碟,啟動服務,維修故障磁碟,修復之後再停服,起服,讓Hadoop重新使用這塊磁碟
-
其他無狀態服務相對簡單,通常直接維修即可
可見,不同服務的差異化是不可窮舉的,如果ARS要介入具體的維修邏輯,無異於“攬屎上身”,最終陷入泥潭裡無法自拔。
我們的思路是: 對外提供一套機制,能簡易地將維修邏輯嵌入工作流子系統,實現步驟如下,
-
將複雜任務拆解成多個原子操作,每個原子操作實現為一個python方法,返回值格式固定
-
定義原子操作的執行順序以及分支
只要滿足上述條件,系統就能支援任意數量、任意順序的原子操作集合。
原子操作的python實現如下圖所示,
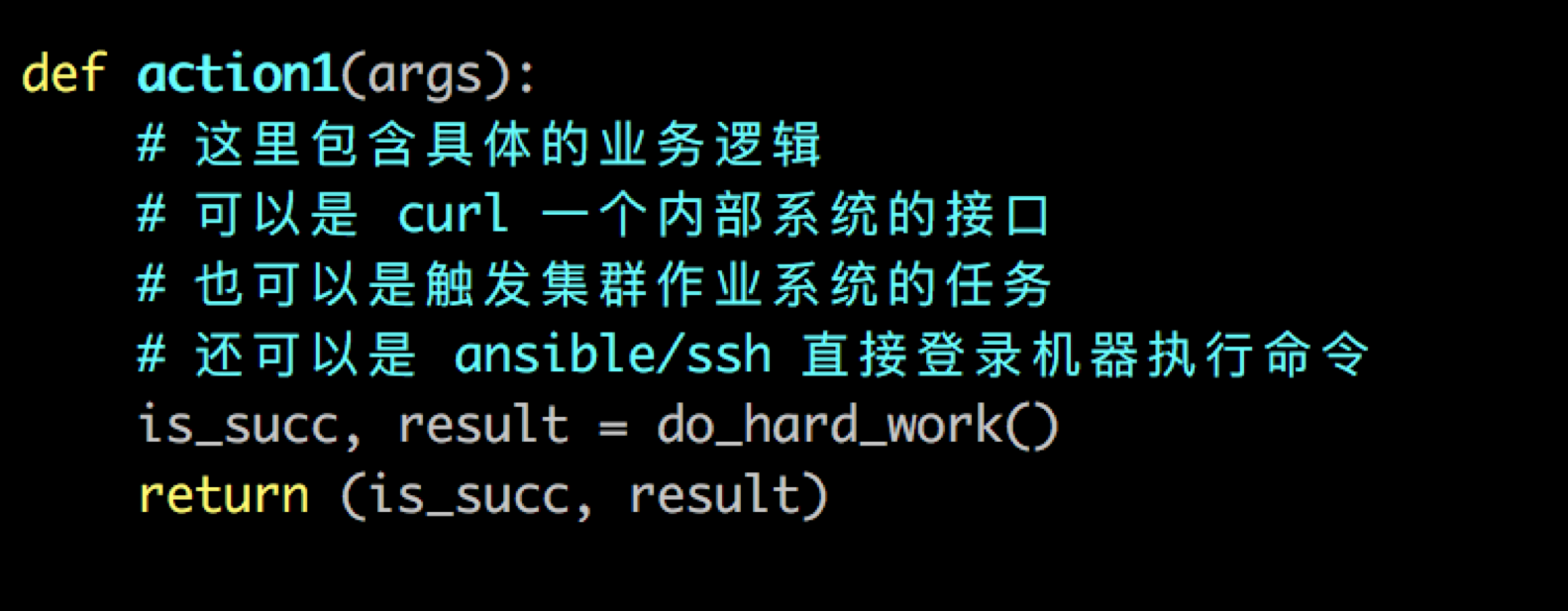
action1為原子操作名字,do_hard_work()方法由業務sre 完成,工作流子系統只負責呼叫, is_succ表明本次操作是否執行成功,result通常是操作結果資訊。
只要按照這個約定編寫的任務,都可註冊到系統裡被執行,哪怕提交人只是用python 包了一坨 shell 指令碼,也是可嵌入系統的,雖然我們在review的時候會“建議”他重寫。
有了原子操作的實現,就可以定義它們的執行順序,我們使用了“樹”的概念,如下圖json配置示例所示,

可以看到,整棵樹有多棵子樹組成,每棵子樹指向一個nodes list,每個node就是一個action, action的數量和順序可以在nodes list裡任意配置擴充套件。
在example_trees裡, action1~action6就是原子操作,執行的順序有兩種可能分支,
action1-> action2 (true)--> action3->action4->結束;
action1-> action2 (false)--> action5->action6->結束;
假設現在業務有一個大的改動,需要在action2之前增加一個操作action7, 並在action6之後,增加一個分支action8, 這隻需在配置上小改動即可實現,
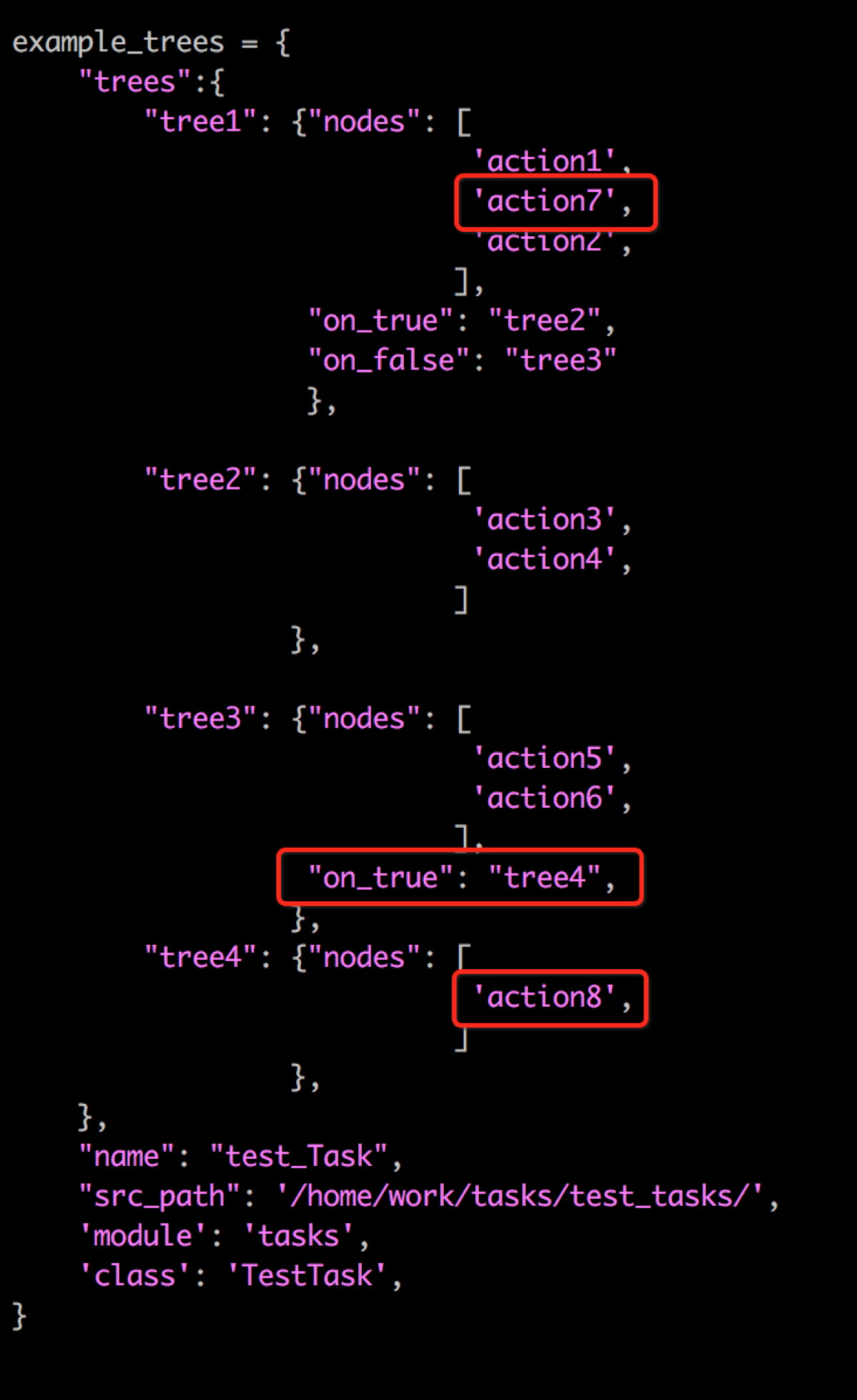
example_trees 會被儲存在Action類的action_definition欄位裡,這個配置記錄了執行邏輯的python 檔案,類和方法; 工作流在執行時,會動態載入相應的類,根據方法名呼叫方法,如下圖所示,

憑藉這些特性,業務sre可以靈活多變的定義自己的任務樹,其中公共部分,由平臺sre編寫,與業務相關部分由業務sre編寫。
第二點,閉環。
以無狀態的 web機器的宕機自動處理流程為例,(這裡為了方便表述,做了簡化)
-
檢測宕機的機器
-
重啟機器
-
如果能起來,檢查程式版本,啟動web 服務,流程結束
-
如果不能起來,則報修硬體故障
-
如果能修復,回到第3步
-
如果不能修復,則檢查是否過保,如果是,則下架機器,流程結束
其流程樹的配置如下,

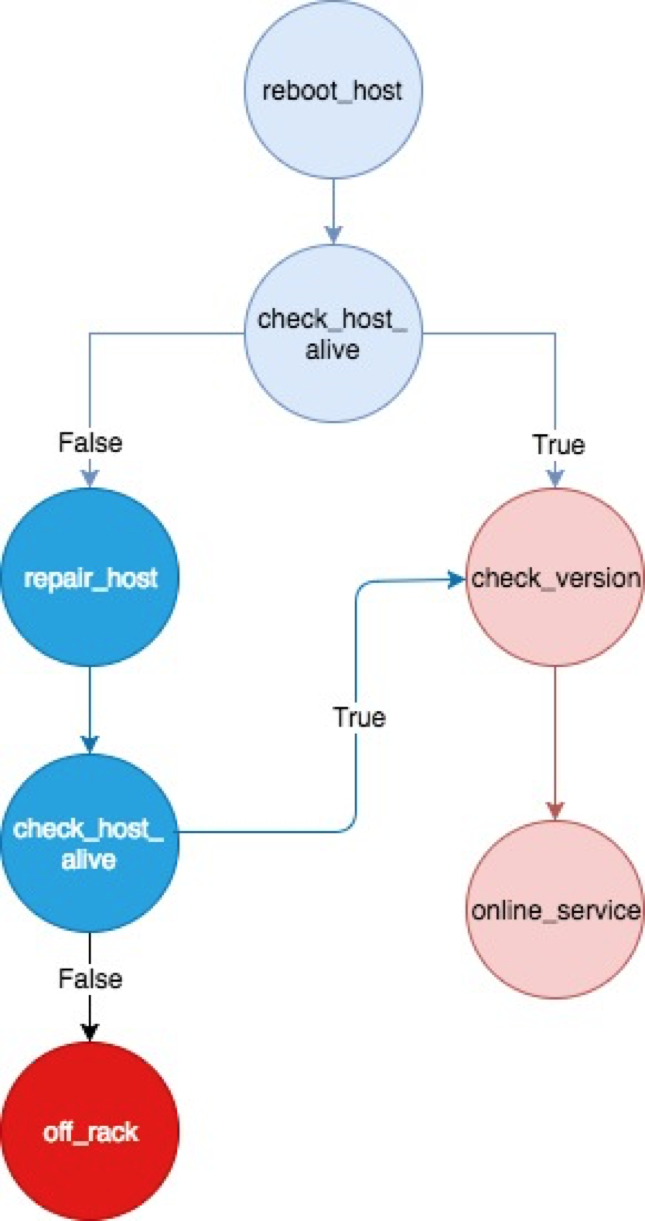
可以看到,reboot_host、check_host_alive、repair_host等action為原子操作;
這棵樹有兩個分支節點,
如果 reboot_host之後 check_host_alive為Ture, 則執行online_service 分支,流程結束;
如果為false, 則執行repair_host 分支,如果能修好,則回到 tree2 ,最後也達到 online_service的狀態, 流程結束;(只要是沒過保,都能修好)
如果修不好,那麼則進入 off_rack 下架流程,流程結束。(通常是機器過保)
這裡之所以反覆強調任務分支,是因為有了任務分支,就可以在各個可能執行失敗的環節,指定下一步的操作,最終將目標操作到一個可預期的狀態(機器要麼被修好重新投入使用,要麼修不好被下架),形成閉環,不用人工介入,真正提高自動化程度。
同時,由於在一開始就設定了維修只有兩種操作:重啟,重灌,這兩種操作都由sys來保證交付時間,所以這棵樹能保證流程是閉環的。
在ARS上線之前,早期的自動工具發起重啟命令之後,機器起不來,通常是人工通知sys 報修,報修之後 sys 再根據機器是否過保來給sre 反饋維修狀態,這個過程,如同黑洞,吞噬了rd-sre-sys-機房外包四方大量的溝通時間, 如圖所示,

工作流子系統還涉及狀態機、併發控制、重試、任務重入、超時、執行進度等,後續另寫文章介紹。
在下一節裡,將介紹故障檢測、安全策略等內容。
2.2故障檢測
故障檢測的完整性、正確性是故障維修自動化的前提。
通過分析歷史機器故障型別,可將故障分為5個層次,如下表,基本覆蓋了sre日常處理的故障。
|
層次 |
異常型別 |
常見問題 |
檢測方式 |
|
業務相關 |
執行異常 |
磁碟空間不足、部署時呼叫的control指令碼返回值異常、目錄許可權 |
Falcon |
|
運維繫統 |
平臺自身異常 |
帳號異常、Executor執行任務異常、部署系統異常 |
Falcon+運維繫統介面 |
|
基礎環境 |
依賴異常 |
環境異常(依賴庫/檔案缺失)、版本不符(核心/python/perl)、limits.conf不符 |
Falcon+shell/python |
|
系統層 |
讀寫異常 |
檔案系統錯誤(Input/Output Error)、檔案系統掛載錯誤(read-only、home未掛載) |
Falcon+shell/python |
|
機器層 |
連線異常 |
硬碟故障, 宕機故障, 記憶體故障, 電源故障, 風扇故障, CPU/GPU故障 |
ping/ssh/Falcon+ipmi |
ARS主要覆蓋了機器層、系統層,下面分別做說明。
磁碟故障
磁碟故障率高的業務型別很多, 如hadoop、索引服務、分散式檔案系統服務、機器學習模型訓練服務等,這些服務的機器,磁碟塊數最高多達36塊,大量讀寫磁碟,造成磁碟故障率很高。
常見的磁碟故障型別有掉盤、讀寫錯誤(Input/Output Error)、漂盤、掛載錯誤、 read-only錯誤、效能劇降(ls /disk/ 超過10分鐘無反應);
磁碟故障的積累,有可能會導致資料丟失,以及拖慢整個系統的效能,所以要儘早檢測到儘早處理。
宕機故障
宕機故障分為完全宕機,假死。
完全宕機(指連續3個小時失去心跳,並且主動ssh 探測失敗的機器),這種情況容易處理,直接進入自動重啟流程;
假死,有如下型別,
l Connection timed out
l Connection closed by remotehost
l Connection reset by peer
l Connection refused
l Connection closed by
這些假死狀態,可能會造成業務受損。
比如機器假死,服務埠還能連線,但實際業務程序內部無法正常工作,如果是前端web機器出現這種情況,會導致業務5xx監控飆升;此時,想手動重啟,ssh已經無法連線,只能通過ilo重啟,或者緊急聯絡機房,處理耗時往往超過半小時。
記憶體故障
記憶體故障時,通常機器還沒有宕機,(在/var/log/message 裡顯示CE error on CPU#1Channel#2_DIMM#1)
rd認為機器還能跑,不願意停服務;
如果積攢到多臺機器出現類似錯誤,極有可能在短時間內出現連續宕機,導致服務容量突然減少,服務效能大幅下降的業務故障,所以對於一些敏感服務,出現這種故障,還是要當作宕機來處理。
電源故障
雙電源是突然斷電、市政施工的保障,如果電源壞了不修,在這種情況下,機器會斷電關機,如果積攢多了,服務容量會突減,影響業務。
風扇故障
不會馬上造成宕機,但是會產生連鎖反應。風扇故障會導致cpu溫度升高,引發宕機。
上述故障檢測的實現,主要是通過 Falcon監控系統 + scripts 實現,涉及了 ping/ssh/ipmi/dmesg/proc/sar…等大量系統命令和系統資訊。
Falcon 執行這些scripts,檢測故障,外部應用就可以從接口裡查詢故障列表資訊,如下,
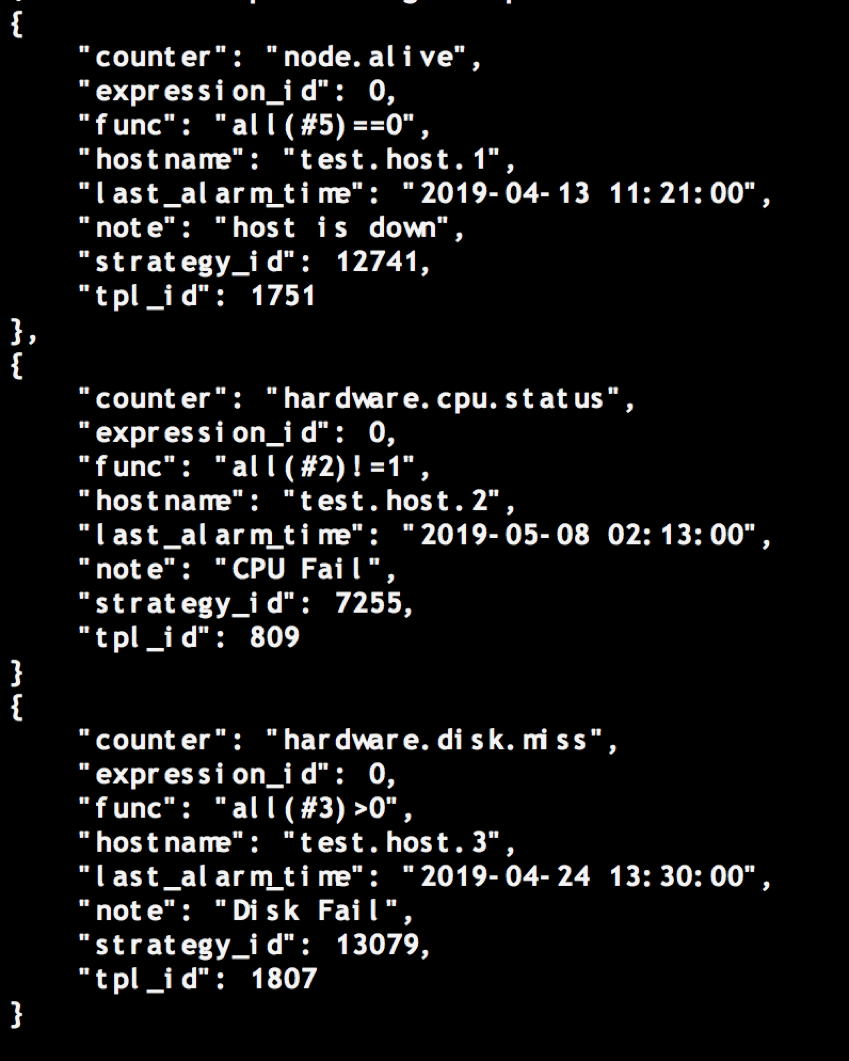
ARS從Falcon拉取當前時刻叢集內所有故障機器的列表,附帶了相應的故障資訊,推送到工作流裡,進行維修。
2.3 安全策略
對機器的操作,通常是重灌、重啟、root環境修改、部署基礎agent等;此類操作往往不可逆且無法暫停,所以需要嚴格的安全策略保證機器操作不影響線上服務或影響最小。
經過“故障檢測”這個環節後,得到一個當前時刻所有故障機器列表,安全策略會對這個列表進行分析過濾,下表是我們使用的安全策略列表,
|
策略 |
作用&應用場景 |
實現 |
|
filter_bw _lists |
黑白名單; 通常用於敏感服務,如支付、隔離環境服務 |
只處理白名單內的機器 跳過黑名單內的機器 |
|
filter_alive_hosts |
過濾掉處於非宕機的機器; 防止誤判,重啟了非宕機的機器 |
1、3分鐘內連續ping機器,如果有響應,則過濾機器 2、過濾可以響應 ssh 請求的機器 3、防止網路抖動誤判,在多個機房 ping,交叉驗證 |
|
filter_switch_fail |
防止交換機故障引起誤判,比如批量機器無法聯通 |
按分鐘統計機器的故障時間,如是同一分鐘內報上來的(falcon採集週期是1分鐘),本次就不會向後端推送任何機 |
|
filter_base_agent |
過濾掉基礎agent埠存活的機器; 某些特殊服務會禁止ping/ssh命令,所以通過基礎agent埠來判斷存活 |
通過 telnet/curl ip:port 判斷基礎agent是否存活,基礎agent存活代表機器存活,過濾機器 |
|
filter_running_service_hosts |
過濾掉有服務處於running狀態的機器; 防止誤判,操作了服務還在執行的機器 |
檢查機器網絡卡流量、磁碟io等指標,超過閾值則認為存在服務,過濾機器 |
|
filter_capacities |
根據服務容量過濾; 防止因操作了機器,導致服務容量不足 |
計算服務容量, 當前running例項數/總例項數 < 閾值(90%),過濾機器 |
|
filter_duplicate |
去重,保證同一時刻同一臺機器只有一個操作任務在執行; 防止多個任務疊加到同一臺機器,出現未預期結果 |
遍歷系統所有任務,如果此機器有處於running的任務,跳過此機器 |
|
filter_pattern |
過濾指定patterns的機器; 這是最嚴格的過濾器,通常是單點服務使用此策略 |
對機器的機器名、節點名、執行服務名、在各類配置中心註冊名進行正則匹配,如果匹配,則過濾機器 |
|
filter_threshold |
閾值保護,保證同時進行的機器操作任務數低於允許維修的數量 |
1、按機房粒度,對於不同的任務型別,如果當前此機房的機器操作任務數大於閾值,跳過此機器 2、按服務(app)粒度,如果當前此服務(app)的機器操作任務數大於閾值,跳過此機器 例如這個例子,當前app1任務數是3,而允許維修的閾值是5,所以只能再發起2臺機器的維修 current_repairing/beijing/app1: 3 threshold /beijing/app1: 5 |
|
filter_by_date |
遵循分級釋出原則,在一個星期內的某一天,只能維修對應機房的機器 |
1、指定每天允許維修的機房 2、遍歷所有機器,如果一臺機器所屬的機房不是當天允許維修的,跳過此機器 |
這個安全策略表,是總結分析多個業務線的歷史case study得出來的, 在線上執行以來,未出現過誤判,保證了自動任務的安全性。
每一個安全策略,實現為工作流裡的一個原子操作,即action,結合上述重啟的例子,json配置如下,(維修的流程也可以使用這些安全策略,這裡不再單獨列出)
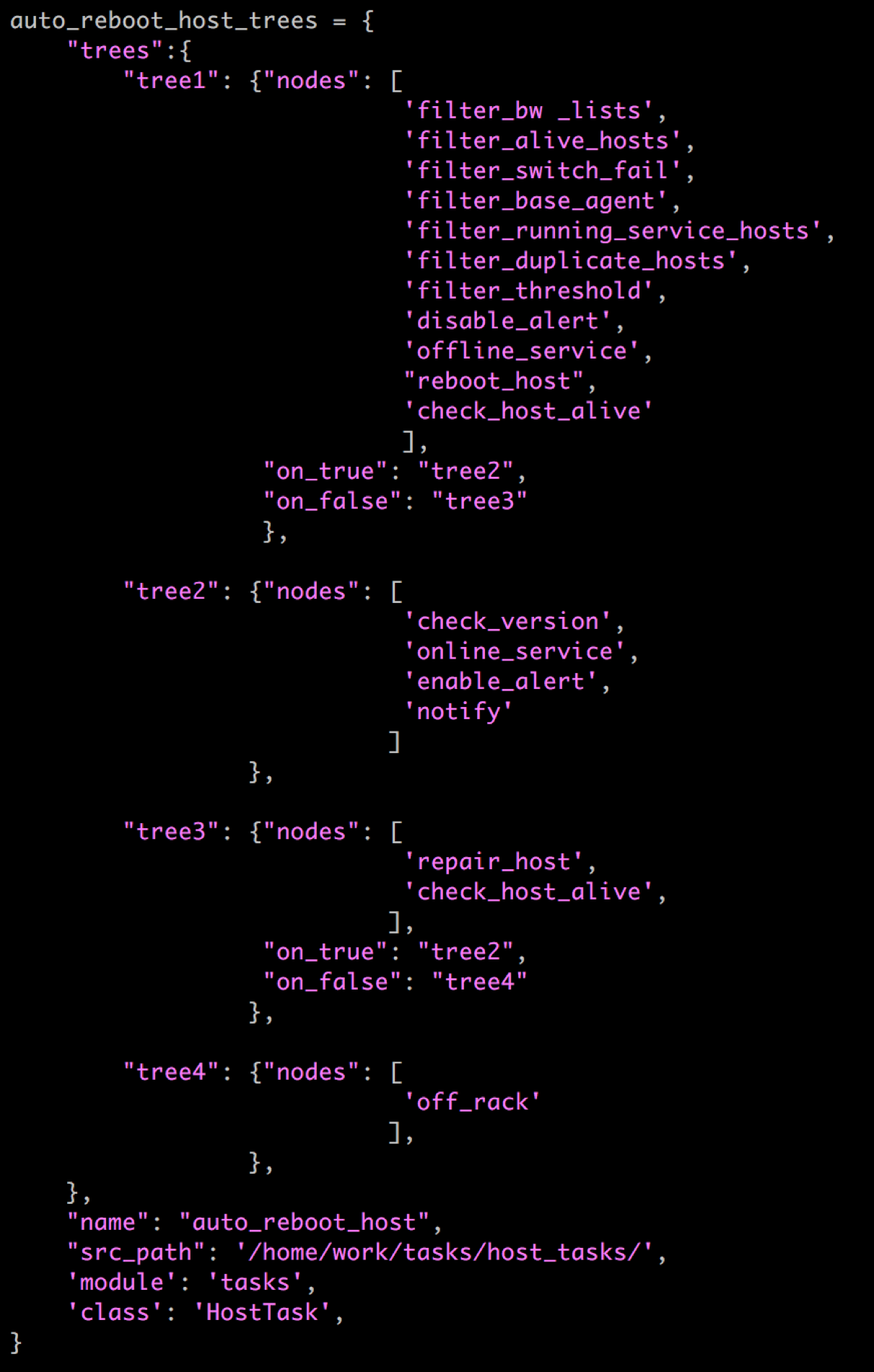
這些策略,可複用也可自由組合、調整順序,這對於接入不同業務的機器進行自動維修,有很大的便利性和靈活性,同時降低了接入成本。
如果業務有自己的安全策略需求,只需按照上述的action 方法規範,自己寫一個安全策略方法,在配置裡指定即可使用。
2.4 維修工具及SLA
機器硬體故障維修,是真實世界中的事件,這個過程需要人去到機房現場,從倉庫拿出配件,走到機架旁邊,拆卸機器,裝配硬體。
所以這個環節是“不可抗力”產生的地方,比如配件備貨不足;節假日廠商人員放假,無法趕赴機房;趕上兩會,機房封禁,不讓進入等各種問題。
1 交付時間
為了達到流程閉環,我們(甲方)和機器廠商(乙方)約定機器維修交付時間, 通常是36小時交付(不同公司、廠商可能不一樣),至於怎麼解決上述“不可抗力”,由乙方負責。
2 遠端管理工具可用率
遠端管理工具是機器操作自動化的必備工具,reboot_host/repair_host底層呼叫的就是ipmi;
為了儘可能地減少機房現場人員操作,我們要求sys保證遠端管理工具可用率達到 99.9%,比如,ilo,ipmi
有了這兩個SLA,我們可以認為 reboot_host、repair_host 這兩個原子操作的最長耗時為36小時,所以維修流程是一定可以閉環的,避免了因任務中斷導致的人工介入。
當然,有了這些,也只是修復了硬體,還有系統引數設定、環境初始化、基礎agent的問題,這個內容比較多,在下一篇講。
將上述提及的技術細節彙總,得到ARS的完整檢視,
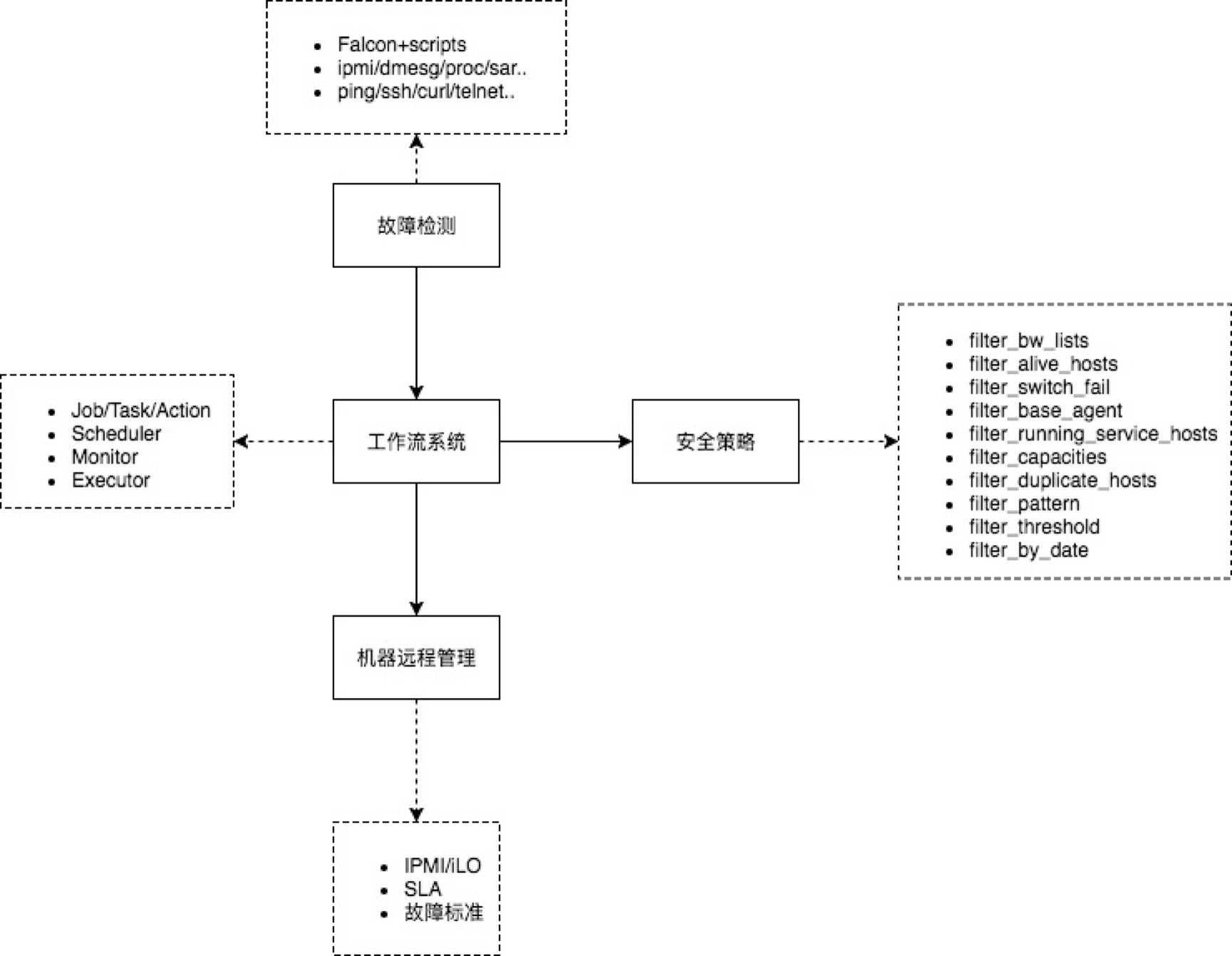
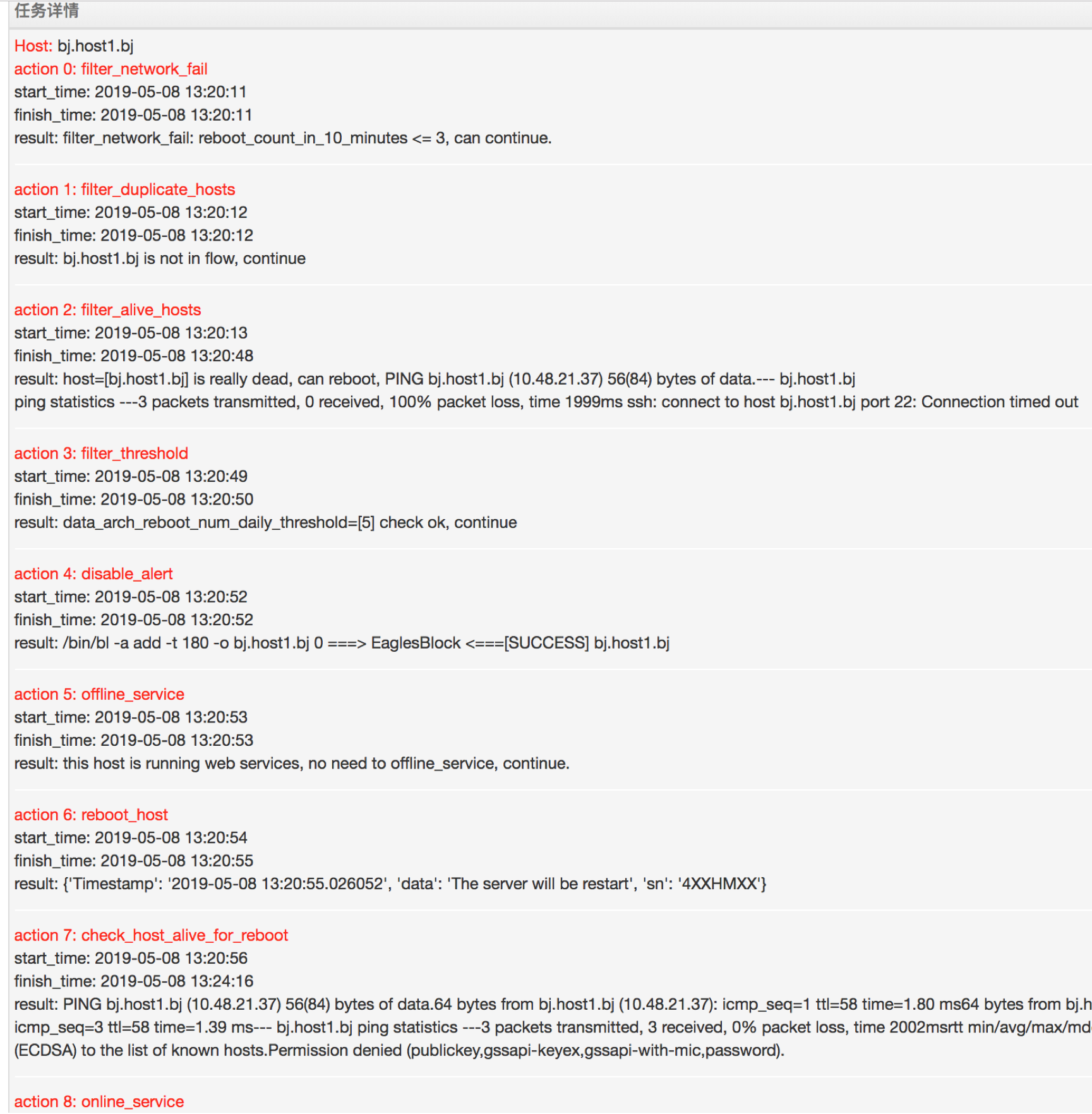
最後,看一個自動重啟的例子,
可以看到任務樹定義的actions 是怎麼執行的,先是執行一系列的 filter_*安全策略,然後遮蔽報警,執行服務離線,發起重啟,然後輪詢機器狀態,直到任務結束。
2.5 系統執行資料
ARS上線後,覆蓋數萬臺機器的故障自動處理,宕機數量保持在10臺左右,所有硬體故障總數量保持在100臺以下,這對於一個數萬臺機器的叢集來說,是非常理想的狀態了。
人力方面,對於20人的sre 團隊,機器故障只需要 0.5人力維護系統正常運轉,例如新服務的接入、業務要求緊急修復之類的情況;當機器規模增長時,人力並不需要相應的增加。
2.6 總結
最後,總結一下幾個關鍵點,
-
標準,定義了有哪些型別的故障,什麼故障執行什麼樣的修復,修復的標準流程
-
閉環,對於機器的操作,用任務分支覆蓋操作成功或失敗的情況,用SLA約束廠商在約定時間內交付機器,保證流程可達到明確的結束狀態,避免人工介入
-
安全,10個安全策略組成的過濾鏈,並支援低成本的增加新策略,保證自動化任務是安全的
在本文中,有一個重要的事項沒有提到,就是環境初始化,這個再下一篇文章講述。
排列文字,重組感受。
我是曲行人,日常寫碼,閒時寫點兒文字,
如果你覺得有點意思,或者有點用,可以關注我,
我將在大腦裡的思維原子做布朗運動時,輸出文字。
公眾號: qxren7
二維碼:

相關推薦
大規模機器叢集-故障自動處理(二)
本篇開始介紹具體的實現過程,為表述方便,先定義一些名詞, AutoRepairSystem: 故障自動維修系統, 縮寫為ARS 原子操作:任務的最小操作,機器任務通常是指重啟、重灌 運維人員:運維工程師= SRE = OP,系統工程師 = sys 遠端管理工具: 遠端控制操作物理機器
couchbase failover 叢集故障自動轉移方案研究!
哥使用了兩臺伺服器,分別部署Couchbase服務端,並模擬一臺伺服器掛了,看是叢集的故障自動轉移功能是否有效,測試中,發現死活不行,查遍了國內外資料,中文的太少了,英文的看不懂,難死哥了。 好歹功夫不負有心人,終於找到了問題的所在。在此與諸位分享! 1、在部落格
叢集故障處理之處理思路以及健康狀態檢查(三十二)
前言 按照筆者的教程,大家應該都能夠比較順暢的完成k8s叢集的部署,不過由於環境、配置以及對Linux、k8s的不瞭解會導致很多問題、異常和故障,這裡筆者分享一些處理技巧和思路,以及部分常見的問題,
JDBC【PreparedStatment、批處理、處理二進制、自動主鍵、調用存儲過程、函數】
參數 高效 gpo 批量處理 資源 key limit 場景 註入 1.PreparedStatement對象 PreparedStatement對象繼承Statement對象,它比Statement對象更強大,使用起來更簡單 Statement對象編譯SQL語句時,如果
Redis 叢集 故障處理 overcommit_memory is set to 0
處理方式 設定 vm.overcommit_memory = 1 方法1: ①新增 vm.overcommit_memory = 1 至配置檔案 /etc/sysctl.conf ②
Python機器學習-資料預處理技術 標準化處理、歸一化、二值化、獨熱編碼、標記編碼總結
資料預處理技術 機器是看不懂絕大部分原始資料的,為了讓讓機器看懂,需要將原始資料進行預處理。 引入模組和資料 import numpy as np from sklearn import preprocessing data = np.array([[3,-1.5,2,-5.4], &nbs
通過大規模機器學習自動調優資料庫引數
資料庫管理系統(DBMS)配置優化是任何資料密集型應用程式努力的基本方面。但這在歷史上是一項艱鉅的任務,因為DBMS有數百個配置引數,控制系統中的一切,比如快取記憶體使用的記憶體量和資料寫入儲存的頻率。這些引數的問題在於它們不標準化(即,兩個DBMS相同引數卻使用
spark機器學習筆記:(二)用Spark Python進行資料處理和特徵提取
下面用“|”字元來分隔各行資料。這將生成一個RDD,其中每一個記錄對應一個Python列表,各列表由使用者ID(user ID)、年齡(age)、性別(gender)、職業(occupation)和郵編(ZIP code)五個屬性構成。4之後再統計使用者、性別、職業和郵編的數目。這可通過如下程式碼
Elasticsearch叢集無法自動叢集處理
在構建Elasticsearch(ES)多節點叢集的時候,通常情況下只需要將elasticsearch.yml中的cluster.name設定成相同即可,ES會自動匹配並構成叢集。但是很多時候可
叢集故障處理之處理思路以及聽診三板斧(三十三)
前言 本篇主要分享一些處理故障和問題絕招,比如聽診三板斧:1)檢視日誌 2)檢視資源詳情和事件 3)檢視資源配置(YAML) 如果還是不太好分析,那就祭出神器——kubectl-debug。 最後,僅需根據問題對症下藥即可。
Java中處理二進制移位
置0 返回 進制 com 移位 移除 bsp int 說服力 我相信,這篇文章讀起來會相當有趣。 文章中編程語言是Java,用Java的原因:第一,Java不做數據溢出校驗,這樣我們可以忽略溢出異常;第二,Java普及率比較高,就像是python或shell,幾乎人人都會吶
Ng第十七課:大規模機器學習(Large Scale Machine Learning)
在線 src 化簡 ima 機器學習 learning 大型數據集 machine cnblogs 17.1 大型數據集的學習 17.2 隨機梯度下降法 17.3 微型批量梯度下降 17.4 隨機梯度下降收斂 17.5 在線學習 17.6 映射化簡和數據並行
第五篇:數據預處理(二) - 異常值處理
ges 方向 分享 site 方式 得到 ros 聚類 測試 前言 數據中如果有某個值偏離該列其他值比較離譜,那麽就有可能是一個異常的值。在數據預處理中,自然需要把這個異常值檢測出來,然後剔除掉,或者光滑掉,或者其他各種方法進行處理。 需要註
OCR表格識別—企事業單位必備自動處理表格軟件
表格識別 雲脈OCR技術 樓主的一些朋友問樓主,樓主所在公司處理大量紙質表格表單使用了哪種方式?那麽,樓主在這裏統一回復一下,樓主所在公司使用的是雲脈OCR表格識別。 可能到這裏有些小夥伴就會問了,雲脈OCR表格識別www.yunmai.cn是什麽?與人工錄入方式相比,有什麽優勢嗎? 首先,
一次DHCP故障的處理
cisco h3c dhcp故障描述:客戶端得不到ip,三層核心設備是cisco6509,二層是h3c e528查看二層交換機配置,dis int bri ,查看哪個口連接電腦,dis dhcp-snooping 查看哪個口得到ip,哪個沒得到ip,dis cu 查看端口下有沒有stp edged-port
大規模機器學習
如何 維度 方法 精確 情況 函數 變化 學習 align 第十三講. 大規模機器學習——Large Scale Machine Learning ============================= (一)、為什麽要大規模機器學習? (二)、Stochastic
【機器學習基石筆記】二、感知機
證明 機器學習 sign 線性可分 缺點 學習 犯錯 nbsp 錯誤 感知機算法: 1、首先找到點,使得sign(wt * xt) != yt, 那麽如果yt = 1,說明wt和xt呈負角度,wt+1 = wt + xt能令wt偏向正角度。 如果yt = -1, 說
常見的手機小故障及處理方法
kkk 常見的手機小故障及處理方法 世界在變,社會在發展,而現如今的手機已經成為人們生活中不可或缺的一部分了。眾所周知不管是什麽東西用久了都會出現或大或小的毛病。如人會生病,手機也和人是一樣的用久了也會出現一些小毛病的。當手機出現問題時,不要著急,深圳莊文展國際手
用JDBC處理二進制類文件
gen ive cal del logs n) rtm pub on() 數據庫中可以存儲整數、小數、字符,也可以存儲音樂視頻等文件,這時候我們可以用二進制的方式。 四種不同大小的二進制類型,單位為字節 TinyBlob 255B Blob 65k MediumBlob
mysql中用HEX和UNHEX函數處理二進制數據的導入導出
sele 函數 str 處理 tab sql 數據 bsp 導入導出 讀取數據並拼寫sql語句,然後進行導入。具體方法為: (1)導出時采用HEX函數讀取數據,把二進制的數據轉為16進制的字符串; select HEX(binField) from testTable; (