
拒絕低效!Python教你爬蟲公眾號文章和連結
本文首發於公眾號「Python知識圈」,如需轉載,請在公眾號聯絡作者授權。
前言
上一篇文章整理了的公眾號所有文章的導航連結,其實如果手動整理起來的話,是一件很費力的事情,因為公眾號裡新增文章的時候只能一篇篇的選擇,是個單選框。
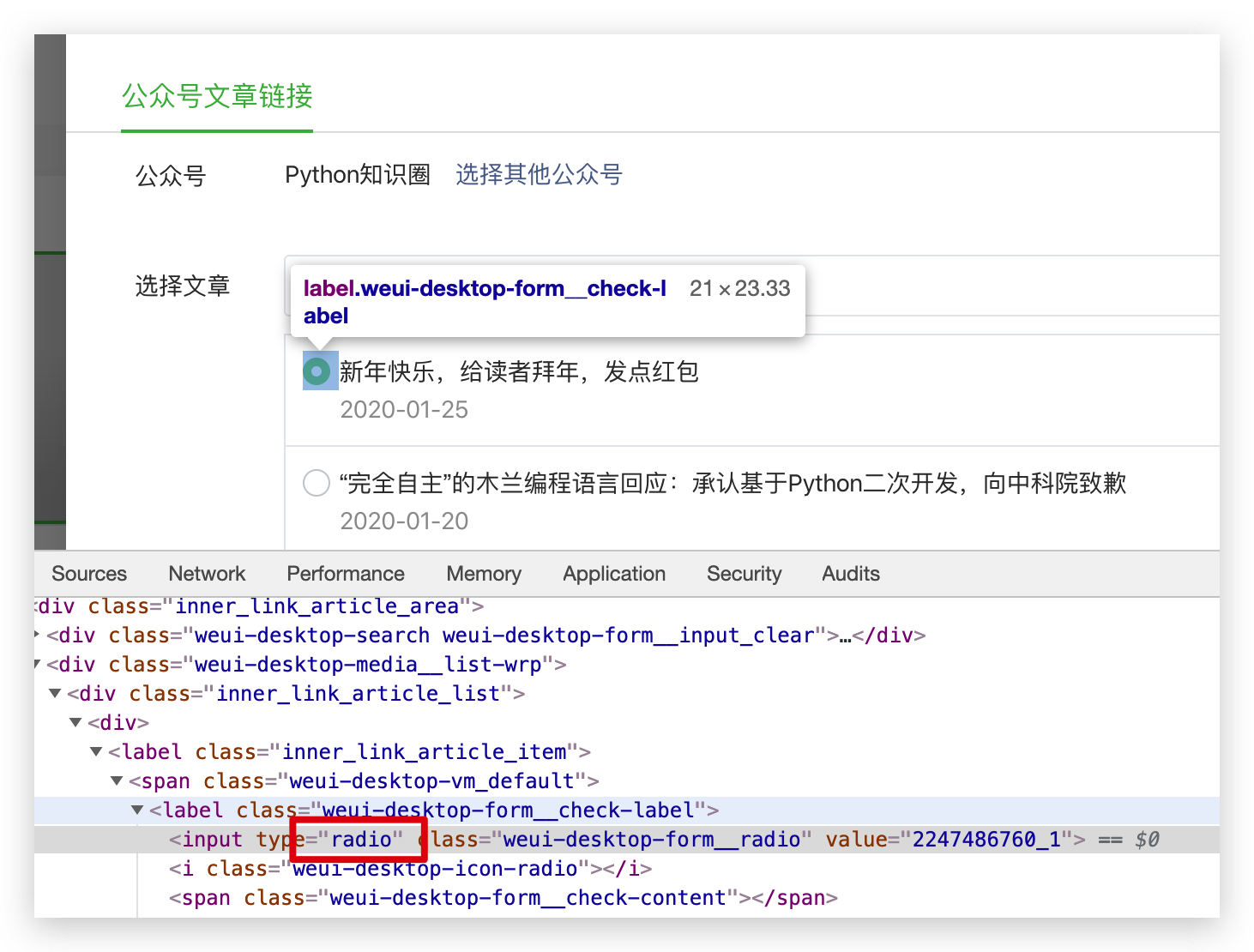
面對幾百篇的文章,這樣一個個選擇的話,是一件苦差事。
pk哥作為一個 Pythoner,當然不能這麼低效,我們用爬蟲把文章的標題和連結等資訊提取出來。
抓包
我們需要通過抓包提取公眾號文章的請求的 URL,參考之前寫過的一篇抓包的文章 Python爬蟲APP前的準備,pk哥這次直接抓取 PC 端微信的公眾號文章列表資訊,更簡單。
我以抓包工具 Charles 為例,勾選容許抓取電腦的請求,一般是預設就勾選的。
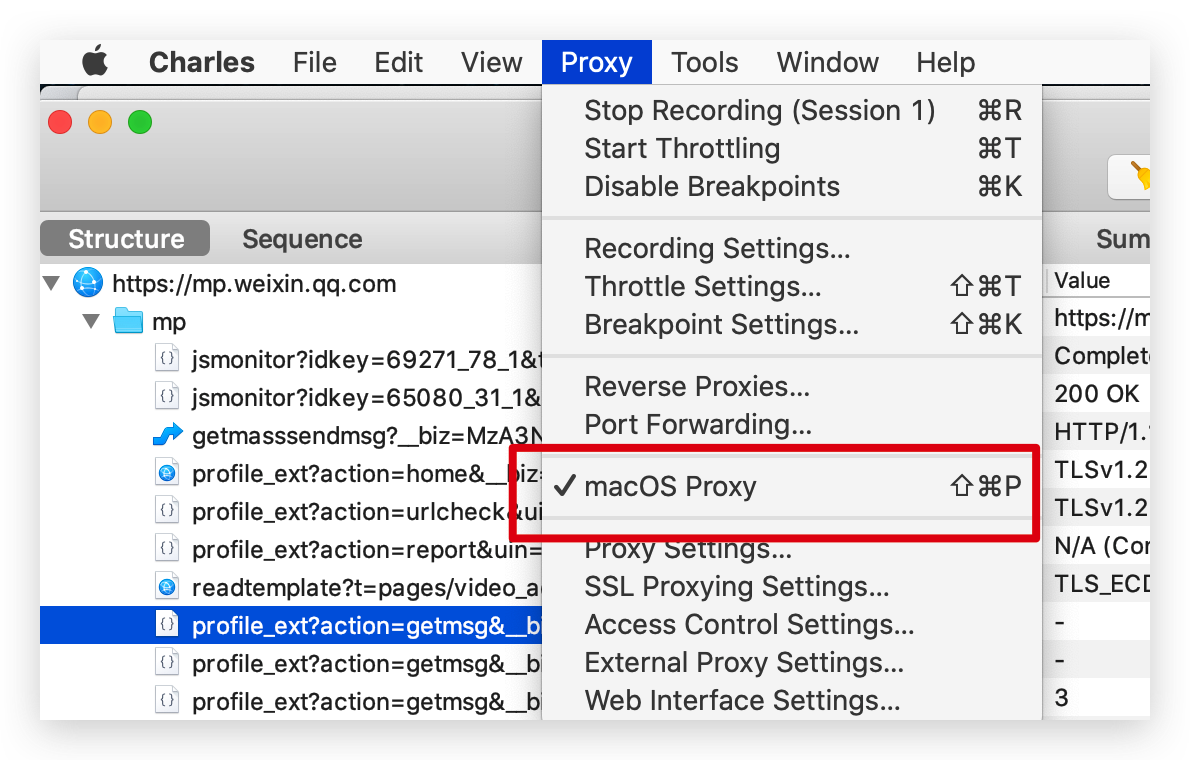
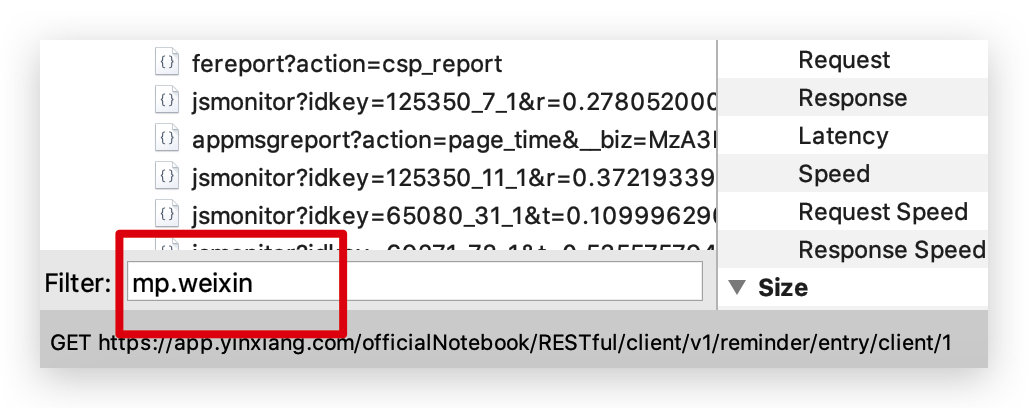
為了過濾掉其他無關請求,我們在左下方設定下我們要抓取的域名。
開啟 PC 端微信,開啟 「Python知識圈」公眾號文章列表後,Charles 就會抓取到大量的請求,找到我們需要的請求,返回的 JSON 資訊裡包含了文章的標題、摘要、連結等資訊,都在 comm_msg_info 下面。
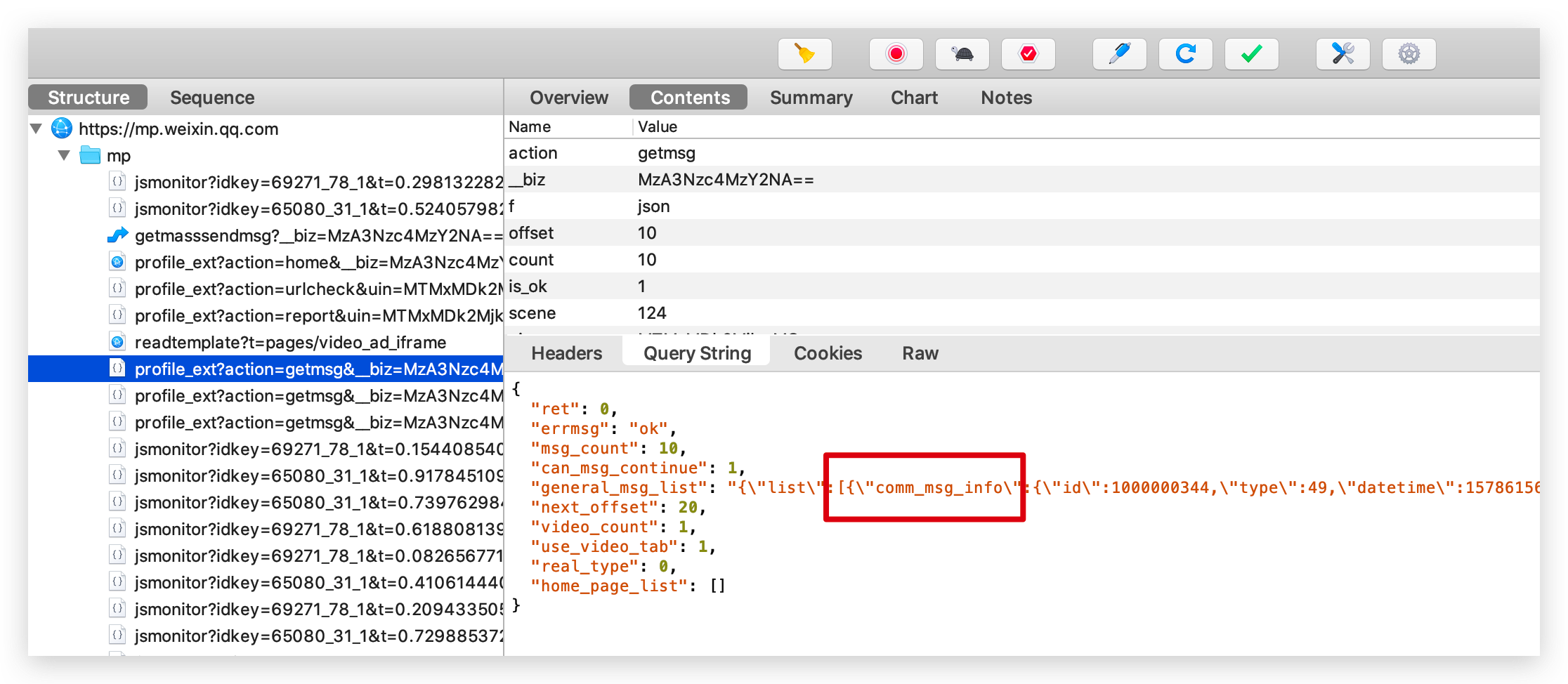

這些都是請求連結後的返回,請求連結 url 我們可以在 Overview 中檢視。
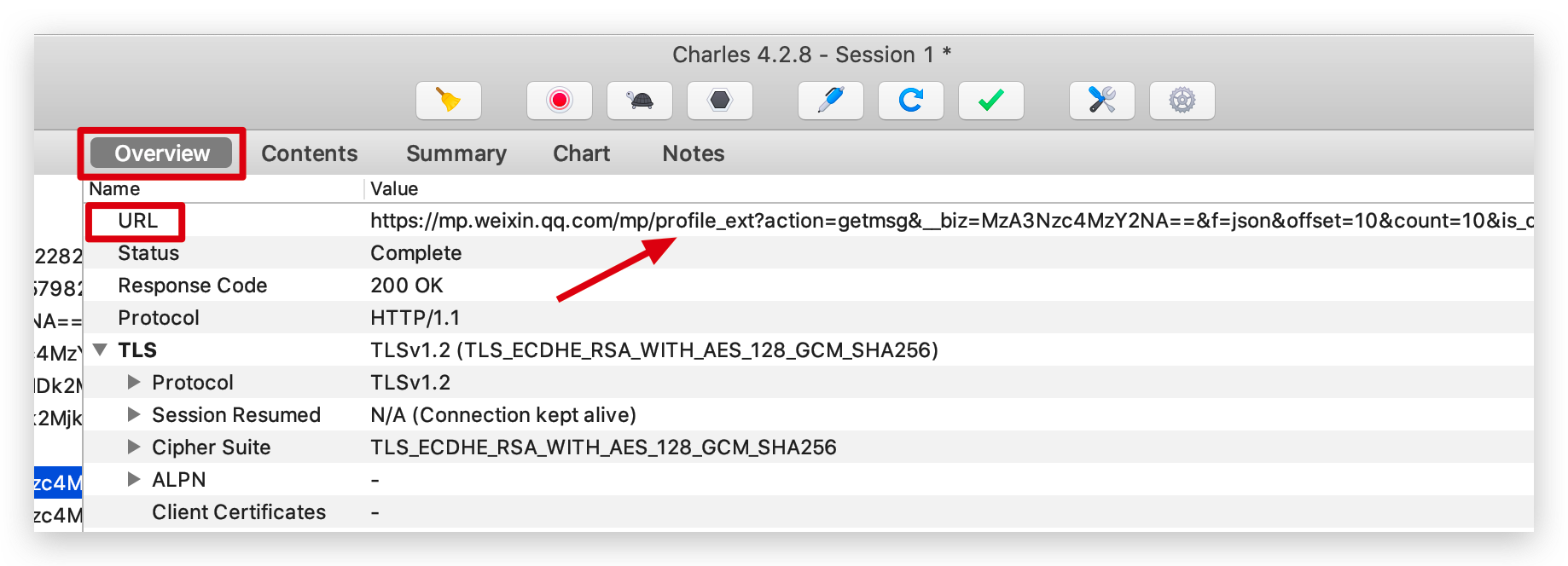
通過抓包獲取了這麼多資訊後,我們可以寫爬蟲爬取所有文章的資訊並儲存了。
初始化函式
公眾號歷史文章列表向上滑動,載入更多文章後發現連結中變化的只有 offset 這個引數,我們建立一個初始化函式,加入代理 IP,請求頭和資訊,請求頭包含了 User-Agent、Cookie、Referer。
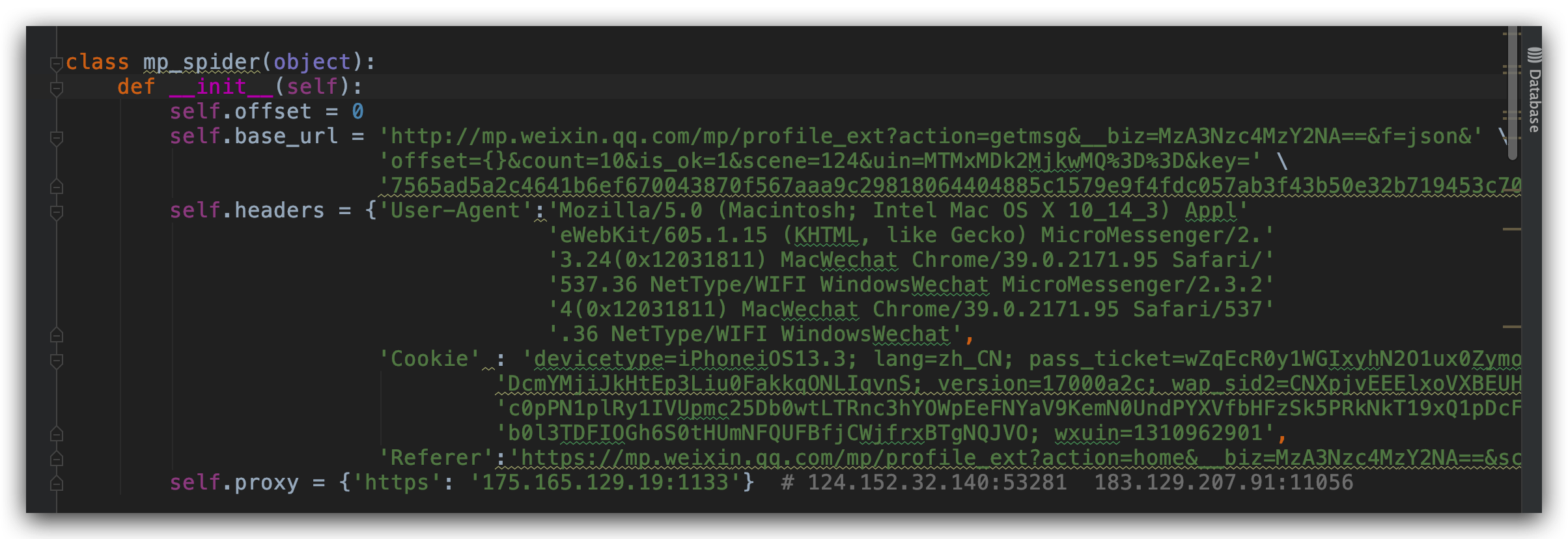
這些資訊都在抓包工具可以看到。
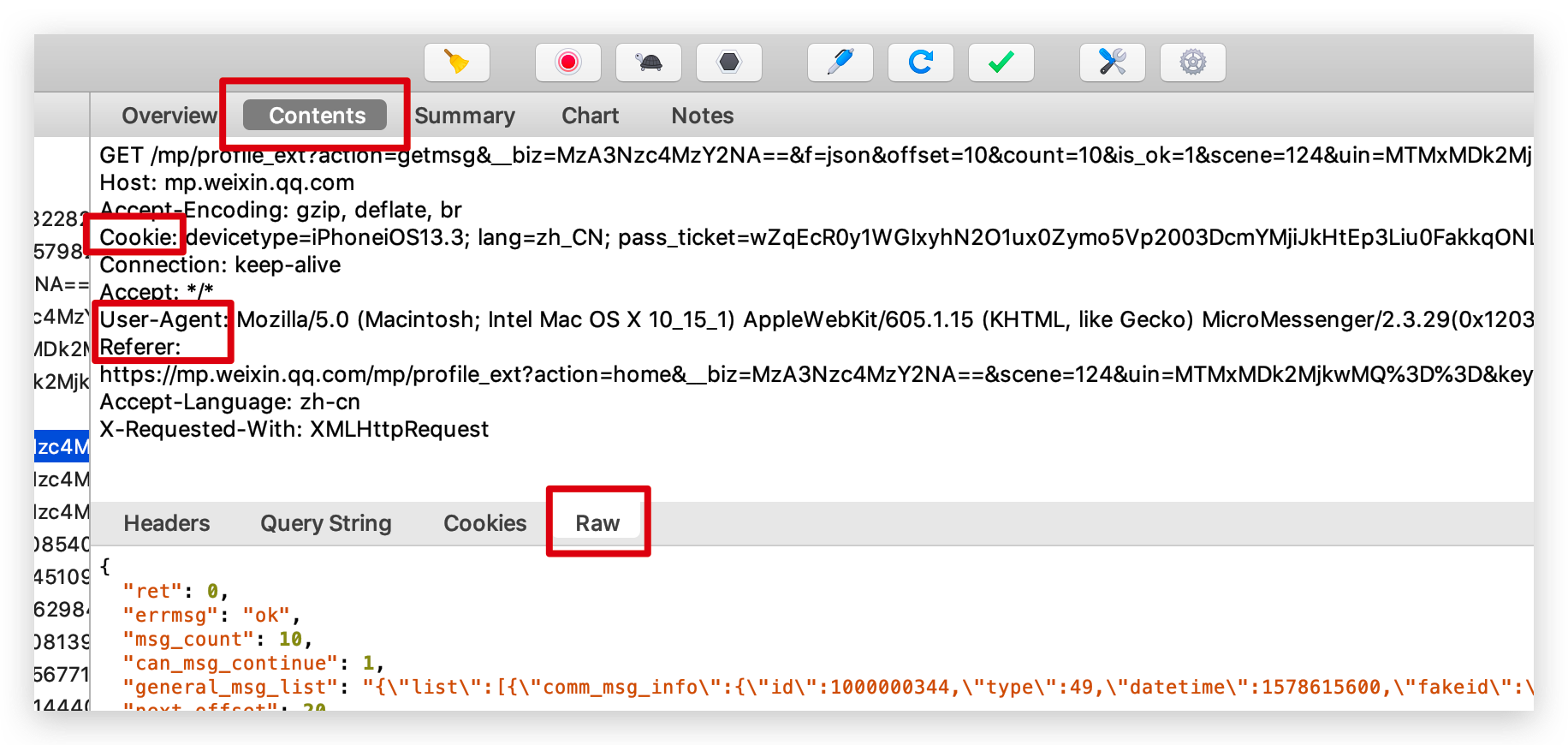
請求資料
通過抓包分析出來了請求連結,我們就可以用 requests 庫來請求了,用返回碼是否為 200 做一個判斷,200 的話說明返回資訊正常,我們再構建一個函式 parse_data() 來解析提取我們需要的返回資訊。
def request_data(self): try: response = requests.get(self.base_url.format(self.offset), headers=self.headers, proxies=self.proxy) print(self.base_url.format(self.offset)) if 200 == response.status_code: self.parse_data(response.text) except Exception as e: print(e) time.sleep(2) pass
提取資料
通過分析返回的 Json 資料,我們可以看到,我們需要的資料都在 app_msg_ext_info 下面。
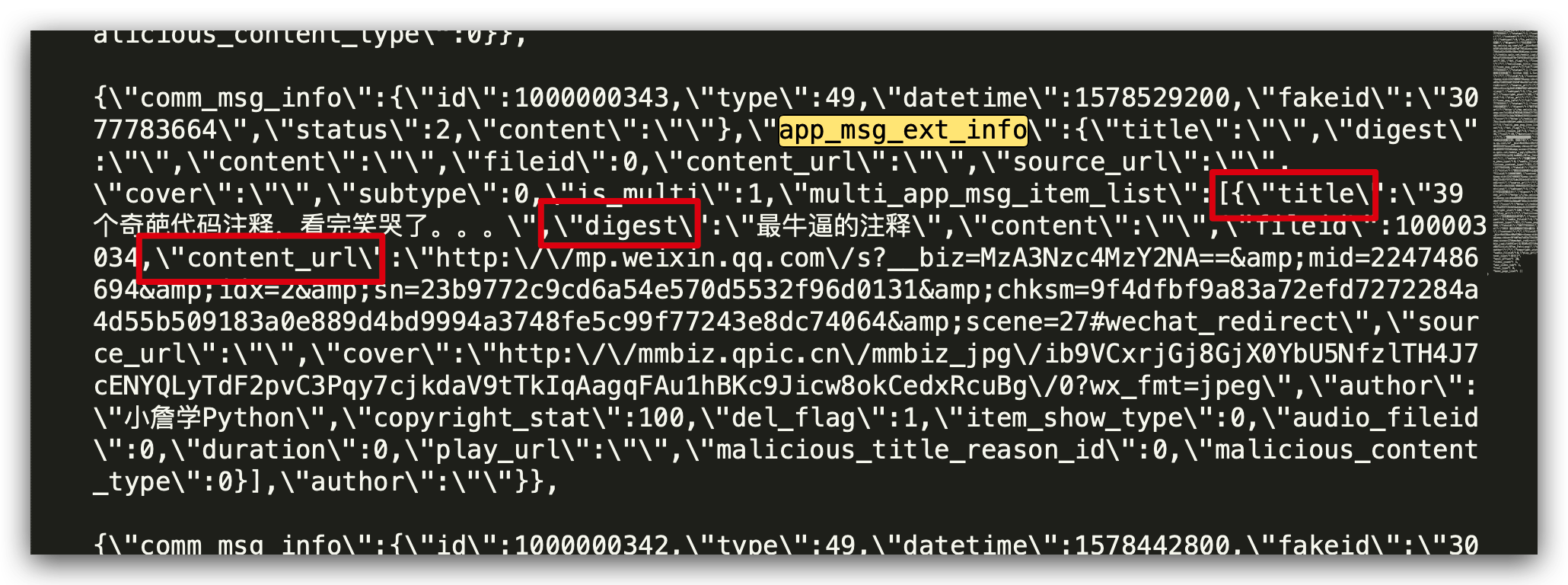
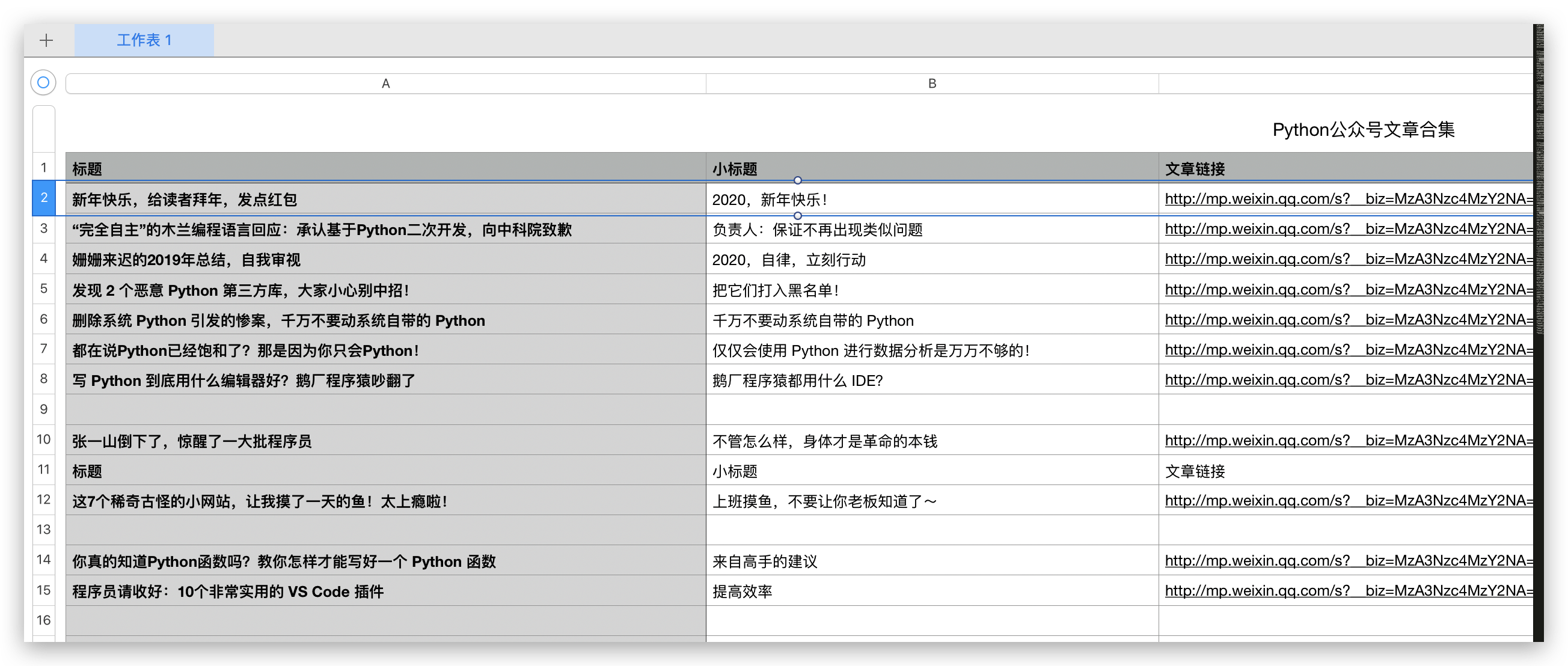
我們用 json.loads 解析返回的 Json 資訊,把我們需要的列儲存在 csv 檔案中,有標題、摘要、文章連結三列資訊,其他資訊也可以自己加。
def parse_data(self, responseData):
all_datas = json.loads(responseData)
if 0 == all_datas['ret'] and all_datas['msg_count']>0:
summy_datas = all_datas['general_msg_list']
datas = json.loads(summy_datas)['list']
a = []
for data in datas:
try:
title = data['app_msg_ext_info']['title']
title_child = data['app_msg_ext_info']['digest']
article_url = data['app_msg_ext_info']['content_url']
info = {}
info['標題'] = title
info['小標題'] = title_child
info['文章連結'] = article_url
a.append(info)
except Exception as e:
print(e)
continue
print('正在寫入檔案')
with open('Python公眾號文章合集1.csv', 'a', newline='', encoding='utf-8') as f:
fieldnames = ['標題', '小標題', '文章連結'] # 控制列的順序
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(a)
print("寫入成功")
print('----------------------------------------')
time.sleep(int(format(random.randint(2, 5))))
self.offset = self.offset+10
self.request_data()
else:
print('抓取資料完畢!')這樣,爬取的結果就會以 csv 格式儲存起來。
執行程式碼時,可能會遇到 SSLError 的報錯,最快的解決辦法就是 base_url 前面的 https 去掉 s 再執行。
儲存markdown格式的連結
經常寫文章的人應該都知道,一般寫文字都會用 Markdown 的格式來寫文章,這樣的話,不管放在哪個平臺,文章的格式都不會變化。
在 Markdown 格式裡,用 [文章標題](文章url連結) 表示,所以我們儲存資訊時再加一列資訊就行,標題和文章連結都獲取了,Markdown 格式的 url 也就簡單了。
md_url = '[{}]'.format(title) + '({})'.format(article_url)爬取完成後,效果如下。
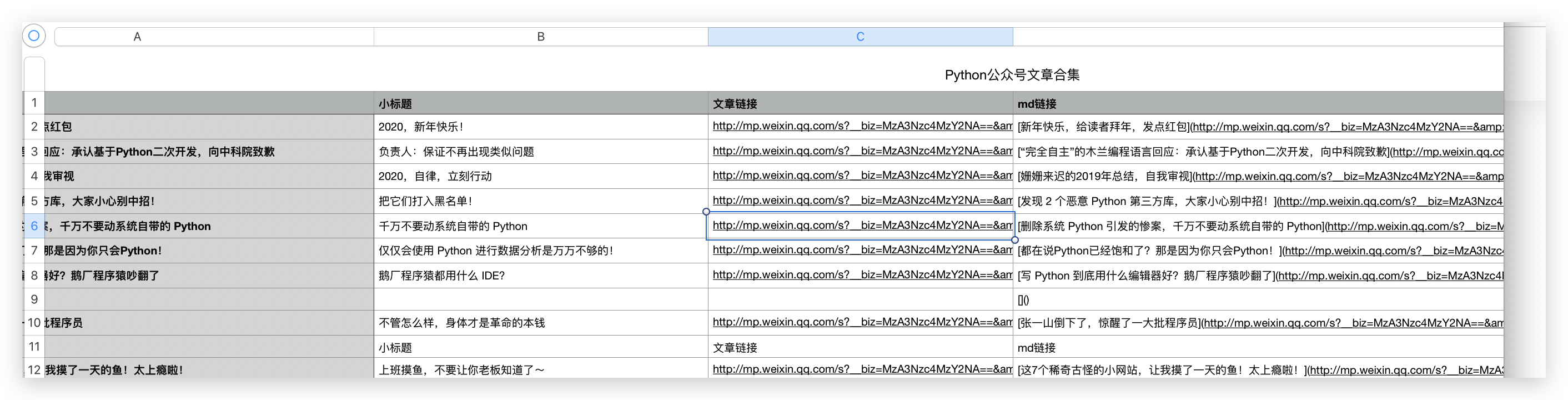
我們把 md連結這一列全部貼上到 Markdown 格式的筆記裡就行了,大部分的筆記軟體都知道新建 Markdown 格式的檔案的。
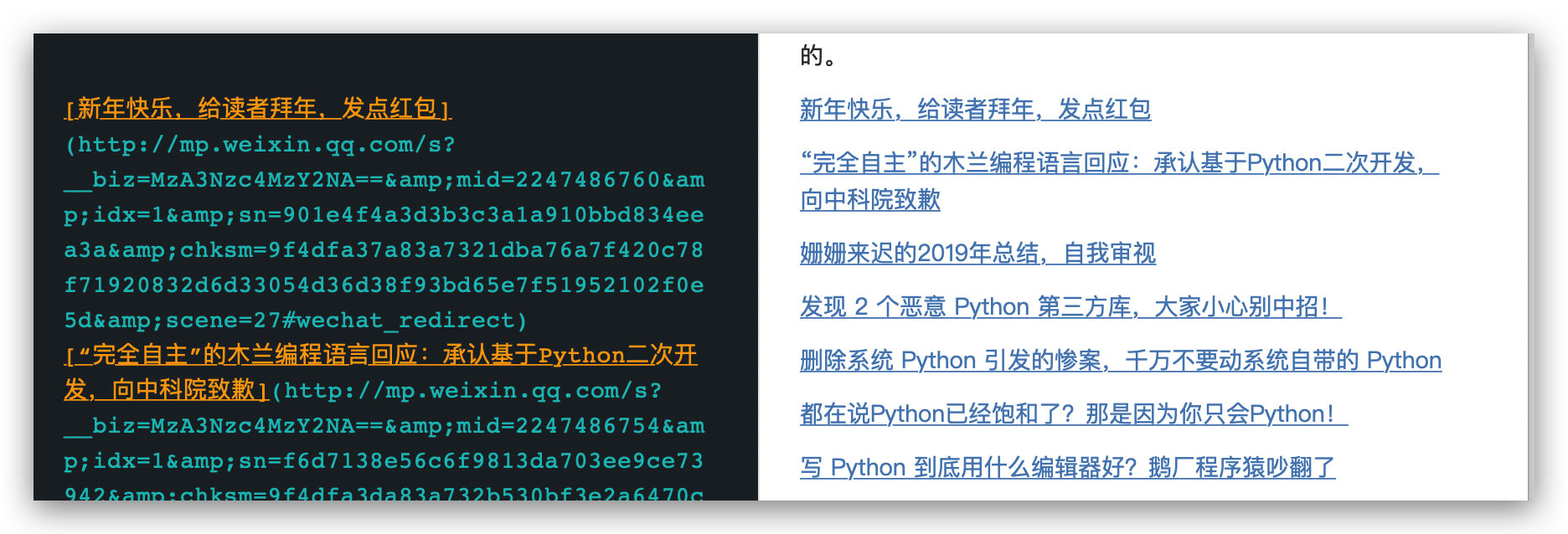
這樣,這些導航文章連結整理起來就是分類的事情了。
你用 Python 解決過生活中的小問題嗎?歡迎留言討論