
2000_narrowband to wideband conversion of speech using GMM based transformation
論文地址:基於GMM的語音窄帶到寬頻轉換
部落格作者:凌逆戰
部落格地址:https://www.cnblogs.com/LXP-Never/p/12151027.html
摘要
在不改變現有通訊網路的情況下,利用窄帶語音重建寬頻語音是一個很有吸引力的問題。本文提出了一種從窄帶語音中恢復寬頻語音的新方法。該方法基於高斯混合模型(GMM)將輸入語音的窄帶頻譜包絡變換為寬頻頻譜包絡,並採用聯合密度估計技術對其引數進行計算。然後利用重構後的譜包絡,利用LPC合成器對低頻和高頻語音訊號進行重構。本文還提出了一種基於碼字的功率估計方法。客觀和主觀測試結果均表明,該演算法優於傳統的碼本對映方法。
1 引言
在模擬電話網路和移動通訊系統中,語音頻寬限制在300Hz - 3.4 kHz範圍內。結果,窄帶語音的音質不如寬頻語音,特別是子音的可懂度降低。由於人類對寬頻語音的偏好,將窄帶語音改造成寬頻語音顯得很有吸引力。
窄帶到寬頻(NB到WB)語音轉換的目的是從窄帶語音中重建附加的低頻(20hz-300hz)和高頻(3.4khz-8khz)訊號。重建基於兩個假設[1]。一是窄帶語音與高、低頻段訊號密切相關。二是即使重構的低頻段和高頻段訊號不完全準確,也能顯著提高感知語音質量。NB到WB語音轉換的最大優點是,它在不需要任何額外傳輸資訊的情況下生成增強的寬頻語音(盲源頻帶擴充套件),從而為現有網路提供向後相容性。
本文對NB到WB語音轉換問題進行了一些嘗試,包括基於codebook mapping (碼本對映)[1]的方法和統計方法[2]。其主要問題是寬頻頻譜包絡的重構。在碼本對映方法中,聲學空間由一組離散的模板codevector(碼矢)表示。利用窄帶碼本和寬頻碼本之間的對映關係重構寬頻頻譜包絡。該方法的侷限性在於向量量化(VQ)過程中對輸入窄帶譜向量的硬分類,雖然模糊VQ在一定程度上緩解了這一問題[1]。統計方法引入了統計恢復函式(SRF),它只預測基於窄帶語音的高頻段頻譜。雖然統計方法獲得了良好的效能,但它需要大量的計算。
眾所周知,高斯混合模型(GMM)[3]能有力的表示語音的聲學空間,並被成功地用作頻譜變換的方法,特別是在說話人轉換系統[4][5]中。由於聲學空間的連續逼近,GMM提供了平滑的分類索引,避免了不自然的不連續性,從而優於VQ模型。因此,該演算法將GMM作為寬頻頻譜包絡重建的工具。
本文組織如下。第二部分介紹了基於GMM的NB到WB語音轉換演算法。第三部分給出了實驗結果,最後得出結論。
2 基於GMM的NB到WB語音轉換
本文提出了一種基於GMM的窄帶語音重建方法。第一種是基於聯合密度估計的GMM的頻譜包絡重構。將窄帶譜向量轉換為寬頻譜向量的對映函式是最小二乘迴歸估計。最小二乘迴歸估計,簡稱迴歸,是由一對訓練語音(窄帶和寬頻)得到的。第二步是生成低頻帶和高頻帶訊號。 在本文中,與碼本對映方法一樣,使用LPC合成器生成低頻帶和高頻帶語音訊號[1]。
2.1 高斯混合模型(GMM)
設$x\in R^n$為具有任意分佈的隨機向量。將$x$的分佈密度建模為由Q個分量密度混合而成的高斯混合密度,表示為:
$$公式1:
p(x | \lambda)=\sum_{i=1}^{Q} \alpha_{i} b_{i}(x), \sum_{i=1}^{Q} \alpha_{i}=1, \alpha_{i} \geq 0
$$
其中$b_i(x),i=1,...,Q$為分量密度,$\alpha_i,i=1,...,Q$為分量權重。每個分量密度都是一個包含n個變數的高斯函式的形式
$$公式2:
b_{i}(x)=\frac{1}{(2 \pi)^{n / 2}\left|C_{i}\right|^{1 / 2}} \exp \left[-\frac{1}{2}\left(x-\mu_{i}\right)^{T} C_{i}^{-1}\left(x-\mu_{i}\right)\right]
$$
$\mu_i$為n*1個均值向量,變數$C_i$為n*n各協方差向量。
完整的高斯混合密度由各分量密度的均值向量、協方差矩陣和混合權重 引數化,這些引數用符號表示
$$公式3:
\lambda=\left\{\alpha_{i}, \mu_{i}, C_{i}\right\} \quad, i=1, \cdots, Q
$$
使用GMM來表示聲學空間的兩個主要的動機:
- 第一個是經驗觀察,一個高斯base函式的線性組合能夠代表一大類樣本分佈。
- 第二種是直觀的概念,即單個成分密度被解釋為代表一些廣泛的聲學類別。
為了對聲學空間分佈進行建模,必須利用訓練語音資料估計GMM的引數。有幾種估計GMM引數的技術。最常用的方法是極大似然(ML)估計。ML引數估計可以使用眾所周知的期望最大化(EM)演算法[3]迭代獲得。
2.2 頻譜包絡重構
2.2.1 聯合密度估計的GMM
設$x\in R^n$為窄帶語音的譜向量,$y\in R^n$為原寬頻語音的譜向量。然後將向量$z=(x,y)$的聯合密度建模為Q 2n變數高斯函式的混合。
$$公式4:\begin{array}{l}p(z|\lambda ) = \sum\limits_{i = 1}^Q {\frac{{{\alpha _i}}}{{{{(2\pi )}^n}|{C_i}{|^{1/2}}}}} \exp [ - \frac{1}{2}{(z - {\mu _i})^T}C_i^{ - 1}(z - {\mu _i})]\\\quad \quad \quad \quad \sum\limits_{i = 1}^Q {{\alpha _i}} = 1,{\alpha _i} \ge 0\end{array}$$
其中$\alpha_i$、$\mu_i$和$c_i$表示第$i$類的先驗概率、平均向量和協方差矩陣。我們的目標是找到一個使均方誤差最小化的對映函式F。
$$公式5:{\varepsilon _{mse}} = E[||y - F(x)|{|^2}]$$
其中$E[·]$表示期望,F(x)為待估計的重構寬頻譜向量。
迴歸函式可以使重構的寬頻頻譜向量和原始寬頻頻譜向量之間的均方誤差最小。
$$公式6:F(x)=E[y|x]=\sum_{i=1}^Qh_i(x)[\mu_i^y+C_i^{yx}C_i^{xx-1}(x-\mu_i^x)]$$
其中
$$公式7:{h_i}(x) = \frac{{\frac{{{\alpha _i}}}{{{{(2\pi )}^{n/2}}{{\left| {C_i^{xx}} \right|}^{1/2}}}}\exp \left[ { - \frac{1}{2}{{\left( {x - \mu _i^x} \right)}^T}C_i^{xx - 1}\left( {x - \mu _i^x} \right)} \right]}}{{\sum\limits_{j = 1}^Q {\frac{{{\alpha _j}}}{{{{(2\pi )}^{n/2}}{{\left| {C_j^{xx}} \right|}^{1/2}}}}} \exp \left[ { - \frac{1}{2}{{\left( {x - \mu _j^x} \right)}^T}C_j^{x{\rm{x}} - 1}\left( {x - \mu _j^x} \right)} \right]}}$$
其中$C _ { i } = \left[ \begin{array} { l l } { C _ { i } ^ { \infty } } & { C _ { i } ^ { \mathrm { xy } } } \\ { C _ { i } ^ { y x } } & { C _ { i } ^ { y y } } \end{array} \right]$和$\mu_i=\begin{bmatrix}\mu_i^x\\ \mu_i^y\end{bmatrix}$
加權函式$h_i(x)$表示第$i$個高斯分量生成向量x的後驗概率。
2.2.2 訓練和引數提取
利用以上討論的迴歸方法進行頻譜包絡重建。為得到最優迴歸,通過使寬頻語音通過帶通濾波器來生成窄帶語音,並提取頻譜向量序列,如圖1所示。令$x=[x_1,x_2,...x_N]$為窄帶語音訊譜向量序列,$y=[y_1,y_2,...,y_n]$為寬頻語音的頻譜向量序列。通過訓練向量序列,使用EM演算法估計式(4)中模型$(\alpha,\mu,C)$的引數。

圖1 GMM聯合密度引數估計過程框圖
2.2.3 碼字相關功率估計
在NB到WB的轉換中,只需利用窄帶語音資訊就可以估計出重構後的低頻和高頻語音的功率。先前的方法使用恆定的功率比來產生低頻和高頻語音[1],但很明顯,功率比取決於聲音identity(特性)。受此啟發,本文還提出了一種與碼字相關的功率估計方法。該方法使用一對碼本。其中一個碼本包含有代表性的窄帶譜模板,另一個碼本包含低/高頻帶語音與其窄帶版本之間的功率比。這兩個碼本也是使用一對訓練語音、窄帶和寬頻語音生成的。具體步驟如下:首先,生成窄帶頻譜向量的碼本。然後利用窄帶譜碼本對窄帶語音訓練後的每一幀語音進行向量量化,並將低頻寬和窄帶語音的功率比進行聚類。最後,平均每個功率比群集中的功率比,並將其儲存為功率比碼本的碼字。
2.3 從窄帶語音生成寬頻語音
圖2顯示了寬頻語音生成過程的框圖。其基本思想與[1]相似,具體步驟如下
(1)對輸入窄帶語音進行LPC分析,逐幀提取基音、功率和譜向量。
(2)利用GMM引數,通過式(6)和式(7)得到重構的寬頻譜向量。
(3)利用分析過的基音、功率和重建的譜向量,由LPC合成器合成寬頻語音。
(4)通過帶阻濾波器提取低頻段和高頻段訊號。
(5)通過分析窄帶譜向量,解碼功率比,將(4)的輸出乘以功率比。
(6)將功率補償的低頻段和高頻段語音加入到輸入窄帶語音中,得到重構的寬頻輸出語音。
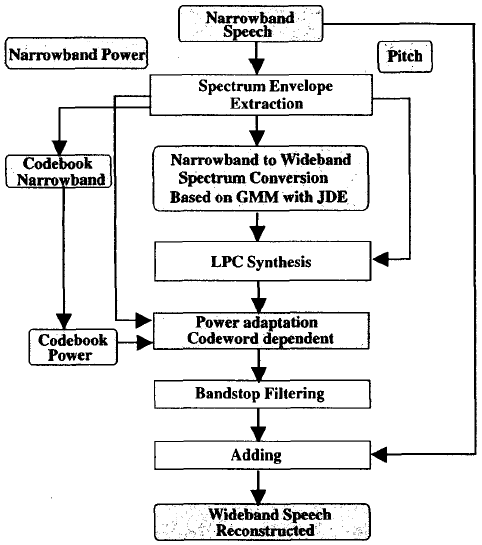
圖2 基於GMM聯合密度估計的寬頻語音生成過程框圖
3 實驗結果
為了評估所提演算法的效能,我們對所提演算法和傳統的忙了對映演算法進行了客觀語音質量測量和主觀聽力測試。實驗條件如表1所示。
作為使用傳統碼本對映方法的初步實驗,我們研究了哪種訓練資料適合語音平衡的單詞和句子資料庫之間的NB到WB語音轉換問題。結果表明,儘管詞型別資料的資料庫大小是句式資料的5倍,但是句式訓練資料的效能要好於詞型別資料。因此,我們選擇了韓語語音平衡句子資料庫進行訓練。
我們還通過使用常規碼本對映方法的另一個初步實驗,評估了所提出的碼字相關功率估計方法的效能。結果表明,使用所提出方法重建的寬頻語音與使用原始語音的寬頻語音之間沒有明顯的聽覺差異。因此,為了將碼本對映方法與基於GMM的方法進行比較,我們將所提出的功率估計方法應用於兩種演算法。除LPC順序外,其他實驗條件與[1]相同。在原始的碼本對映方法中,LPC的階數為14,但是我們將LPC的階數增加到18,以覆蓋寬頻語音中的高頻共振峰。因為在[13]中的最佳碼本大小為128,所以我們選擇GMM中相同數量的混合數128。
表一:實驗條件
訓練話術的數量:10句/每個說話人
分析window:Hamming
window長度:21ms
幀移長度:3ms
LPC階數:18
VQ碼本尺寸:128
GMM的混合數目:128
距離度量:LPC倒譜的歐氏距離
作為一種客觀的質量度量,我們使用平均對數譜距離度量,它被近似為截斷倒譜距離度量。表2顯示了客觀質量測量的結果,其中“spk-dep”和“spk-ind”分別表示說話人依賴的方式和說話人獨立的方式。從表中可以看出,無論在說話人依賴還是說話人獨立的情況下,提出的基於GMM的方法都優於傳統的VQ碼本對映方法。
表2:客觀質量測量結果
| 語音型別 | 方法 | 方式 | 倒譜距離 |
| NB語音 | - | - | 11.82dB |
| 重建的寬頻語音 | VQ | spk-dep | 3.27dB |
| GMM | spk-dep | 2.85dB | |
| VQ | spk-ind | 3.96dB | |
| GMM | spk-ind | 3.40dB |
我們通過主觀偏好測試對演算法的效能進行了評價。首先,我們比較了重建的寬頻語音和窄帶語音。在測試之前,給聽眾們展示了窄帶和寬頻語音的例子。為了驗證實驗的有效性,重構的寬頻語音和窄帶語音被隨機地呈現在每個聽眾面前。在測試中,聽眾被要求判斷兩個測試話語中哪個更清晰。當聽眾不能確定哪一個更清晰時,他們可以選擇“無差別”。我們還使用與上述相同的步驟,將所提出的演算法所重建的寬頻語音與傳統的碼本對映演算法所重建的寬頻語音進行了比較。
實驗結果如表3所示。可以看出,該演算法重構的寬頻語音優於窄帶語音,並且在說話人依賴和說話人獨立兩方面都優於傳統的碼本對映演算法。
主觀偏好測驗結果
(a)、窄帶語音與基於gmm的重組語音的比較
| NB 語音 | 無區別 | GMM | |
| spk-dep | 10.0% | 2.5% | 87.5% |
| spk-ind | 35.0% | 0.0% | 65.0% |
(b)、VQ碼本對映法重構語音與基於gmm的方法重構語音
| VQ | 無區別 | GMM | |
| spk-dep | 2.5% | 32.5% | 65.0% |
| spk-ind | 7.5% | 27.5% | 65.0% |
4 總結
提出了一種基於聯合密度估計的高斯混合模型,通過頻譜變換從窄帶語音中恢復寬頻語音的新方法。我們還提出了一種基於碼字的功率估計方法來獲得重構的低頻段和高頻段語音訊號的適當增益項。客觀和主觀測試結果均表明,該演算法優於傳統的碼本對映方法。雖然所提演算法的結果是很有希望的,但重建後的語音仍有一定的噪聲。正在進行的研究正在處理這個問題。
參考文獻
[1]Y. Yoshida and M. Abe, "An algorithm to reconstruct wideband speech from narrowband speech based on codebook mapping," Proc. of ICSLP 94, pp. 1591 -1 594, 1994.
[2]Y. M. Cheng, D. OShaughnessy, and P. Mermelstein,"Statistical recovery of wideband speech from narrowband speech," IEEE Trans. Speech and Audio Processing, Vo1.2,no.4, pp. 544-548, Oct. 1994.
[3]D. A. Reynolds and R. C. Rose, "Robust text-independent speaker identification using Gaussian mixture speaker models," IEEE Trans. Speech and Audio Processing, Vo1.3,no. 1, pp. 72-83, Jan. 1995.
[4]Y. Stylianou, Harmonic plus Noise Models for Speech,Combined with Statistical Methods, for Speech and Speaker Modification, Ph.D. thesis, Ecole Nationale Superieure des Telecommunication, Paris, France, pp. 115-144, Jan. 1996.
[5]A. Kain and M. W. Macon, "Spectral voice conversion for text-to-speech synthesis," Proc. of IEEE ICASSP 98, pp. 285-288,1