
【docker Elasticsearch】Rest風格的分散式開源搜尋和分析引擎Elasticsearch初體驗
目錄
- 概述:
- 2、問題
- 二:安裝kibana
- 1、安裝
- 2、問題
- 貳:Elastic search初體驗
- 一:新增資料
- 1、查詢單個數據
- 2、查詢所有的資料
- 3、按條件查詢
- 4、檢視資料是否存在
- 三、修改資料
- 四:刪除資料
- 一:新增資料
- 作者有話
概述:
Elasticsearch 是一個分散式、可擴充套件、實時的搜尋與資料分析引擎。 它能從專案一開始就賦予你的資料以搜尋、分析和探索的能力,這是通常沒有預料到的。 它存在還因為原始資料如果只是躺在磁盤裡面根本就毫無用處。
Elasticsearch 不僅僅只是全文搜尋,我們還將介紹結構化搜尋、資料分析、複雜的人類語言處理、地理位置和物件間關聯關係等。 我們還將探討為了充分利用 Elasticsearch 的水平伸縮性,應當如何建立資料模型,以及在生產環境中如何配置和監控你的叢集。
Elasticsearch也使用Java開發並使用 Lucene 作為其核心來實現所有索引和搜尋的功能,但是它的目的是通過簡單的 RESTful API 來隱藏 Lucene 的複雜性,從而讓全文搜尋變得簡單。
不過,Elasticsearch 不僅僅是 Lucene 和全文搜尋,我們還能這樣去描述它:
- 分散式的實時檔案儲存,每個欄位都被索引並可被搜尋
- 分散式的實時分析搜尋引擎
可以擴充套件到上百臺伺服器,處理PB級結構化或非結構化資料
@壹:安裝軟體
一:安裝elasticsearch
1、安裝
1、搜尋映象 docker search Elasticsearch 2、拉取映象 docker pull elasticsearch:7.5.2 3、檢視映象 docker images 4、啟動容器 docker run -d --name elaseticsearch -p 9200:9200 -p 9300:9300 -e ES_JAVA_POTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" [映象id] 5、訪問 http://localhost:9200 { "name": "ea92e317dcb0", "cluster_name": "docker-cluster", "cluster_uuid": "nN5sGE2FQuidchtltDxAhQ", "version": { "number": "7.5.2", "build_flavor": "default", "build_type": "docker", "build_hash": "8bec50e1e0ad29dad5653712cf3bb580cd1afcdf", "build_date": "2020-01-15T12:11:52.313576Z", "build_snapshot": false, "lucene_version": "8.3.0", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" }
2、問題
1、啟動失敗,docker內容器無故停止
原因:elasticsearch初始佔用記憶體大,開始佔用兩G,而我給docker只分配了1G,所以造成記憶體不夠從而造成啟失敗,如果你電腦記憶體夠大,你可以給你的docker分配大一點的記憶體,記憶體不夠的同學,你可以在建立容器時加引數-e ES_JAVA_POTS="-Xms256m -Xmx256m"
二:安裝kibana
1、安裝
1、拉取映象
docker pull kibana:7.5.2
注:最好與你的elasticsearch版本一致,以免出現問題
2、建立容器
docker run -d --name kibana -p 5601:5601 [映象id]
3、訪問測試
訪問地址:http://locahost:5601在除錯很久之後,終於來到我渴望來到的介面。
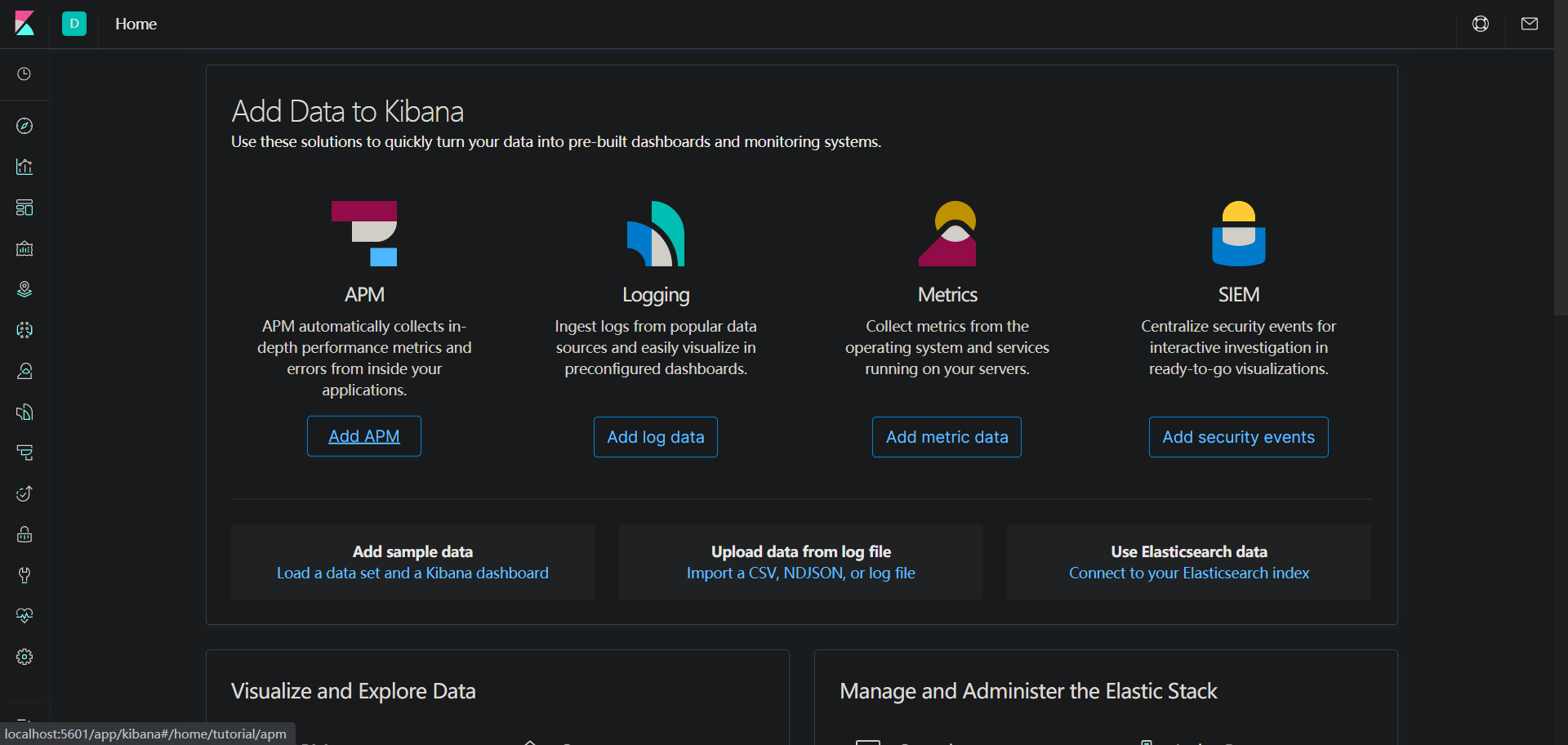
他裡面有一個測試:http://localhost:9200/_search
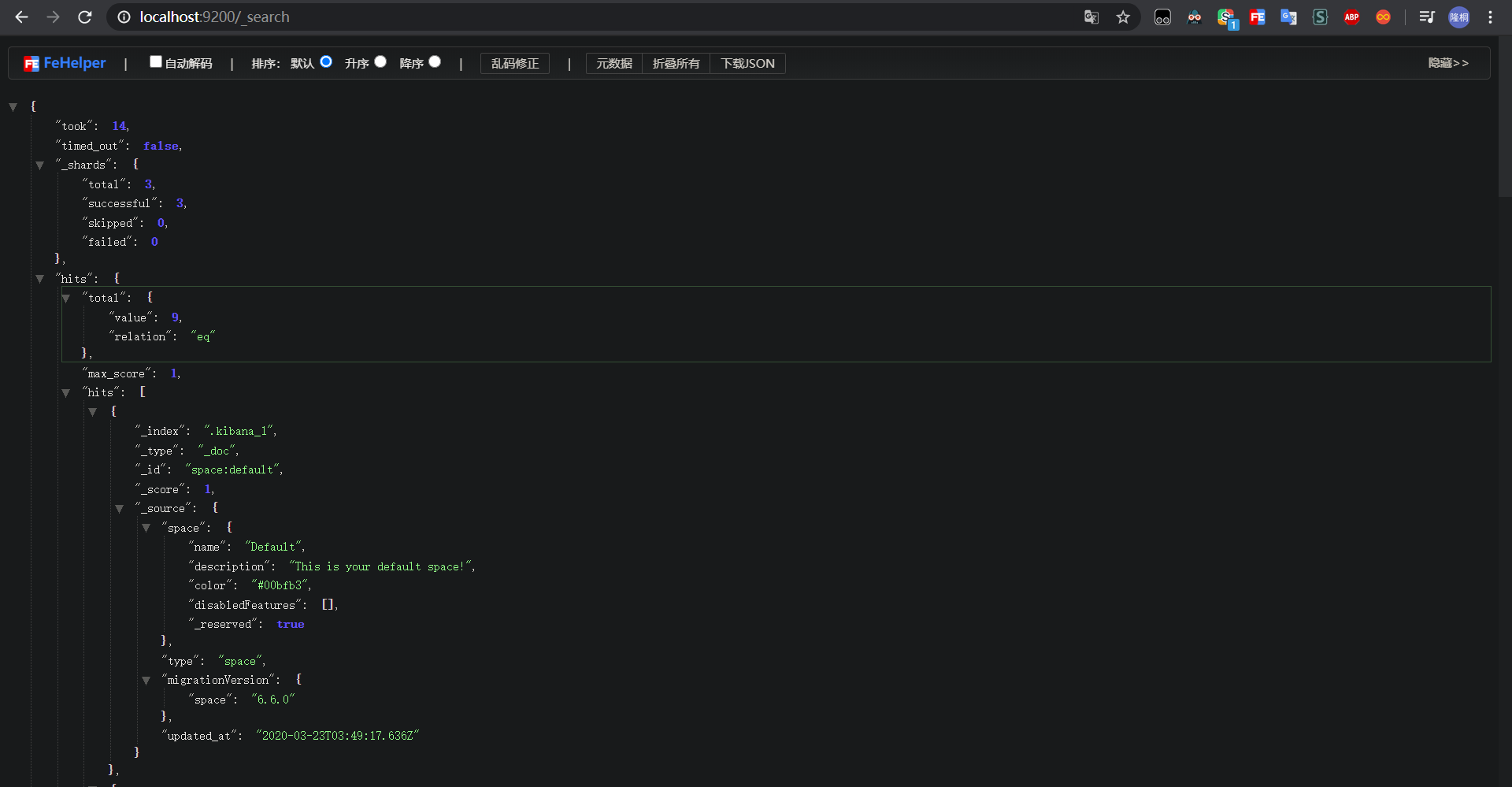
2、問題
1、訪問kibana出現問題:Kibana server is not ready yet,具體問題你需要看他的日誌,使用kitematic可以檢視容器的日誌。
出現這個問題的可能性有很多,需要注意的是:
- 1、確認你的elasticsearch是否啟動,這沒什麼好說的
- 2、確認你的elasticsearch版本是否與你的kibana版本是否一致,雖然我也沒有測試,版本一致總歸沒有什麼壞處。

- 3、你最好把kibana與elasticsearch兩個容器之間連線起來

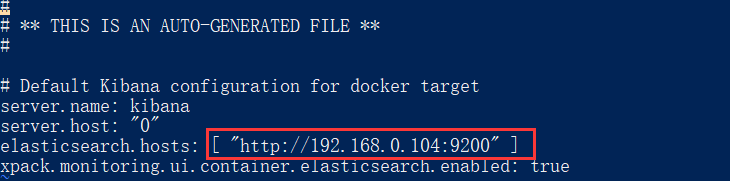
- 4、在進入容器後,你必須修改
elasticsearch.hosts引數,它裡面會有預設值為http://elaseicsearch:9200,注意這裡不能改為http://localhost:9200,因為這樣他會對映到你的容器內部。
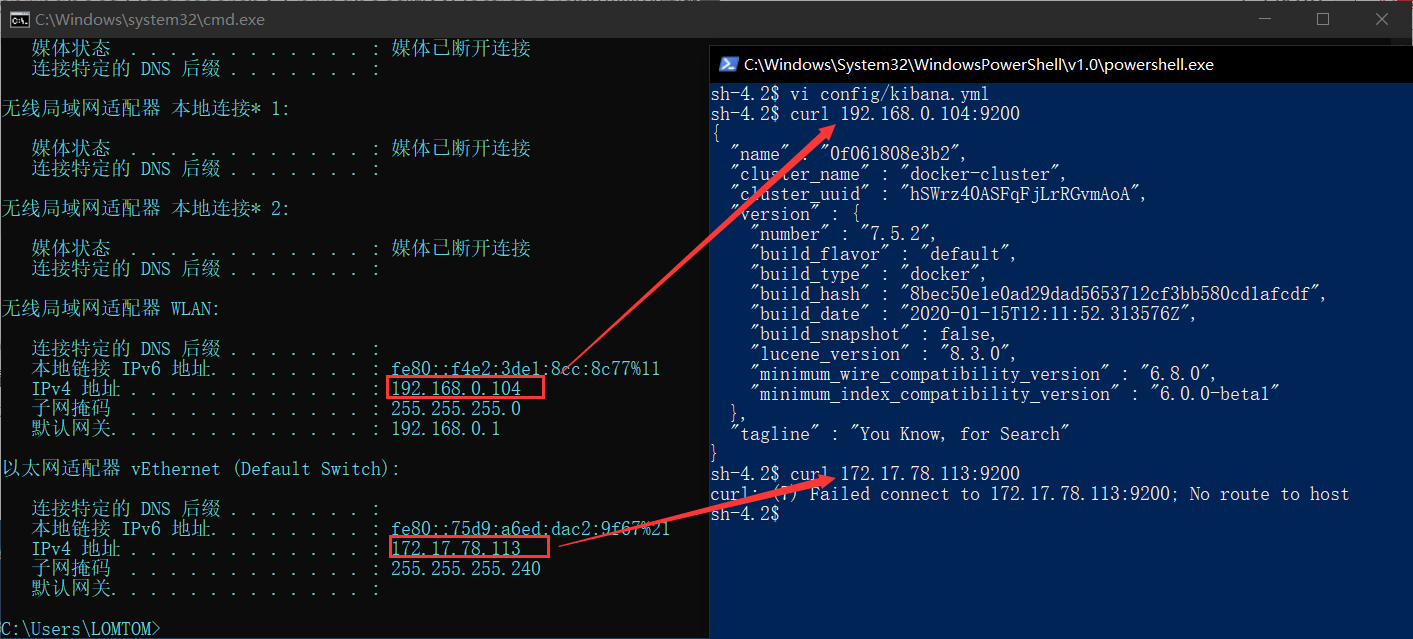
你需要在你的主機檢視ip,輸入ipconfig,這裡會有很多ip,請注意,這裡只有一個才能連線,如果你不能確認是哪一個,請在你的kibana容器內部curl一下http://ip:9200,出現elasticsearch資訊的才是正確的。
貳:Elastic search初體驗
資料的操作無非就是增刪改查四種對吧,接下來演示怎麼實現這四種方法:
一:新增資料
這時elasticsearch開發文件裡的例子。
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
PUT /megacorp/employee/2
{
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests": [ "music" ]
}
PUT /megacorp/employee/3
{
"first_name" : "Douglas",
"last_name" : "Fir",
"age" : 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}以1號員工為例:這裡使用Postman工具:
我們將請求切換為PUT請求,輸入Url,在請求裡面加上資料,點擊發送,就會看到響應,
注意,路徑 /megacorp/employee/1 包含了三部分的資訊:
- megacorp(索引名稱)
- employee(型別名稱)
1(特定僱員的ID)
請求體 —— JSON 文件 —— 包含了這位員工的所有詳細資訊,他的名字叫 John Smith ,今年 25 歲,喜歡攀巖。

二:檢視資料
目前我們已經在 Elasticsearch 中儲存了一些資料, 接下來就能專注於實現應用的業務需求了。第一個需求是可以檢索到單個僱員的資料。
這在 Elasticsearch 中很簡單。簡單地執行 一個 HTTP GET 請求並指定文件的地址——索引庫、型別和ID。 使用這三個資訊可以返回原始的 JSON 文件:
1、查詢單個數據
同樣的,我們只需要將索引名、類別名、id的形式以get的請求傳送,就可以實現單個數據的查詢。
GET /megacorp/employee/1返回結果包含了文件的一些元資料,以及 _source 屬性,內容是 John Smith 僱員的原始 JSON 文件
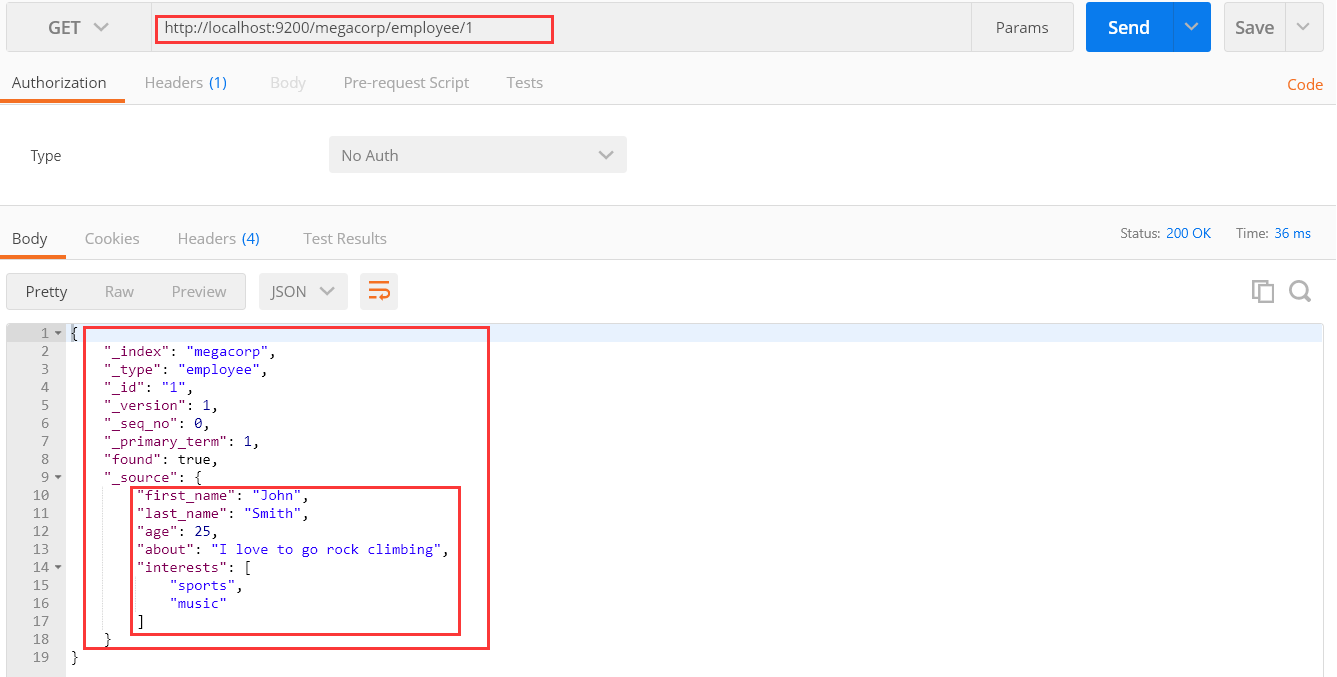
2、查詢所有的資料
一個 GET 是相當簡單的,可以直接得到指定的文件。 現在嘗試點兒稍微高階的功能,比如一個簡單的搜尋!
第一個嘗試的幾乎是最簡單的搜尋了。我們使用下列請求來搜尋所有僱員:
GET /megacorp/employee/_search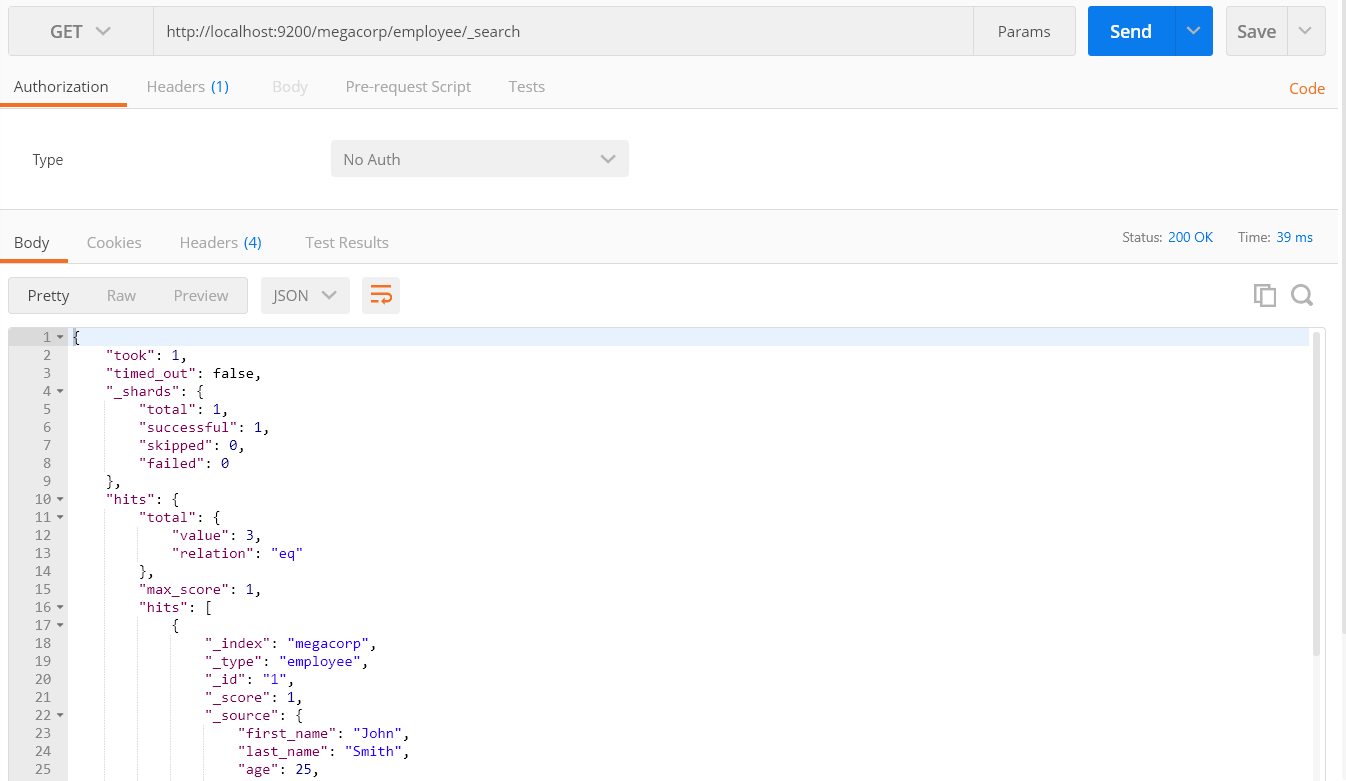
可以看到,我們仍然使用索引庫 megacorp 以及型別 employee,但與指定一個文件 ID 不同,這次使用 _search 。返回結果包括了所有三個文件,放在陣列 hits 中。一個搜尋預設返回十條結果。
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "Douglas",
"last_name": "Fir",
"age": 35,
"about": "I like to build cabinets",
"interests": [
"forestry"
]
}
}
]
}
}3、按條件查詢
①、get
嘗試下搜尋姓氏為 Smith 的僱員。、這個方法一般涉及到一個 查詢字串 (query-string) 搜尋,因為我們可以通過一個URL引數來傳遞查詢資訊給搜尋介面:
GET /megacorp/employee/_search?q=last_name:Smith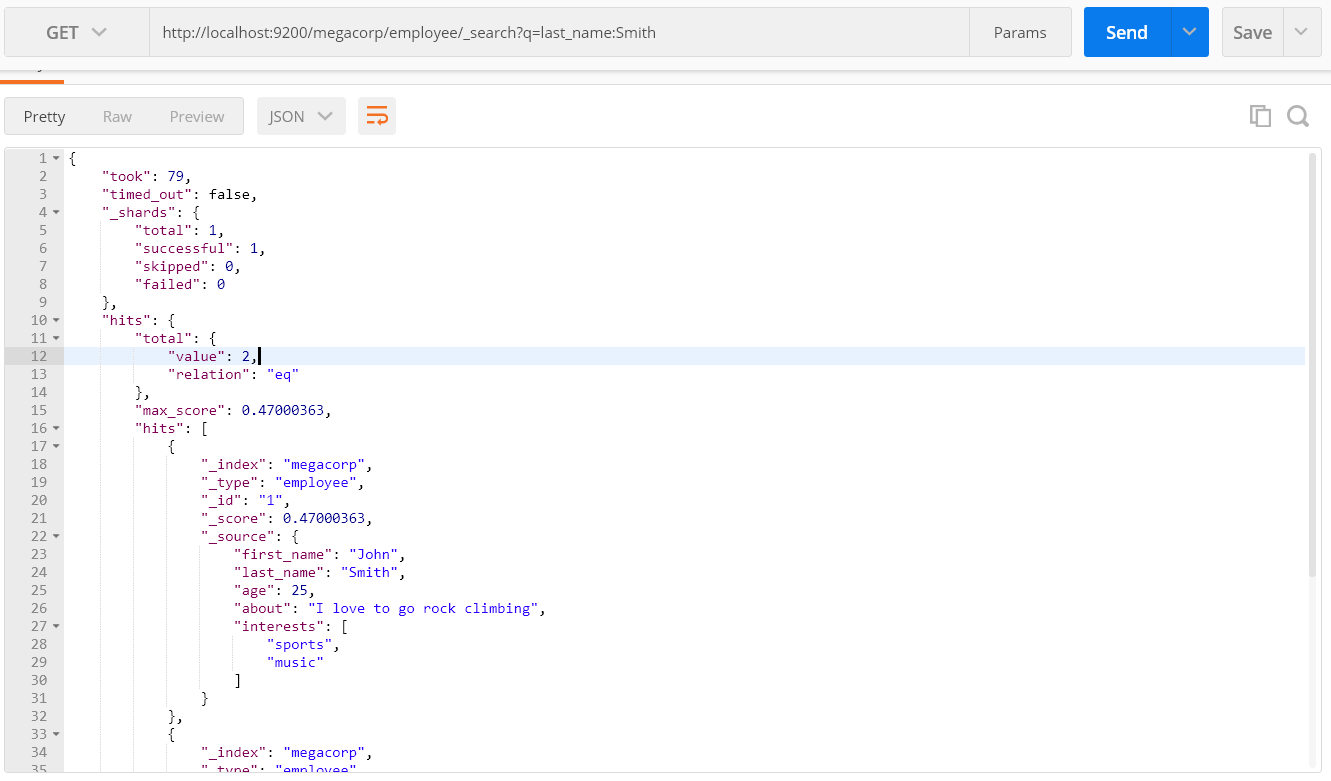
可以看到我們將查詢本身賦值給引數 q= 。返回結果給出了所有的 Smith,一共兩條。
{
"took": 79,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.47000363,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.47000363,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.47000363,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
}
]
}
}②:post請求
官方文件介紹這是使用查詢表示式搜尋。
Query-string 搜尋通過命令非常方便地進行臨時性的即席搜尋 ,但它有自身的侷限性(參見 輕量 搜尋 )。Elasticsearch 提供一個豐富靈活的查詢語言叫做 查詢表示式 , 它支援構建更加複雜和健壯的查詢。
領域特定語言 (DSL), 使用 JSON 構造了一個請求。我們可以像這樣重寫之前的查詢所有名為 Smith 的搜尋 :
POST /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}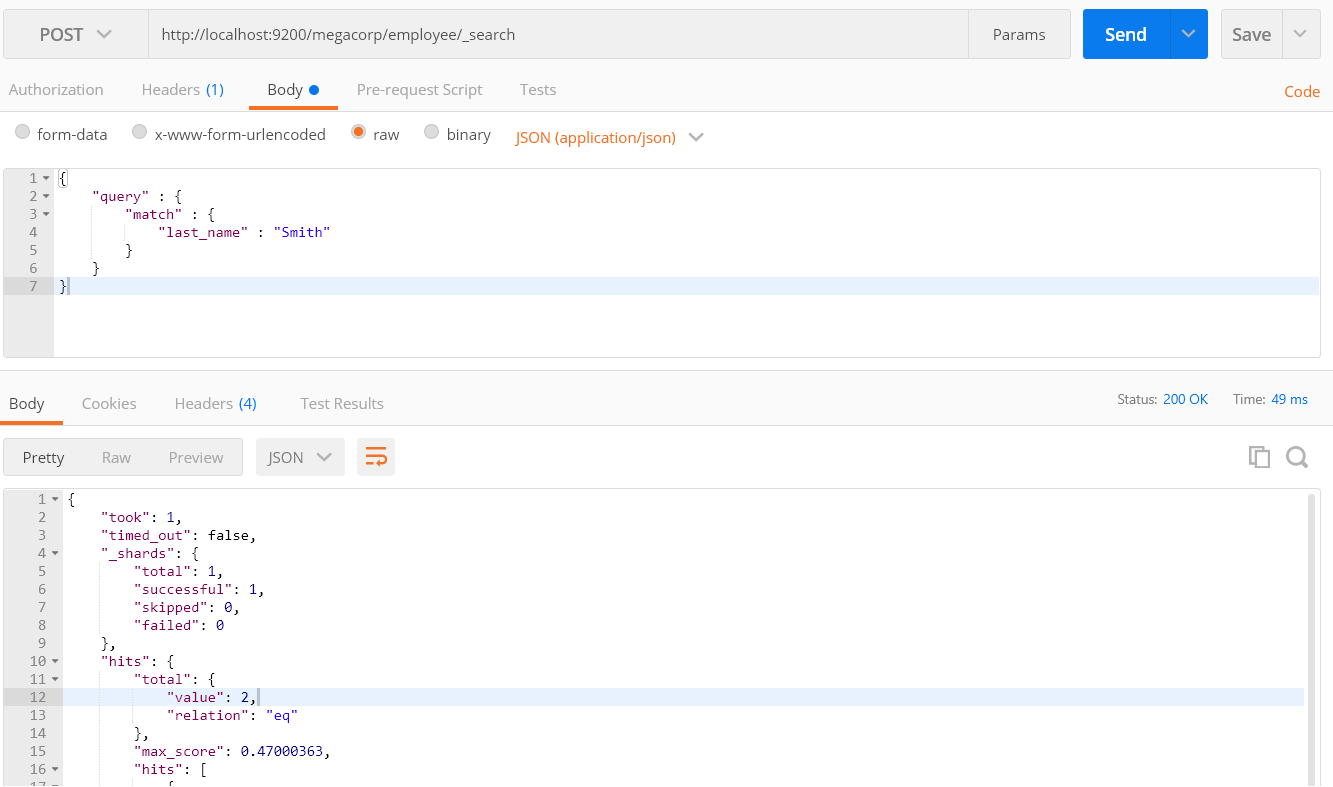
官方文件給出的是get請求,我實在是不知道引數加在哪裡,加在header裡,沒有任何效果,於是我改成了POST請求,請求成功,值得注意的是只有在有條件的時候才能查詢成功。
其中與get請求的不同是:不再使用 query-string 引數,而是一個請求體替代。這個請求使用 JSON 構造,並使用了一個 match 查詢(屬於查詢型別之一)
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.47000363,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 0.47000363,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 0.47000363,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [
"music"
]
}
}
]
}
}4、檢視資料是否存在
相對於其他集中請求,這時一種比較少見的請求方式,如果需要檢視資料是否存在,將請求方式改為head即可。
HEAD /megacorp/employee/1傳送請求後,你也許會疑問,咦,他也沒有返回資訊啊,那我怎麼知道結果呢。別急,聽我慢慢道來。
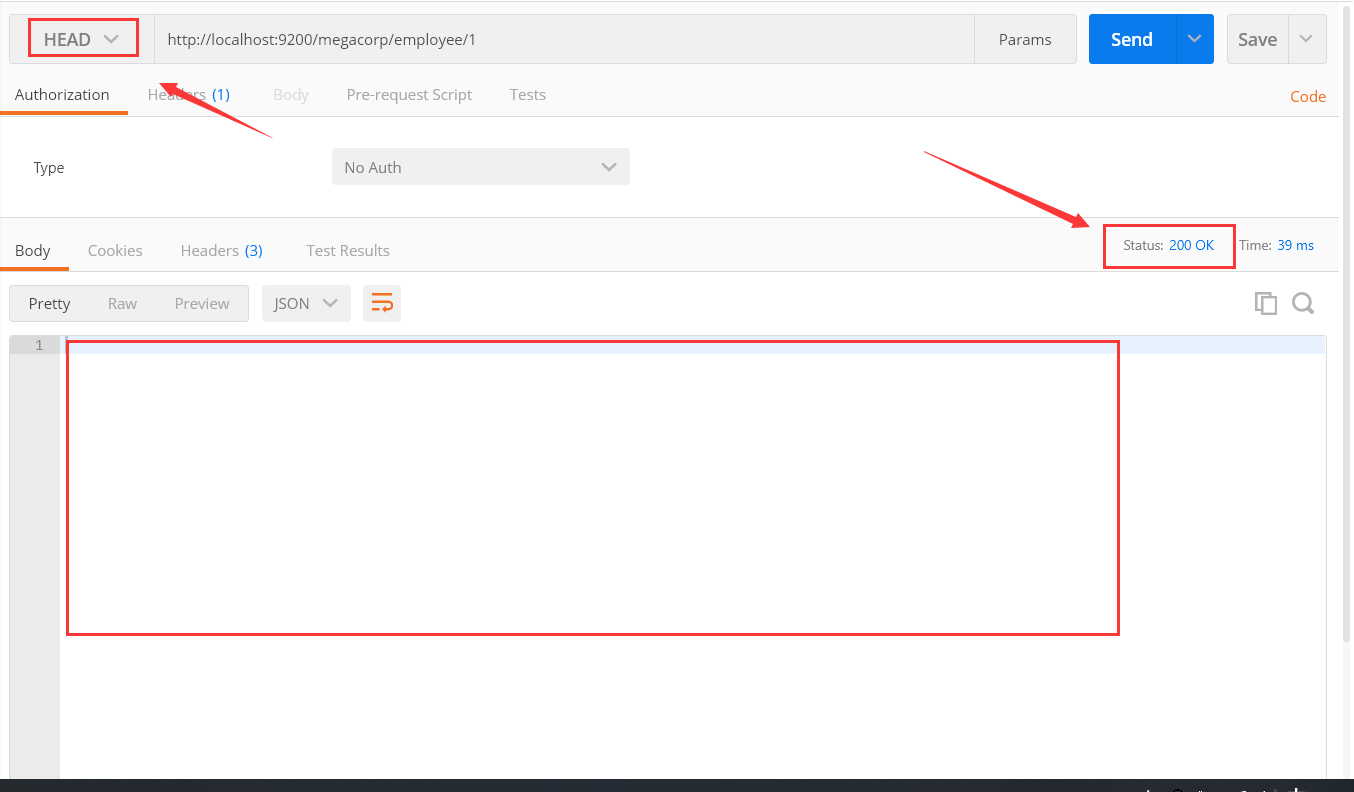
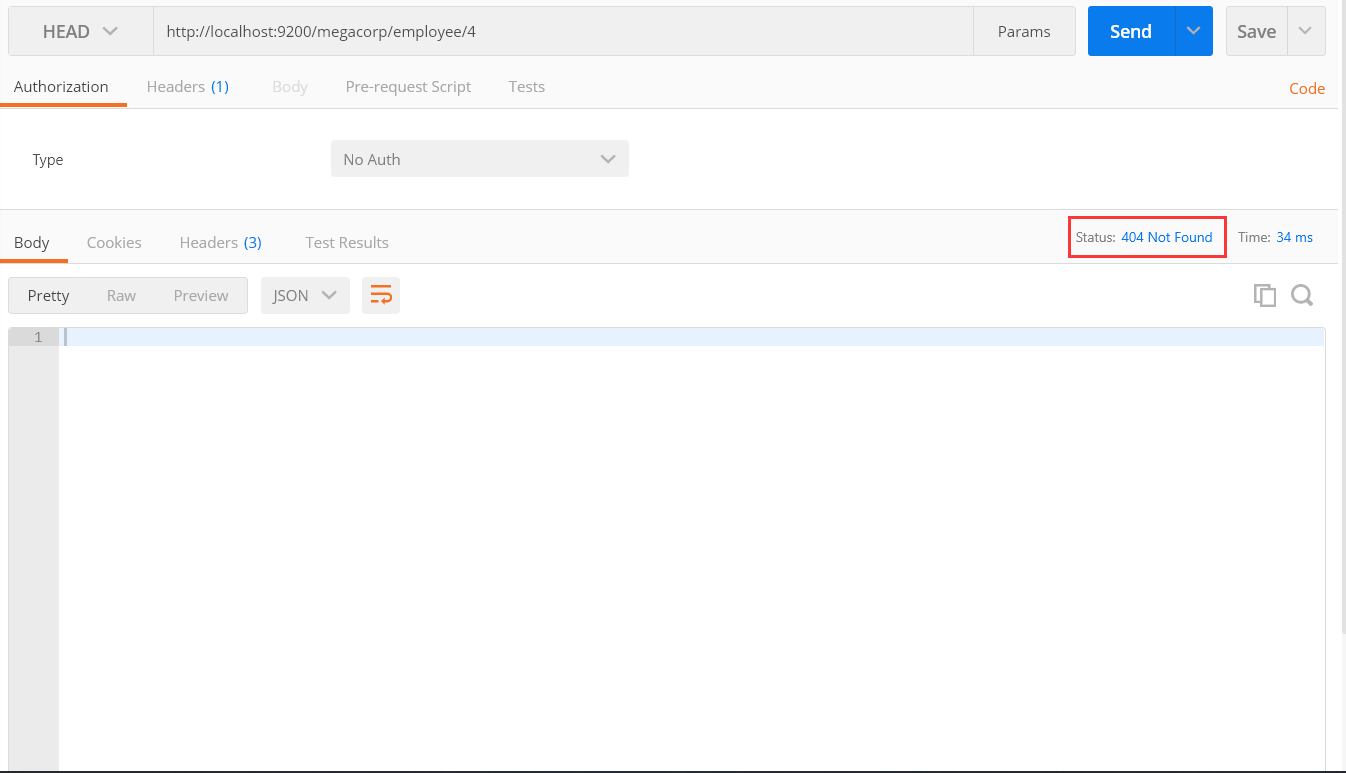
根據圖,我們可以看出,他的確沒有返回結果,但是可以注意到,再右上角他會有一個狀態碼,當有這個資訊時,他的狀態碼就是200,沒有就返回404表示找不到。
三、修改資料
我們使用了GET和POST查詢資料,使用PUT新增資料,根據官方給出的是修改資料還是用PUT,如果存在資料他就會更新資料,這樣的模式確實與我們常見的請求使用方法略有不同。
PUT /megacorp/employee/1
{
"first_name" : "唐",
"last_name" : "菜雞",
"age" : 21,
"about" : "I love to go rock climbing",
"interests": [ "movie", "music" ]
}傳送該請求後,返回引數
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 3
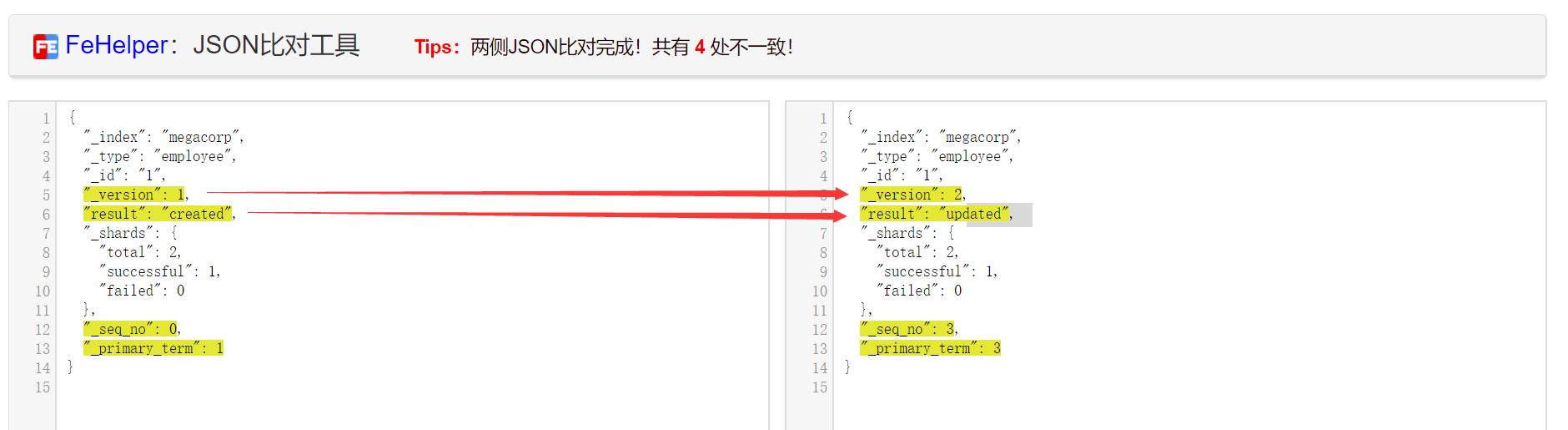
}我們對比可以發現,主要有兩處不同,看圖你就會說,呀不對呀,明明有四處,那是因為之前插入第一條的時候還只有一條引數,現在有三條了,不許抬槓,不許抬槓,不許抬槓。
不同:他的版本加一,返回狀態為created變為updated。
我們再查詢一次就會發現他的資訊已經發現改變,這就是修改。
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 2,
"_seq_no": 3,
"_primary_term": 3,
"found": true,
"_source": {
"first_name": "唐",
"last_name": "菜雞",
"age": 21,
"about": "I love to go rock climbing",
"interests": [
"movie",
"music"
]
}
}四:刪除資料
根據前面,不用想我們也知道刪除資料用的就是delete請求。
DELETE /megacorp/employee/2我們刪除二號員工,返回如下資訊,result變為deleted。
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 3
}作者有話
當然,elasticsearch的功能不僅僅是如此,這些只是他的基本功能之一,更多請看他的開發文件。 傳