
ConcurrentHashMap中節點數目併發統計的實現原理
前言:
前段時間又看了一遍ConcurrentHashMap的原始碼,對該併發容器的底層實現原理有了更進一步的瞭解,本想寫一篇關於ConcurrentHashMap的put方法所涉及的初始化以及擴容操作等的原始碼解析的,但是這類文章在各平臺上實在是太多了,寫了感覺意義不是很大。但學了東西,還是想著儘量能夠輸出點什麼,所以就打算稍微寫寫點偏門的,關於ConcurrentHashMap中統計節點數目的size()方法的實現原理。由於JDK 1.7和1.8中ConcurrentHashMap的原始碼發生了較大的變化,size()方法的底層實現也發生了變動。為此,本文將會通過對比兩個版本的size()方法的底層實現來加深對ConcurrentHashMap的理解。
關鍵字:
原始碼、JDK1.7、JDK1.8、ConcurrentHashMap、LongAdder
思考:
在瞭解具體實現原理之前,我們可以先自己思考該如何實現併發容器中的節點數目統計問題。
一種很自然的想法是,用一個成員變數(size)來統計容器的節點數目,每次對容器進行put或者remove操作時,都對該成員變數(size)進行執行緒安全的更新。這樣,當要獲取容器的節點數目時,直接返回該值即可。
這樣的計數方法在返回結果的時候,速度很快,但是在統計的過程中存在著一個很明顯的問題,就是併發度不高。由於需要對該成員變數(size)進行執行緒安全的更新,為此只能採用獨佔鎖(Synchronized、Lock等)或者CAS(AtomicInteger等)等方式來進行更新,無論採取何種方式,每次都只會允許一個執行緒執行成功。如果採用該方式來實現,節點統計將會成為該容器的瓶頸。且我們知道,ConcurrentHashMap為提高併發度,採用了分段鎖的方式(無論是JDK 1.7還是1.8版本,1.8版本的可以看成進一步提高了分段鎖的粒度)。為此,當採用一個成員變數執行緒安全更新的方式來實現時,分段鎖的實現也變得沒有了意義(因為要在每次put操作或者remove操作之後,執行對該變數的更新操作後才能返回)。
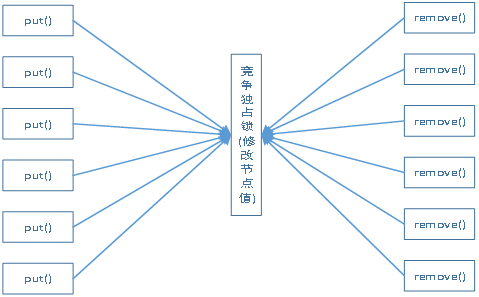
由於上面那種實現方式會導致存在效能瓶頸,那麼為了併發而生的ConcurrentHashMap肯定是不能採用該方式實現的(事實證明,確實沒有采用該方式進行實現)。我們知道, ConcurrentHashMap的底層採用了分段鎖的方式。為此,另一種很自然的想法是讓每個分段自己去統計該區間的節點數目,當在呼叫size()方法時,先一次性獲取所有的分段鎖(防止在統計節點數目時,還在進行節點數目的變動),將每個分段區間都給鎖住,之後依次獲取各個分段區間的節點數目進行彙總,從而得到ConcurrentHashMap全域性的節點數目。那麼該方法是否可行呢?事實上,在JDK 1.7中就是採用了該方式來進行實現的且對該實現方式進行了改進(先嚐試採用不獲取任何獨佔鎖的方式進行統計)。我們可以知道,在JDK 1.7中,每次對ConcurrentHashMap執行put操作,都會獲取該分段區間對應的鎖。為此,該方式天然契合JDK 1.7中ConcurrentHashMap的實現,不會由於各個分段進行節點數目的統計而導致併發度降低的問題。
JDK1.7的實現方式:
在具體瞭解JDK1.7的實現之前,我們可以先看下JDK1.7中的原始碼:
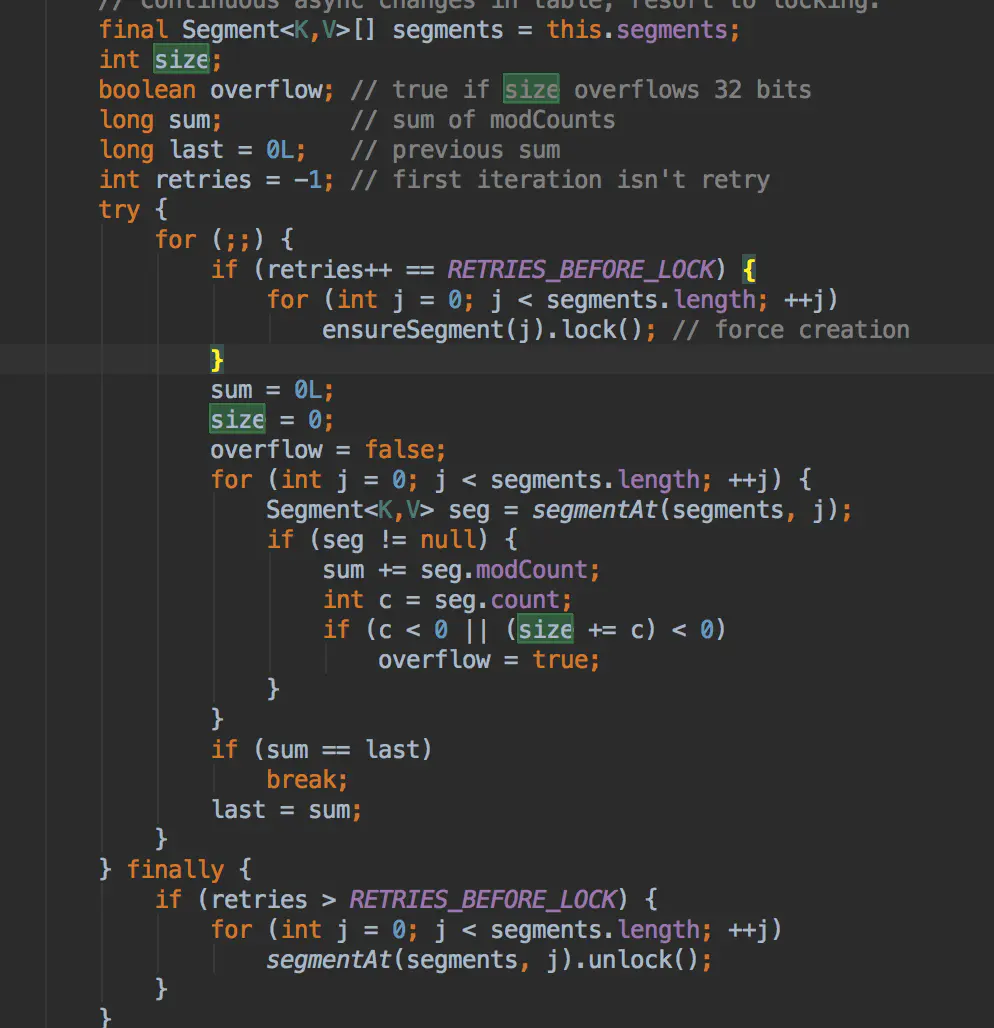
size為各個分段節點數目的總和,sum為各個segment的modCount的總和。我們知道,當segment對應的hashmap底層結構發生修改時(執行了put、remove操作),modCount值便會加一,也就是modCount為segment對應的hashMap修改的次數,sum即為各個segment的修改次數的總和。last為上一次統計的各個segment的修改次數。通過原始碼我們可以得知,其會先進行兩次非獲取獨佔鎖的統計,當sum==last時,也就是上一次統計和這一次統計的過程中,ConcurrentHashMap的各個分段都沒有發生過改動(既沒有新增節點,也沒有刪除節點),則size即為對應的結果。否則,就一次性獲取各個分段的獨佔鎖,再度統計兩次各個分段的節點數,而由於兩次統計的過程中一直持有著各個分段的獨佔鎖,為此,兩次統計的過程中不可能會有別的執行緒對該ConcurrentHashMap進行改動,sum和last值必定相同,最終會退出迴圈。也就是size()方法最多迴圈執行四次,便可以得到節點數統計的結果。
JDK1.8的實現方式:
JDK1.8中ConcurrentHashMap的size()方法的底層實現和在1.8中引入的LongAdder該併發計數類的底層實現原理是相同的。為此,我們只需要瞭解JDK1.8中LongAdder的底層實現方法便可知道ConcurrentHashMap中對size()方法的實現原理。
LongAdder該類繼承自Striped64,同時封裝了相關方法,以實現對併發計數的要求,Striped64該類借鑑了分段鎖的相關思想。其將原本所有執行緒對一個變數進行的執行緒安全的更新操作,擴充套件為不同執行緒對多個不同的計數單元的執行緒安全的操作。
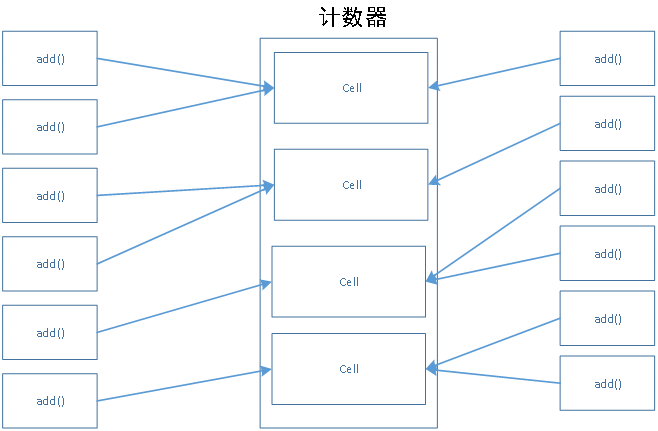
當要獲取總數時,將多個計數單元的值進行累加求和,即可得到最終結果。
在講解LongAdder該類的原始碼之前,我們先了解Striped64該類。
在Striped64該類中,有著如下幾個重要的成員變數和內部類:

NCPU表示系統CPU的數目,cells是計數單元的陣列,其大小始終為2的n次方倍,目的是使取餘運算更加高效。base作為基礎計數變數來使用,執行緒嘗試先將值加在該變數上,如果成功則返回,否則認為存在競爭,則應當去將值新增到對應的計數單元中。cellsBusy是一個用volatile修飾的變數,通過CAS原子更新的方式,充當了自旋鎖的作用,當該值為0時,表示該鎖可以使用,當該值為1時,表示某個執行緒獲取了鎖。
接著我們來看靜態內部類Cell:

內部類Cell為計數單元,其實現較為簡單,成員變數只有一個被volatile所修飾的long型變數value,對該值的修改是通過CAS的方式進行的,用於疊加各個執行緒記錄到該計數單元的值。值得注意的是,該類被註解@sun.misc.Contended所修飾,該註解是用於解決偽共享問題的,這裡就暫時不展開討論偽共享的問題,留到下一篇文章中再講。
接著我們來看Striped64該類中的重要方法,longAccumulate(),該方法完成了計數單元陣列cells的初始化,計數單元陣列某個元素的初始化,擴容以及將值疊加到對應的計數單元上等相關操作。
我們先來解析當cells非空的情況,當其非空時,表明之前存在多執行緒更新base的值發生過沖突。

當cells陣列非空,但對應的計數單元為空,且沒有其它執行緒獲取鎖時,其先嚐試例項化一個計數單元,同時將值傳遞給該計數單元,之後,嘗試獲取鎖,並將該計數單元賦值給cells陣列對應的元素,完成賦值操作後,再釋放鎖,並退出迴圈,進行返回。
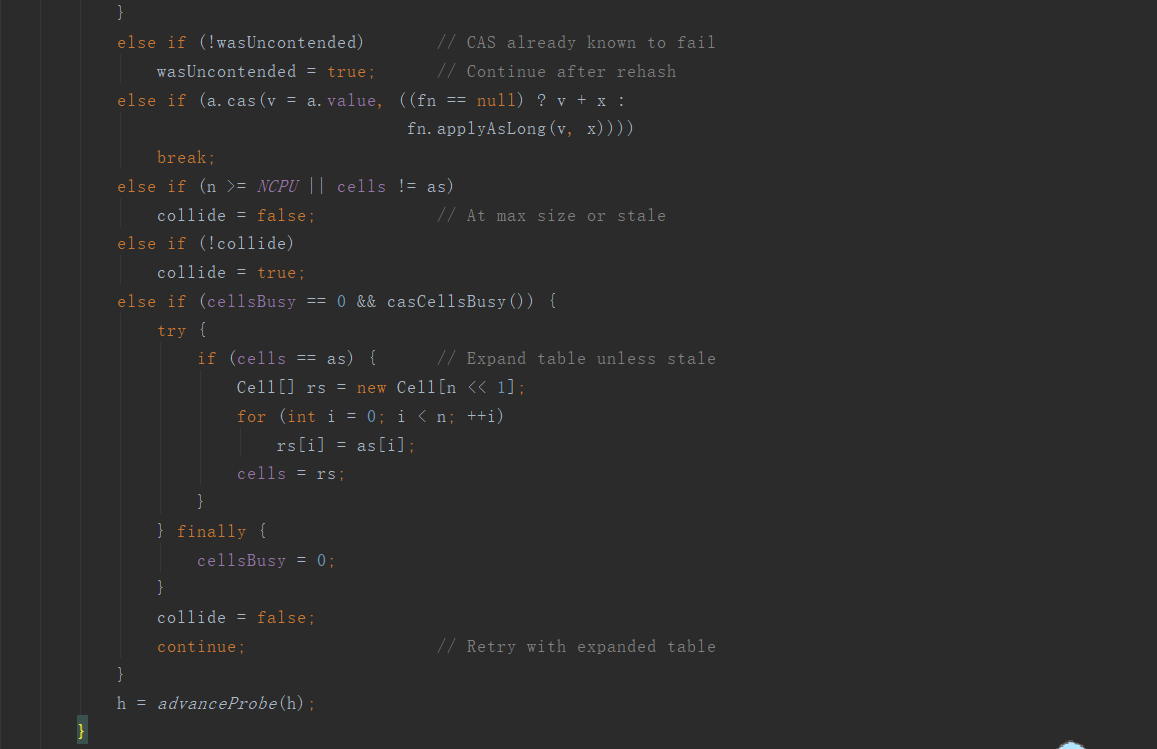
當cells陣列非空,對應的計數單元也非空時,嘗試採用CAS的方式將值疊加到對應的計數單元中,當執行成功時返回。否則,判斷Cell陣列的長度是否是最大的了(大於等於CPU的數目),如已經是最大的了,則重新計算執行緒的hash值,繼續進行操作。如不是,則進行擴容操作。
我們從原始碼中可以得知,每次cells陣列擴容時,其大小為先前大小的2倍,同時將舊計數單元陣列的每個元素直接複製到新表中,完成擴容的過程。以上便是當cells非空時,所進行的相關操作。

當cells陣列為空時,其會先嚐試獲取鎖並初始化陣列,同時將值疊加到對應的計數器單元中,當獲取鎖失敗時,則嘗試將值疊加到基礎計數變數base中,成功時返回,失敗時繼續迴圈操作。以上便是Striped64處理併發情況下統計值的整個過程。
總結:當cells陣列非空時,嘗試將值疊加到某個陣列元素所表示的計數單元中,疊加失敗時,表明存在多執行緒的競爭。此時,如果cells的大小小於CPU數目時,嘗試進行擴容操作,否則,將對應執行緒的hash值進行rehash後,重新執行迴圈過程。當cells為空時,嘗試對cells進行初始化,並將值疊加到對應的計數單元中,執行初始化完成之後返回。否則,當初始化失敗時,嘗試將值疊加到基礎計數變數base中,初始化成功時結束該過程並返回,失敗時,重新執行迴圈過程。
在瞭解了Striped64該類的主要實現方法和相關成員變數後,瞭解LongAdder該類的實現就是一件非常簡單的事情了。
下面我們對LongAdder該類的原始碼進行解析。
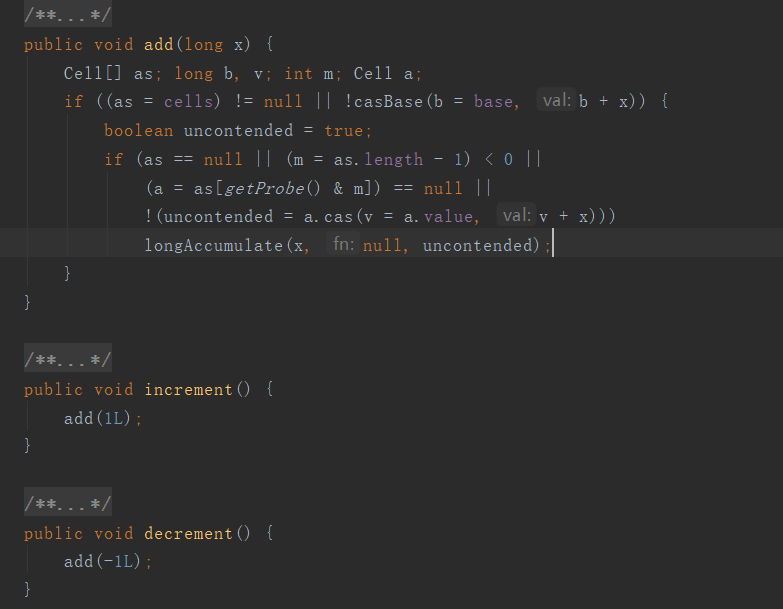
我們可以看到,LongAdder類中核心的便是那個add()方法,當cells還沒有進行初始化時(表明之前不存在多執行緒的競爭累加),其先嚐試將值x通過CAS的方式累加到成員變數base中。當失敗時,表明存在多執行緒之間的競爭,隨後判斷計數單元cells是否已被初始化完成,如果已經初始化(被其它執行緒初始化),則嘗試通過將值x累加到某個計數單元中,當同樣失敗時,執行父類Striped64中的longAccumulate方法,將值累加到對應的計數單元或者base中,以完成累加的過程。
那麼如何獲取統計操作後的結果呢?
其原始碼實現如下所示:
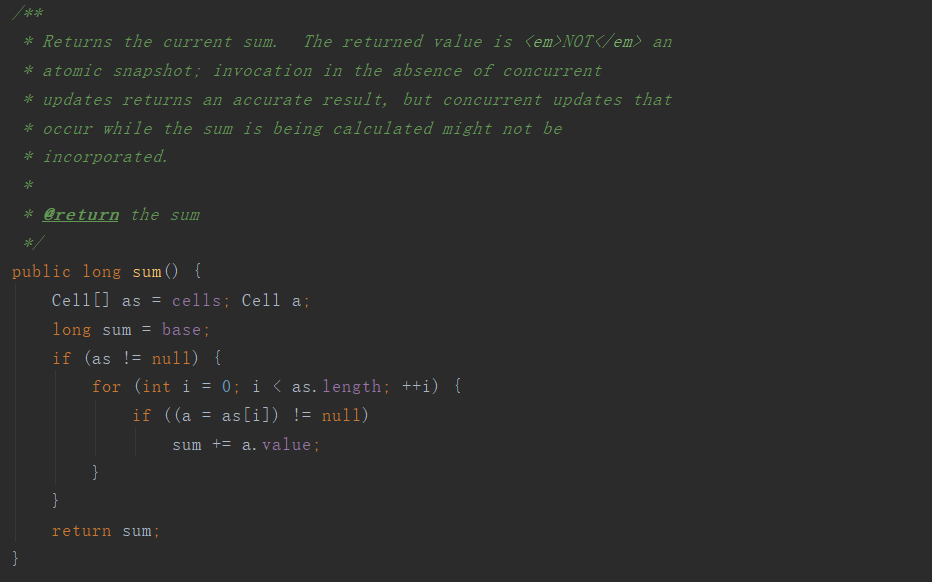
從原始碼中我們就可以得知,其累加了base變數的值和各個計數單元Cell的值作為結果進行返回。當該方法被呼叫的時候,其它執行緒可能還在進行著修改操作,為此,其最終返回的值並非是精確的當前情況下的統計結果,其只是一個“大概”值。當想要獲得精確值時,只能採用對各個計數單元進行加鎖的方式來實現。
一個問題:仔細想想,ConcurrentHashMap為何採用該方式來實現size()方法?我能想到的一個原因是ConcurrentHashMap並不需要精確的節點數目的值,由於ConcurrentHashMap該資料結構是為併發而生的,為此,獲取精確的節點數目的值本身意義並不大。當你消耗了效能,獲取了此時此刻的節點數目的精確值,隨後還是可能會被其他執行緒修改,導致上一刻的值無法使用,為此獲取一個“大概”值便是一個較好的選擇。
這個是本人的公眾號,致力於寫出絕大部分人都能讀懂的技術文章。歡迎相互交流,我們博採眾長,共同進步。

相關推薦
ConcurrentHashMap中節點數目併發統計的實現原理
前言: 前段時間又看了一遍ConcurrentHashMap的原始碼,對該併發容器的底層實現原理有了更進一步的瞭解,本想寫一篇關於ConcurrentHashMap的put方法所涉及的初始化以及擴容操作等的原始碼解析的,但是這類文章在各平臺上實在是太多了,寫了感覺意義不是很大。但學了東西,還是想著儘量能夠輸出
Java併發包中的同步佇列SynchronousQueue實現原理
作者:一粟 介紹 Java 6的併發程式設計包中的SynchronousQueue是一個沒有資料緩衝的BlockingQueue,生產者執行緒對其的插入操作put必須等待消費者的移除操作take,反過來也一樣。 不像ArrayBlockingQueue或LinkedListBlockingQu
SylixOS中AARCH64跳轉表實現原理
body 當前位置 當前 () sylixos water 實現原理 armv8 .text 1. 跳轉表存在的意義 1.1 內核模塊反匯編 如下的程序清單,為一個內核模塊的源碼。 #define __SYLIXOS_KERNEL #include <SylixO
Vue中 key keep-alive的實現原理
入門到 java border 保存 tab clu 創建 培訓 activated vue2.0提供了一個keep-alive組件用來緩存組件,避免多次加載相應的組件,減少性能消耗 keep-aliv是Vue.js的一個內置組件。它能夠不活動的組件實例保存在內存中,而不是
[轉]Android限制只能在主線程中進行UI訪問的實現原理
free fin 主線程 安全 create 其它 pla static http 目錄 Android限制只能在主線程中進行UI訪問 Thread的實現 Android Thread 的構造方法 Android Thread 的start()方
Java中Iterator(迭代器)實現原理
在Java中遍歷List時會用到Java提供的Iterator,Iterator十分好用,原因是: 迭代器是一種設計模式,它是一個物件,它可以遍歷並選擇序列中的物件,而開發人員不需要了解該序列的底層結構。迭代器通常被稱為“輕量級”物件,因為建立它的代價小。 Java中的Iterator功能比
Java併發程式設計(二)——Java併發底層實現原理
Java程式碼會被編譯後變成Java位元組碼,位元組碼會被類載入器載入到JVM中,JVM執行位元組碼,最終轉化成彙編指令在CPU上執行,Java中所使用的併發機制依賴於JVM的實現和CPU的指令。 volatile 在多執行緒併發程式設計中,synchronized和volatile
[轉]Android限制只能在主執行緒中進行UI訪問的實現原理
目錄 Android限制只能在主執行緒中進行UI訪問 Thread的實現 Android Thread 的構造方法 Android Thread 的start()方法 如何在我們自己的程式碼中去檢測當前Thread是不是UI執
Innodb中的事務隔離級別實現原理
前言: 我們都知道事務的幾種性質,資料庫為了維護這些性質,尤其是一致性和隔離性,一般使用加鎖這種方式。同時資料庫又是個高併發的應用,同一時間會有大量的併發訪問,如果加鎖過度,會極大的降低併發處理能力。所以對於加鎖的處理,可以說就是資料庫對於事務處理的精髓所在。這裡通過分析M
coco2d-x中成員函式回撥實現原理
//標頭檔案 #ifndef __COOCS2D_CALLBACK_H__ #define __COOCS2D_CALLBACK_H__ #include <iostream> #include <string> using namespace std;
iOS中__block 關鍵字的底層實現原理
在 《iOS面試題集錦(附答案)》 中有這樣一道題目: 在block內如何修改block外部變數?(38題)答案如下: 預設情況下,在block中訪問的外部變數是複製過去的,即:寫操作不對原變數生效。但是你可以加上 __block 來讓其寫操作生效,示例程式碼如下:
MLlib中決策樹演算法的實現原理解析
決策樹作為一種分類迴歸演算法,在處理非線性、特徵值缺少的資料方面有很多的優勢,能夠處理不相干的特徵,並且對分類的結果通過樹的方式有比較清晰的結構解釋,但是容易過擬合,針對這個問題,可以採取對樹進行剪枝的方式,還有一些融合整合的解決方案,比如隨機森林RandomForest
Akka中Actor訊息通訊的實現原理(原始碼解析)
Akka中通過下面的方法向actor傳送訊息 ! tell 意味著 “fire-and-forget”,即非同步的傳送訊息無需等待返回結果 ? ask 非同步傳送訊息並返回代表可能回覆的Future。 訊息在每個發件人的基礎上是有序的。 Mai
python 中 set 和 dict 的實現原理
1. dict 和 list 查詢效能的比較 from random import randint def load_list_data(total_nums, target_nums): """ 從檔案中讀取資料,以list的方式返回 :param total_nu
淺析 Linux 中的時間程式設計和實現原理
引子 我們都生活在時間中,但卻無法去思考它。什麼是時間呢?似乎這是一個永遠也不能被回答的問題。然而作為一個程式設計師,在工作中,總有那麼幾次我必須思考什麼是時間。比如,需要知道一段程式碼運行了多久;要在 log 檔案中記錄事件發生時的時間戳;再比如需要一個定時器以便能
資料庫連線池併發的實現原理
1 . 概述和說明在資料庫操作中,和資料庫建立連線(Connection)是最為耗時的操作之一,而且資料庫都有最大連線數目的限制, 如何很多使用者訪問的是同一資料庫,所進行的都是相同的操作,比如查詢記錄,那麼,為每個使用者都建立一個連線是不合理的 連線池的思想:Tomcat
Java併發--synchronized實現原理及鎖優化
注:本文中的部分內容摘抄自他人部落格,如有侵權,請聯絡我,侵刪~ 本篇部落格主要講述 synchronized 關鍵字的實現原理以及 JDK 1.6 後對 synchronized 的種種優化。synchronized 的使用不再贅述。 博主目前依舊存在
C++中純虛擬函式的實現原理是什麼,為什麼該純虛擬函式不能例項化?
虛擬函式的原理採用 vtable。 類中含有純虛擬函式時,其vtable 不完全,有個空位。 即“純虛擬函式在類的vftable表中對應的表項被賦值為0。也就是指向一個不存在的函式。由於編譯器絕對不允許有呼叫一個不存在的函式的可能,所以該類不能生成物件。在它的派生類中,除非
[轉]淺析 Linux 中的時間程式設計和實現原理,第 1 部分: Linux 應用層的時間程式設計
引子 我們都生活在時間中,但卻無法去思考它。什麼是時間呢?似乎這是一個永遠也不能被回答的問題。然而作為一個程式設計師,在工作中,總有那麼幾次我必須思考什麼是時間。比如,需要知道一段程式碼運行了多久;要在 log 檔案中記錄事件發生時的時間戳;再比如需要一個定時器以便能夠定期做某些計算機操作。我發現,在計算機
spring web.xml中 攔截器(Interceptor)的實現原理及程式碼示例
前言:前面2篇部落格,我們分析了Java中過濾器和監聽器的實現原理,今天我們來看看攔截器。1,攔截器的概念 java裡的攔截器是動態攔截Action呼叫的物件,它提供了一種機制可以使開發者在一個Action執行的前後執行一段程式碼,也可以在一個Action執行前阻止其執