
Boltzmann Machine 玻爾茲曼機入門
阿新 • • 發佈:2020-11-14
# Generative Models
生成模型幫助我們生成新的item,而不只是儲存和提取之前的item。Boltzmann Machine就是Generative Models的一種。
# Boltzmann Machine
## Boltzmann Machine和Hopfield Network對比
- Energy Function是相同的
- 神經元$x_i$的取值在0和1之間,而不是Hopfield Network中的-1和1。
- 使用Boltzmann Machine來產生新的狀態,而不是提取儲存的狀態。
- 更新不是確定性的,而是隨機性的,使用Sigmoid函式。
## Boltzmann Distribution
Boltzmann Distribution是一種在狀態空間上的概率分佈,公式如下:
$$
p(x) = \frac{e^{\frac{-E(x)}{T}}}{Z}
$$
- $E(x)$:energy function
- T:是溫度
- Z:partition function,用來保證$\sum_x p(x)=1$
通常情況下,直接計算partition function很複雜。但是我們可以利用相鄰狀態的相對概率通過迭代過程從分佈中取樣。
## Gibbs Sampling
參考部落格:https://www.cnblogs.com/aoru45/p/12092453.html
假設我們有一個影象x,對於所有的元素$x_i=1$。每一次操作,我們只將一個$x_i$變為0,其他的不變,從而得到一個新的影象。
我們用如下的公式來表示兩個影象之間的energy function的差:
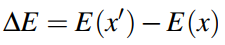
我們可以得到新影象的Boltzmann Distribution,如下:
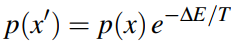
因此,對於所有固定的元素,$x_i$取得1或者0的概率如下所示:
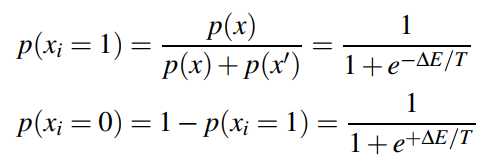
## Boltzmann Machine
Boltzmann Machine的操作和Hopfield Network很像,只是再更新神經元的步驟上又差別!Boltzmann Machine在神經元更新的時候有隨機性。
在Hopfield Network中, $x_i$的變化使得energy function永遠不會增大。但是在Boltzmann Machine中,我們用一個概率來令$x_i=1$:
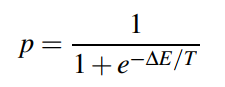
換句話說,這個概率有可能讓energy function的值變大。所以:
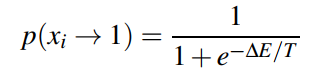
- 如果這個過程重複迭代很多次,我們最終將會獲得一個Boltzmann Distribution中的樣本
- 當$T\rightarrow \infty$,$\space p(x_i\rightarrow1)=1/2$並且$\space p(x_i\rightarrow0)=1/2$
- 當$T\rightarrow 0$,這個行為將會變得很像Hopfield Network,永遠不會讓Energy Function增大。$\space p(x_i\rightarrow1)=0$
- 溫度T可能是一個固定值,或者它一開始很大,然後逐漸的減小(**模擬退火,Simulated Annealing**)
## Limitations
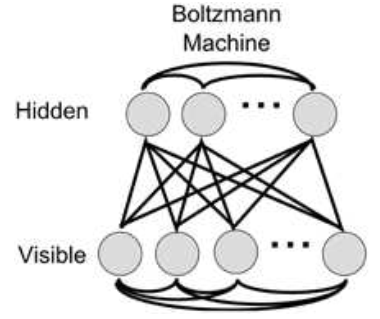
Boltzmann Machine的侷限性在於,每個單元的概率必須是周圍單元的線性可分函式。所以,我們可以考慮到的解決辦法就是增加隱藏層,將可見的單元和隱藏的單元分開。類似於前饋神經網路中的輸入層和隱藏層。目的就是讓隱藏單元學習一些隱藏的特徵或者潛在的變數,從而幫助系統去對輸入進行建模。結構如下圖所示:
# Restricted Boltzmann Machine
如果我們讓所有的可見單元之間和隱藏單元之間互相存在連線,訓練網路要花非常長的時間。所以,我們通常限制Boltzmannn Machine只在可見單元和隱藏單元之間存在連線,如下圖所示:

這樣的網路就被稱作Restricted Boltzmann Machine,受限玻爾茲曼機。主要特徵是:
- 輸入是二元向量
- 是兩層的雙向神經網路
- 可見層,v,visible layer
- 隱藏層,h,hidden layer
- 沒有vis-to-vis或者hidden-to-hidden連線
- 所有可見單元連線到所有隱藏單元,公式如下:$E(v, h) = -(\sum_i b_i v_i + \sum_j c_j h_j + \sum_{ij} v_i w_{ij}h_j)$
- $\sum_i b_i v_i$:可見層偏差
- $\sum_j c_j h_j$:隱藏層偏差
- $\sum_{ij} v_i w_{ij}h_j$:可見單元和隱藏單元之間的連線
- 訓練使資料的期望對數概率最大化
因為輸入單位和隱藏單位是解耦的,我們可以計算h在v下的條件分佈,反之亦然。
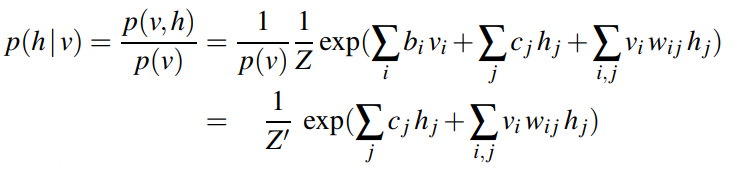
於是,
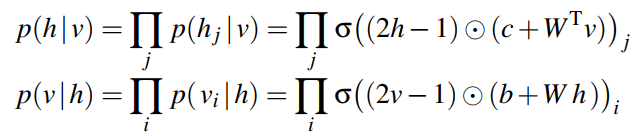
- :component-wise multiplication
- σ(s) = 1/(1 + exp(-s)) ,是Sigmoid函式
## Alternating Gibbs Sampling

在Boltzmann Machine中我們可以從Boltzmann Distribution中進行如下抽樣:
- 隨機選擇$v_0$
- 從$p(h|v_0)$中抽樣$h_0$
- 從$p(v|h_0)$中抽樣$v_1$
- 從$p(h|v_1)$中抽樣$h_1$
- ...
# Training RBM
## Contrastive Divergence
通過對比真實和虛假的圖片進行訓練,優先選擇真實的圖片
1. 從訓練資料中選擇一個或者多個positive samples { $v^{(k)}$ }
2. 對於每一個$v^{(k)}$,從$p(h|v(k))$中抽樣一個隱藏向量$h^{(k)}$
3. 通過alternating Gibbs sampling 生成一個fake樣本{$v'^{(k)}$}
4. 對於每一個$v'^{(k)}$,從$p(h|v'^{(k)})$中抽樣一個隱藏向量$h'^{(k)}$
5. 更新${b_i}$,$c_j$,$w_{ij}$去增大$log\ p(v^{(k)}, h^{(k)}) - log\ p(v'^{(k)}, h'^{(k)})$
- $b_i \leftarrow b_i + \eta(v_i - v'_i)$
- $c_j \leftarrow c_j + \eta(h_j - h'_j)$
- $w_{ij} \leftarrow w_{ij} + \eta(v_i h_j - v'_i h'_j)$
## Quick Contrastive Divergence
在2000‘s的時候,研究人員注意到,這個過程可以通過只取一個額外的樣本來加速,而不是執行多次迭代。
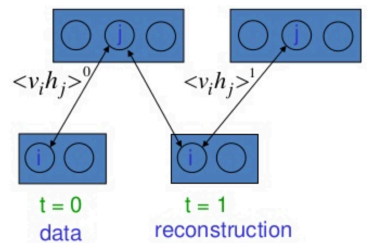
從實數開始,生成隱藏單元,生成假(重構)數字,並分別作為正樣本和負樣本進行訓練
1. $v_0, h_0$: positive sample
2. $v_1, h_1$:negative sample
# Deep Boltzmann Machine
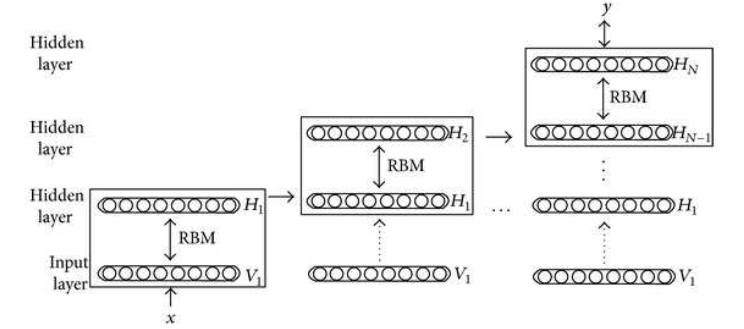
和Boltzmann Machine是相同的方法,但是可以迭代的應用於多層網路。
首先訓練輸入到第一層的權重。然後保持這些權重不變,繼續訓練第一層到第二層之間的權重,以此類推。
# Greedy Layerwise Pretraining
Deep Boltzmann Machine的一個主要應用是Greedy unsupervised layerwise pretraining(貪婪無監督逐層與訓練)。
連續的對每一對layers進行訓練,訓練成RBM。
當模型訓練完成之後,權重和偏差會被儲存下來,在下一次進行類似的任務時會被當做前饋神經網路的初始權重和偏差,然後再根據當前任務資料進行反向傳播訓練。
對於Sigmoid或者tanh啟用函式,這一類的預訓練能夠比直接進行隨機初始化權重然後訓練取得更好的