
這個Map你肯定不知道,畢竟存在感確實太低了。
這是why哥的第 75 篇原創文章

從Dubbo的優雅停機說起
好吧,其實本文並不是講 Dubbo 的優雅停機的。
只是我在 Dubbo 停機方法 DubboShutdownHook 類中,看到了這樣的一段程式碼:
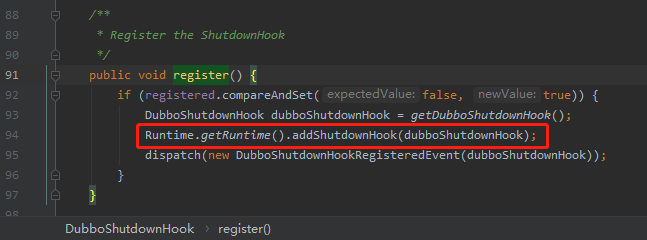
很明顯,這個地方最關鍵的地方是紅框框起來的部分。
而這個 addShutdownHook 其實是 JDK 的方法:
java.lang.Runtime#addShutdownHook
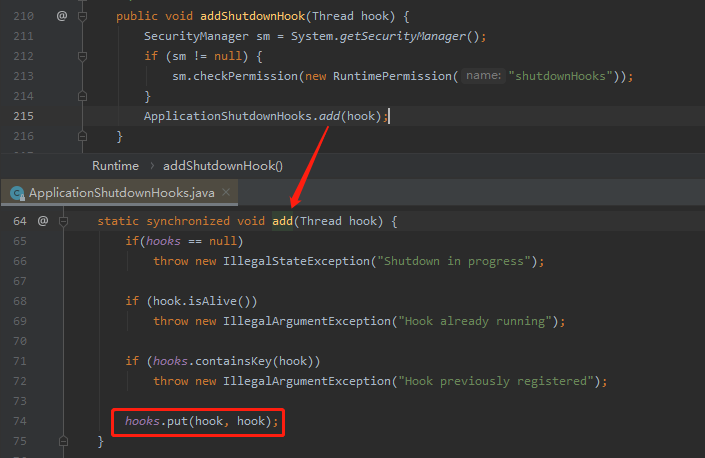
最終,把傳進來的 hook 放到了 hooks 裡面。
你說 hooks 是這個什麼玩意?
這個 hooks 呼叫的是 put 方法,裡面放了一個 key,一個 value。
盲猜也知道:這個 hooks 肯定是一個 Map。那麼這麼多 Map 具體是哪個呢?
來看看答案:
.jpg)
說真的,第一次看到這個 IdentityHashMap 的時候,我都有點愣住了。
一時間居然想不起來這是個什麼玩意了,只是覺得有點眼熟。
至於它是幹啥的,有啥特性,那就更是摸不清楚了。
於是我去了解了一下,發現這玩意,有點意思。屬於學了基本沒啥卵用,但如果你知道,偶爾會出奇制勝的東西。

有啥不一樣
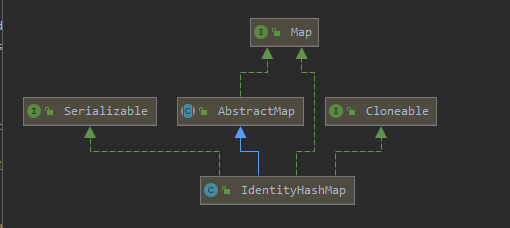
IdentityHashMap 也是 Map 家族中的一員。只是他的存在感也太低了,很多人都不知道還有這麼一個玩意。
甚至感覺它是一個第三方包裡面引進的類,沒想到居然是一個親兒子。
說到 Map 家族,大家最熟悉的也就是 HashMap 了。
那麼這個 IdentityHashMap 和 HashMap 有什麼區別呢?
先上個程式碼給大家看看:
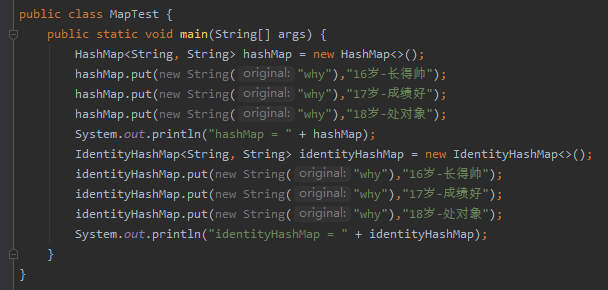
先不說後半部分輸出什麼了。
前面的 hashMap 最終的輸出結果你肯定知道吧。
由於多次 new String("why") 出來的字串物件的 hashCode 是一樣的。
所以,最終 hashMap 裡面只會留下最後一個值。
這個點,之前的這《why哥悄悄的給你說幾個HashCode的破事》篇文章中已經講過了。相信不需要我再次補充。
疑問點是 identityHashMap 最終會輸出什麼呢?
來,看看結果:
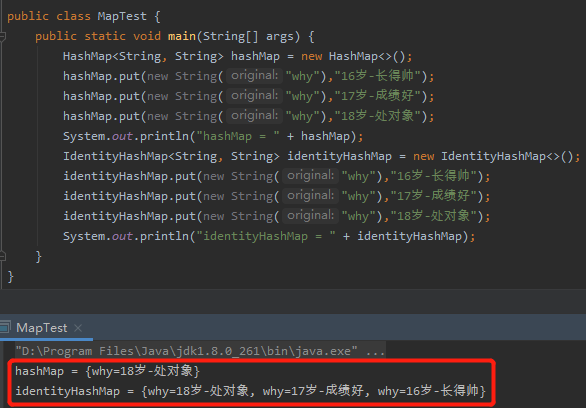
OMG,什麼鬼?identityHashMap 裡面把三個值都存下來啦?這麼神奇的嗎?怎麼做到的?
先不去想它怎麼實現的,我們就把它當個黑盒使用。
那麼它在給我們傳遞什麼樣的資訊?
我們可以存多個相同的 key 到 map 裡面了。
比如這樣的:

我把前面的示例程式碼的中的 String 換成 Person 物件。
來,你先告訴我,hashMap 裡面放了幾個物件?一個還是三個?
什麼,一個?
你出去,你個假粉絲!你自己看看是幾個:

之前的文章裡面說過了,hashMap 裡面,如果我們要用物件當做 key。我們應該怎麼辦?
必!須!要! 重寫物件的 hashCode 和 equals 方法。
HashMap 才會是表現的和我們預期一樣。
所以,當我們重寫了物件的 hashCode 和 equals 方法後,執行結果是這樣的:
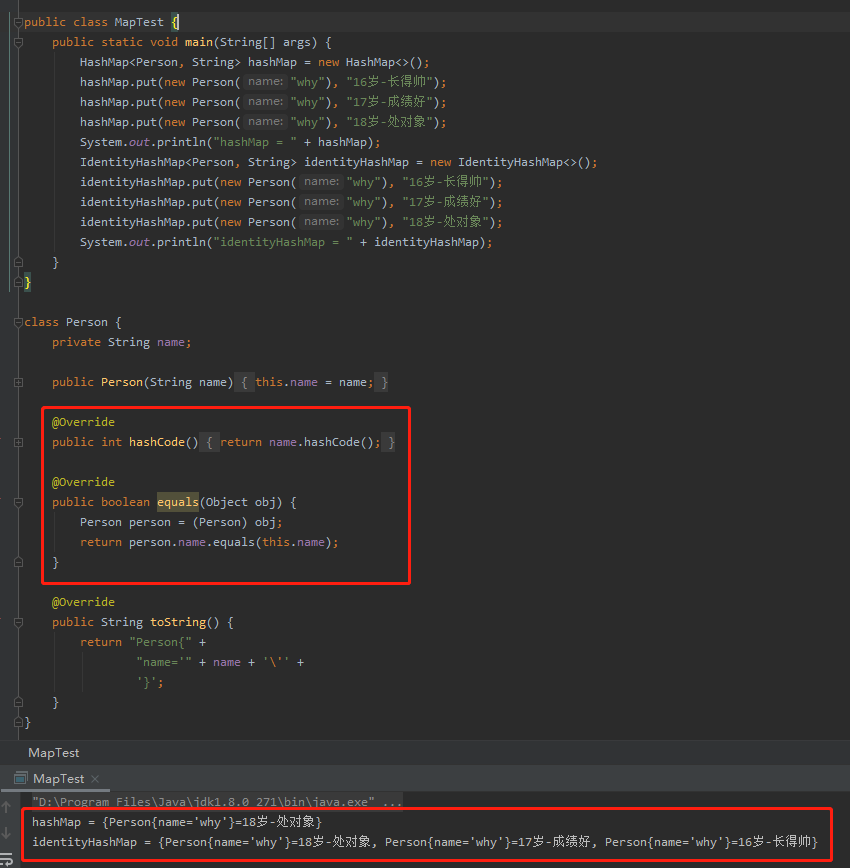
這兩個容器的執行結果,含義是不一樣的。
hashMap 只能看到 18 歲的 why。
identityHashMap 可以看到 16 到 18 歲的 why。
總之,你是否重寫了物件的 hashCode 和 equals 方法,identityHashMap 都不關心。
那麼 identityHashMap 是怎麼實現這個效果的呢?
我們去原始碼中尋找一下答案。
暢遊原始碼-PUT
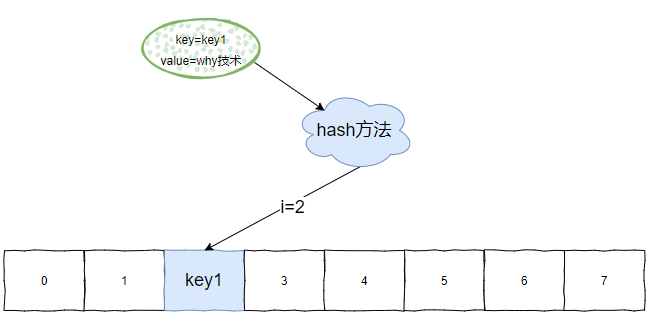
在講原始碼之前,我先把 identityHashMap 的儲存套路給你說一下,你看原始碼的時候就輕鬆多了。
不管怎麼它還是一個 Map,那麼必然就有對應的 hash 方法。
對於 identityHashMap 而言,經過 hash 方法,計算出 key 的下標為 2:
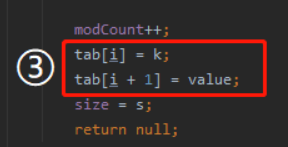
key 放好了,然後 value 直接放到 i+1 的位置:
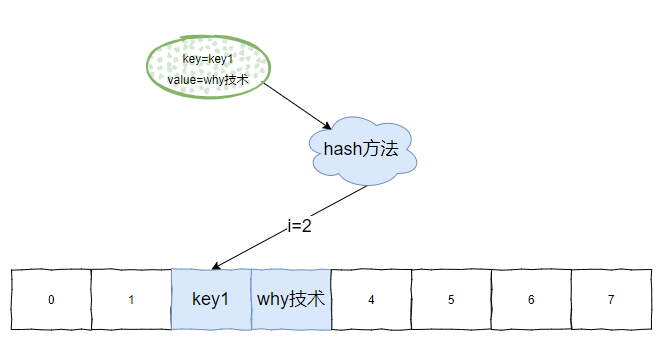
key 的下一個位置,就是這個 key 的 value 值。 這就是 identityHashMap 的儲存套路。它的資料結構不是陣列加連結串列,就完完全全是一個數組。
記住這個套路,我們先從 put 方法的原始碼入手:
java.util.IdentityHashMap#put
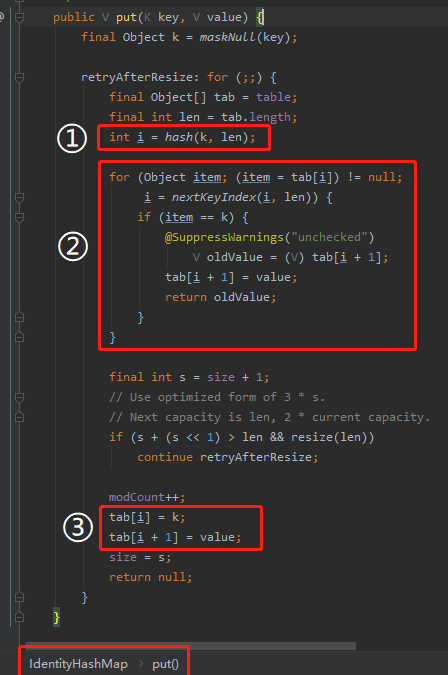
在標號為 ① 的地方,就是 hash 方法,入參是我們傳入的物件和 table 的長度。
table 是個什麼玩意呢?

是一個 Object 的陣列。所以,我們知道了 identityHashMap 的資料結構它還是一個數組,而且看註釋:這個 table 的長度必須是 2 的整數倍,也就是偶數。
那麼陣列的預設長度是多少呢:
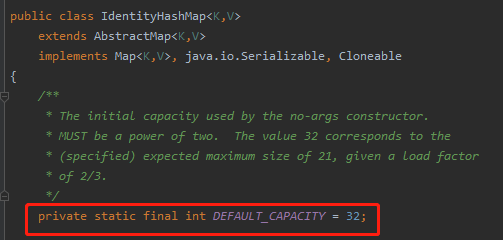
是的,看起來是 32。
但是當我對程式進行除錯的時候我發現,這個 len 居然是 64:
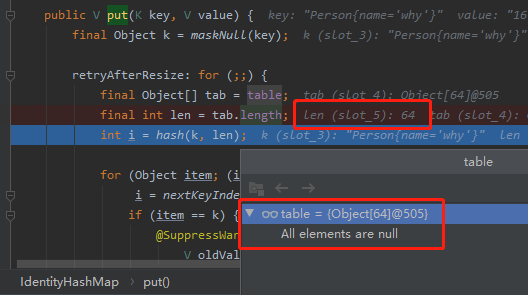
可以看到這個 table 數組裡面什麼東西都沒有,也就根本不存在觸發擴容什麼的。
為什麼長度是 64 呢?說好的 32 呢?
後來我在構造方法中找到了答案:

臥槽,說好的預設容量 32,你初始化的時候直接翻倍了?
這是什麼行為?年輕人,你這程式碼,不講武德啊!

但是你轉念一想。預設容量 32 是指的 key 的容量。而一個 key 對應一個 value。 key + value 總共不就是 64 的長度嗎?
好了,我們接著看 hash 方法的具體實現:
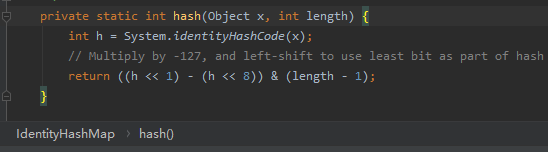
hash 方法只有兩行。但是這兩行都非常的關鍵。
先看第一個 System.identityHashCode,這個是什麼東西?
看看 API 上的解釋:

就是對於一個物件,不管你有沒有重寫 hashCode 方法,該方法返回的值都是不會變化的。
看兩個示例程式碼:
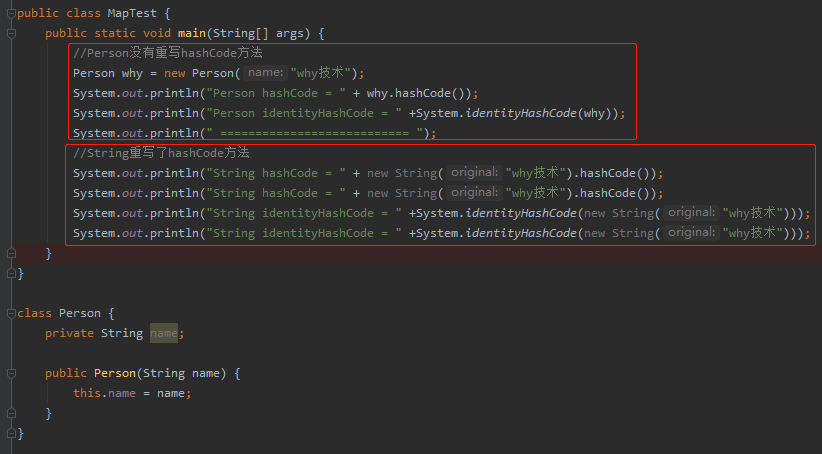
注意 Person 物件是沒有重寫 hashCode 方法的。
程式的最終輸出結果是這樣的:
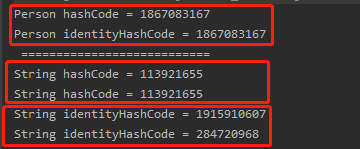
我們分成三個部分去看,我們可以發現。
當物件(Person)沒有重寫 hashCode 方法的時候,他們的 hashCode 和 identityHashCode 是一樣的。
即使物件(String)重寫了 hashCode 方法,對於不同的物件,hashCode 值是一樣的,但是 identityHashCode 可能是不一樣的。
注意是“可能不一樣”。因為 identityHashCode 的底層邏輯是基於一個偽隨機數生成的。
這個特性特別有用,但是也別亂用。用錯了,就是一個 bug。
比如在 identityHashMap 裡面的使用就是一個正確的使用。至於錯誤的使用,我們稍後會講。
經過前面的分析我們知道了:hash 方法中的第一行程式碼,對於 new 出來的相同物件的不同例項,不管是否重寫 hashCode 方法,會產生不同的 identityHashCode。
可以說 System.identityHashCode 方法,是整個 identityHashMap 的基石。
然後再看這一行程式碼:
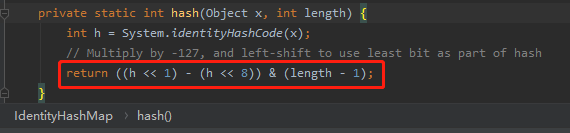
很多朋友第一眼看到位運算,心裡就稍微有點牴觸。
別這樣,我帶你分析一下,很簡單的。
首先,我前面畫圖示意了 identityHashMap 的儲存套路,說了:key 的下一個位置就是這個 key 的 value。
那麼 key 的位置一定要是一個偶數。
這一點能不能跟上?跟不上你就多想想再往下看。

而 hash 方法就是計算 key 的位置。
所以,該方法的返回值一定是一個偶數。
這縝密的邏輯,是不是無懈可擊。
假設 length 為 64 的話,那麼這一行程式碼的目的是為了生成一個 0 到 63 之間的偶數。
0 到 63 之間的數,是 &(length-1) 保證的。這個沒啥說的。
那麼為什麼一定會生成一個偶數呢?
h<<1 的最終結果肯定是一個偶數吧?
h<<8 的最終結果肯定也是一個偶數吧?
那麼偶數減去偶數是一個什麼數?
什麼,你問我會不會溢位?
你管它溢位不溢位,就算它變成負數了,變成 0 了,它也是一個偶數呀!

偶數的二進位制的最後一位是不是 0?
length-1 這個數的二進位制最後一位不是 0 就是 1,對不對?
0 & 上 0 或者 1,是不是還是 0?
那不就對了。所以,最終結果肯定是一個偶數的。
經過前面的分析,我們知道了標號為 ① 的地方返回的 i 肯定是一個 0 到 len-1 之間的偶數:

返回的這個偶數 i,在標號為 ② 和 ③ 的地方都有用到。
標號為 ② 的地方是檢查傳進來的這個 key 是否在陣列中已經存在了,也就是我們說的是否 hash 衝突。
如果沒衝突,繼續往下執行。
如果衝突了,且 value 值存在,就替換 value 值,然後返回。
如果衝突了,且 value 值不存在, i 值經過 nextKeyIndex 方法後也發生了變化。
下標 i 是怎麼變化的呢?
假設我們來了一個 key=key2 的元素,經過 hash 計算後,對應陣列下標為 2,但是該位置上已經有了一個 key1 ,那麼就是發生了 hash 衝突:
.jpg)
發生衝突,i+2,也就是找到下一個偶數下標。
程式碼中是這樣的體現的:

當 key2 的 identityHashCode 和 key1 一樣,發生 hash 衝突之後,是這樣儲存的:
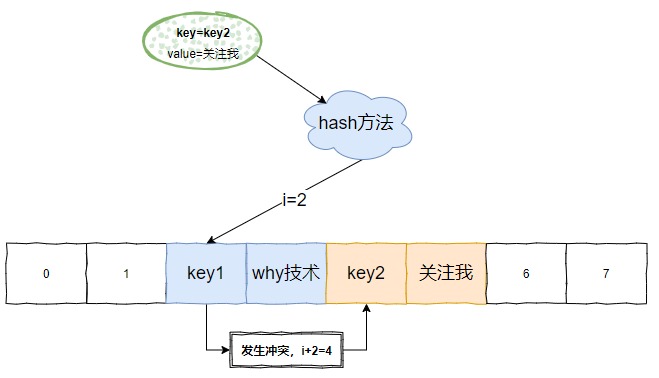
那勢必會出現 i+2 的結果比 len 還長的情況:
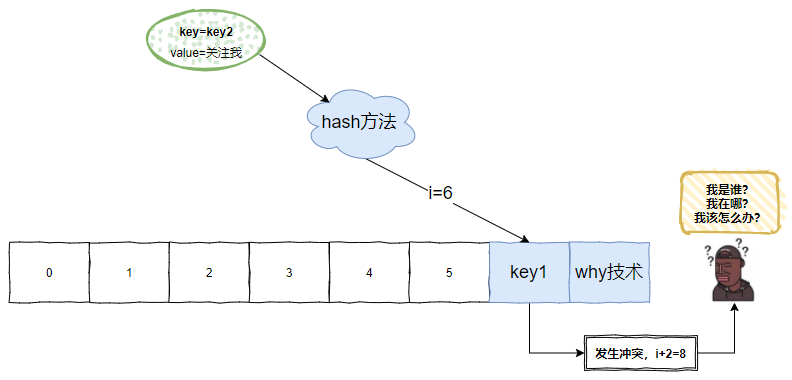
你發現原始碼是怎麼解決這個問題的嗎?
這個 nextkeyIndex 這個方法首尾相接,它是一個圓啊:

這種情況,這個圓,畫圖是怎麼體現的呢?

怎麼樣,是不是很騷。
執行到編號為 ③ 的地方,就很清晰了:
key 是放在 tab[i] 的位置的。
value 是放在 tab[i+1] 的位置的。
和我們畫圖的邏輯一致。
暢遊原始碼-GET
接下來我們看看 get 方法:
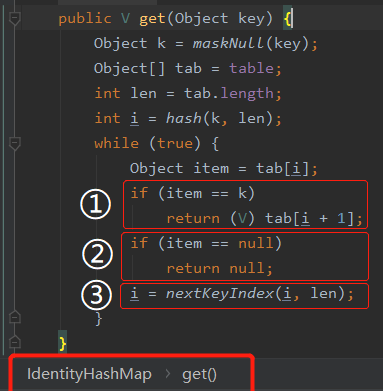
標號為 ① 的地方,直接取到了對應的 key。
你注意這個地方,用的是 == 來判斷物件是否相等,hashMap 用的是 equals 。
標號為 ② 的地方,是沒有對應的 key,直接返回 null。
走到標號為 ③ 的地方,代表這個 key 發生過 hash 衝突。那麼接著找下一個偶數位下標的 key。
比如我們這裡的 key2:
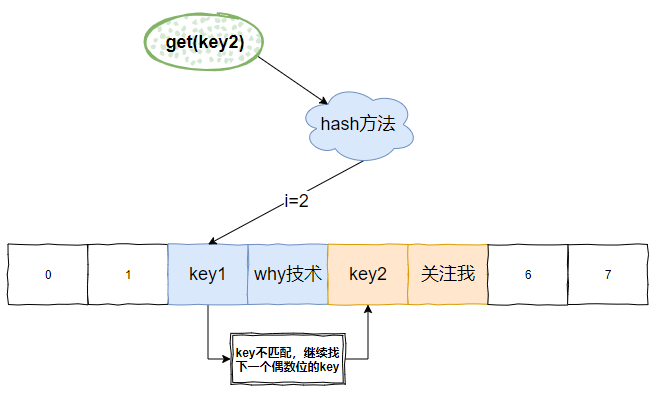
整個過程還是非常清晰的。學習的時候可以和 hashMap 的 get 方法進行對比學習。
你會發現,思想是一個思想,但是解決方案是完全不同的解決方案。
暢遊原始碼-REMOVE
接著再看最後一個 remove 方法:
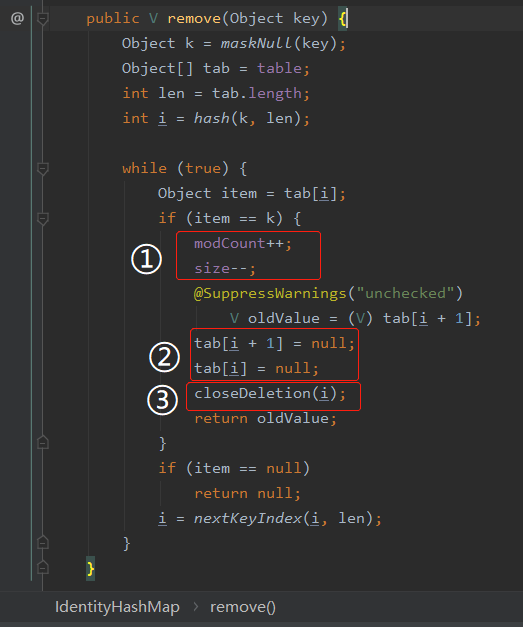
首先,標號為 ① 的地方,你想到了什麼東西?
我看到這個 modCount 可太親切了。圍繞著這個玩意,我前前後後大概寫了有 3w 多字的文章吧:
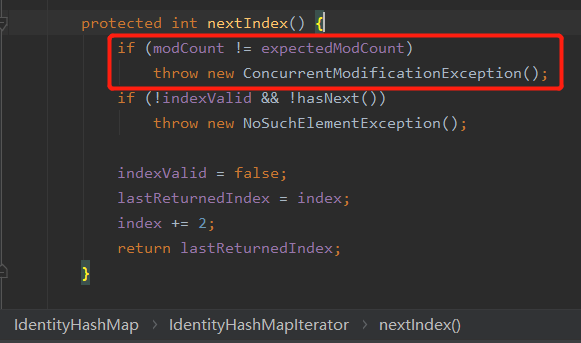
是為了丟擲 ConcurrentModificationException 服務的。
這裡體現的是 fast-fail 的思想。
關於這個異常最經典的一個面試題就是:ArrayList 如果一邊遍歷,一邊刪除,會出現什麼情況?
什麼?你不會?我也不回答了。
假粉絲,請你回去等通知吧。
標號為 ② 的地方,把 i 和 i+1 的位置都置為 null。也就是把 key 和對應的 value 都置為 null。
執行完標號為 ② 的地方, remove 的操作也就完成了。
那麼按理來說方法就應該結束了。對嗎?

你想一想我之前的這個圖片:

如果這個時候我要移除 key=key1 的鍵值對,當標號為 ② 的地方執行完成後,是這個樣子的:
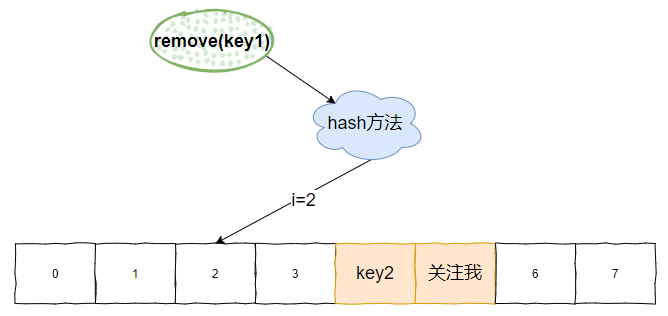
發現問題了嗎?
如果這個時候我來查詢 key2,而 key2 經過 hash 方法後計算出來的 i 還是 2,而對應位置上的值是 null:
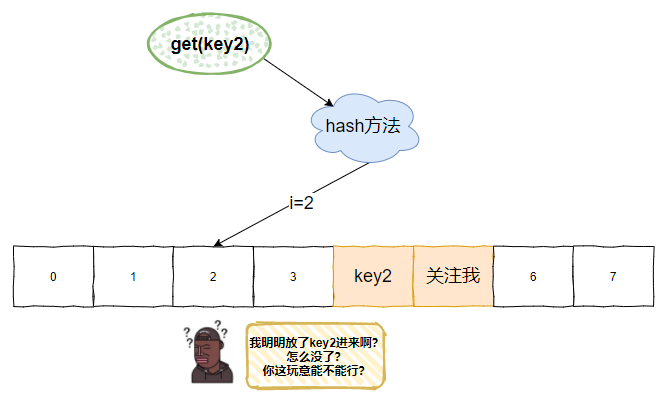
這個時候你告訴我 key2 查不到,返回一個 null 給我?
key2,啪,沒了!

所以,標號為 ③ 的地方就是為了解決這個問題的。
java.util.IdentityHashMap#closeDeletion
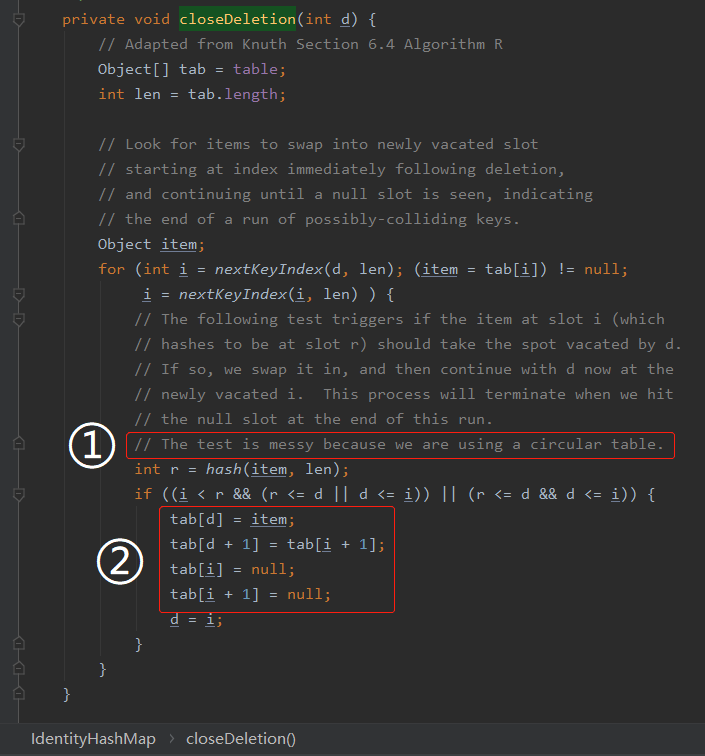
你看這個方法標號為 ① 的地方,自己都說了:
朋友,因為我們這個結構是一個圓,這個方法比較混亂。做好心理準備。
然後就是一個異常複雜的 if 判斷。
這個我是看懂了,但是屬於只可意會不可言傳的那種,所以就不給大家分析了。大家有興趣的自己去看看。
只要你抓準了它的儲存機制和方法功能,理解起來應該不算很費勁。

再看標號為 ② 的地方,理解起來就很容易了,把之前由於 hash 衝突導致的位置偏移的資料,一個個的往前挪:
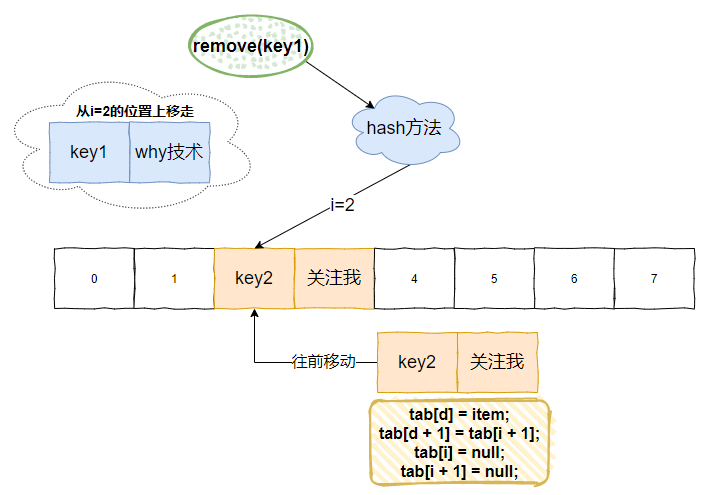
意思就是上面圖片的意思。
先把 key1 從 i=2 的位置移走。然後把 i=4 的 key2 往前移動 2 位。
這樣,下次來查詢 key2 的時候,就能得到正確的返回了。
這裡留下一個疑問,假設下面這個場景:
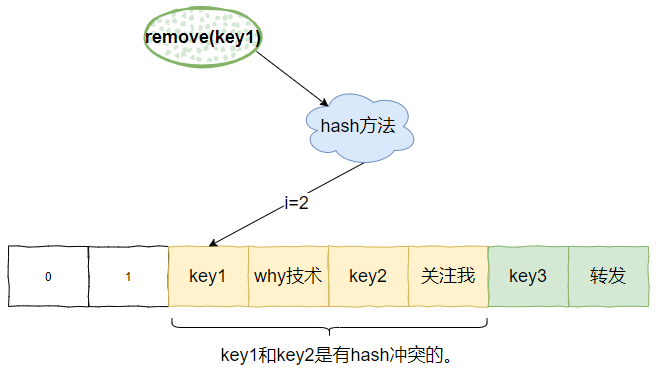
key1 和 key2 是有 hash 衝突的,但是 key3 是正常的。
那麼移除掉 key1 之後的圖應該是這樣的:

程式碼是怎麼控制或者說怎麼知道 key2 和 key1 是有衝突的,所以移走 key1 之後,需要把 key2 往前移動。而 key3 和 key2 是沒有關係的,所以 key3 放著不動。
答案其實就藏在 closeDeletion 方法的原始碼裡面,就看你有沒有徹底理解這個方法了。
好了,到這裡關於 identityHashMap 增刪改查我們就分享完畢了。
老規矩,原始碼導讀,點到為止。
就像傳統功夫,都是點到為止。年輕人,不講武德,耗子尾汁...

馬老師可真是我最近一段時間的快樂源泉啊。
咦,偏了偏了,說程式設計呢,怎麼說到馬老師那邊去了。
難道我不經意間發現了:萬物皆可馬保國定律?
identityHashCode的錯誤使用
前面說了,IdentityHashMap 的核心點在於 System.identityHashCode 方法。
說到這個 identityHashCode 我又想到了曾經在 Dubbo 中的看到的一段原始碼。
位於一致性雜湊負載均衡演算法中:
org.apache.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance#doSelect
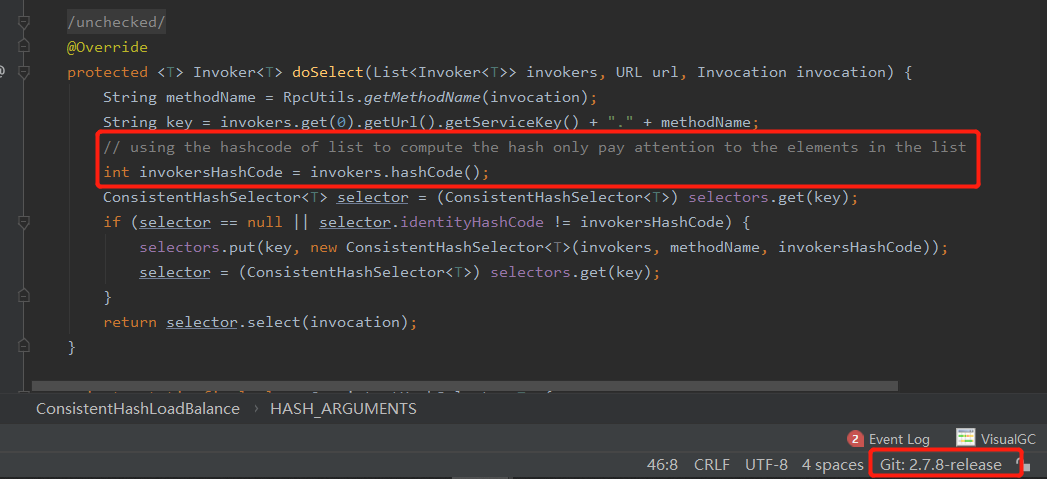
上面的原始碼是 2.7.8 版本。
假設有五個可用的服務提供者,這裡的 invokers 集合裡面裝的就是一個個服務提供者。
然後呼叫了 invokers ,也就是 list 的 hashCode 方法。
因為一致性雜湊的負載均衡的思想就是當服務發生了上下線之後,我們需要對雜湊環進行調整。
如果服務沒有發生上下線,那麼是不需要進行雜湊環調整的。
具體到這個 list 來說就是:
當 list 裡面的元素髮生了變化,那麼說明有服務上下線的情況發生。
至於你裝元素的 list 是否和原來的不一樣,那我是不關心的。
所以作者在這裡還寫了一個備註:我們應該只注意 list 裡面的元素就可以了。
言外之意就是我剛剛說的:裝元素的 list 是否發生了變化,我是不關心的。
按照開源框架的尿性,這地方專門寫了一行註釋,說明這個地方曾經是有問題的。
那我們看看這個地方的提交記錄:
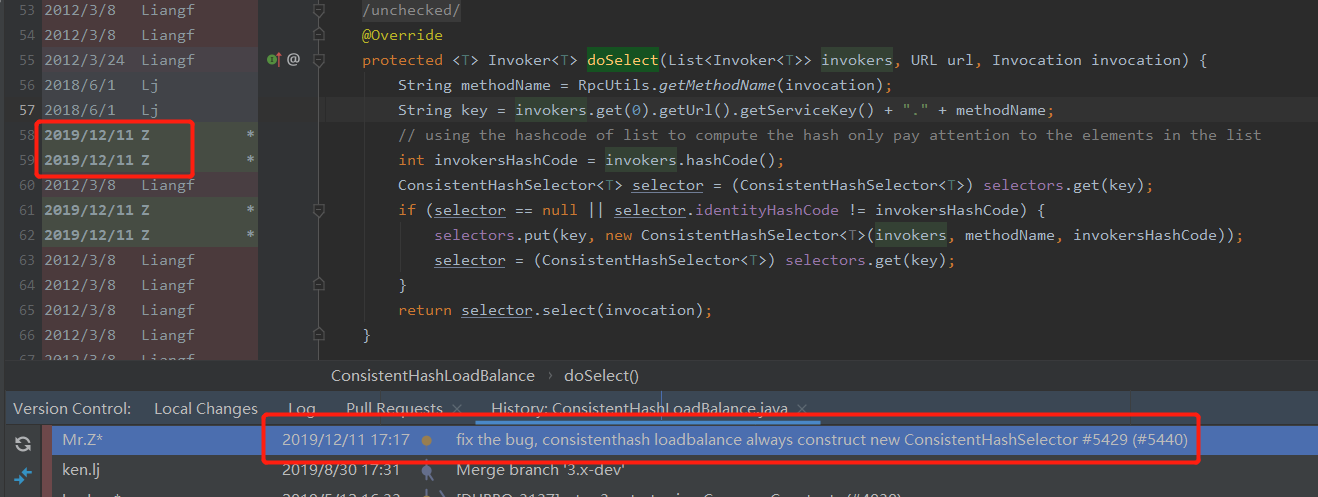
果然,在 2019 年 12 月 11 日,有人提交了程式碼。
提交的程式碼如下:
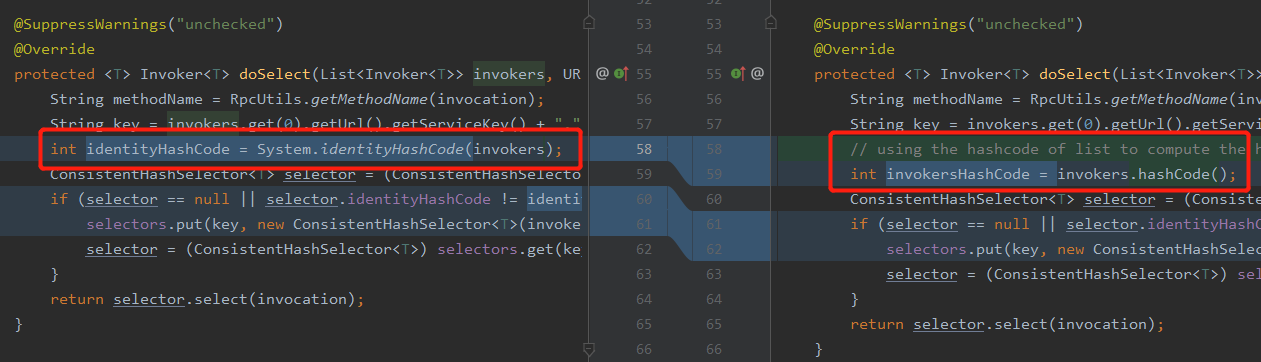
你看,原來的程式碼是 System.identityHashCode 方法。
後來修改為呼叫 list 的 hashCode 方法。
單單看著一行程式碼,我們就知道,之前的程式碼是關注 list 這個容器了,導致了某些 bug 的出現。
具體什麼原因,我們可以看看這次提交對應的 pr:
也就是編號為 5429 的 issue:
https://github.com/apache/dubbo/issues/5429
哎呀,我去,這誰啊?看著眼熟啊?這不就是 why 哥嗎?這不是巧了嗎,這不是?
是的,這個 bug 就是我發現並提出的對應的 issue。

而且這個 bug 其實是非常好發現的,只要你把環境一搭,程式碼一跑,場景一模擬。是個必現的問題。
而產生這個 bug 的原因,可謂是蝴蝶效應。在離這段原始碼很遠的,毫不相干的一次需求中,不知不覺的就影響到了這段程式碼。
而且連開發者自己都不知道,自己的修改會影響到一致性雜湊負載均衡演算法。所以,根本也就談不上什麼測試用例了。
如果你想更進一步瞭解這個 bug 的來龍去脈。可以看看這篇文章:
《夠強!一行程式碼就修復了我提的Dubbo的Bug》
如果你想更進一步的瞭解 Dubbo 的負載均衡策略,那可以看看這篇文章:
《吐血輸出:2萬字長文帶你細細盤點五種負載均衡策略。》
好了,那麼這次的文章就到這裡啦。給大家分享了一個冷門的、"學了沒多大卵用" 的 IdentityHashMap。
你要是不喜歡下面的荒腔走板環節的話,也請記得拉到文章的最後。留言、點贊、在看、轉發、讚賞,隨便來一個就行。你要是都安排上,我也不介意。
荒腔走板
最近專案組接到了一個工期特別緊張的專案。
所以剛剛過去的週末我加了兩天的班。週六晚上把流程走通之後,已經快是 22 點了。
之前預約了安裝家電的師傅,剛好也是週六。
所以只有女朋友一個人去家那邊,邊打掃衛生,邊等著安裝師傅。
安裝師傅全部弄好之後也是 19 點之後了。
因為我從公司到家特別的近。女朋友覺得我也差不多該下班了,於是決定就在家裡等我,然後一起從家裡回到租住的小區。
結果一等就是 2 個多小時。
我下班之後,馬上打車到小區。
下午沒有吃飯,工作也比較勞累,坐在車上,一陣疲倦的感覺襲來。
但是在小區門口刷門禁卡的時候,我一抬頭,門口寫著:歡迎回家。
那一刻,我突然覺得好暖啊,甚至還有一絲絲的感動。
走在小區的路上,感覺一切都是這麼的可愛。
因為這個家,真的是屬於自己的家,用自己一手一腳掙出來的錢堆出來的。
此時此刻,家裡還有一個人,開著燈,在等著我回家。
之前我從來沒有這樣的感覺過,這是一種非常神奇的感覺。
到家之後,由於傢俱還沒有準備好,我看到女朋友在地上鋪著一個泡沫墊子,坐在上面,靠在牆上,通過手機看著綜藝。
她起來抱了抱我,說:你終於回來啦。今天的事可真是多。
我們一起站在空蕩蕩的客廳中間。
那一刻,家的含義,家的感覺,從來沒有這麼具體過。
最後說一句(求關注)
才疏學淺,難免會有紕漏,如果你發現了錯誤的地方,可以在留言區提出來,我對其加以修改。 感謝您的閱讀,我堅持原創,十分歡迎並感謝您的關注。
我是 why,一個被程式碼耽誤的文學創作者,不是大佬,但是喜歡分享,是一個又暖又有料的四川好男人。
歡迎關注我呀。
