
記憶體分頁不就夠了?為什麼還要分段?還有段頁式?
阿新 • • 發佈:2021-01-04
你好,我是 yes。
關於記憶體訪問你可能聽過分段,分頁,還有段頁式。
但是為什麼要分段?又為什麼要分頁?
有了分頁為什麼還要分段?
這就需要看一看歷史的發展,知曉歷史之後就知道這一切其實都是自然而然的。
這些概念也不是硬塞出來的。
## 正文
1971 年 11 月 15 日,Intel 推出世界第一塊個人微型處理器 4004(4位處理器)。
隨後又推出了 8080(8 位處理器)。
那時候訪問記憶體就只有直白自然的想法,用具體實體地址。
**所有的記憶體訪問就是通過絕對實體地址去訪問的**,那時候還沒有段的概念。
段的概念是起源於 8086,這個 16 位處理器。
限於當時的技術背景和經濟,暫存器只有 16 位,而地址匯流排是 20 位。
那 16 的位的暫存器如何能訪問 20 位的地址?
2 的16 次方如果直著來如何能訪問到 2 的 20 次方所表達的數?
直著來是不可能的,因此就需要操作一下。
也就是引入段的概念,讓 CPU 通過**「段基地址+段內偏移」**來訪問記憶體。
有人可能就問你這都只有 16 位,兩個 16 位加起來最多隻能表示 17 位呀。
你說的沒錯。
所以再具體一點的計算規則其實是:段基地址左移 4 位(就是乘16)再加上段內偏移,這樣得到的就是 20 位的地址。
比如現在的要訪問的記憶體地址是0x05808,那麼段基地址可以是 0x0580,偏移量就是 0x0008。
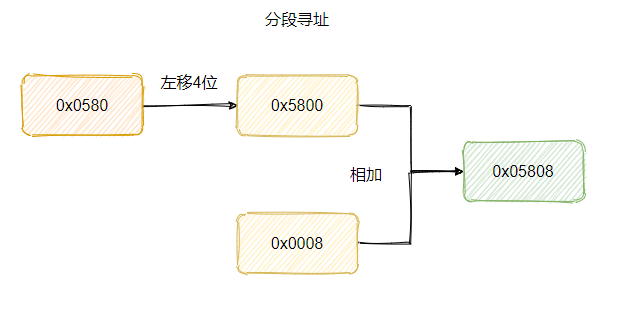
這樣記憶體的定址空間就擴大到 20 位了。
至於為什麼稱之為段,其實就是因為暫存器只有 16 位一段只能訪問 64 KB,所以需要移動基地址,一段一段的去訪問所有的記憶體空間。
對了,專門為分段而生的暫存器為段暫存器,當時裡面直接存放段基地址。
不過漸漸地人們就考慮到安全問題,因為在這個時候程式之間的地址沒有隔離,我的程式可以訪問你的程式地址,這就很不安全。
於是在 1982 年 80286 推出時,就有了保護模式。

其實就是 CPU 在訪問地址的時候做了約束,會判斷地址是否在允許的範圍內,會判斷當前的程式對目的地址是否有訪問許可權。
搞了個 GDT (全域性描述符表)存放所有段描述符。

段暫存器裡面也不是直接放段基地址了,而是放了一個叫**選擇子**的東西。
大致可以認為就是段描述符的索引,也就是通過這個索引去找到段描述符,所以叫選擇子。
這個選擇子裡面還有一點屬性。

這個 T1 就是標明要去哪個表找,而 RPL 就是特權級了,一共分為四層,0 為最高特權級,3 為最低特權級。
當地址訪問時,如果 RPL 的許可權低於目標特權級(DPL)時,就會拒絕訪問,於是就起到了保護的作用。
所以稱之為**保護模式**,之前的那種沒有判斷許可權的稱之為**真實模式。**
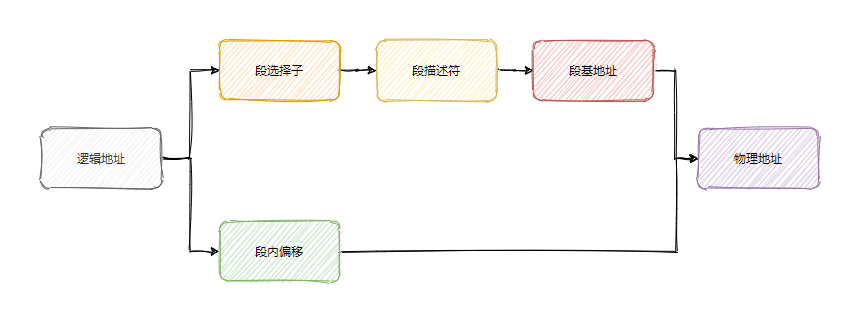
當時 80286 的地址匯流排已經是 24 位,但是用於定址的通用暫存器還是 16 位,雖然段基地址的位數已經足夠訪問到 24 位(因為已經放到 GDT 中,且有 24位)。
但是因每次一段只有 64 KB,這樣訪問就很不方便,需要不斷的更換段基地址,於是 80286 很快就被淘汰,換上了 80386。
這是 Intel 第一代 32 位處理器。

除了段暫存器還是 16 位之外,地址匯流排和暫存器都是 32 位,這就意味著以前為了定址搞的段機制其實沒用了。
因為單單段內偏移就可以訪問到 4GB 空間,但是為了**向前相容**段機制還是保留了下來,段暫存器還是 16 位是因為夠用了,所以沒必要擴充。
不過上有政策,下有對策。
雖說段機制保留了,但是咱可以“忽悠”著用,把段基值都設定為 0 ,就用段內偏移地址來訪問記憶體空間就好了。
這其實就意味著每個段的起始地址都是一樣的,那就等於不分段了,這就叫**平坦模式**。
Linux 就是這樣實現的。
## 那為什麼要分頁?
因為分段粒度太粗了,導致記憶體碎片大,不利於管理。
當時載入到記憶體等於一個段都得搞到記憶體中,而段的範圍過大,舉個例子。
假設此時你有 200M 記憶體,此時有 3 個應用在執行,分別是 LOL、chrome、微信。

此時記憶體中明明有 30MB 的空閒,但是網易雲載入不進來,這記憶體碎片就有點大了。
然後就得把 chrome 先換到磁碟中,然後再讓 chrome 載入進來到微信的後面,這樣空閒的 30MB 就連續了,於是網易雲就能載入到記憶體中了。
但是這樣等於要把 50MB 的記憶體來個反覆橫跳,磁碟的訪問太慢了,所以效率就很低。
總體而言可以認為分段記憶體的管理粒度太粗了,所以隨著 80386 就出來了個分頁管理,一個更加精細化的記憶體管理方式。
簡單地說就是把記憶體等分成一頁一頁,**每頁 4KB 大小,按頁為單位來管理記憶體。**
你看按一頁一頁來管理這樣就不用把一段程式都載入進記憶體,只需要將用到的頁載入進記憶體。
這樣記憶體的利用率就更高了,能同時執行的程式就更多了。
並且由於一頁就 4KB, 所以記憶體交換的效能問題得以緩解,畢竟只要換一定的頁,而不需要整個段都換到磁碟中。
對應的還有個**虛擬記憶體**的概念。
分頁機制構造了一個虛擬記憶體空間,讓每個程序誤以為自己掌控所有的記憶體。

再具體一點就是每個程序都有一個頁表,頁表中有物理頁號和屬性,這樣定址的時候通過頁表就能利用虛擬地址找到對應的實體地址。
屬性用來做許可權的一些管理。

就理解為程序想要記憶體中的任意一個地址都行,沒問題,反正背地裡偷偷的會換成可以用的實體記憶體地址。
如果實體記憶體滿了也沒事,把不常用的記憶體頁先換到磁碟中,即 swap,騰出空間來就好了,到時候要用再換到記憶體中。
上面提到的虛擬地址也叫線性地址,簡單地說就是通過繞不開的段機制得到線性地址,然後再通過分頁機制轉化得到實體地址。
## 最後
至此我們已經知曉了為什麼有分段,又有分頁,還有段頁式。
一開始限於技術和成本所以暫存器的位數不夠,因此為了擴大定址範圍搞了個分段訪問記憶體。
而隨後技術起來了,位數都擴充了,暫存器其實已經可以訪問全部記憶體空間了,所以分段已經沒用了。
但是為了向前相容還是保留著分段訪問的形式,並且隨著軟體的發展,同時執行各種程序的需求越發強烈。
為了更好的管理記憶體,提高記憶體的利用率和記憶體互動效能引入了分頁管理。
所以就變成了先分段,然後再分頁的段頁式。
當然也可以和 Linux 那樣讓每一段的基地址都設為 0 ,這樣就等於“繞開”了段機制。
至此今天的內容就差不多了,這篇文章沒有深入具體的分段和分頁的細節,之後再作一篇文章來闡述細節。
個人能力有限,如有錯誤請指正,也歡迎關注我的個人公眾號,文章首發公眾號。

> 更多文章可看我的文章彙總:[https://github.com/yessimida/yes](https://github.com/yessimida/yes) 歡迎 star !
---
**我是 yes,從一點點到億點點,歡迎在看、轉發、留言,我們下篇