
Nebula Exchange 工具 Hive 資料匯入的踩坑之旅
阿新 • • 發佈:2021-01-11

摘要:本文由社群使用者 xrfinbj 貢獻,主要介紹 Exchange 工具從 Hive 數倉匯入資料到 Nebula Graph 的流程及相關的注意事項。
## 1 背景
公司內部有使用圖資料庫的場景,內部通過技術選型確定了 Nebula Graph 圖資料庫,還需要驗證 Nebula Graph 資料庫在實際業務場景下的查詢效能。所以急迫的需要匯入資料到 Nebula Graph 並驗證。在這個過程中發現通過 Exchange 工具從 hive 數倉匯入資料到 Nebula Graph 文件不是很全,所以把這個流程中踩到的坑記錄下來,回饋社群,避免後人走彎路。
本文主要基於我之前發在論壇的 2 篇帖子:
- [exchange 如何匯入 hive 資料問題](https://discuss.nebula-graph.com.cn/t/topic/1773)
- [exchange 執行從 hive 匯入資料報錯](https://discuss.nebula-graph.com.cn/t/topic/1759)
## 2 環境資訊
- Nebula Graph 版本:nebula:nightly
- 部署方式(分散式 / 單機 / Docker / DBaaS):Mac 電腦 Docker 部署
- 硬體資訊
- 磁碟(SSD / HDD):Mac 電腦 SSD
- CPU、記憶體資訊:16 G
- 數倉環境(Mac 電腦搭建的本地數倉):
- Hive 3.1.2
- Hadoop 3.2.1
- Exchange 工具:[https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/exchange](https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/exchange)
編譯後生成 jar 包
- Spark
spark-2.4.7-bin-hadoop2.7 (conf 目錄下配置 Hadoop 3.2.1 對應的 core-site.xml,hdfs-site.xml,hive-site.xml 設定 spark-env.sh)
Scala code runner version 2.13.3 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
### 3 配置
### 1 Nebula Graph DDL
```
CREATE SPACE test_hive(partition_num=10, replica_factor=1); --建立圖空間,本示例中假設只需要一個副本
USE test_hive; --選擇圖空間 test
CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double); -- 建立標籤 tagA
CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double); -- 建立標籤 tagB
CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double); -- 建立邊型別 edgeAB
```
### 2 Hive DDL
```
CREATE TABLE `tagA`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagA select 1,1,'str1',true,11.11;
insert into tagA select 2,2,"str2",false,22.22;
CREATE TABLE `tagB`(
`id` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into tagB select 3,3,"str 3",true,33.33;
insert into tagB select 4,4,"str 4",false,44.44;
CREATE TABLE `edgeAB`(
`id_source` bigint,
`id_dst` bigint,
`idInt` int,
`idString` string,
`tboolean` boolean,
`tdouble` double) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' LINES TERMINATED BY '\n';
insert into edgeAB select 1,3,5,"edge 1",true,55.55;
insert into edgeAB select 2,4,6,"edge 2",false,66.66;
```
### 3 我的最新 nebula_application.conf 檔案
注意看exec、fields、nebula.fields、vertex、source、target欄位對映
```
{
# Spark relation config
spark: {
app: {
name: Spark Writer
}
driver: {
cores: 1
maxResultSize: 1G
}
cores {
max: 4
}
}
# Nebula Graph relation config
nebula: {
address:{
graph: ["192.168.1.110:3699"]
meta: ["192.168.1.110:45500"]
}
user: user
pswd: password
space: test_hive
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/error
}
rate: {
limit: 1024
timeout: 1000
}
}
# Processing tags
tags: [
# Loading from Hive
{
name: tagA
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.taga"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 10
}
{
name: tagB
type: {
source: hive
sink: client
}
exec: "select id,idint,idstring,tboolean,tdouble from nebula.tagb"
fields: [id,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
vertex: id
batch: 256
partition: 10
}
]
# Processing edges
edges: [
# Loading from Hive
{
name: edgeAB
type: {
source: hive
sink: client
}
exec: "select id_source,id_dst,idint,idstring,tboolean,tdouble from nebula.edgeab"
fields: [id_source,idstring,tboolean,tdouble]
nebula.fields: [idInt,idString,tboolean,tdouble]
source: id_source
target: id_dst
batch: 256
partition: 10
}
]
}
```
## 4 執行匯入
### 4.1 確保 nebula 服務啟動
### 4.2 確保 Hive 表和資料就緒
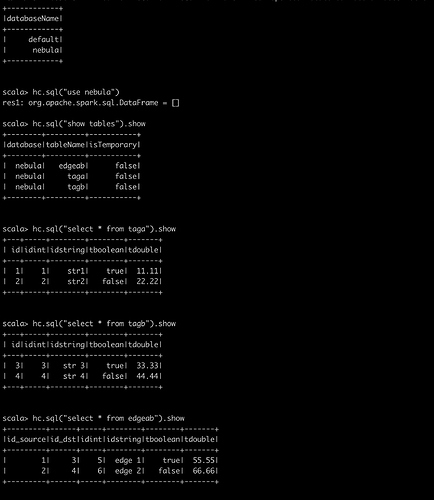
### 4.3 執行 spark-sql cli 檢視 Hive 表以及資料是否正常以確保 Spark 環境沒問題
### 4.4 一切配置工作就緒後,執行 Spark 命令:
```
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master “local[4]” /xxx/exchange-1.0.1.jar -c /xxx/nebula_application.conf -h
```
### 4.5 匯入成功後 可以藉助 db_dump 工具檢視匯入資料量 驗證正確性
```
./db_dump --mode=stat --space=xxx --db_path=/home/xxx/data/storage0/nebula --limit 20000000
```
## 5 踩坑以及說明
- 第一個坑就是 spark-submit 命令沒有加 -h 引數
- Nebula Graph 中 tagName 是大小寫敏感的,tags 的配置中 name 配置的應該是 Nebula Graph 的 tag 名
- Hive的 int 和 Nebula Graph 的 int 不一致,Hive 裡面的 bigint 對應 Nebula Graph 的 int
### 其他說明:
- 由於 Nebula Graph 底層儲存是 kv,重複插入其實是覆蓋,update 操作用 insert 替代效能會高些
- 文件裡面不全的地方可能暫時只有一邊看原始碼解決,一邊去論壇問(開發同學也不容易又要緊張的開發又要回答使用者的疑問)
- 匯入資料、Compact 以及操作建議:[https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact/](https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/5.storage-service-administration/compact/)
- 我已經驗證如下兩個場景:
- 用 Spark 2.4 從 Hive 2(Hadoop 2)中匯入資料到 Nebula Graph
- 用 Spark 2.4 從 Hive3(Hadoop 3)中匯入資料到 Nebula Graph
說明:Exchange 目前還不支援 Spark 3,編譯後執行報錯,所以沒法驗證 Spark 3 環境
### 還有一些疑問
- nebula_application.conf 檔案的引數 batch 和 rate.limit 應該如何設定?引數如何抉擇?
- Exchange 工具 Hive 資料匯入原理(Spark 這塊我也是最近現學現用)
## 6 Exchange 原始碼 Debug
Spark Debug 部分參考部落格:[https://dzone.com/articles/how-to-attach-a-debugger-to-apache-spark](https://dzone.com/articles/how-to-attach-a-debugger-to-apache-spark)
通過 Exchange 原始碼的學習和 Debug 能加深對 Exchange 原理的理解,同時也能發現一些文件描述不清晰的地方,比如 [匯入 SST 檔案](https://docs.nebula-graph.com.cn/nebula-exchange/use-exchange/ex-ug-import-sst/) 和 [Download and Ingest](https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/5.storage-service-administration/data-import/download-and-ingest-sst-file/ ) 只有結合原始碼看才能發現文件描述不清晰邏輯不嚴謹的問題。
通過原始碼 Debug 也能發現一些簡單的引數配置問題。
進入正題:
步驟一:
```
export SPARK_SUBMIT_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=4000
```
步驟二:
```
spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master “local” /xxx/exchange-1.1.0.jar -c /xxx/nebula_application.conf -h
Listening for transport dt_socket at address: 4000
```
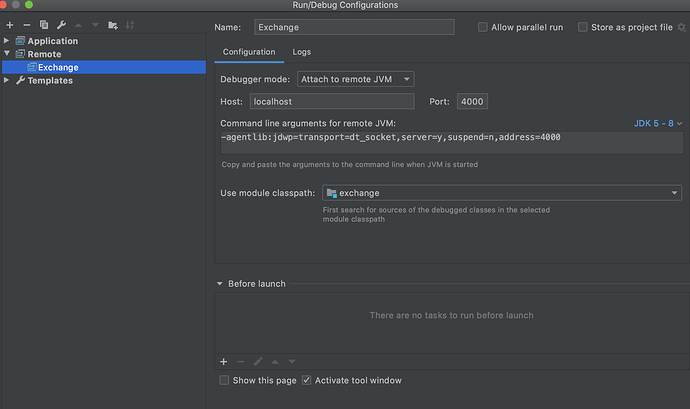
步驟三:IDEA 配置
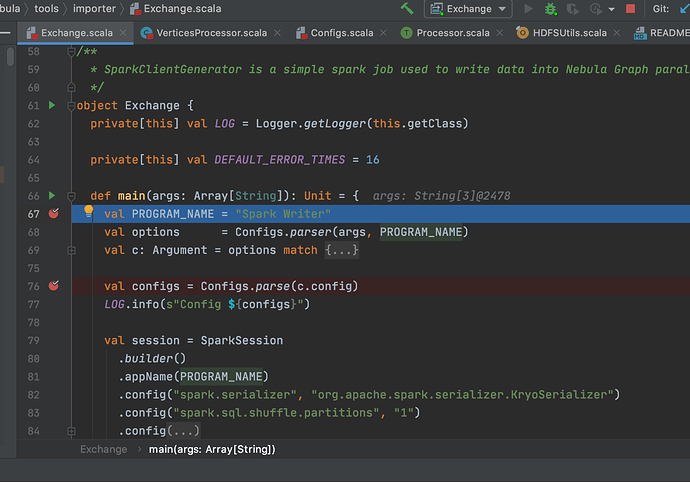
步驟四:在 IDEA 裡面點選 Debug
## 7 建議與感謝
感謝 vesoft 提供了宇宙效能最強的 Nebula Graph 圖資料庫,能解決業務中很多實際問題,中途這點痛不算什麼(看之前的分享,360 數科他們那個痛才是真痛)。中途遇到的問題都有幸得到社群及時的反饋解答,再次感謝
**很期待 Exchange 支援 Nebula Graph 2.0**
## 參考資料
- [exchange和Spark Writer什麼關係?](https://discuss.nebula-graph.com.cn/t/topic/1721)
- [Spark Writer 手冊](https://docs.nebula-graph.com.cn/manual-CN/3.build-develop-and-administration/5.storage-service-administration/data-import/spark-writer/)
- [Spark Writer 手冊](https://docs.nebula-graph.com.cn/nebula-exchange/about-exchange/ex-ug-what-is-exchange/)
喜歡這篇文章?來來來,給我們的 [GitHub](https://github.com/vesoft-inc/nebula) 點個 star 表鼓勵啦~~