
Hadoop企業開發場景案例,虛擬機器伺服器調優
阿新 • • 發佈:2021-03-17
## Hadoop企業開發場景案例
### 1 案例需求
(1)需求:從1G資料中,統計每個單詞出現次數。伺服器3臺,每臺配置4G記憶體,4核CPU,4執行緒。
(2)需求分析:
1G/128m = 8個MapTask;1個ReduceTask:1個mrAppMaster
平均每個節點執行10個/3臺 ≈ 3個任務(4 3 3)
### 2 HDFS引數調優
(1)修改:hadoop-env.sh
``` shell
export HDFS_NAMENODE_OPTS = "-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS = "-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
```
(2)修改:hdfs-site.xml
```shell
```
(3)修改core-site.xml
```shell
```
(4)將配置分發到三臺伺服器上
``` shell
rsync -av 分發的檔名稱 使用者名稱@主機名稱:儲存配置檔案地址
```
### 3 MapReduce 引數調優
(1)修改mapred-site.xml
``` shell
```
(2)伺服器分發配置檔案
```shell
rsync -av 分發的檔名稱 使用者名稱@主機名稱:儲存配置檔案地址
```
### 4 Yarn引數調優
(1)修改Yarn-site.xml
```shell
```
(2)伺服器分發配置檔案
```shell
rsync -av 分發的檔名稱 使用者名稱@主機名稱:儲存配置檔案地址
```
### 10.3.5 執行程式
(1)重啟叢集
```shell
sbin/stop-yarn.sh
sbin/start-yarn.sh
```
(2)執行 WordCount 程式
```shell
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
```
說明:在hadoop資料夾下執行命令,/input 為要統計的 1G 資料所在的資料夾目錄,/output 為要輸出統計結果的資料夾目錄。
(3)觀察 Yarn 任務執行頁面
網址:hadoop103:8088
(4)執行結果
/wcinput/work.txt原內容:
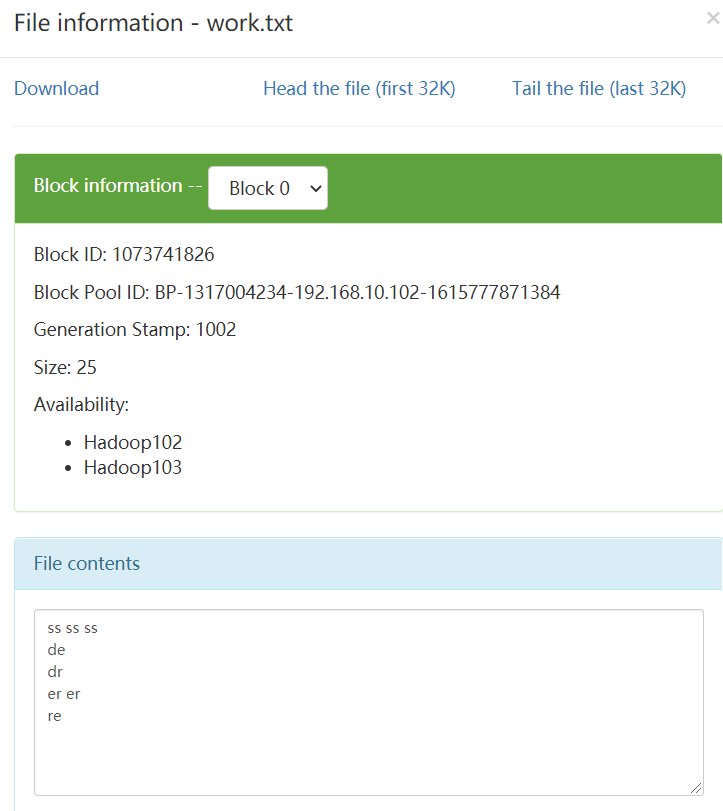
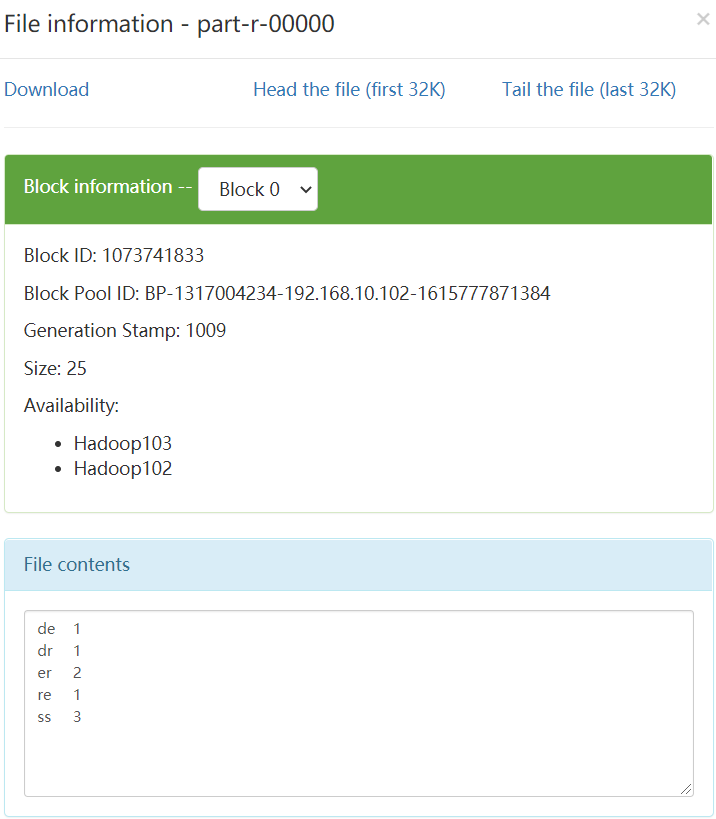
執行結果:生成資料夾/wcoutput
##### 加入QQ群:947117563,一起加入小猿森林吧!!群裡可以摘果實