
python基礎: 深入理解 python 中的賦值、引用、拷貝、作用域
文章轉載自python基礎(5):深入理解 python 中的賦值、引用、拷貝、作用域
python的賦值
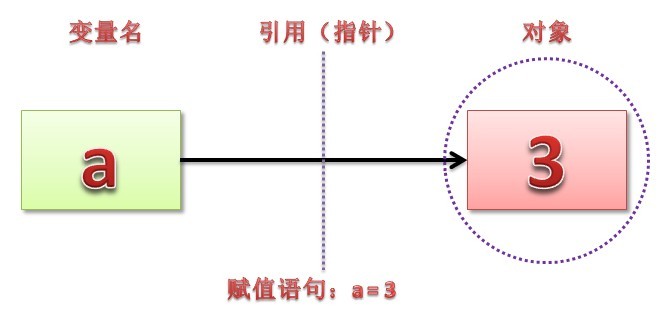
在 python 中賦值語句總是建立物件的引用值,而不是複製物件。因此,python 變數更像是指標,而不是資料儲存區域,
這點和大多數 OO 語言類似吧,比如 C++、java 等 ~
{kind=link}
先來看個問題吧:
一個賦值問題
在Python中,令values=[0,1,2];values[1]=values,為何結果是[0,[...],2]?連結
1
|
|
可以說 Python 沒有賦值,只有引用。你這樣相當於建立了一個引用自身的結構,所以導致了無限迴圈。為了理解這個問題,有個基本概念需要搞清楚。
Python 沒有「變數」,我們平時所說的變數其實只是「標籤」,是引用。
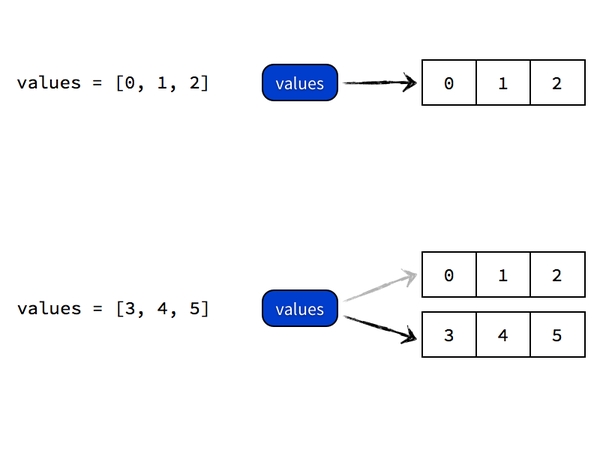
執行values = [0, 1, 2]的時候,Python 做的事情是首先建立一個列表物件 [0, 1, 2],然後給它貼上名為 values 的標籤。
如果隨後又執行values = [3, 4, 5]的話,Python 做的事情是建立另一個列表物件 [3, 4, 5],然後把剛才那張名為 values 的標籤從前面的 [0, 1, 2] 物件上撕下來,重新貼到 [3, 4, 5] 這個物件上。
至始至終,並沒有一個叫做 values 的列表物件容器存在,Python 也沒有把任何物件的值複製進 values 去。過程如圖所示:
{kind=link}
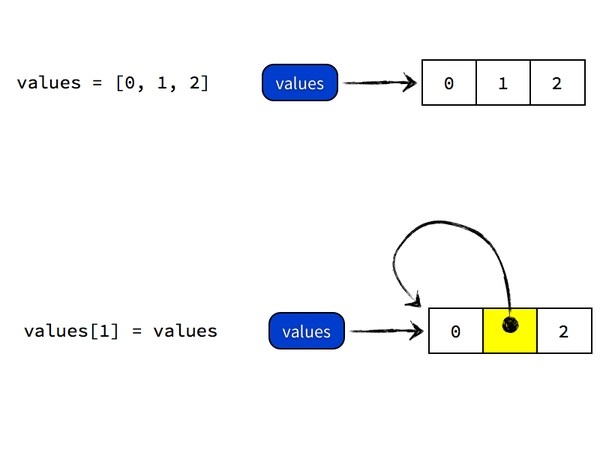
執行values[1] = values的時候,Python 做的事情則是把 values 這個標籤所引用的列表物件的第二個元素指向 values 所引用的列表物件本身。執行完畢後,values 標籤還是指向原來那個物件,只不過那個物件的結構發生了變化,從之前的列表 [0, 1, 2] 變成了 [0, ?, 2],而這個 ? 則是指向那個物件本身的一個引用。如圖所示:
{kind=link}
淺複製及其風險
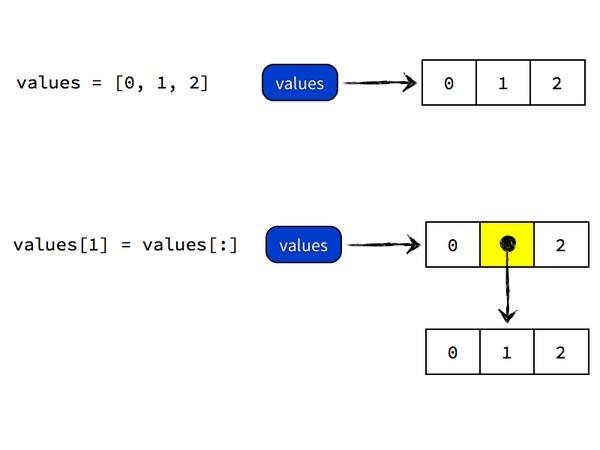
要達到你所需要的效果,即得到 [0, [0, 1, 2], 2] 這個物件,你不能直接將 values[1] 指向 values 引用的物件本身,而是需要吧 [0, 1, 2] 這個物件「複製」一遍,得到一個新物件,再將 values[1] 指向這個複製後的物件。Python 裡面複製物件的操作因物件型別而異,複製列表 values 的操作是
1
|
values[:] #生成物件的拷貝或者是複製序列,不再是引用和共享變數,但此法只能頂層複製
|
所以你需要執行values[1] = values[:]
Python 做的事情是,先 dereference 得到 values 所指向的物件 [0, 1, 2],然後執行 [0, 1, 2][:] 複製操作得到一個新的物件,內容也是 [0, 1, 2],然後將 values 所指向的列表物件的第二個元素指向這個複製二來的列表物件,最終 values 指向的物件是 [0, [0, 1, 2], 2]。過程如圖所示:
{kind=link}
往更深處說,values[:] 複製操作是所謂的「淺複製」(shallow copy),當列表物件有巢狀的時候也會產生出乎意料的錯誤,比如為何要賦值無限次
1
|
a = [0, [1, 2], 3]
|
問:此時 a 和 b 分別是多少?
正確答案是 a 為 [8, [1, 9], 3],b 為 [0, [1, 9], 3]。發現沒?b 的第二個元素也被改變了。想想是為什麼?不明白的話看下圖
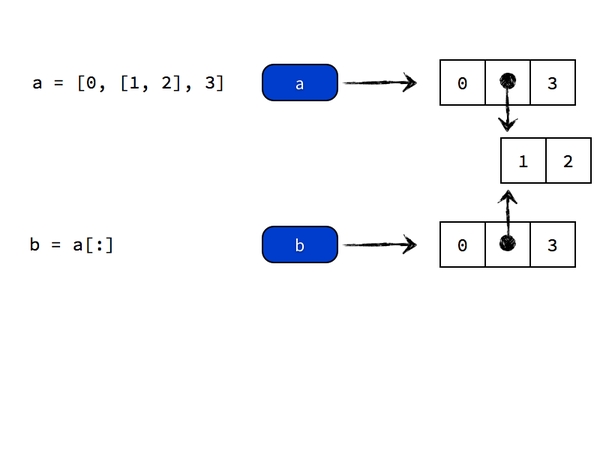{kind=link}
深複製
正確的複製巢狀元素的方法是進行「深複製」(deep copy),方法是
1
|
import copy
|
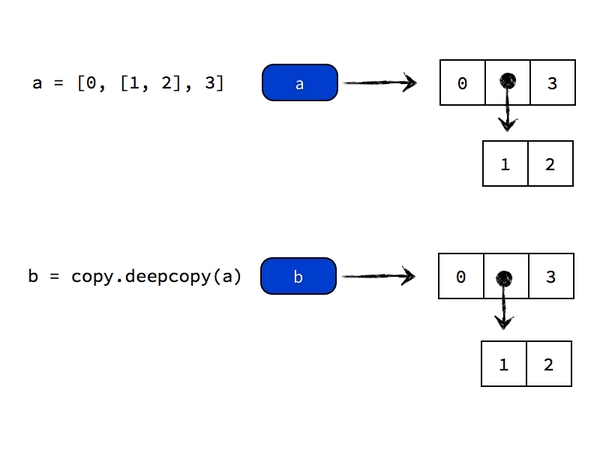{kind=link}
引用 VS 拷貝:
- 沒有限制條件的分片表示式(L[:])能夠複製序列,但此法只能淺層複製。
- 字典 copy 方法,D.copy() 能夠複製字典,但此法只能淺層複製
- 有些內建函式,例如 list,能夠生成拷貝 list(L)
- copy 標準庫模組能夠生成完整拷貝:deepcopy 本質上是遞迴 copy
- 對於不可變物件和可變物件來說,淺複製都是複製的引用,只是因為複製不變物件和複製不變物件的引用是等效的(因為物件不可變,當改變時會新建物件重新賦值)。所以看起來淺複製只複製不可變物件(整數,實數,字串等),對於可變物件,淺複製其實是建立了一個對於該物件的引用,也就是說只是給同一個物件貼上了另一個標籤而已。
1
|
L = [1, 2, 3]
|
增強賦值以及共享引用:
x = x + y,x 出現兩次,必須執行兩次,效能不好,合併必須新建物件 x,然後複製兩個列表合併
屬於複製/拷貝
x += y,x 只出現一次,也只會計算一次,效能好,不生成新物件,只在記憶體塊末尾增加元素。
當 x、y 為list時, += 會自動呼叫 extend 方法進行合併運算,in-place change。
屬於共享引用
1
|
L = [1, 2]
|
python 從 2k 到 3k,語句變函式引發的變數作用域問題
先看段程式碼:
1
|
def test():
|
在 python 2k 和 3k 下 你會發現他們的結果不一樣:
1
|
2K:
|
這是為什麼呢?
因為 3k 中 exec 由語句變成函數了,而在函式中變數預設都是區域性的,也就是說
你所見到的兩個 a,是兩個不同的變數,分別處於不同的名稱空間中,而不會衝突。
具體參考 《learning python》P331-P332
知道原因了,我們可以這麼改改:
1
|
def test():
|
這是一個典型的 python 2k 移植到 3k 不相容的案例,類似的還有很多,也算是移植的坑吧~
具體的 2k 與 3k 有哪些差異可以看這裡:使用 2to3 將程式碼移植到 Python 3
深入理解 python 變數作用域及其陷阱
可變物件 & 不可變物件
- 在Python中,物件分為兩種:可變物件和不可變物件,
- 不可變物件包括int,float,long,str,tuple等,可變物件包括list,set,dict等。
- 需要注意的是:這裡說的不可變指的是值的不可變。對於不可變型別的變數,如果要更改變數,則會建立一個新值,把變數繫結到新值上,而舊值如果沒有被引用就等待垃圾回收。另外,不可變的型別可以計算hash值,作為字典的key。
- 可變型別資料對物件操作的時候,不需要再在其他地方申請記憶體,只需要在此物件後面連續申請(+/-)即可,也就是它的記憶體地址會保持不變,但區域會變長或者變短。
1
|
|
函式值傳遞
1
|
def func_int(a):
|
對於上面的輸出,不少Python初學者都比較疑惑:第一個例子看起來像是傳值,而第二個例子確實傳引用。其實,解釋這個問題也非常容易,主要是因為可變物件和不可變物件的原因:對於可變物件,物件的操作不會重建物件,而對於不可變物件,每一次操作就重建新的物件。
在函式引數傳遞的時候,Python其實就是把引數裡傳入的變數對應的物件的引用依次賦值給對應的函式內部變數。參照上面的例子來說明更容易理解,func_int中的區域性變數”a”其實是全部變數”t”所指向物件的另一個引用,由於整數物件是不可變的,所以當func_int對變數”a”進行修改的時候,實際上是將區域性變數”a”指向到了整數物件”1”。所以很明顯,func_list修改的是一個可變的物件,區域性變數”a”和全域性變數”t_list”指向的還是同一個物件。
為什麼修改全域性的dict變數不用global關鍵字
為什麼修改字典d的值不用global關鍵字先宣告呢?
1
|
s = 'foo'
|
這是因為,在s = ‘bar’這句中,它是“有歧義的“,因為它既可以是表示引用全域性變數s,也可以是建立一個新的區域性變數,所以在python中,預設它的行為是建立區域性變數,除非顯式宣告global,global定義的本地變數會變成其對應全域性變數的一個別名,即是同一個變數。
在d[‘b’]=2這句中,它是“明確的”,因為如果把d當作是區域性變數的話,它會報KeyError,所以它只能是引用全域性的d,故不需要多此一舉顯式宣告global。
上面這兩句賦值語句其實是不同的行為,一個是rebinding(不可變物件), 一個是mutation(可變物件).
但是如果是下面這樣:
1
|
d = {'a':1}
|
在d = {}這句,它是”有歧義的“了,所以它是建立了局部變數d,而不是引用全域性變數d,所以d[‘b’]=2也是操作的區域性變數。
推而遠之,這一切現象的本質就是”它是否是明確的“。
仔細想想,就會發現不止dict不需要global,所有”明確的“東西都不需要global。因為int型別str型別之類的不可變物件,每一次操作就重建新的物件,他們只有一種修改方法,即x = y, 恰好這種修改方法同時也是建立變數的方法,所以產生了歧義,不知道是要修改還是建立。而dict/list/物件等可變物件,操作不會重建物件,可以通過dict[‘x’]=y或list.append()之類的來修改,跟建立變數不衝突,不產生歧義,所以都不用顯式global。
可變物件 list 的 = 和 append/extend 差別在哪?
接上面 5.3 的理論,下面咱們再看一例常見的錯誤:
1
|
# coding=utf-8
|
大家可以看到為什麼 語句1 不能改變 list_a 的值,而 語句2 卻可以?他們的差別在哪呢?
因為 = 建立了局部變數,而 .append() 或者 .extend() 重用了全域性變數。
陷阱:使用可變的預設引數
我多次見到過如下的程式碼:
1
|
def foo(a, b, c=[]):
|
永遠不要使用可變的預設引數,可以使用如下的程式碼代替:
1
|
def foo(a, b, c=None):
|
與其解釋這個問題是什麼,不如展示下使用可變預設引數的影響:
1
|
In[2]: def foo(a, b, c=[]):
|
同一個變數c在函式呼叫的每一次都被反覆引用。這可能有一些意想不到的後果。