
爬取英雄聯盟所有英雄面板
阿新 • • 發佈:2020-12-24
{kind=link}
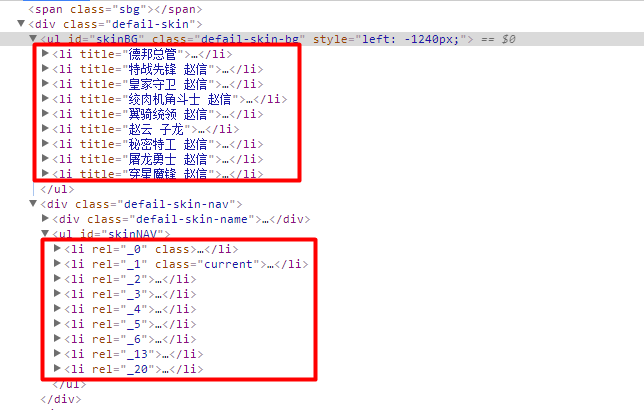
這裡有兩種型別的同樣的圖片,一種是大圖片的,一種是類似頭像的小圖片。我們這裡抓取大圖片
拿到幾種圖片連結分析https://game.gtimg.cn/images/lol/act/img/skin/big5000.jpg可以發現所有英雄面板連結url除了數字之前的都一樣,而且後面的數字都是以英雄id+三位數拼接而成(三位數從000開始,但是有的英雄並不是就是依次排列,可能000,,001,002會直接跳到013)
由於英雄聯盟官網也是做了反爬措施了的,所有圖片也是使用區域性載入的方式,在開發者工作中,可以找到一個js檔案,裡面包含了英雄id與英雄的對應關係
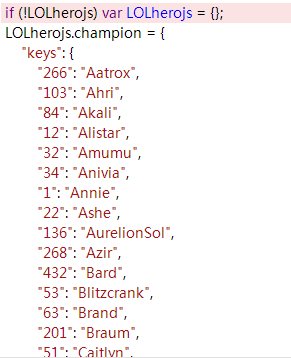{kind=link}
通過請求該js,獲取其原始碼,使用正則表示式將其提取出來,用於後面的url拼接
程式碼如下:
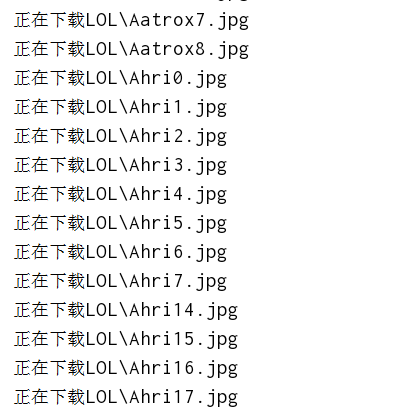
import requests import re import json # 請求js資料,獲取英雄對應的程式碼 # "92": "Riven", # "68": "Rumble", # "13": "Ryze", # "113": "Sejuani", def path_js(url): # 通過js原始碼,獲取位元組資料 response = requests.get(url).content.decode('gb2312') req = '"keys":(.*?),"data"' #將字串轉成正則物件 # req = re.compile(req) list_js = re.findall(req,response) dict_js = json.loads(list_js[0]) # print(dict_js) # print(len(dict_js)) return dict_js 'https://game.gtimg.cn/images/lol/act/img/skin/big21003.jpg' # LOL 面板連結除了前面的https://game.gtimg.cn/images/lol/act/img/skin/big都一樣外,後面的數字採用# 英雄的程式碼+三位數(從000開始,但是中間可能會跳,如001,002,003,012,013...) # 拼接圖片url def path_url(dict_js): list_pic = [] for key in dict_js: # 假設後面的數字到25,後面通過url訪問是否成功判斷是否有效 for item in range(25): item = str(item) # item一位數拼接兩個0 if len(item) == 1: hero_item = '00' + item # item一位數拼接一個0 elif len(item) == 2: hero_item = '0' + item # 拼接完整數字 numbers_str = key + hero_item # print(numbers_str) # 拼接完整圖片url url = 'https://game.gtimg.cn/images/lol/act/img/skin/big' + numbers_str + '.jpg' # 將所有拼接的圖片url儲存至列表 list_pic.append(url) return list_pic # 拼接圖片名稱 def name_pic(dict_js,path): list_file_path = [] for name in dict_js.values(): for item in range(25): file_path = path + name + str(item) + '.jpg' list_file_path.append(file_path) return list_file_path # 儲存圖片 def save_pic(list_pic,list_file_path): for item in range(len(list_pic)): res = requests.get(list_pic[item]) if res.status_code == 200: print('正在下載%s'%list_file_path[item]) with open(list_file_path[item],'wb')as fp: fp.write(res.content) print('所有面板全部下載完畢!') if __name__ == '__main__': url = 'https://lol.qq.com/biz/hero/champion.js' path = './/' # 獲取英雄對應id,返回字典資料 dict_js = path_js(url) # 拼接完整的圖片url,返回列表資料 list_pic = path_url(dict_js) # 拼接完整的圖片儲存路徑,返回列表資料 list_file_path = name_pic(dict_js,path) # 根據圖片url列表和路徑列表,儲存圖片 save_pic(list_pic,list_file_path)
{kind=link}