
MySQL 行鎖等待超時問題
一、背景
#### 20191219 10:10:10,234 | com.alibaba.druid.filter.logging.Log4jFilter.statementLogError(Log4jFilter.java:152) | ERROR | {conn-10593, pstmt-38675} execute error. update operation_service set offlinemark = ? , resourcestatus = ? where RowGuid = ?
com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction上述這個錯誤,接觸 MySQL 的同學或多或少應該都遇到過,專業一點來說,這個報錯我們稱之為鎖等待超時。 根據鎖的型別主要細分為:
-
行鎖等待超時
當 SQL 因為等待行鎖而超時,那麼就為行鎖等待超時,常在多併發事務場景下出現。
-
元資料鎖等待超時
當 SQL 因為等待元資料鎖而超時,那麼就為元資料鎖等待超時,常在 DDL 操作期間出現。
本文僅介紹如何有效解決行鎖等待超時,因為大多數專案都是此類錯誤,元資料鎖等待超時則不涉及講解。
二、行鎖的等待
在介紹如何解決行鎖等待問題前,先簡單介紹下這類問題產生的原因。
產生原因簡述:當多個事務同時去操作(增刪改)某一行資料的時候,MySQL 為了維護 ACID 特性,就會用鎖的形式來防止多個事務同時操作某一行資料,避免資料不一致。只有分配到行鎖的事務才有權力操作該資料行,直到該事務結束,才釋放行鎖,而其他沒有分配到行鎖的事務就會產生行鎖等待。如果等待時間超過了配置值(也就是 innodb_lock_wait_timeout 引數的值,個人習慣配置成 5s,MySQL 官方預設為 50s),則會丟擲行鎖等待超時錯誤。
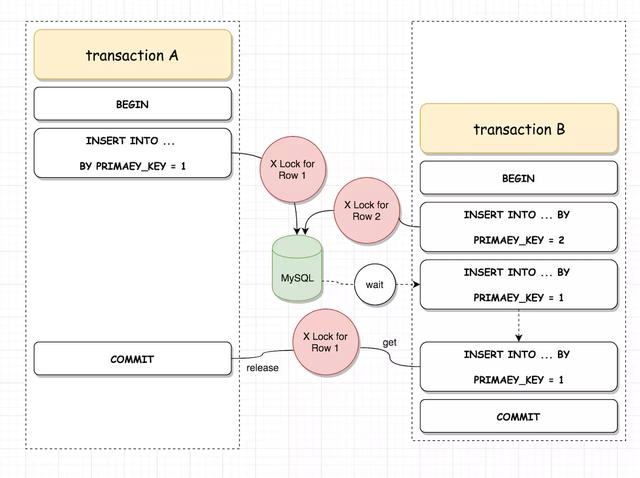
如上圖所示,事務 A 與事務 B 同時會去 Insert 一條主鍵值為 1 的資料,由於事務 A 首先獲取了主鍵值為 1 的行鎖,導致事務 B 因無法獲取行鎖而產生等待,等到事務 A 提交後,事務 B 才獲取該行鎖,完成提交。
這裡強調的是行鎖的概念,雖然事務 B 重複插入了主鍵,但是在獲取行鎖之前,事務一直是處於行鎖等待的狀態,只有獲取行鎖後,才會報主鍵衝突的錯誤。
當然這種 Inster 行鎖衝突的問題比較少見,只有在大量併發插入場景下才會出現,專案上真正常見的是 update&delete 之間行鎖等待,這裡只是用於示例,原理都是相同的。
三、產生的原因
根據我之前接觸到的此類問題,大致可以分為以下幾種原因:
1. 程式中非資料庫互動操作導致事務掛起將介面呼叫或者檔案操作等這一類非資料庫互動操作嵌入在 SQL 事務程式碼之中,那麼整個事務很有可能因此掛起(介面不通等待超時或是上傳下載大附件)。 2. 事務中包含效能較差的查詢 SQL事務中存在慢查詢,導致同一個事務中的其他 DML 無法及時釋放佔用的行鎖,引起行鎖等待。 3. 單個事務中包含大量 SQL通常是由於在事務程式碼中加入 for 迴圈導致,雖然單個 SQL 執行很快,但是 SQL 數量一大,事務就會很慢。 4. 級聯更新 SQL 執行時間較久這類 SQL 容易讓人產生錯覺,例如:update A set ... where ...in (select B) 這類級聯更新,不僅會佔用 A 表上的行鎖,也會佔用 B 表上的行鎖,當 SQL 執行較久時,很容易引起 B 表上的行鎖等待。
5. 磁碟問題導致的事務掛起極少出現的情形,比如儲存突然離線,SQL 執行會卡在核心呼叫磁碟的步驟上,一直等待,事務無法提交。
綜上可以看出,如果事務長時間未提交,且事務中包含了 DML 操作,那麼就有可能產生行鎖等待,引起報錯。
四、定位難點
當 web 日誌中出現行鎖超時錯誤後,很多開發都會找我來排查問題,這裡說下問題定位的難點!
1. MySQL 本身不會主動記錄行鎖等待的相關資訊,所以無法有效的進行事後分析。
2. 鎖爭用原因有多種,很難在事後判斷到底是哪一類問題場景,尤其是事後無法復現問題的時候。
3. 找到問題 SQL 後,開發無法有效從程式碼中挖掘出完整的事務,這也和公司框架-產品-專案的架構有關,需要靠 DBA 事後採集完整的事務 SQL 才可以進行分析。
五、常用方法
先介紹下個人通常是如何解決此類問題的, 這裡問題解決的前提是問題可以復現,只要不是突然出現一次,之後再也不出現,一般都是可以找到問題源頭的。
這裡問題復現分為兩種情景:
1. 手動復現只要按照一定的操作,就可以復現報錯,這種場景較簡單! 2. 隨機復現不知道何時會突然報錯,無法手動復現,這種場景較難!下面先寫下統一的模擬場景,用於復現行鎖超時問題,便於大家理解:
--表結構 CREATE TABLE `emp` ( `id` int(11) NOT NULL, KEY `idx_id` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 從1~100w插入100w行記錄。 --測試過程: 事務1: start transaction; delete from emp where id = 1; select * from emp where id in (select id from emp); -->模擬慢查詢,執行時間很久,事務因此一直不提交,行鎖也不釋放. commit; 事務2: start transaction; delete from emp where id < 10; --> 處於等待id=1的行鎖狀態,當達到行鎖超時時間(這裡我配置了超時時間為 5s)後,返回行鎖超時報錯 rollback;
5.1 手動復現場景
這個場景通常只需要通過 innodb 行鎖等待指令碼就可以知道當前 MySQL 的 innodb 行鎖等待情況,例如我們一邊模擬上述報錯場景(模擬頁面操作),另一邊使用指令碼查詢(需要在超時之前查詢,否則超時報錯後就看不到了)。/*innodb 行鎖等待指令碼 5.7版*/ SELECT r.trx_mysql_thread_id waiting_thread,r.trx_query waiting_query, concat(timestampdiff(SECOND,r.trx_wait_started,CURRENT_TIMESTAMP()),'s') AS duration, b.trx_mysql_thread_id blocking_thread,t.processlist_command state,b.trx_query blocking_current_query,e.sql_text blocking_last_query FROM information_schema.innodb_lock_waits w JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id JOIN performance_schema.threads t on t.processlist_id = b.trx_mysql_thread_id JOIN performance_schema.events_statements_current e USING(thread_id) /*8.0版本*/ SELECT r.trx_mysql_thread_id waiting_thread,r.trx_query waiting_query, concat(timestampdiff(SECOND,r.trx_wait_started,CURRENT_TIMESTAMP()),'s') AS duration, b.trx_mysql_thread_id blocking_thread,t.processlist_command state,b.trx_query blocking_current_query,e.sql_text blocking_last_query FROM `performance_schema`.data_lock_waits w JOIN information_schema.INNODB_TRX b ON b.trx_id = w.blocking_thread_id JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_thread_id JOIN performance_schema.threads t on t.processlist_id = b.trx_mysql_thread_id JOIN performance_schema.events_statements_current e USING(thread_id)
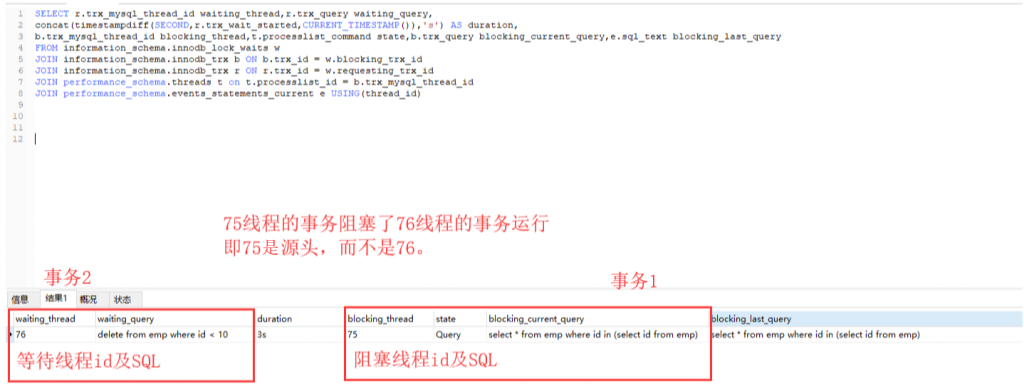
如上我們可以看到事務 2 的執行緒 id 為 76,已經被事務 1,也就是執行緒 id 為 75 的事務阻塞了 3s,並且可以看到事務 1 當前執行的 SQL 為一個 SELECT。這裡也解釋了很多開發經常問我的,為什麼 SELECT 也會阻塞其他會話?
如果遇到這種情況,那麼處理其實非常簡單。需要優化這個 SELECT 就好了,實在優化不了,把這個查詢扔到事務外就可以了,甚至都不需要挖掘出整個事務。
上述這個問題模擬,其實就是對應第三節問題產生原因中的第二點(事務中包含效能較差的查詢 SQL),下面我們把第一點(程式中非資料庫互動操作導致事務掛起)也模擬下,對比下現象。
我們只需要將事務 1 的過程改成如下即可。事務1: start transaction; delete from emp where id = 1; select * from emp where id in (select id from emp); 等待60s(什麼都不要做) --> 模擬介面呼叫超時,事務夯住,隨後再執行commit。 commit;
再次用指令碼檢視,可以看到現象是有所不同的,不同點在於,阻塞事務處於 sleep 狀態,即事務當前並不在跑 SQL。從 DBA 的角度看,這類現象八成就可以斷定是程式碼在事務中嵌入了其他的互動操作導致的事務掛起(另外也有可能是網路問題導致的事務僵死),因為程式並不像人,它不會偷懶,不會出現事務執行到一半,休息一會再提交一說。
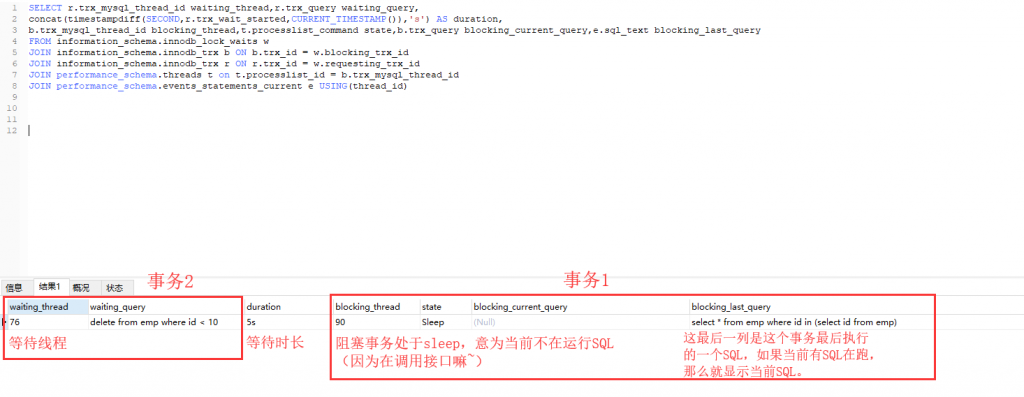
如果是這類現象的問題,因為本質並不是由於 SQL 慢導致的事務掛起,所以必須要到程式碼裡去找到對應的點,看下到底是在做什麼互動操作卡住了。
這裡就需要開發去排查程式碼才可以找到源頭,但是唯一可用的資訊就是該事務最後執行的一條 SQL,也就是上圖中最後一列,從我之前的經驗來看(絕大時候),開發很難單從這一條 SQL 就可以找到程式碼裡具體位置,尤其是當這條 SQL 是一條很常見的 SQL,就更為困難!
當面對這種情況,就需要 DBA 去挖掘出這個事務執行過的所有 SQL,然後再讓開發去排查程式碼,這樣難度應該就小多了。這裡就需要用到 MySQL 的 general_log,該日誌用於記錄 MySQL 中所有執行過的 SQL。
--檢視general_log是否開啟,及檔名 mysql> show variables like '%general_log%'; +------------------+--------------------------------------+ | Variable_name | Value | +------------------+--------------------------------------+ | general_log | OFF | | general_log_file | /data/mysql_data/192-168-188-155.log | +------------------+--------------------------------------+ --暫時開啟general_log mysql> set global general_log = 1; Query OK, 0 rows affected (0.00 sec) --暫時關閉general_log mysql> set global general_log = 0; Query OK, 0 rows affected (0.00 sec)
開啟 general_log 後,手動復現的時候通過 innodb 行鎖等待指令碼查詢結果中的執行緒 ID,去 general_log 找到對應的事務分析即可,如下:

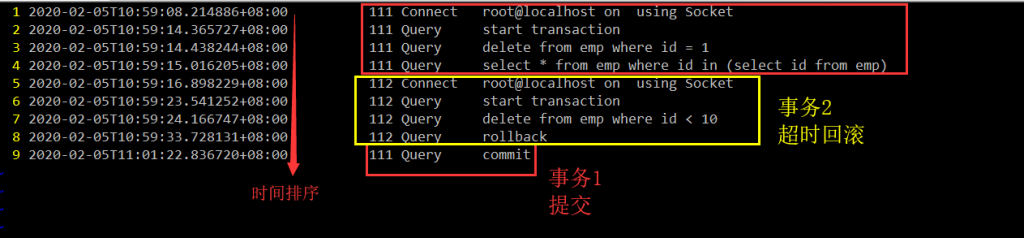 根據執行緒 ID 可以很輕易的從 general_log 中找到對應時間點的事務操作(實際場景下可能需要通過管道命令過濾)。如上圖所示,事務 1 與事務 2 的全部 SQL 都可以找到,再通過這些 SQL 去程式碼中找到對應的位置即可,比如上圖中執行緒 ID 為 111 的事務,執行
根據執行緒 ID 可以很輕易的從 general_log 中找到對應時間點的事務操作(實際場景下可能需要通過管道命令過濾)。如上圖所示,事務 1 與事務 2 的全部 SQL 都可以找到,再通過這些 SQL 去程式碼中找到對應的位置即可,比如上圖中執行緒 ID 為 111 的事務,執行 select * from emp where id in (select id from emp) 後到真正提交,過了 1min 左右,原因要麼就是這條 SQL 查詢慢,要麼就是程式碼在執行其他互動操作。
PS:general_log 由於會記錄所有 SQL,所以對 MySQL 效能影響較大,且容易暴漲,所以只在問題排查時暫時開啟,問題排查後,請及時關閉!
5.2 隨機復現場景
相較於手動復現場景,這種場景因為具有隨機性,所以無法一邊模擬報錯,一邊通過指令碼查詢到具體的阻塞情況,因此需要通過其他方式來監控 MySQL 的阻塞情況。
我一般是通過在 Linux 上後臺跑監控指令碼(innodb_lock_monitor.sh)來記錄 MySQL 阻塞情況,指令碼如下:#!/bin/bash
#賬號、密碼、監控日誌
user="root"
password="Gepoint"
logfile="/root/innodb_lock_monitor.log"
while true
do
num=`mysql -u${user} -p${password} -e "select count(*) from information_schema.innodb_lock_waits" |grep -v count`
if [[ $num -gt 0 ]];then
date >> /root/innodb_lock_monitor.log
mysql -u${user} -p${password} -e "SELECT r.trx_mysql_thread_id waiting_thread,r.trx_query waiting_query, \
concat(timestampdiff(SECOND,r.trx_wait_started,CURRENT_TIMESTAMP()),'s') AS duration,\
b.trx_mysql_thread_id blocking_thread,t.processlist_command state,b.trx_query blocking_query,e.sql_text \
FROM information_schema.innodb_lock_waits w \
JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id \
JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id \
JOIN performance_schema.threads t on t.processlist_id = b.trx_mysql_thread_id \
JOIN performance_schema.events_statements_current e USING(thread_id) \G " >> ${logfile}
fi
sleep 5
done
再次檢視
--使用 nohup 命令後臺執行監控指令碼 [root@192-168-188-155 ~]# nohup sh innodb_lock_monitor.sh & [2] 31464 nohup: ignoring input and appending output to ‘nohup.out’ --檢視 nohup.out 是否出現報錯 [root@192-168-188-155 ~]# tail -f nohup.out mysql: [Warning] Using a password on the command line interface can be insecure. mysql: [Warning] Using a password on the command line interface can be insecure. mysql: [Warning] Using a password on the command line interface can be insecure. --定時檢視監控日誌是否有輸出(沒有輸出的話,這個日誌也不會生成哦!) [root@192-168-188-155 ~]# tail -f innodb_lock_monitor.log Wed Feb 5 11:30:11 CST 2020 *************************** 1. row *************************** waiting_thread: 112 waiting_query: delete from emp where id < 10 duration: 3s blocking_thread: 111 state: Sleep blocking_query: NULL sql_text: select * from emp where id in (select id from emp)
當監控日誌有輸出阻塞資訊時,後續解決方案就和之前的手動復現場景一致。
-
如果是事務卡在慢 SQL,那麼就需要優化 SQL。
-
如果是事務掛起,那麼就通過 general_log 分析事務,然後找到具體的程式碼位置。
PS:問題排查完成後,請及時關閉後臺監控程序,通過 kill+pid 的方式直接關閉即可!
六、Performance_Schema
之前的方法感覺不是很方便,因為 general_log 需要訪問伺服器,且過濾分析也較難,需要一定的 MySQL 基礎及 Linux 基礎才適用,因此想尋找一種更為簡便的方法。
6.1 方法介紹個人想法是利用 MySQL 5.5 開始提供的 performance_schema 效能引擎來進行分析,Performance_Schema 是 MySQL 提供的在系統底層監視 MySQL 伺服器效能的一個特性,其提供了大量監控項,包括:鎖、IO、事務、記憶體使用等。
介紹下主要原理:
1. 主要用的表有 2 張 events_transactions_history_long 和 events_statements_history_long。2. transactions_history_long 會記錄歷史事務資訊,events_statements_history_long 則記錄歷史 SQL。3. 從 transactions_history_long 中得到回滾事務的執行緒 ID,再根據時間範圍去篩選出可疑的事務,最後從 events_statements_history_long 得到事務對應的 SQL,從中排查哪個為源頭。優點:
1. 不需要通過 general_log 來獲取事務 SQL。2. 不需要監控指令碼來獲取到行鎖等待情況。3. 只需要訪問 MySQL 就可以實現,而不需要訪問伺服器。4. 效能開銷較小,且不會暴漲,因為是迴圈覆蓋寫入的。5. 可以知道每條 SQL 的執行時長。缺點:
1. history_long 相關表預設保留記錄有限,可能會把有用的資料刷掉,尤其是在 SQL 執行較多的系統。2. 如果要加大 history_long 相關表的最大保留行數,需要重啟 MySQL,無法線上修改引數。3. history_long 相關表記錄中的時間均為相對時間,也就是距離 MySQL 啟動的時長,看起來不是很方便。4. history_long 相關表不會主動記錄行鎖等待的資訊,所以只能通過先根據時間範圍刷選出可疑的事務,再進一步分析,不如指令碼監控定位的準。/*開啟performance_schema相關監控項,需要提前開啟performance_schema*/ UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' where name = 'transaction'; UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' where name like '%events_transactions%'; UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' where name like '%events_statements%'; /*查看回滾事務SQL,確認是否是日誌裡報錯的事務*/ SELECT a.THREAD_ID ,b.EVENT_ID ,a.EVENT_NAME ,CONCAT (b.TIMER_WAIT / 1000000000000,'s') AS trx_druation ,CONCAT (a.TIMER_WAIT / 1000000000000,'s') sql_druation ,a.SQL_TEXT,b.STATE,a.MESSAGE_TEXT FROM performance_schema.events_statements_history_long a JOIN performance_schema.events_transactions_history_long b ON a.THREAD_ID = b.THREAD_ID AND (a.NESTING_EVENT_ID = b.EVENT_ID OR a.EVENT_ID = b.NESTING_EVENT_ID) WHERE b.autocommit = 'NO' AND a.SQL_TEXT IS NOT NULL AND b.STATE = 'ROLLED BACK' /*檢視該時間段內可疑事務即超過5s的事務SQL,這裡預設innodb_lock_wait_timeout為5s*/ SELECT a.THREAD_ID ,b.EVENT_ID ,a.EVENT_NAME ,CONCAT (b.TIMER_WAIT / 1000000000000,'s') AS trx_druation ,CONCAT (a.TIMER_WAIT / 1000000000000,'s') sql_druation ,a.SQL_TEXT,b.STATE,a.MESSAGE_TEXT,a.ROWS_AFFECTED,a.ROWS_EXAMINED,a.ROWS_SENT FROM performance_schema.events_statements_history_long a JOIN performance_schema.events_transactions_history_long b ON a.THREAD_ID = b.THREAD_ID AND (a.NESTING_EVENT_ID = b.EVENT_ID OR a.EVENT_ID = b.NESTING_EVENT_ID) WHERE b.autocommit = 'NO' AND SQL_TEXT IS NOT NULL AND b.STATE = 'COMMITTED' AND b.TIMER_WAIT / 1000000000000 > 5 AND b.TIMER_START < (SELECT TIMER_START FROM performance_schema.events_transactions_history_long WHERE THREAD_ID = 70402 /*上述SQL查詢結果中的執行緒ID*/ AND EVENT_ID = 518) /*上述SQL查詢結果中的事件ID*/ AND b.TIMER_END > ( SELECT TIMER_END FROM performance_schema.events_transactions_history_long WHERE THREAD_ID = 70402 /*上述SQL查詢結果中的執行緒ID*/ AND EVENT_ID = 518) /*上述SQL查詢結果中的事件ID*/ ORDER BY a.THREAD_ID
6.2 測試模擬
如果是用這種方法的話,那麼就不需要分手動復現還是隨機復現了,操作方法都是一樣的,下面模擬下如何操作:1. 首先通過上述方法開啟 performance_schema 相關監控項,會直接生效,無需重啟 MySQL。2. 然後復現問題,這裡最好是手動復現(因為復現後如果沒有及時檢視,監控資料可能就會被刷掉),不行的話就只能等待隨機復現了。3. 問題復現後通過上述指令碼查詢是否存在回滾事務(即因為行鎖超時回滾的事務)。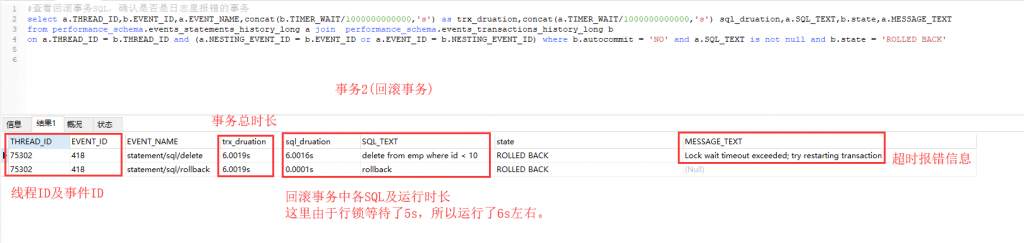 4. 然後根據回滾事務的執行緒 ID 和事件 ID,帶入到最後一個指令碼中,檢視可疑事務,進行分析。
4. 然後根據回滾事務的執行緒 ID 和事件 ID,帶入到最後一個指令碼中,檢視可疑事務,進行分析。
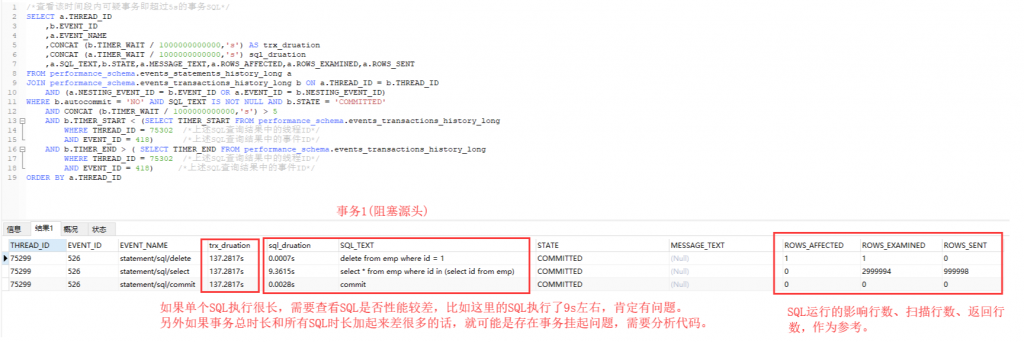
這裡由於是測試環境模擬,所以結果非常瞭然,專案上實際輸出結果可能有很多,需要一一分析事務是否有問題!
七、總結
實際測試後,發現通過 performance_schema 來排查行鎖等待超時問題限制其實也比較多,而且最後的分析也是一門技術活,並不如一開始想象的那麼簡單,有點事與願違了。
通過 performance_schema 排查問題最難處理的有 3 點:1. 時間問題,相對時間如何轉換為絕對時間,這個目前一直找不到好的方法。2. 不會主動記錄下行鎖等待的資訊,所以只能通過時間節點刷選後進一步分析。3. 記錄被刷問題,因為是記憶體表,設定很大容易記憶體溢位,設定很小就容易被很快刷掉。