
Flink 學習 — Flink 寫入資料到 ElasticSearch
前言
前面 FLink 的文章中我們已經介紹了說 Flink 已經有很多自帶的 Connector。
1、《從0到1學習Flink》—— Data Source 介紹
2、《從0到1學習Flink》—— Data Sink 介紹
其中包括了 Source 和 Sink 的,後面我也講了下如何自定義自己的 Source 和 Sink。
那麼今天要做的事情是啥呢?就是介紹一下 Flink 自帶的 ElasticSearch Connector,我們今天就用他來做 Sink,將 Kafka 中的資料經過 Flink 處理後然後儲存到 ElasticSearch。
準備
安裝 ElasticSearch,這裡就忽略,自己找我以前的文章,建議安裝 ElasticSearch 6.0 版本以上的,畢竟要跟上時代的節奏。
下面就講解一下生產環境中如何使用 Elasticsearch Sink 以及一些注意點,及其內部實現機制。
Elasticsearch Sink
新增依賴
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency>
上面這依賴版本號請自己根據使用的版本對應改變下。
下面所有的程式碼都沒有把 import 引入到這裡來,如果需要檢視更詳細的程式碼,請檢視我的 GitHub 倉庫地址:
這個 module 含有本文的所有程式碼實現,當然越寫到後面自己可能會做一些抽象,所以如果有程式碼改變很正常,請直接檢視全部專案程式碼。
ElasticSearchSinkUtil 工具類
這個工具類是自己封裝的,getEsAddresses 方法將傳入的配置檔案 es 地址解析出來,可以是域名方式,也可以是 ip + port 形式。addSink 方法是利用了 Flink 自帶的 ElasticsearchSink 來封裝了一層,傳入了一些必要的調優引數和 es 配置引數,下面文章還會再講些其他的配置。
ElasticSearchSinkUtil.java
public class ElasticSearchSinkUtil {
/**
* es sink
*
* @param hosts es hosts
* @param bulkFlushMaxActions bulk flush size
* @param parallelism 並行數
* @param data 資料
* @param func
* @param <T>
*/
public static <T> void addSink(List<HttpHost> hosts, int bulkFlushMaxActions, int parallelism,
SingleOutputStreamOperator<T> data, ElasticsearchSinkFunction<T> func) {
ElasticsearchSink.Builder<T> esSinkBuilder = new ElasticsearchSink.Builder<>(hosts, func);
esSinkBuilder.setBulkFlushMaxActions(bulkFlushMaxActions);
data.addSink(esSinkBuilder.build()).setParallelism(parallelism);
}
/**
* 解析配置檔案的 es hosts
*
* @param hosts
* @return
* @throws MalformedURLException
*/
public static List<HttpHost> getEsAddresses(String hosts) throws MalformedURLException {
String[] hostList = hosts.split(",");
List<HttpHost> addresses = new ArrayList<>();
for (String host : hostList) {
if (host.startsWith("http")) {
URL url = new URL(host);
addresses.add(new HttpHost(url.getHost(), url.getPort()));
} else {
String[] parts = host.split(":", 2);
if (parts.length > 1) {
addresses.add(new HttpHost(parts[0], Integer.parseInt(parts[1])));
} else {
throw new MalformedURLException("invalid elasticsearch hosts format");
}
}
}
return addresses;
}
}
Main 啟動類
Main.java
public class Main {
public static void main(String[] args) throws Exception {
//獲取所有引數
final ParameterTool parameterTool = ExecutionEnvUtil.createParameterTool(args);
//準備好環境
StreamExecutionEnvironment env = ExecutionEnvUtil.prepare(parameterTool);
//從kafka讀取資料
DataStreamSource<Metrics> data = KafkaConfigUtil.buildSource(env);
//從配置檔案中讀取 es 的地址
List<HttpHost> esAddresses = ElasticSearchSinkUtil.getEsAddresses(parameterTool.get(ELASTICSEARCH_HOSTS));
//從配置檔案中讀取 bulk flush size,代表一次批處理的數量,這個可是效能調優引數,特別提醒
int bulkSize = parameterTool.getInt(ELASTICSEARCH_BULK_FLUSH_MAX_ACTIONS, 40);
//從配置檔案中讀取並行 sink 數,這個也是效能調優引數,特別提醒,這樣才能夠更快的消費,防止 kafka 資料堆積
int sinkParallelism = parameterTool.getInt(STREAM_SINK_PARALLELISM, 5);
//自己再自帶的 es sink 上一層封裝了下
ElasticSearchSinkUtil.addSink(esAddresses, bulkSize, sinkParallelism, data,
(Metrics metric, RuntimeContext runtimeContext, RequestIndexer requestIndexer) -> {
requestIndexer.add(Requests.indexRequest()
.index(ZHISHENG + "_" + metric.getName()) //es 索引名
.type(ZHISHENG) //es type
.source(GsonUtil.toJSONBytes(metric), XContentType.JSON));
});
env.execute("flink learning connectors es6");
}
}
配置檔案
配置都支援叢集模式填寫,注意用 , 分隔!
kafka.brokers=localhost:9092
kafka.group.id=zhisheng-metrics-group-test
kafka.zookeeper.connect=localhost:2181
metrics.topic=zhisheng-metrics
stream.parallelism=5
stream.checkpoint.interval=1000
stream.checkpoint.enable=false
elasticsearch.hosts=localhost:9200
elasticsearch.bulk.flush.max.actions=40
stream.sink.parallelism=5
執行結果
執行 Main 類的 main 方法,我們的程式是隻列印 flink 的日誌,沒有列印存入的日誌(因為我們這裡沒有打日誌):
{kind=link}
所以看起來不知道我們的 sink 是否有用,資料是否從 kafka 讀取出來後存入到 es 了。
你可以檢視下本地起的 es 終端或者伺服器的 es 日誌就可以看到效果了。
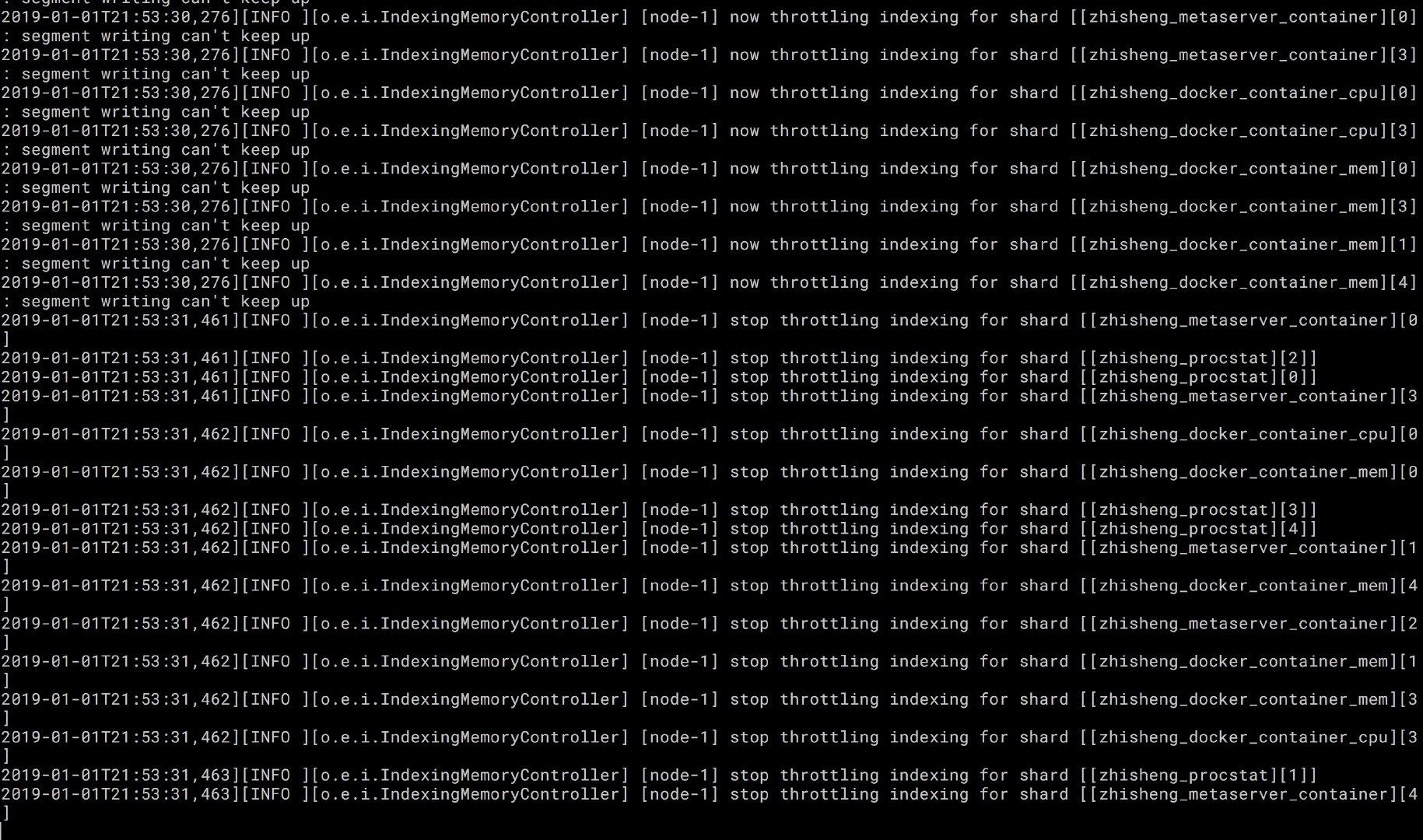
es 日誌如下:
{kind=link}
上圖是我本地 Mac 電腦終端的 es 日誌,可以看到我們的索引了。
如果還不放心,你也可以在你的電腦裝個 kibana,然後更加的直觀檢視下 es 的索引情況(或者直接敲 es 的命令)
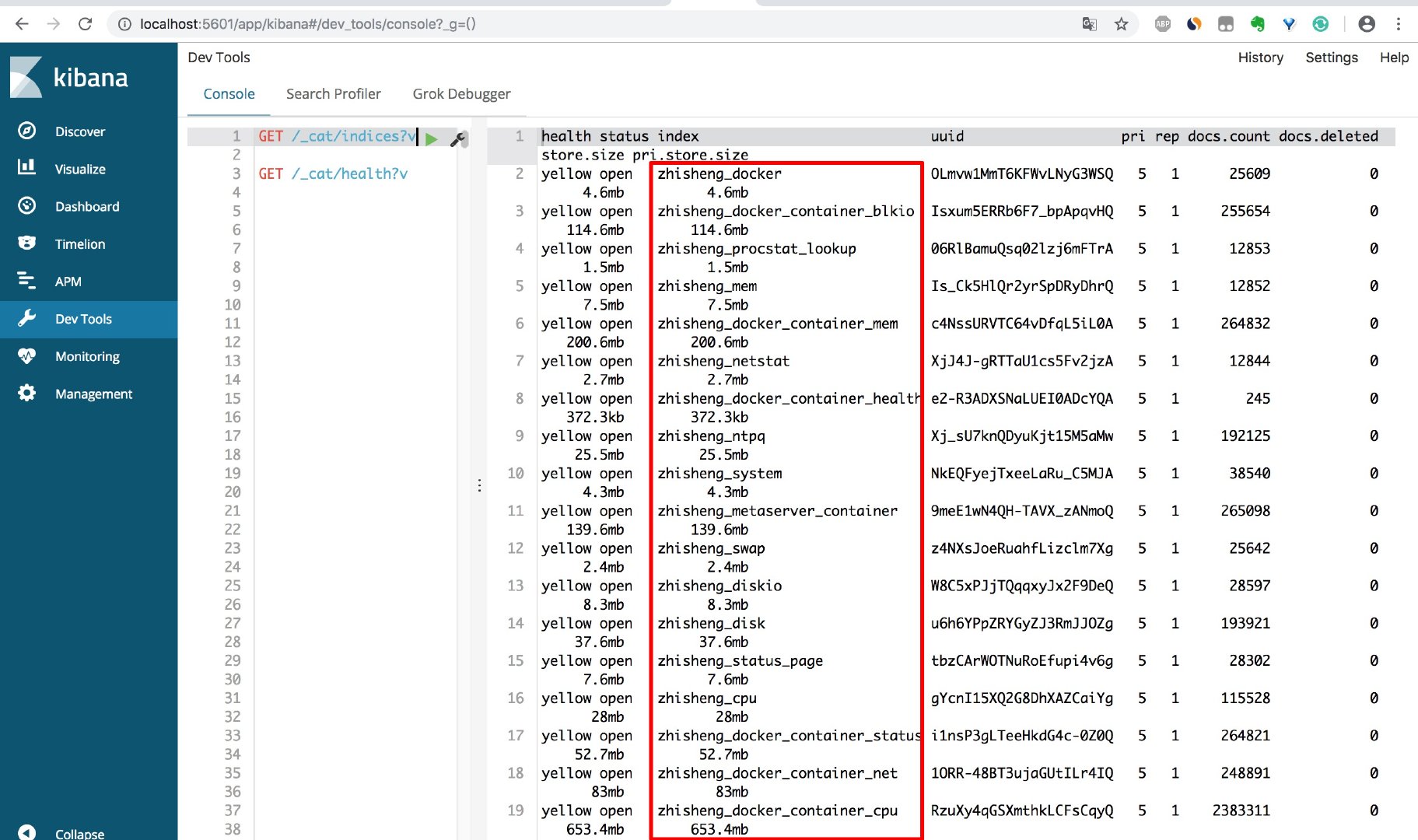
我們用 kibana 檢視存入 es 的索引如下:
{kind=link}
程式執行了一會,存入 es 的資料量就很大了。
擴充套件配置
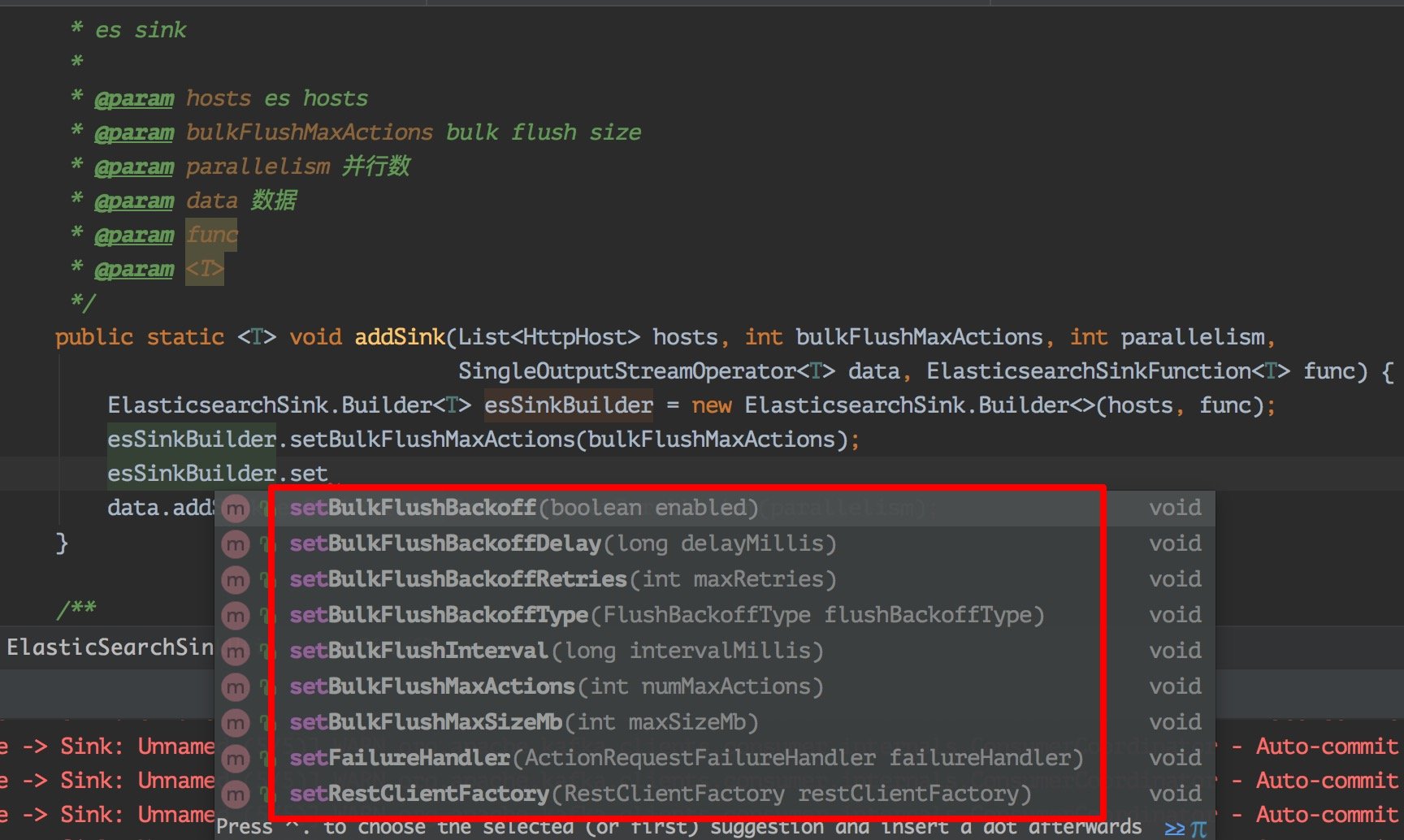
上面程式碼已經可以實現你的大部分場景了,但是如果你的業務場景需要保證資料的完整性(不能出現丟資料的情況),那麼就需要新增一些重試策略,因為在我們的生產環境中,很有可能會因為某些元件不穩定性導致各種問題,所以這裡我們就要在資料存入失敗的時候做重試操作,這裡 flink 自帶的 es sink 就支援了,常用的失敗重試配置有:
1、bulk.flush.backoff.enable 用來表示是否開啟重試機制
2、bulk.flush.backoff.type 重試策略,有兩種:EXPONENTIAL 指數型(表示多次重試之間的時間間隔按照指數方式進行增長)、CONSTANT 常數型(表示多次重試之間的時間間隔為固定常數)
3、bulk.flush.backoff.delay 進行重試的時間間隔
4、bulk.flush.backoff.retries 失敗重試的次數
5、bulk.flush.max.actions: 批量寫入時的最大寫入條數
6、bulk.flush.max.size.mb: 批量寫入時的最大資料量
7、bulk.flush.interval.ms: 批量寫入的時間間隔,配置後則會按照該時間間隔嚴格執行,無視上面的兩個批量寫入配置
看下啦,就是如下這些配置了,如果你需要的話,可以在這個地方配置擴充了。
{kind=link}
FailureHandler 失敗處理器
寫入 ES 的時候會有這些情況會導致寫入 ES 失敗:
1、ES 叢集佇列滿了,報如下錯誤
12:08:07.326 [I/O dispatcher 13] ERROR o.a.f.s.c.e.ElasticsearchSinkBase - Failed Elasticsearch item request: ElasticsearchException[Elasticsearch exception [type=es_rejected_execution_exception, reason=rejected execution of org.elasticsearch.transport.TransportService$7@566c9379 on EsThreadPoolExecutor[name = node-1/write, queue capacity = 200, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@f00b373[Running, pool size = 4, active threads = 4, queued tasks = 200, completed tasks = 6277]]]]
是這樣的,我電腦安裝的 es 佇列容量預設應該是 200,我沒有修改過。我這裡如果配置的 bulk flush size * 併發 sink 數量 這個值如果大於這個 queue capacity ,那麼就很容易導致出現這種因為 es 佇列滿了而寫入失敗。
當然這裡你也可以通過調大點 es 的佇列。參考:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
2、ES 叢集某個節點掛了
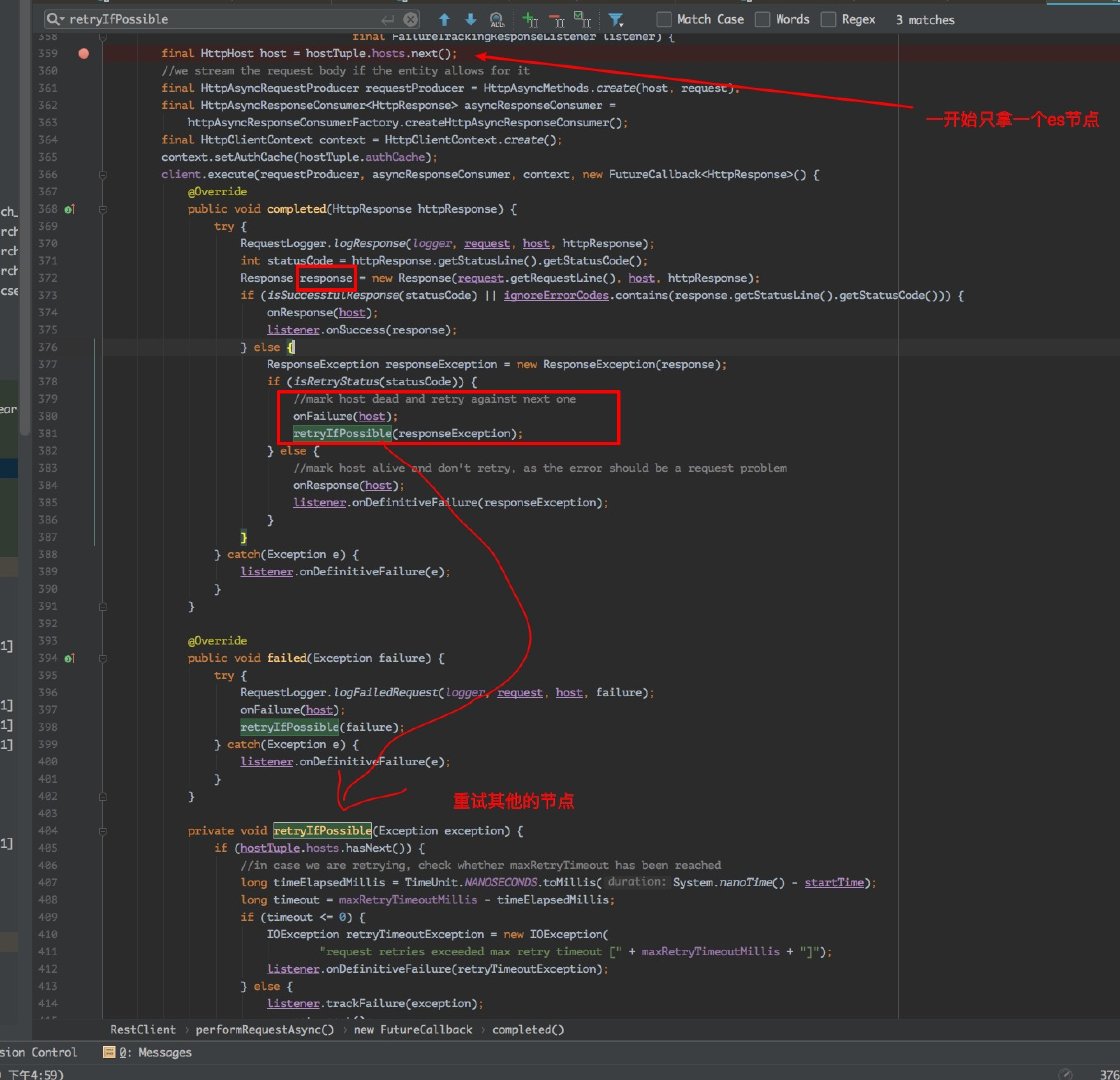
這個就不用說了,肯定寫入失敗的。跟過原始碼可以發現 RestClient 類裡的 performRequestAsync 方法一開始會隨機的從叢集中的某個節點進行寫入資料,如果這臺機器掉線,會進行重試在其他的機器上寫入,那麼當時寫入的這臺機器的請求就需要進行失敗重試,否則就會把資料丟失!
{kind=link}
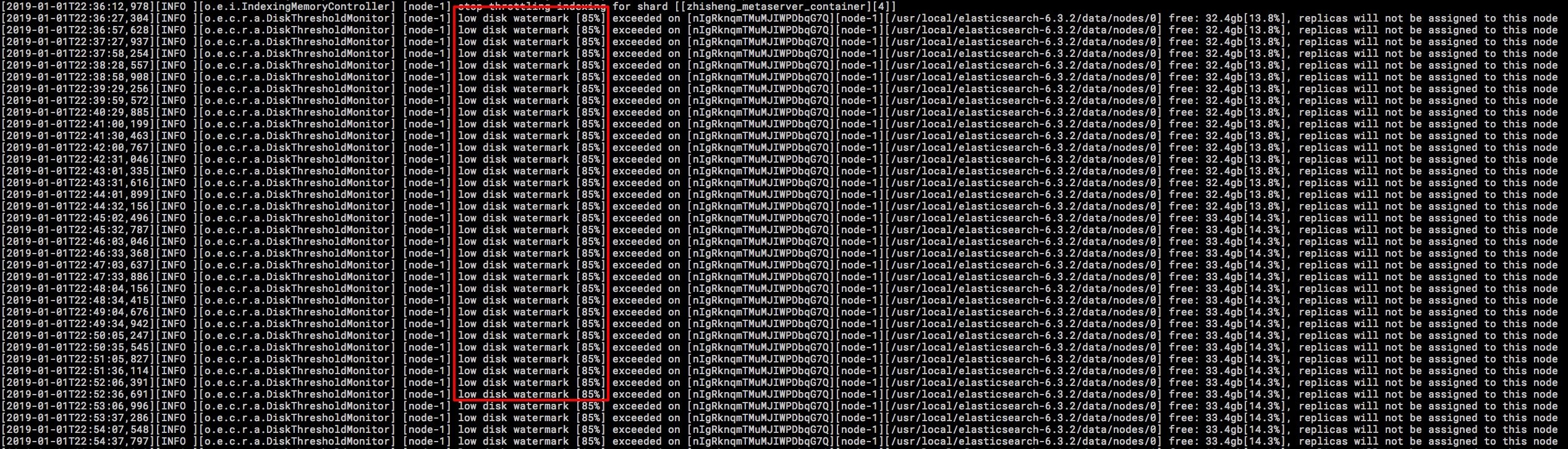
3、ES 叢集某個節點的磁碟滿了
這裡說的磁碟滿了,並不是磁碟真的就沒有一點剩餘空間的,是 es 會在寫入的時候檢查磁碟的使用情況,在 85% 的時候會列印日誌警告。
{kind=link}
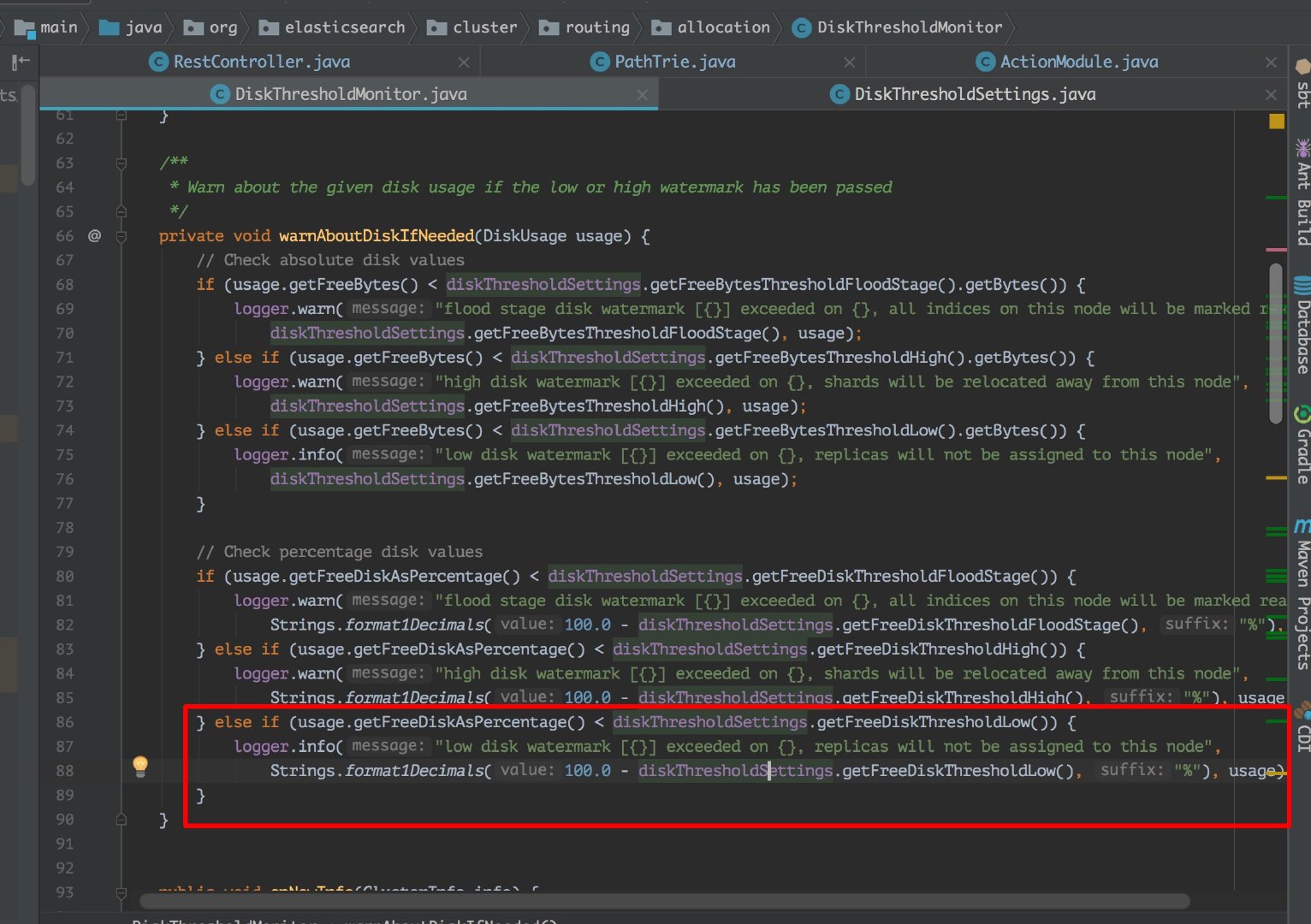
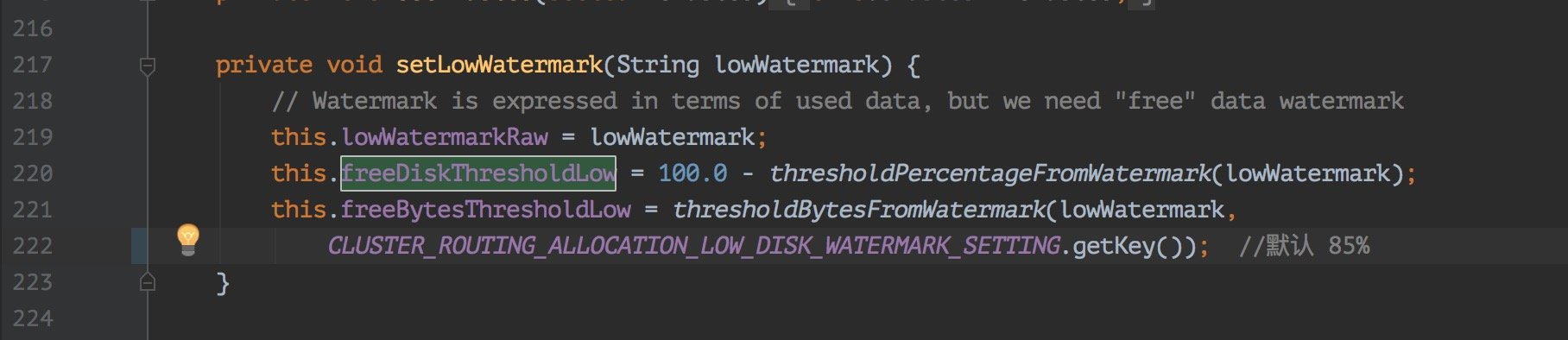
這裡我看了下原始碼如下圖:
{kind=link}
{kind=link}
如果你想繼續讓 es 寫入的話就需要去重新配一下 es 讓它繼續寫入,或者你也可以清空些不必要的資料騰出磁碟空間來。
解決方法
DataStream<String> input = ...;
input.addSink(new ElasticsearchSink<>(
config, transportAddresses,
new ElasticsearchSinkFunction<String>() {...},
new ActionRequestFailureHandler() {
@Override
void onFailure(ActionRequest action,
Throwable failure,
int restStatusCode,
RequestIndexer indexer) throw Throwable {
if (ExceptionUtils.containsThrowable(failure, EsRejectedExecutionException.class)) {
// full queue; re-add document for indexing
indexer.add(action);
} else if (ExceptionUtils.containsThrowable(failure, ElasticsearchParseException.class)) {
// malformed document; simply drop request without failing sink
} else {
// for all other failures, fail the sink
// here the failure is simply rethrown, but users can also choose to throw custom exceptions
throw failure;
}
}
}));
如果僅僅只是想做失敗重試,也可以直接使用官方提供的預設的 RetryRejectedExecutionFailureHandler ,該處理器會對 EsRejectedExecutionException 導致到失敗寫入做重試處理。如果你沒有設定失敗處理器(failure handler),那麼就會使用預設的 NoOpFailureHandler 來簡單處理所有的異常。
總結
本文寫了 Flink connector es,將 Kafka 中的資料讀取並存儲到 ElasticSearch 中,文中講了如何封裝自帶的 sink,然後一些擴充套件配置以及 FailureHandler 情況下要怎麼處理。(這個問題可是線上很容易遇到的)
原文地址:http://www.54tianzhisheng.cn/2018/12/30/Flink-ElasticSearch-Sink/.