
據分析pandas完成資料分析專案
【Python有趣打卡】資料分析pandas完成資料分析專案

今天依然是跟著羅羅攀學習資料分析,原創:羅羅攀(公眾號:luoluopan1) [ 學習Python有趣|資料分析三板斧
](https://mp.weixin.qq.com/s?__biz=MzIyMjY2MzgyMw
。今天是在DD大資料團隊實習的第一天,正式開始資料分析之旅,很開心,感覺離自己的夢想又進了一步~
資料來源
-
資料來源
[ https://www.kaggle.com/starbucks/store-locations](https://www.kaggle.com/starbucks/store-locations) (資料下載需要註冊)
-
定義問題
哪些國家星巴克店鋪較多;哪些城市星巴克店鋪較多;中國星巴克店鋪分佈情況 -
讀取資料
import numpy as np
import pandas as pd
data = pd.read_csv(r'C:\Users\xuxiaojielucky_i\Desktop\directory.csv')
data.head()
還是使用 jupyter notebook
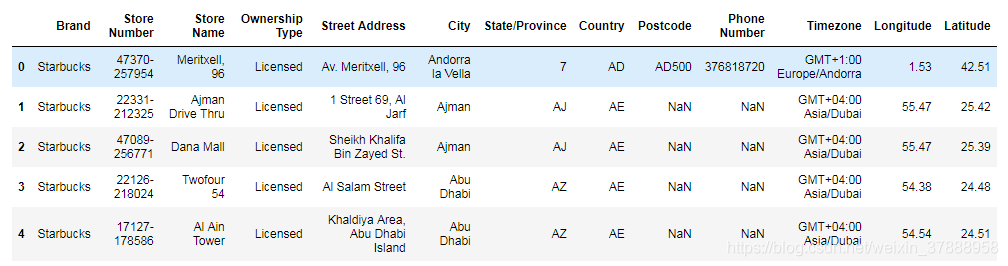
檢視資料
- 檢查資料
data.describe()
describe函式主要是用來了解數值型資料的分佈和概況
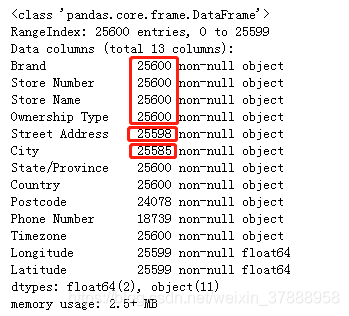
data.info()
info函式主要是用來檢視資料的缺失值情況,如針對我們的問題,我們關注的資料主要是地點(國家和城市),這裡城市city部分資料缺失。
資料處理
對原始資料進行預處理,包括對資料缺失值處理、異常值處理、重複值處理、多表處理、資料轉換處理等,要怎麼處理資料要具體問題具體分析。
- 選擇資料
首先看下星巴克旗下有哪些品牌吧
data['Brand'].unique()
不研究這麼多品牌,我們只看品牌—— ‘Starbucks’
data = data[data['Brand'] == 'Starbucks']
data.head()
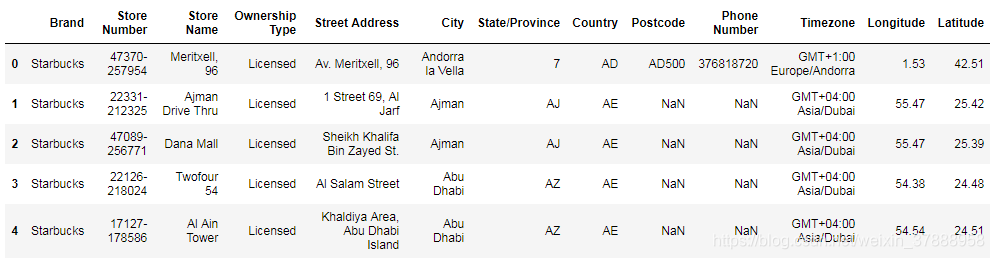
- 找出缺失值
data.isnull().sum()
針對我們定義的問題,主要是對City欄位進行分析,觀察City欄位缺失值,都是國家EG的城市有缺失,百度了一下EG,是埃及,好奇的可以深入分析下為啥埃及的城市都缺失了,哈哈哈哈哈
data[data['City'].isnull()]
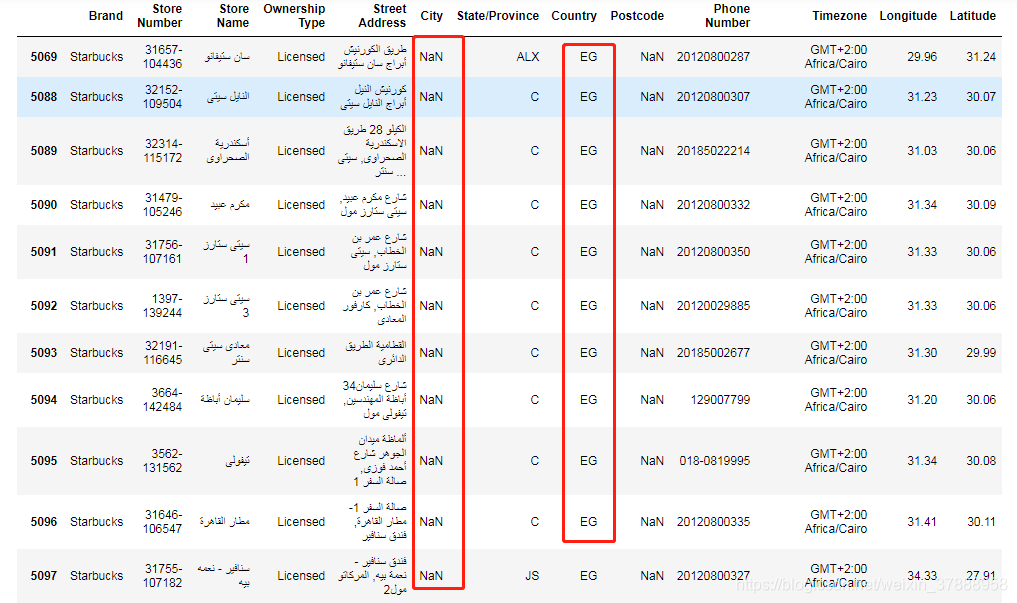
- 處理缺失值
缺失值處理主要有兩種方法:1.刪除 2.填充
我們這裡採用填充的方式,將 State/Province 欄位填充在 City 處
data['City'] = data['City'].fillna(data['State/Province'])
data[data['Country']=='EG']
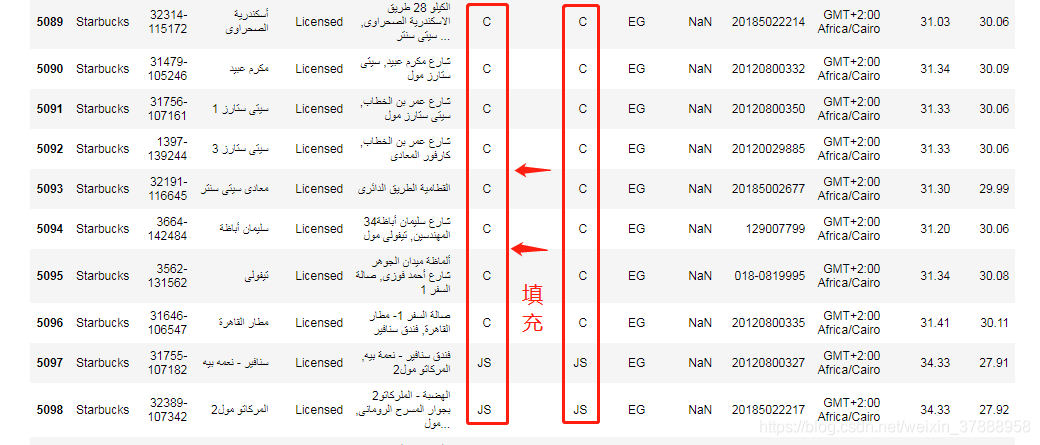
羅老師發現星巴克資料居然把臺灣當做了國家,老師表示不能忍,怒改資料,直接重新賦值,換成了中國(中國一點都不能少)。(哈哈哈哈哈羅老師很可愛了)
data['Country'][data['Country']=='TW']= 'CN'
資料分析
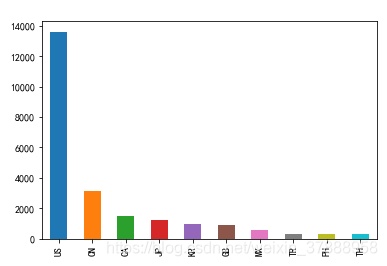
- 檢視各個國家星巴克店的數量
(1)統計每個國家星巴克店的數量,並返回數量前十的國家
data['Country'].value_counts()[0:10]
為了讓資料更加直觀,我們繪製一些圖形
由於matplotlib沒有中文庫,為了放置一些錯誤出現,可以先進行一些配置
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號
%matplotlib inline
country_count.plot(kind = 'bar')
再從城市的維度分析下,哪個城市的星巴克最多
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號
%matplotlib inline
city_count.plot(kind = 'barh')
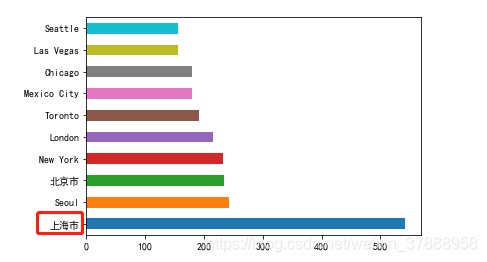
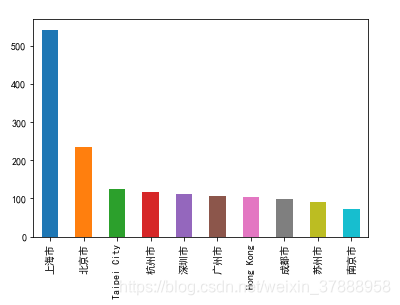
排名最多的居然是上海,不是美國的城市,不分析不知道,一分析嚇一跳,中國的市場還是很大的。其實可以繼續深挖,這些星巴克店較多的城市有什麼共同點,是不是都是經濟比較發達的。
下面只分析中國星巴克的分佈。
China_data=data[data['Country'] == 'CN']
China_citycount = China_data['City'].value_counts()[0:10]
China_citycount.plot(kind = 'bar')
- 匯出資料
匯出上一篇文章資料處理的資料
country_count.to_excel(r'C:\Users\xuxiaojielucky_i\Desktop\display.xlsx',
sheet_name='國家分佈前十')
把多個DataFrame(或者Series)資料匯出到同一個excel表格
writer = pd.ExcelWriter(r'C:\Users\xuxiaojielucky_i\Desktop\display.xlsx')
country_count.to_excel(writer,sheet_name='國家分佈前十')
city_count.to_excel(writer,sheet_name='城市分佈前十')
writer.save()### 這個才可以儲存到本地