
selenium之xpath語法總結
xpath 語法
1. 什麼是 XPath?
XPath是一種 XML 路徑,用於瀏覽頁面的 HTML 結構。他是一種語法或者語言用來查詢使用 XML 路徑表達的網頁中的任意元素。
XPath的基本形式如下:
{kind=link}
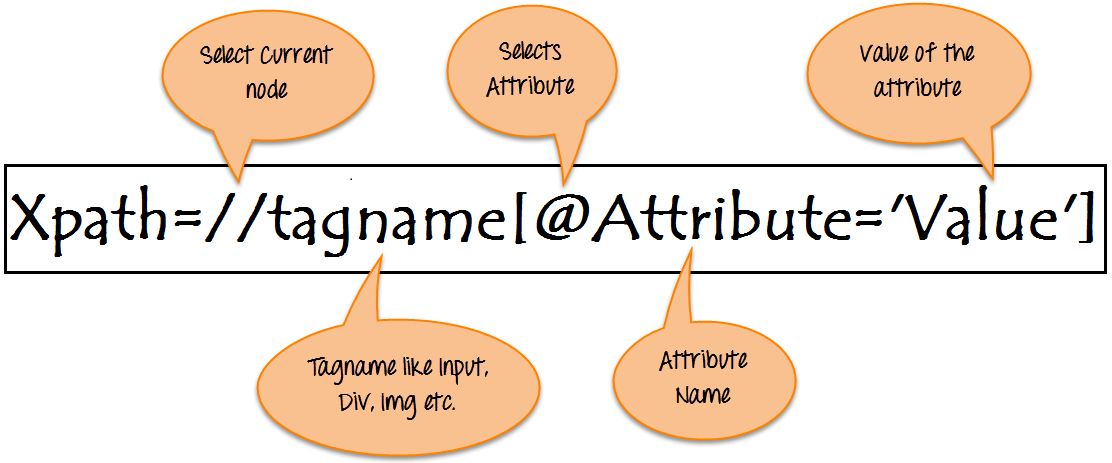
Xpath=//tagname[@attribute='value']- //:選中當前節點
- Tagname:特定節點的標記名
- @:選中屬性的標記符
- Attribute:節點的屬性名字
- Value:屬性值
為了精確查詢網頁中的元素,有以下幾種不同型別的定位器:
| XPath 定位器 | 查詢不同元素 |
|---|---|
| ID | 通過元素中的 ID 查詢元素 |
| Classname | 查詢元素中的 Class |
| Name | 通過元素的名字查詢元素 |
| Link text | 通過連結的內容查詢元素 |
| XPath | 查詢動態元素並在網頁的各個元素之間遍歷所需的 XPath |
| CSS path | CSS 路徑也能定位到沒有 name、class 或者 ID 的元素 |
2. X-path 的型別
XPath 有兩種型別:
1)絕對 XPath 路徑
2)相對 XPath 路徑
2.1 絕對 XPath
這是一種直接查詢元素的方式,不過弊端就是如果元素路徑中有一點兒變動的話,XPath 就會獲取失敗。
XPath 的關鍵特徵是它以單個正斜槓(/)開頭,這意味著您可以從根節點中選擇元素。
- Absolute XPath
/html/body/div[2]/div[1]/div/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]/b[1]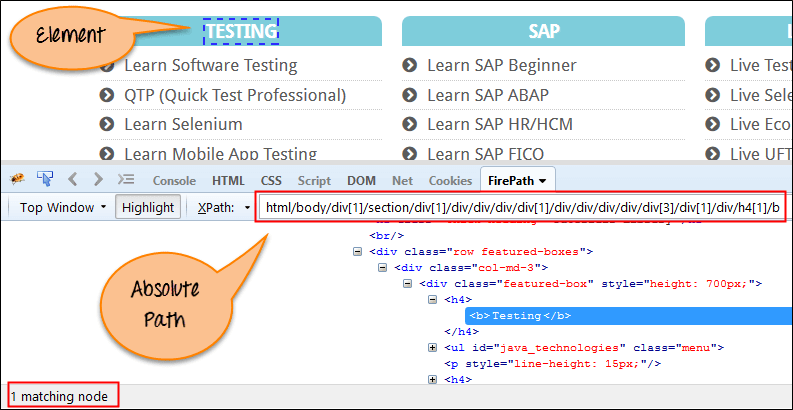{kind=link}
2.2 相對 XPath
XPath 相對路徑從 HTML DOM 結構的中間部分開始。它以雙正斜槓//開始。他可以查詢網頁中的任何元素,不需要寫很長的 XPath 路徑。相對 XPath 一直讓人偏愛的原因就在於不需要從根元素得到一個完整路徑。
- Relative XPath
Relative XPath: //div[@class='featured-box cloumnsize1']//h4[1]//b[1]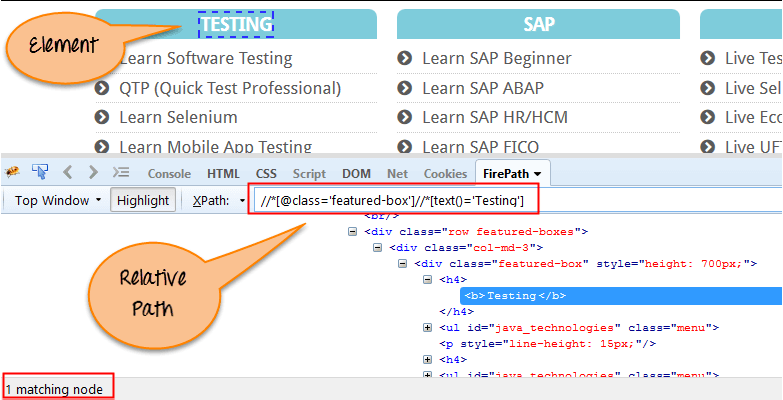{kind=link}
2.3 什麼是 XPath axes
XPath axes 在 XML 文件中從當前上下文節點搜尋不同的節點。XPath Axes 是查詢動態元素的方法,否則,這是沒有 ID、Classname,Name 等常規 XPath 方法無法實現的。
Axes 方法用來查詢那些重新整理或者執行其他操作而動態改變的元素。Selenium Webdriver 中常用的 Axes 方法很少,例如孩子 (child),父母 (parent),祖先 (ancestor),兄弟姐妹 (sibling),上一級 (preceding),自己 (self) 等。
3. 在 selenium 中用 XPath 處理複雜的 & 動態的元素
1)基本的 XPath
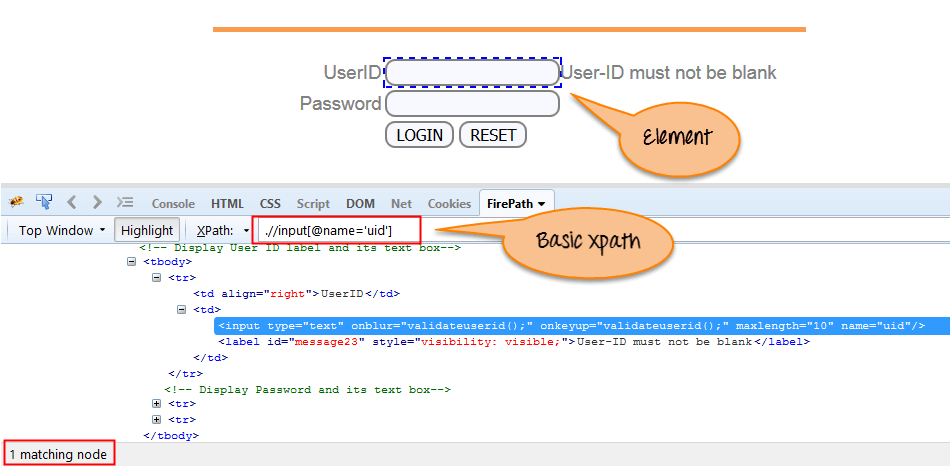
XPath 表示式根據 XML 文件中的 ID、Name、Classname 等基本屬性,選擇節點或節點列表,如下所示:
Xpath=//input[@name='uid']從這個連結進入頁面:demo.guru99.com/test/selenium-xpath...
{kind=link}
一些基本的 xpath 表示式:
Xpath=//input[@type='text']
Xpath= //label[@id='message23']
Xpath= //input[@value='RESET']
Xpath=//*[@class='barone']
Xpath=//a[@href='http://demo.guru99.com/']
Xpath= //img[@src='//cdn.guru99.com/images/home/java.png']2)Contains()
Contains()是一個在 XPath 表示式中使用的方法。當任何屬性的值動態變化(例如,登入資訊)時,將使用該屬性。
contain功能可以查詢具有部分文字的元素,如以下示例所示。
在這個例子中,我們嘗試僅僅通過屬性的部分文字值來辨認元素。在下面的 XPath 表示式中部分值’sub’用來替代提交按鈕。可以觀察到成功找到了元素。
‘Type’的完整值是’submit’但是隻使用了部分值’sub’。
Xpath=//*[contains(@type,'sub')] ‘name’的完整值是’btnLogin’但是隻用了部分值’btn’。
Xpath=//*[contains(@name,'btn')]在上面的表示式中,我們將 “name” 作為屬性,將 “ btn” 作為部分值,如下面的螢幕快照所示。 這將找到 2 個元素(LOGIN 和 RESET),因為它們的’name’屬性以’btn’開頭。
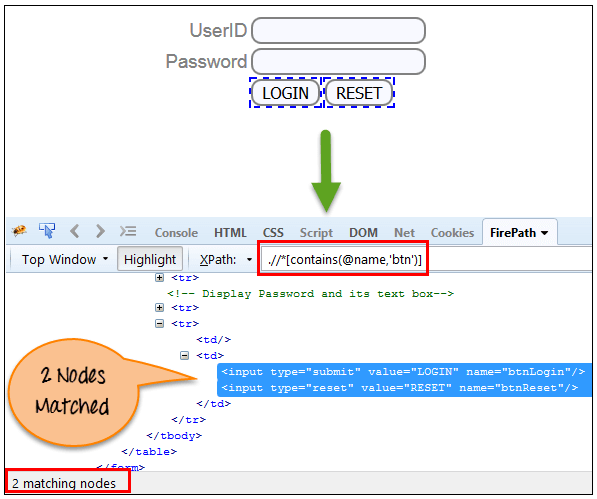{kind=link}
同樣,在下面的表示式中,我們將 “id” 作為屬性,將 “ message” 作為部分值。 這將發現 2 個元素(“使用者 ID 不能為空” 和 “密碼不能為空”),因為其 “name” 屬性以 “message” 開頭。
Xpath=//*[contains(@id,'message')]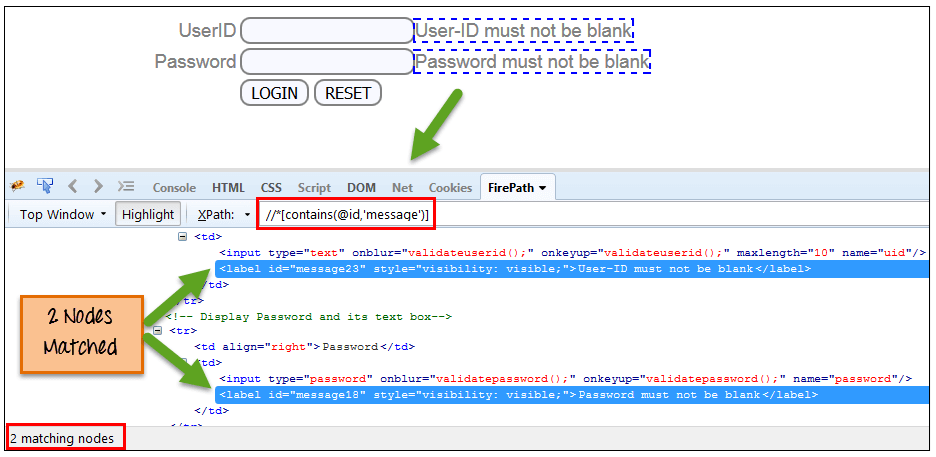{kind=link}
在下面的表示式中,我們將連結中的’text’作為屬性,’here’作為部分值,如下面快照中所示。這將找到連結 (‘here’) 因為它顯示了文字’here’。
Xpath=//*[contains(text(),'here')]
Xpath=//*[contains(@href,'guru99.com')]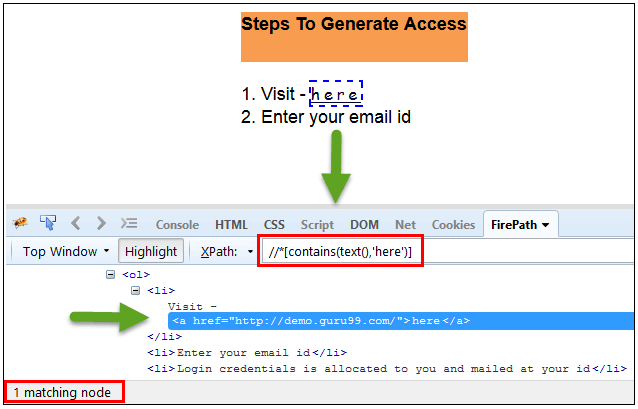{kind=link}
3)使用 OR & AND
在 OR 表示式中,有兩個條件要用到,條件一或者條件二應為真。如果任何一個條件為真或兩者皆為真,則也適用。 意味著任何一種條件都應為真才能找到該元素。
在下面的 XPath 表示式中,辨認出了單個條件或者兩個條件皆為真的元素。
Xpath=//*[@type='submit' or @name='btnReset']高亮顯示兩個元素,“LOGIN” 元素有’type’屬性,“RESET” 元素有’name’屬性。
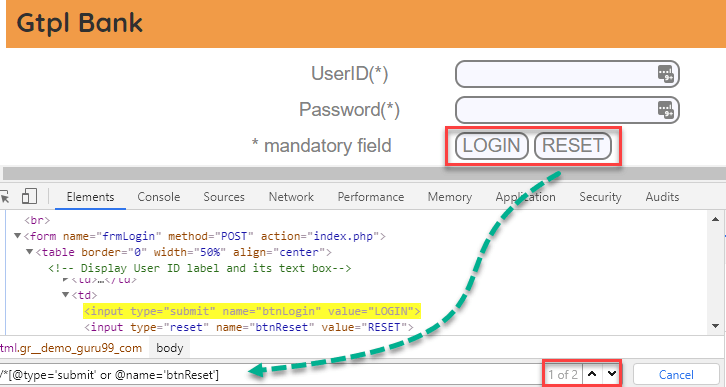{kind=link}
在 AND 表示式中,有兩個條件要用到,這兩個條件必須全部為真才能找到元素。如果任意一個條件為假就不能查詢到元素。
Xpath=//input[@type='submit' and @name='btnLogin']在下面的表示式中,高亮顯示的’LOGIN’元素擁有’type’和’name’屬性。
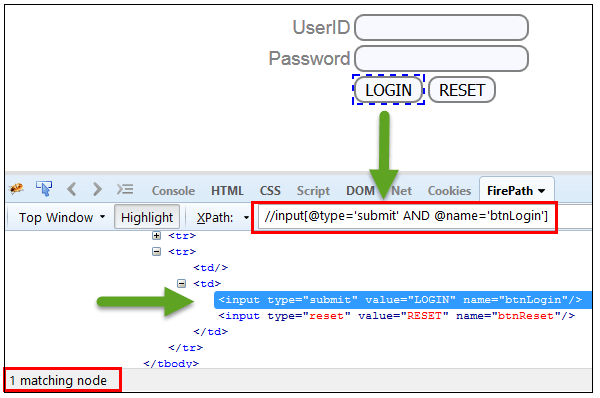{kind=link}
4)Xpath Starts-with
XPath starts-with()是一個用來查詢屬性值隨著頁面重新整理或者其他動態操作而改變的頁面元素的函式。在這個方法中,屬性的開始檔案被匹配到用來查詢屬性值動態變化的元素。你也可以查詢屬性值是靜態 (不變) 的元素。
例如:假設特定元素的 ID 這樣動態變化:
Id=”message12”
Id=”message345”
Id=”message8769”
等等等等… 但是初始文字是一樣的。在這種情況下,我們就可以使用 Start-with 表示式。
在下面的函式中,有兩個以”message” 開頭的 id 元素 (例如:’使用者 - Id 不能為空’&’密碼不能為空’)。在下面的表示式中,XPath 查詢到這些以’message’開頭的’ID’元素。
Xpath=//label[starts-with(@id, 'message')]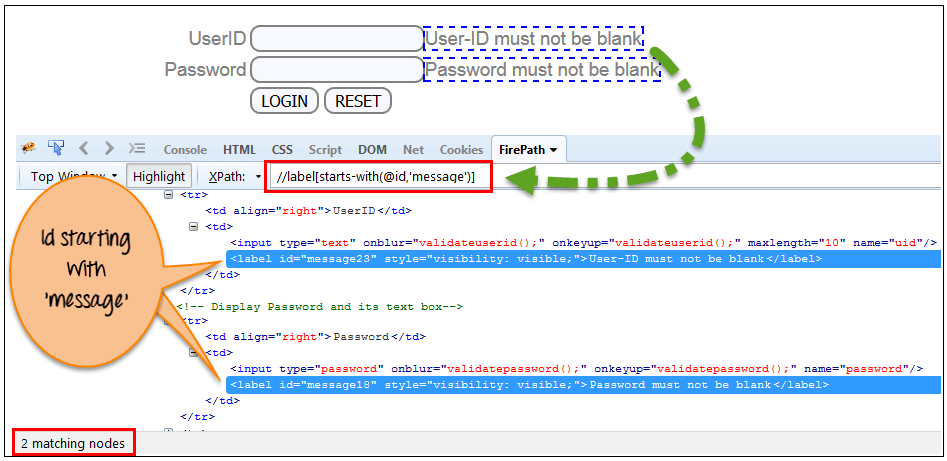{kind=link}
5)XPath Text() Function
XPath text()函式是一個用來基於頁面元素文字來定位元素的selenium webdriver的內建函式。它幫助查詢精準的文字元素以及在文字節點集合中定位元素。要定位的元素應為字串形式。
在這個表示式中,使用文字功能,我們找到了具有完全文字匹配的元素,如下所示。在我們的例子中,我們找到了文字為”UserID” 的元素。
Xpath=//td[text()='UserID']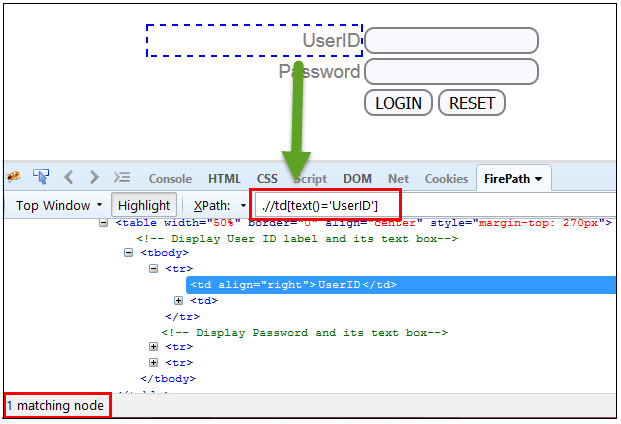{kind=link}
6)Xpath 軸方法
這些 XPath 軸方法被用來查詢複雜的或者動態的元素。下面我們會看到一部分這些方法。
為了
舉例說明這些 XPath 軸方法,我們將會使用 Guru99 bank demo 站點。
- a)Following
選取文件中當前節點所有元素 [UserID 輸入框是當前節點],如下所示:
Xpath=//*[@type='text']//following::input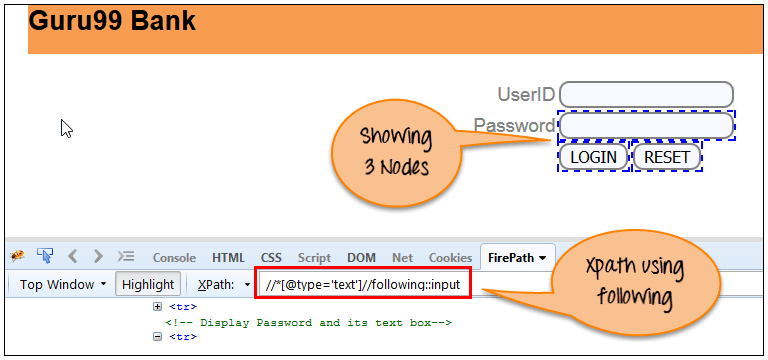{kind=link}
通過使用”following” 軸匹配到了 3 個”input” 節點 - 密碼、登陸、重置按鈕。如果你想集中任意一個特定的元素,那麼你可以用下面的 Xpath 方法。
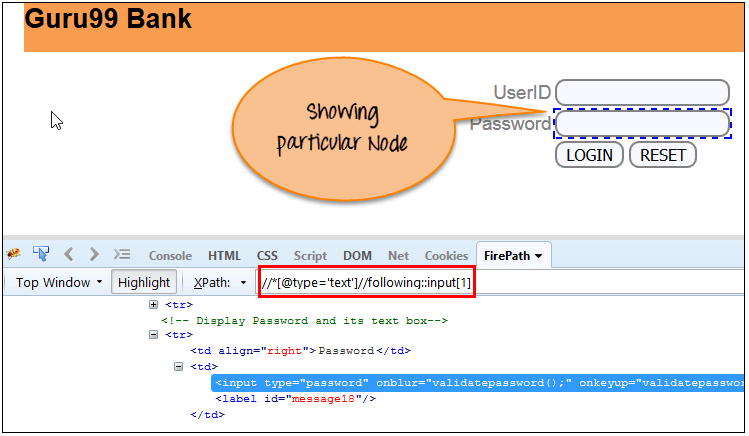
Xpath=//*[@type='text']//following::input[1]你可以根據需求通過放置 [1],[2]… 等等來更改 XPath。
輸入為’1’時,下面的截圖找到了特定的節點是’密碼’輸入框。
{kind=link}
b)祖節點
祖先軸選擇當前節點的所有祖先元素(祖父母,父母等),如以下螢幕所示。
在下面的表示式中,我們正在找到當前節點(“ENTERPRISE TESTING” 節點)的祖先元素。
Xpath=//*[text()='Enterprise Testing']//ancestor::div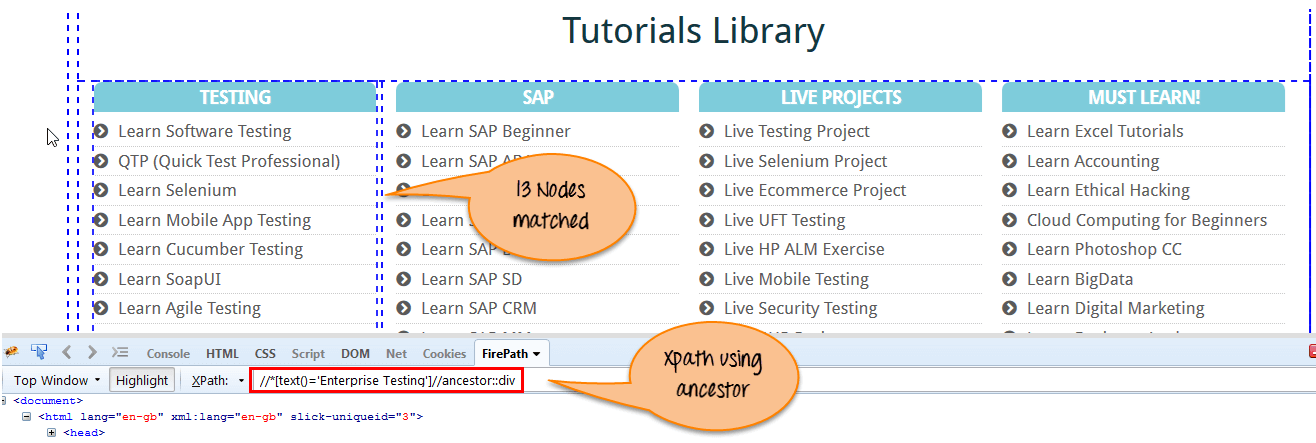{kind=link}
通過使用 “祖先” 軸匹配的 13 個 “ div” 節點。 如果您想關注任何特定元素,則可以使用下面的 XPath,在其中您可以根據需要更改數字 1、2:
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]您可以根據需要通過輸入 [1],[2]………… 來更改 XPath。
c)子節點
選擇當前節點(Java)的所有子元素,如下螢幕所示。
Xpath=//*[@id='java_technologies']//child::li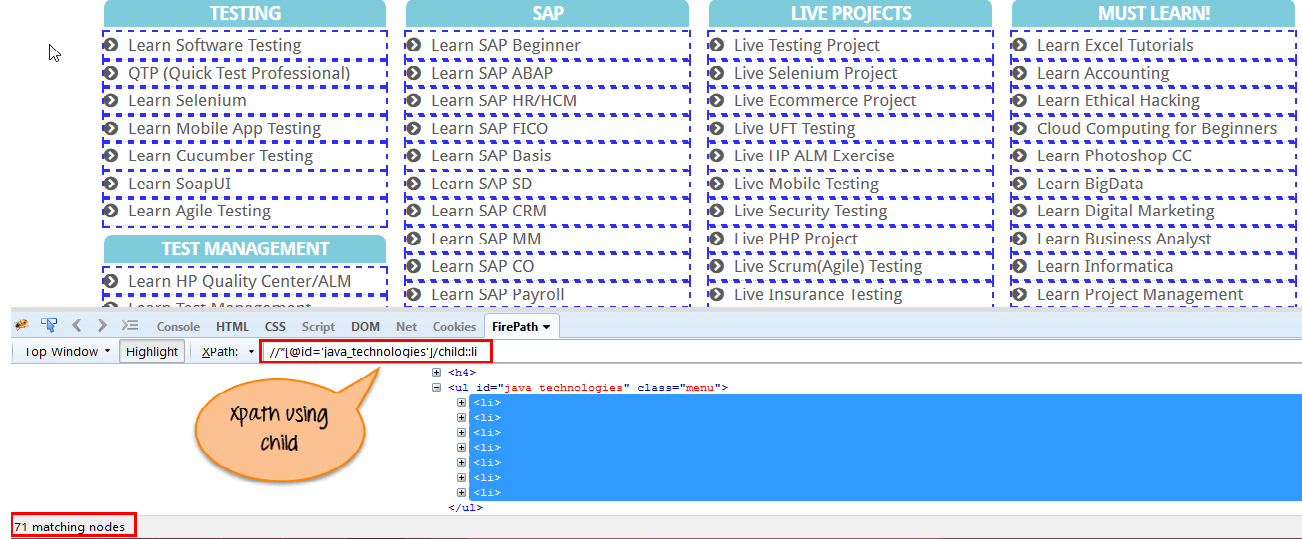{kind=link}
通過使用 “子” 軸可以匹配 71 個 “ li” 節點。 如果要關注任何特定元素,則可以使用以下 xpath:
Xpath=//*[@id='java_technologies']/child::li[1]您可以根據需要通過輸入 [1],[2]………… 來更改 XPath。
d)前節點
如下螢幕所示,選擇當前節點之前的所有節點。
在下面的表示式中,它標識 “LOGIN” 按鈕之前的所有輸入元素,即 Userid 和密碼輸入元素。
Xpath=//*[@type='submit']//preceding::input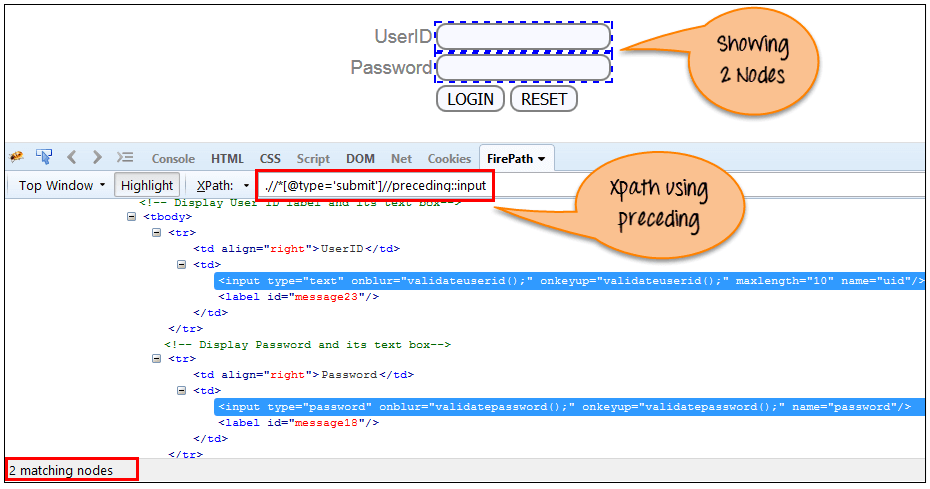{kind=link}
通過使用 “上一個” 軸可以匹配 2 個 “輸入” 節點。 如果您想關注任何特定元素,則可以使用以下 XPath:
Xpath=//*[@type='submit']//preceding::input[1]您可以根據需要通過輸入 [1],[2]………… 來更改 XPath。
e)繼兄弟姐妹節點
選擇上下文節點的以下同級。 兄弟姐妹與當前節點處於同一級別,如以下螢幕所示。 它將在當前節點之後找到元素。
xpath=//*[@type='submit']//following-sibling::input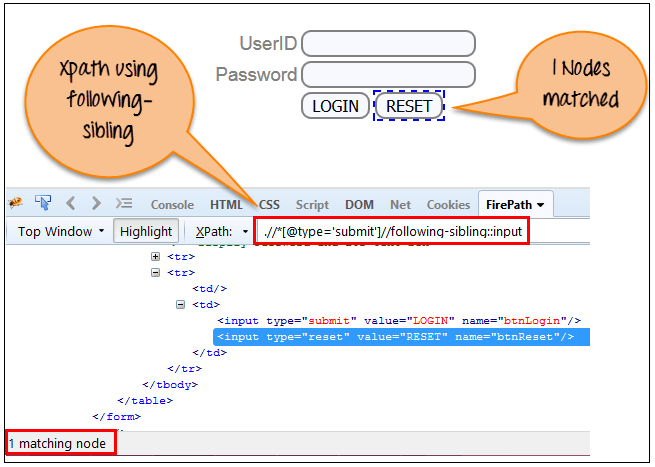{kind=link}
一個輸入節點通過使用 “跟隨兄弟” 軸進行匹配。
f)父節點
選擇當前節點的父節點,如下圖所示:
Xpath=//*[@id='rt-feature']//parent::div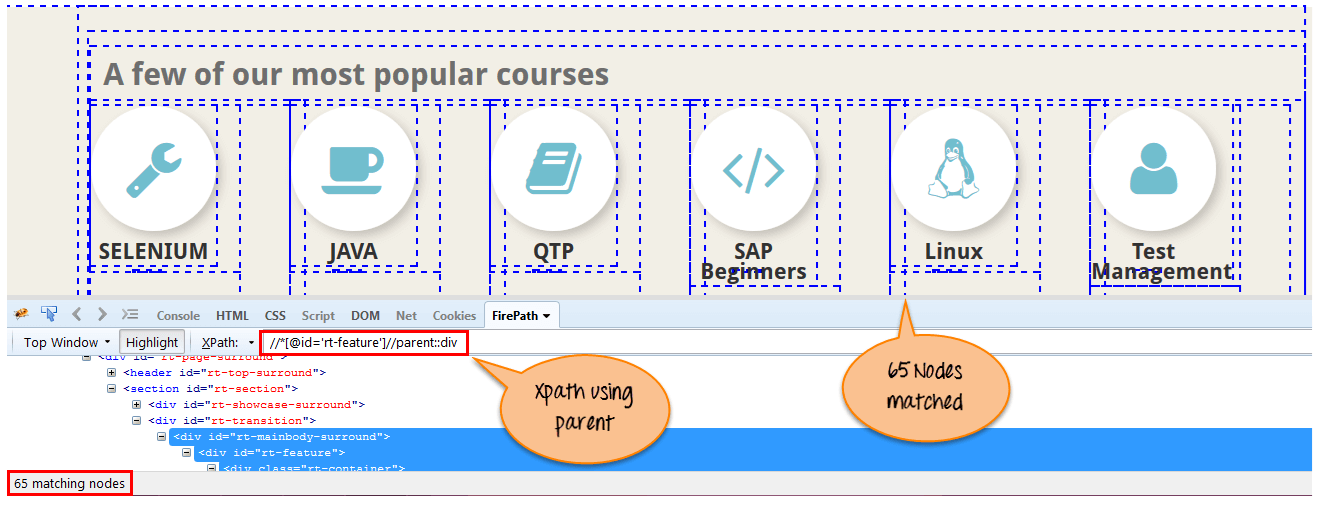{kind=link}
通過使用” 父節點” 軸匹配到 65 個”div” 節點。如果你想關注任意一個特定的元素那麼你可以使用下面的 XPath:
Xpath=//*[@id='rt-feature']//parent::div[1]您可以根據需要通過輸入 [1],[2]………… 來更改 XPath。
g)節點自身 (self)
選擇當前節點或者’self’意味著預示了節點本身,如下所示。
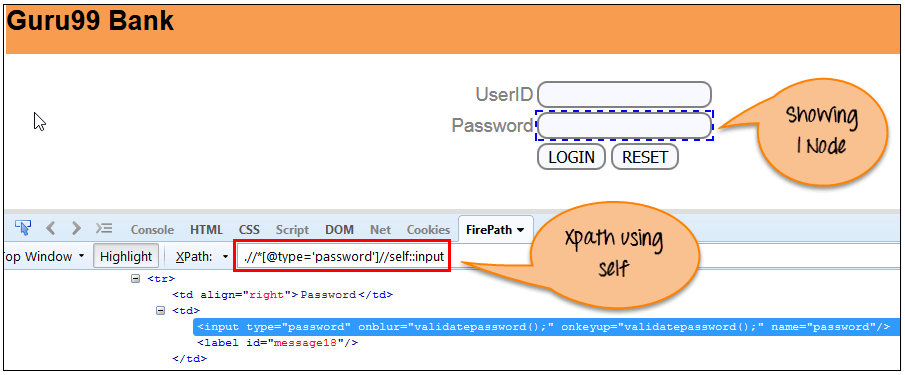{kind=link}
通過’self’軸匹配到一個節點。它總是隻找到一個節點,因為它代表了元素本身。
Xpath =//*[@type='password']//self::inputh)後裔節點
選擇當前節點的後代,如下螢幕所示。
在下面的表示式中,它標識當前元素(“主體環繞” 框架元素)的所有元素後代,這意味著向下位於節點(子節點,孫子節點等)下。
Xpath=//*[@id='rt-feature']//descendant::a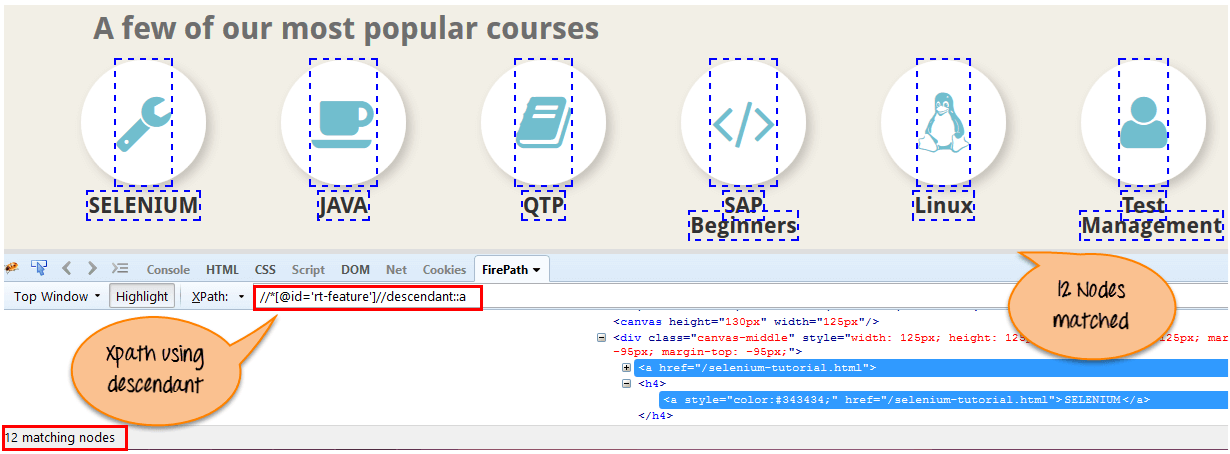{kind=link}
通過使用 “後代” 軸可以匹配 12 個 “link” 節點。 如果您想關注任何特定元素,則可以使用以下 XPath:
Xpath=//*[@id='rt-feature']//descendant::a[1]您可以根據需要通過輸入 [1],[2]………… 來更改 XPath。
總結:
需要 XPath 才能在網頁上查詢元素,以便對該特定元素執行操作。
- XPath 有兩種型別:
- 絕對 XPath
- 相對 XPath
- XPath 軸是用於查詢動態元素的方法,否則通常的 XPath 方法無法找到這些元素的。
- XPath 表示式根據 XML 文件中的 ID,Name,Classname 等屬性選擇節點或節點列表。