
[ Datawhale ] 計算機視覺下 —— Haar特徵描述運算元
Haar特徵描述運算元
經過前面的學習,個人對幾個基礎概念仍然有些模糊,比如說影象特徵、級聯分類器等,所以這篇筆記就結合這些天查閱到的知識點和Datawhale提供的學習內容一起記錄一下,會比較注重概念的理解,文字內容多一些~
影象特徵
實際上,計算機是不認識影象的,但倘若我們能夠將影象數字化地輸入計算機,它就能夠理解不同的影象,從而有真正意義上的視覺。所以在進行人臉檢測或者識別的過程中,需要關注的是如何從影象中提取出有用的資料或資訊,得到影象的“非影象”的表示或描述,比如常用的數值、向量等。這個過程就是特徵提取。而提取出來的特徵我們可以通過訓練過程教會計算機如何懂得這些特徵,從而使得計算機具備識別影象的能力。
基礎概念
特徵
嚴格上說,特徵是某一類物件區別於其他類物件的相應特點或特性。對於一幅影象而言,它自身的紋理、亮度等等,都可以成為區別於其他影象的自身特徵。當然有些特徵需要經過變換處理之後才能得到,需要我們轉換成直方圖等等。
特徵向量
如果現在我們想要表示一個抽象的物件,可以把這個物件的特徵們都組合在一起,形成一個特徵向量來表示。如果這個物體只有單個特徵,那特徵向量就是一個一維的向量。如果有n個特徵,那對應的,特徵向量將是一個n維的。
如下圖所示,左圖是一些在三維空間中的樣本點。假設這些樣本是鳶尾花,那麼三個座標軸可能分別代表花瓣的“長度”、“寬度”、“厚度”三個特徵,給出三者的分數後,便可在三維空間中詳細表示。例如,現在使用一個三維的特徵來代表一個植物物件,比如(5, 6.7, 1)。

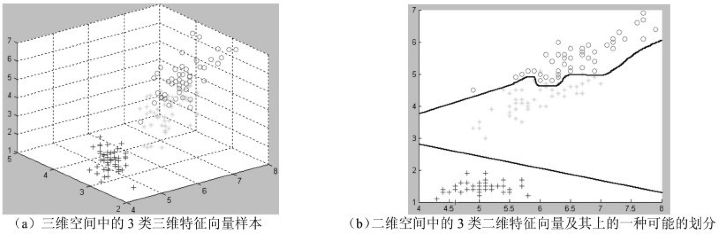{kind=link}
特徵提取原則
其實影象識別是一個分類的過程。我們需要識別出某影象所屬的類別,就需要將它和其他不同的影象區分開來。那麼這就要求選取的特徵不僅要能夠很好地描述影象,重要的是還要能夠很好地區分不同類別的影象。
我們更希望選擇那些在同類影象之間差異較小,但是在不同類別的影象之間差異較大的影象特徵作為我們的判斷標準,可以稱它們為是最有區分能力的特徵。
那麼重點來了,在特徵提取的過程中我們應該注意些什麼呢?
如果在分類過程中,僅僅是簡單地提取影象中所有畫素的灰度值作為特徵,雖然可以儘可能地提供資訊給分類器,但是高緯度意味著高計算複雜度,在後續的處理和識別中很容易導致維度災難。
所以,我們僅僅只需要將部分畫素資訊交給分類器就已經足夠了。
比如說,在表情識別的時候,我們並不需要膚色、面部輪廓等特徵,只要給出眉毛、眼睛、和嘴這些表情區域作為特徵提取的候選區,就已經完全足夠了。
評價標準
評價標準其實有一定的主觀性,但是還是有一些原則是可以普遍遵循的,比如說下面這幾點:
- 特徵應該容易提取,也就是說在提取的過程中不應該花費過多的代價。
- 選取的特徵應該對噪聲、不相關的轉換等操作不敏感。
- 尋找一個最具區分能力的特徵。
直方圖及其統計特徵
其實直方圖更多是作為一種輔助影象分析的工具,但它也可以作為影象紋理描述的一種強大手段。
筆者在上一篇部落格已經詳細闡述了影象紋理的概念及其特點,它具有一定的週期性。我們知道,紋理區域的畫素灰度級分佈具有一定的形式,而直方圖又恰好可以用來描述影象中畫素灰度級分佈的有力工具,所以我們當然可以使用直方圖來描述影象紋理咯~
那麼,毫無疑問的是,相似的紋理具有相似的直方圖,也就可以說明,直方圖和紋理之間存在一定的對應關係。然後,經過分析可以想象到,直方圖本身就是一個向量,而向量的維數是直方圖統計的灰度級數,因此我們可以直接把這個直方圖形成的向量作為代表影象紋理的樣本特徵向量,交給分類器處理,就像LBP直方圖所做的工作那樣。
當然,還有其他思路,比如說從直方圖中提取出能夠描述自身的統計特徵,然後組合成樣本的特徵向量,這樣還可以降低特徵向量的維數。
級聯分類器
在上節的學習過程中,遇到了一個新的名詞,叫做級聯分類器。我不僅不知道它是個什麼東西,還老唸錯它的名字,所以也找了一些資料,決定搞明白它到底是個啥玩意。
概念理解
通常情況下,分類器需要對多個影象特徵進行識別。比如在識別一個動物是狗還是其他動物的時候,可能需要根據多個條件進行判斷,如果首先就比較它們有幾條腿:
● 有“四條腿”的動物被判斷為“可能為狗”,並對此範圍內的物件繼續進行分析和判斷。
● 沒有“四條腿”的動物直接被否決,即不可能為狗。
這樣,僅僅比較腿的數目,根據這個特徵就能排除樣本集中大量的負類(例如雞、鴨、鵝等不是狗的其他動物例項)。
級聯分類器就是基於這種思路,將多個簡單的分類器按照一定的順序級聯而成的。
它將多個弱分類器串聯成了強分類器,其中弱分類器是一些效能受限的分類器,它們無法正確區分所有事物。而強分類器是可以正確地對資料進行分類的。之所以以弱分類器為基礎,是因為這種技術可以避免執行高精度的單一分類器所產生的問題。
如果一味強調分類器的精確度,可能會變成計算密集型且執行速度變慢。
級聯分類器的基礎示意圖如下圖所示:
優勢
在開始階段僅僅進行非常簡單的判斷,就能夠排除明顯不符合要求的樣本。那些在開始階段就被排除的負類,之後都不需要參與分類,只有正樣本才會送到下一個強分類器進行再次檢驗,這樣就保證了最後輸出的正樣本的偽正(false positive)的可能性非常低。這樣很大程度提高了後面分類的速度,而且每個弱分類器也不需要太精確。
Haar特徵及其級聯分類器
Haar特徵可以用來反映影象灰度變化,而使用該運算元進行人臉識別時,正是從人臉灰度變化角度考慮的。
概念與應用
研究者發現,從畫素的差值這個角度考慮,兩幅看似不相關的影象可能會存在一定的相關性。隨後提出的Haar特徵正是從這個角度出發,這些特徵包含了垂直特徵、水平特徵和對角特徵。根據特徵的特點,構建了特徵模版,使用某類模版可以判斷是否具備某類特徵。
Haar運算元如今普遍適用於行人檢測和人臉檢測中。
Haar特徵的計算
簡單的幾個Haar特徵如下圖所示,它主要反映的是影象的灰度變化(你品,你細品),它將畫素劃分為模組後求差值。其中特徵模版是用黑白兩種矩形框組合成特徵模版的。
在特徵模版中,用白色矩形畫素塊的畫素和減去黑色矩形畫素塊的畫素和來表示該模版的特徵。那麼經過上述處理之後,人臉部的一些特徵就可以使用矩形框的差值來簡單表示,其中公式如下:
\[T = \sum(白色區域畫素和) - \sum(黑色區域畫素和) \]
之所以可以使用haar運算元來識別某些面部特徵,是因為在我們的面部構造上存在了一些明顯的特點。
比如說眼睛的顏色比臉頰的顏色要深,那麼讓這兩者的區域畫素和做減法操作時,其差值就會比較大。但假如我們對兩個都是臉頰的區域做這樣的操作,顯然差值很小,有可能是0。那麼這樣眼睛區域和非眼睛區域就能夠使用差值的大小來進行區分了。
因此,經過分析發現,面部的這些特點使得有很多區域都可以藉助不同的模版來計算並區分。
同樣的,我們希望當把矩形放到人臉區域計算出來的特徵值和放到非人臉區域計算出來的特徵值差別越大越好,這樣我們就能夠用來區分人臉和非人臉了。
關於Harr特徵中的矩形框,有如下3個變數。
● 矩形位置:矩形框要逐畫素地劃過(遍歷)整個影象獲取每個位置的差值。
● 矩形大小:矩形的大小可以根據需要做任意調整。
● 矩形型別:包含垂直、水平、對角等不同型別。
上述3個變數保證了能夠細緻全面地獲取影象的特徵資訊。
積分圖
前面說到,計算haar特徵之前,要先計算兩塊區域的和,再算它們之間的差。
都說程式設計師是最知道偷懶的,他們發現光是計算區域和也好累,因為如果我們細緻全面地獲取影象的特徵資訊,使用不同的矩形進行特徵提取,若同一個畫素包含在不同的重疊矩形區域中會被多次遍歷,導致計算量加大。
所以學者們又提出了簡化Haar特徵的方法,也就引出了積分圖的計算。假設現在有一張圖,如下圖所示:
如果需要計算影象中任意矩形區域的大小,不需要遍歷區域內的所有畫素。
想象下圖中左上的點和任何相對的點P形成的矩形。設AP表示這個矩形的面積。如前圖所示,AB表示通過取左上角點和相對的B點形成的5×2矩形的面積。為了清楚起見,看一下下圖:
上圖中的左上部分,著色畫素表示左上角與點A之間的區域。這個區域用AA表示,剩下的圖用AB、AC、AD表示。若想計算上圖ABCD區域,將使用下列公式:
\[T_{ABCD} = T_{AC} - (T_{AB} + T_{AD} - T_{AA}) \]
這種特定的公式有什麼特別的地方嗎?
⚠️ 實際上我們知道,提取影象的Haar特徵需要計算多個尺度矩形的和。而這些計算是重複的,因為反覆遍歷了同一個畫素。那麼上面這種方法藉助了動態規劃的思想,避免了對同一個位置的重複計算,極大地節省了時間開銷。
Haar級聯分類器
這下總算能具體說說Haar級聯分類器到底是什麼,應該怎麼使用的了!!其實這部分的內容,助教給的學習資料已經很清楚了,甚至很多影象處理的書都沒他講的明白。。
簡單地說,在進行人臉檢測的過程中,需要使用一個強分類器,且其由多個弱分類器組成。那麼其中的每個弱分類器都只包含一個Haar特徵。每個分類器都將確定一個閾值,如果某區域的處理差值小於該閾值,則被歸為負類,反之則進行下一級的弱分類,最終經過多個弱分類器後,可完成檢測。其分類過程如下圖所示:
那麼接下來,再具體地說明執行過程:
- 首先,對於一幅影象,它可能存在K個面部特徵,假設這些面部特徵可以用來區分眼睛、眉毛、鼻子、嘴等特徵。
- 確定一些超引數,如滑動視窗的大小,及視窗的移動步長。視窗從上往下,從左向右地滑動。在滑動的過程中,每次都可以計算出一個數值\(K\)。
- 滑動結束時,將得到的特徵值進行排序,並選取一個最佳特徵值(最優閾值),使得在該特徵值下,對於該特徵而言,樣本的加權錯誤率最低。這樣就訓練出了一個弱分類器。
- 因為面部特徵的不同,我們將採用不同的滑動視窗進行特徵提取。所以根據不同的視窗識別不同的特徵,進而訓練出了不同的弱分類器。
- 對於每個弱分類器都將計算它的錯誤率,選擇錯誤率最低的K個弱分類器,組合成強分類器。
- 一組樣本投入強分類器後,在每個漸進的階段,分類器逐漸在較少的影象視窗上使用更多的特徵(負類被丟棄)。如果某個矩形區域在所有弱分類器中都被歸結為正類,那麼可以認為該區域是存在人臉的。
其中,弱分類器訓練的具體步驟如下:
1、對於每個特徵