
JVM(完成度95%,不斷更新)
一、HotSpot
HotSpot是最新的虛擬機器器,替代了JIT,提高Java的執行效能。Java原先是將原始碼編譯為位元組碼在虛擬機器器執行,HotSpot將常用的部分程式碼編譯為原生程式碼。
物件建立過程
| 類載入 |
|---|
| 分配記憶體 |
| 初始化 |
| 設定物件頭 |
| 執行init |
物件的記憶體佈局
| 物件頭 | 記錄一個物件的例項名字、ID和例項狀態
普通物件佔用 8 bytes,陣列佔用 12 bytes (8 bytes 的普通物件頭 + 4 bytes 的陣列長度)
| 1.第一部分用於儲存物件自身的執行時資料,如雜湊碼、GC分代年齡、鎖狀態標誌、執行緒持有的鎖、偏向執行緒ID、偏向時間戳等,官方稱為“Mark Word”。 |
|---|
| 基本型別 |
| 引用型別 |
| 對齊填充物 |
計算 User 物件佔用空間大小?
User 物件有兩個屬性,一個 int 型別的 id 佔用 4 bytes,一個引用型別的 name 佔用 4bytes,在加上 8 bytes 的物件頭,正好是 16 bytes
物件的訪問
Java程式需要通過JVM棧上的引用訪問堆中的具體例項
| 方法 | 概念 | 優點 |
|---|---|---|
| 控制程式碼 | 堆中劃分一塊記憶體作為控制程式碼池,引用中存放物件的控制程式碼地址,控制程式碼池中存放物件例項的指標以及物件類資訊的指標。 |
引用中存放的是穩定的控制程式碼地址,當物件移動時,引用本身不需要修改 |
| 直接指標 | 引用中存放的是物件的地址,物件的類資訊指標也存在例項中。 如果使用直接指標訪問,那麼Java堆物件的佈局中就必須考慮如何放置訪問型別資料的相關資訊,而reference中儲存的直接就是物件地址。  |
速度更快,節省了一次指標定位的時間開銷 (HotSpot採用該方式) |
二、類載入機制
虛擬機器器將編譯好的位元組碼檔案載入進JVM記憶體,也就是執行時資料區,並對資料進行校驗、解析、初始化,然後由執行引擎將位元組碼指令轉為底層系統指令。類載入器只負責載入,不負責執行。
原理
Java中的所有類,都是有誤類載入器載入到JVM然後執行的,類載入器本身也是一個類,負責將class檔案從硬碟載入到記憶體。
類載入器
概念:通過類的全限定類名獲取該類的二進位制位元組流。
| 啟動類載入器BootStrap | 用於載入java核心類庫,lib下的jar包的類,提供初始化環境,比如Object、String |
|---|---|
| 擴充套件類載入器Extension | 用於載入Java的擴充套件庫,JavaX包下的類,比如swing、awt等 |
| 應用程式類載入器Application | 用於載入應用類路徑classpath下的類,比如自己定義的Hello.class類 |
| 使用者自定義類載入器 | 通過繼承java.lang.ClassLoader實現 |
類載入過程
| 載入 | 類載入器載入class檔案到記憶體 |
|---|---|
| 驗證 | 驗證class檔案的正確性,class檔案的開頭有特定的標識 --> cafe babe |
| 準備 | 給類中的靜態變數分配記憶體空間並且初始預設值 |
| 解析 | 將類常量池中的符號引用解析為直接引用 |
| 初始化 | 初始化階段就是類的構造器方法的執行過程,該方法是由編譯器自動收集類中的所以類變數的賦值動作以及靜態程式碼塊中的語句合成的,其中編譯器收集的順序是由語句在原始檔中出現的順序決定的。 |
類初始化時機
| 主動引用 右邊幾種方式會觸發類的初始化 |
使用new關鍵字例項化物件時 |
|---|---|
| 呼叫一個類的靜態方法時 | |
| 使用反射獲取物件時,如果物件沒有初始化,會先進行初始化 | |
| 當初始化一個類時,如果父類還沒初始化,會先初始化父類 | |
| 虛擬機器器啟動時,會先初始化主類(main方法) | |
| 被動引用 右邊幾種方式不會觸發類的初始化 |
通過子類呼叫父類的靜態欄位,子類不會初始化 |
| 通過陣列引用類,不會觸發此類的初始化 | |
| 呼叫類的常量,不會觸發類初始化,因為常量是存在類的常量池中,會轉為呼叫常量的那個類中 |
例項初始化過程
- 父類的類構造器clinit
- 子類的類構造器clinit
- 父類的例項變數和例項程式碼塊
- 父類的建構函式
- 子類的例項變數和例項程式碼塊
- 子類的建構函式
如果一個類的成員變數用static修飾,則它被稱為類變數(靜態變數),否則它被稱為例項變數。
Java的例項變數和例項程式碼塊都是按照順序執行的,並且例項變數和例項程式碼塊優先於建構函式執行。
java的靜態變數和靜態程式碼塊是按照順序執行的。
例項初始化不一定要在類初始化結束之後才開始初始化,比如static StaticDemo st=new StaticDemo(); 實際上是把例項初始化嵌入到了靜態初始化流程中。
雙親委派機制
| 概念 | 好處 |
|---|---|
| 當一個類收到了類載入請求,他首先不會嘗試自己去載入這個類,而是把這個請求委派給父類去完成,每一個層次類載入器都是如此,因此所有的載入請求都應該傳送到啟動類載入其中,只有當父類載入器反饋自己無法完成這個請求的時候(在它的載入路徑下沒有找到所需載入的Class),子類載入器才會嘗試自己去載入。 採用雙親委派的一個好處是比如載入位於 rt.jar 包中的類 java.lang.Object,不管是哪個載入器載入這個類,最終都是委託給頂層的啟動類載入器進行載入,這樣就保證了使用不同的類載入器最終得到的都是同樣一個 Object物件。 |
沙箱機制: 保證類的唯一性,防止自己寫的程式碼汙染Java原生的方法。 比如自定義一個java.lang,String類,JVM從Bootstrap啟動器開始尋找String類,但是其中找不到我們寫的方法,這就會丟擲ClassNotFoundException |
三、JVM記憶體結構圖
執行流程圖(精簡)

執行流程圖(詳細)

JDK7、8記憶體空間區別

四、程式計數器
執行緒私有
程式計數器(Program Counter Register)是一塊較小的記憶體空間,它可以看作是當前執行緒所執行的位元組碼的行號指示器。在Java虛擬機器器的概念模型裡,位元組碼直譯器工作時就是通過改變這個計數器 的值來選取下一條需要執行的位元組碼指令,它是程式控制流的指示器,分支、迴圈、跳轉、異常處 理、執行緒恢復等基礎功能都需要依賴這個計數器來完成。
由於Java虛擬機器器的多執行緒是通過執行緒輪流切換、分配處理器執行時間的方式來實現的,在任何一個確定的時刻,一個處理器(對於多核處理器來說是一個核心)都只會執行一條執行緒中的指令。因 此,為了執行緒切換後能恢復到正確的執行位置,每條執行緒都需要有一個獨立的程式計數器,各條執行緒 之間計數器互不影響,獨立儲存,我們稱這類記憶體區域為“執行緒私有”的記憶體。
如果執行緒正在執行的是一個Java方法,這個計數器記錄的是正在執行的虛擬機器器位元組碼指令的地址;
如果正在執行的是本地(Native)方法,這個計數器值則應為空(Undefined)。
此記憶體區域是唯一一個在《Java虛擬機器器規範》中沒有規定任何OutOfMemoryError情況的區域。
可以使用javap 來檢視類的位元組碼檔案
程式計數器在當前指令執行時記錄下一個指令的標記,方便當前指令完成後快速切換

五、Java虛擬機器器棧
執行緒私有
**_棧負責執行、堆負責儲存 _
棧也叫棧記憶體,主管Java程式的執行,是線上程建立時建立,它的生命期是跟隨執行緒的生命期,執行緒結束棧記憶體也就釋放,對於棧來說不存在垃圾回收問題,只要執行緒一結束該棧就Over,生命週期和執行緒一致,是執行緒私有的。8種基本型別的變數+物件的引用變數+例項方法都是在函式的棧記憶體中分配。
儲存的資料型別
方法==棧幀
| 方法的本地變數(Local Variables) | 輸入引數和輸出引數以及方法內的變數 |
|---|---|
| 棧操作(Operand Stack) | 記錄出棧、入棧的操作;類似PC暫存器、計數器) |
| 棧幀資料(Frame Data) | 包括類檔案(方法裡面可以寫新的類)、方法等等 |
記憶體結構
棧中的資料都是以棧幀(Stack Frame)的格式存在,棧幀是一個記憶體區塊,是一個資料集,是一個有關方法(Method)和執行期資料的資料集。
每個方法執行的同時都會建立一個棧幀,用於儲存區域性變量表、運算元棧、動態連結、方法出口等資訊,每一個方法從呼叫直至執行完畢的過程,就對應著一個棧幀在虛擬機器器中入棧到出棧的過程。棧的大小和具體JVM的實現有關,通常在256K~756K之間,約等於1Mb左右。
“棧”通常就是指這裡講的虛擬機器器棧,或者更多的情況下只是指虛擬機器器棧中區域性變量表部分。
| 區域性變量表 |
區域性變量表存放了編譯期可知的各種Java虛擬機器器基本資料型別(boolean、byte、char、short、int、float、long、double)、物件引用(reference型別,它並不等同於物件本身,可能是一個指向物件起始地址的引用指標,也可能是指向一個代表物件的控制程式碼或者其他與此物件相關的位置)和returnAddress型別(指向了一條位元組碼指令的地址)。
| 這些資料型別在區域性變量表中的儲存空間以區域性變數槽(Slot)來表示。 long、double等64位資料型別佔兩個變數槽 其餘資料型別佔一個 區域性變量表所需的記憶體空間在編譯期間完成分配,當進入一個方法時,這個方法需要在棧幀中分配多大的區域性變數空間是完全確定的,在方法執行期間不會改變區域性變量表的大小。這裡說的“大小”是指變數槽的數量,虛擬機器器真正使用多大的記憶體空間(譬如按照1個變數槽佔用32個位元、64個位元,或者更多)來實現一個變數槽,這是完全由具體的虛擬機器器實現自行決定的事情。 |
|---|
| 運算元棧 |
| 動態連結 |
| 方法出口 |
執行順序
先進後出原則(彈夾)
棧中的資料都是以棧幀(Stack Frame)的格式存在,棧幀是一個記憶體區塊,是一個資料集,是一個有關方法(Method)和執行期資料的資料集,當一個函式1被呼叫時就產生了一個棧幀 1,並被壓入到棧中, 1方法又呼叫了 2方法,於是產生棧幀 2 也被壓入棧, 2方法又呼叫了 3方法,於是產生棧幀 3 也被壓入棧 …… 執行完畢後,先彈出5棧幀,再彈出4棧幀……最後彈出1棧幀……

☆堆、棧、方法區的互動關係
HotSpot是使用指標的方式來訪問物件:
Java堆中會存放訪問類元資料的地址(方法區)
reference儲存的就直接是物件的地址 


常見錯誤產生原因
| StackOverFlowError | 執行緒請求的棧深度大於虛擬機器器允許的深度時則報此錯 |
|---|---|
| OutOfMemoryError | 如果虛擬機器器棧容量可以動態擴充套件,當棧擴充套件時無法申請到足夠的記憶體則報此錯 |
_
六、本地方法棧&本地方法介面
本地方法棧:****執行緒私有
本地方法棧(Native Method Stacks)與虛擬機器器棧所發揮的作用是非常相似的,其區別只是虛擬機器器棧為虛擬機器器執行Java方法(也就是位元組碼)服務,而本地方法棧則是為虛擬機器器使用到的本地(Native)方法服務。
因此具體的虛擬機器器可以根據需要自由實現它,甚至有的Java虛擬機器器(譬如Hot-Spot虛擬機器器)直接就把本地方法棧和虛擬機器器棧合二為一。
與虛擬機器器棧一樣,本地方法棧也會在棧深度溢位或者棧擴充套件失敗時分別丟擲StackOverflowError和OutOfMemoryError異常。
本地介面的作用是融合不同的程式語言為 Java 所用,它的初衷是融合 C/C++程式,Java 誕生的時候是 C/C++橫行的時候,要想立足,必須有呼叫 C/C++程式,於是就在記憶體中專門開闢了一塊區域處理標記為native的程式碼,它的具體做法是 Native Method Stack中登記 native方法,在Execution Engine 執行時載入native libraies。 目前該方法使用的越來越少了,除非是與硬體有關的應用,比如通過Java程式驅動印表機或者Java系統管理生產裝置,在企業級應用中已經比較少見。因為現在的異構領域間的通訊很發達,比如可以使用 Socket通訊,也可以使用Web Service等等
本地方法介面:****執行緒共享
它的具體做法是Native Method Stack中登記native方法,在Execution Engine 執行時載入本地方法庫。
七、方法區
執行緒共享(有少量GC)
1.它儲存了每一個類的結構資訊,例如執行時常量池(Runtime Constant Pool)、欄位和方法資料、建構函式和普通方法的位元組碼內容。
2.方法區是規範,在不同虛擬機器器裡頭實現是不一樣的,最典型的就是永久代(PermGen space)和元空間(Metaspace)。
3.例項變數存在堆記憶體中,和方法區無關
方法區記憶體的資料型別
八、堆空間
一個JVM例項只存在一個堆記憶體,堆記憶體的大小是可以調節的。類載入器讀取了類檔案後,需要把類、方法、常變數放到堆記憶體中,儲存所有引用型別的真實資訊,以方便執行器執行。
記憶體結構
| Young Generation Space | 新生區 Young/New (新生區還分伊甸區、倖存者0、1區) |
|---|---|
| Tenure generation space | 養老區 Old/Tenure |
| MetaSpace/Permanent Space | 元空間/永久區 MetaSpace/Perm (元空間JDK8出來後替代永久區) |
- 邏輯上劃分:新生區+養老區+元空間
- 物理上劃分:新生區+養老區
- 元空間存在堆記憶體外的實體記憶體空間中。

MinorGC的過程(複製->清空->互換)
| ①eden、SurvivorFrom 複製到 SurvivorTo,年齡+1 | 首先,當Eden區滿的時候會觸發第一次GC,把還活著的物件拷貝到SurvivorFrom區,當Eden區再次觸發GC的時候會掃描Eden區和From區域,對這兩個區域進行垃圾回收,經過這次回收後還存活的物件,則直接複製到To區域(如果有物件的年齡已經達到了老年的標準,則賦值到老年代區),同時把這些物件的年齡+1 |
|---|---|
| ②清空 eden、SurvivorFrom | 然後,清空Eden和SurvivorFrom中的物件,也即複製之後有交換,誰空誰是to |
| **③SurvivorTo和 SurvivorFrom 互換 ** | 最後,SurvivorTo和SurvivorFrom互換,原SurvivorTo成為下一次GC時的SurvivorFrom區。部分物件會在From和To區域中複製來複制去,如此交換15次(由JVM引數MaxTenuringThreshold決定,這個引數預設是15),最終如果還是存活,就存入到老年代 |
真相:98%的物件是臨時物件,不會進入到old區
物件進入老年代規則
- 躲過15次GC之後進入老年代(-XX:MaxTenuringThreshold設定)
- 大物件直接進入老年代(-XX:PretenureSizeThreshold設定)
- 動態物件年齡判斷(年齡1+年齡2+年齡n的多個年齡物件總和超過了Survivor區域的50%,此時就會把年齡n以上的物件都放入老年代)
- Gc物件太多無法放入Survivor區,會將這些物件放到老年代 (通過老年代空間分配擔保規則)
New物件GC流程、老年代空間分配擔保規則

常量池的區別
| **常量池/class常量池 **
**(Constant Pool) ** | java檔案被編譯成 class檔案,class檔案中除了包含類的版本、欄位、方法、介面等描述資訊外,還有一項就是常量池(Constant Pool),用於存放編譯器生成的各種字面量( Literal )和 符號引用(Symbolic References)。
 |
|---|
| 字串常量池/全域性字串池 (String Pool) |
| 執行時常量池 (Runtime Constant Pool) |
符號、直接引用
| 符號引用 | 符號引用以一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要使用時能無歧義地定位到目標即可。符號引用與虛擬機器器實現的記憶體佈局無關,引用的目標並不一定已經載入到記憶體中。 一般包含以下三類常量 - 類和介面的全限定名 - 欄位的名稱和描述符 - 方法的名稱和描述符 |
|---|---|
| 直接引用 | 直接引用可以使直接指向目標的指標、相對偏移量或是一個能間接定位到目標的控制程式碼。直接引用是與虛擬機器器實現的記憶體佈局相關的,同一個符號引用在不同虛擬機器器例項上翻譯出來的直接引用一般不會相同。如果有了直接引用,那引用的目標必定已經在記憶體中存在。 |
字面量、常量、變數
int a; //變數
const int b = 10; //b為常量,10為字面量
string str = “hello world!”; // str 為變數,hello world!為字面量
字面量是指由字母,數字等構成的字串或者數值,它只能作為右值出現,(右值是指等號右邊的值,如:int a=123這裡的a為左值,123為右值。)
常量和變數都屬於變數,只不過常量是賦過值後不能再改變的變數,而普通的變數可以再進行賦值操作。
元空間
元空間是方法區的是實現
| Klass MetaSpace | Klass Metaspace就是用來存klass的,klass是我們熟知的class檔案在jvm裡的執行時資料結構,不過有點要提的是我們看到的類似A.class其實是存在heap裡的,是java.lang.Class的一個物件例項。這塊記憶體是緊接著Heap的,和我們之前的perm一樣,這塊記憶體大小可通過-XX:CompressedClassSpaceSize引數來控制,這個引數前面提到了預設是1G,但是這塊記憶體也可以沒有,假如沒有開啟壓縮指標就不會有這塊記憶體,這種情況下klass都會存在NoKlass Metaspace裡,另外如果我們把-Xmx設定大於32G的話,其實也是沒有這塊記憶體的,因為會這麼大記憶體會關閉壓縮指標開關。還有就是這塊記憶體最多隻會存在一塊。 |
|---|---|
| NoKlass MetaSpace | NoKlass Metaspace專門來存klass相關的其他的內容,比如method,constantPool等,這塊記憶體是由多塊記憶體組合起來的,所以可以認為是不連續的記憶體塊組成的。這塊記憶體是必須的,雖然叫做NoKlass Metaspace,但是也其實可以存klass的內容,上面已經提到了對應場景。 |
Klass Metaspace和NoKlass Mestaspace都是所有classloader共享的,所以類載入器們要分配記憶體,但是每個類載入器都有一個SpaceManager,來管理屬於這個類載入的記憶體小塊。如果Klass Metaspace用完了,那就會OOM了,不過一般情況下不會,NoKlass Mestaspace是由一塊塊記憶體慢慢組合起來的,在沒有達到限制條件的情況下,會不斷加長這條鏈,讓它可以持續工作。
元空間的特點
- 充分利用了Java語言規範中的好處:類及相關的元資料的生命週期與類載入器的一致。
- 每個載入器有專門的儲存空間
- 只進行線性分配
- 不會單獨回收某個類
- 省掉了GC掃描及壓縮的時間
- 元空間裡的物件的位置是固定的
- 如果GC發現某個類載入器不再存活了,會把相關的空間整個回收掉
常見錯誤產生原因
如果出現java.lang.OutOfMemoryError: Java heap space異常,說明Java虛擬機器器的堆記憶體不夠。原因有二:
(1)Java虛擬機器器的堆記憶體設定不夠,可以通過引數-Xms、-Xmx來調整。
(2)程式碼中建立了大量大物件,並且長時間不能被垃圾收集器收集(存在被引用)。
九、垃圾回收
GC垃圾回收的主要作用域是方法區、****堆記憶體空間
垃圾回收演演算法總覽

垃圾回收演演算法圖形化流程



垃圾回收器
| Serial 序列垃圾回收器 |
序列垃圾回收器,它為單執行緒環境設計且值使用一個執行緒進行垃圾收集,會暫停所有的使用者執行緒,只有當垃圾回收完成時,才會重新喚醒主執行緒繼續執行。所以不適合伺服器環境 |  |
|---|---|---|
| Parallel 並行垃圾回收器 |
並行垃圾收集器,多個垃圾收集執行緒並行工作,此時使用者執行緒也是阻塞的,適用於科學計算 / 大資料處理等弱互動場景,也就是說Serial 和 Parallel其實是類似的,不過是多了幾個執行緒進行垃圾收集,但是主執行緒都會被暫停,但是並行垃圾收集器處理時間,肯定比序列的垃圾收集器要更短 注意:並行垃圾回收在_單核_CPU下可能會更慢 |
 |
| CMS 併發標記清除 回收器 |
併發標記清除,使用者執行緒和垃圾收集執行緒同時執行(不一定是並行,可能是交替執行),不需要停頓使用者執行緒,網際網路公司都在使用,適用於響應時間有要求的場景。併發是可以有互動的,也就是說可以一邊進行收集,一邊執行應用程式。 |
這是一種以最短回收停頓時間為目標的收集器
適合應用在網際網路或者B/S系統的伺服器上,這類應用尤其重視伺服器的響應速度,希望系統停頓時間最短。
CMS非常適合堆記憶體大,CPU核數多的伺服器端應用,也是G1出現之前大型應用的首選收集器 |  |
|
| | 優點:併發收集低停頓
缺點:併發執行,對CPU資源壓力大,採用的標記清除演演算法會導致大量碎片
由於併發進行,CMS在收集與應用執行緒會同時增加對堆記憶體的佔用,也就是說,CMS必須在老年代堆記憶體用盡之前完成垃圾回收,否則CMS回收失敗時,將觸發擔保機制,序列老年代收集器將會以STW方式進行一次GC,從而造成較大的停頓時間
CMS無法整理空間碎片,老年代空間會隨著應用時長被逐步耗盡,最後將不得不通過擔保機制對堆記憶體進行壓縮,CMS也提供了引數 -XX:CMSFullGCSBeForeCompaction(預設0,即每次都進行記憶體整理)來指定多少次CMS收集之後,進行一次壓縮的Full GC | 四個步驟
- 初始標記(CMS initial mark)
- 只是標記一個GC Roots 能直接關聯的物件,速度很快,仍然需要暫停所有的工作執行緒
併發標記(CMS concurrent mark)和使用者執行緒一起
- 進行GC Roots跟蹤過程,和使用者執行緒一起工作,不需要暫停工作執行緒。主要標記過程,標記全部物件重新標記(CMS remark)
- 為了修正在併發標記期間,因使用者程式繼續執行而導致標記產生變動的那一部分物件的標記記錄,仍然需要暫停所有的工作執行緒,由於併發標記時,使用者執行緒依然執行,因此在正式清理前,在做修正併發清除(CMS concurrent sweep)和使用者執行緒一起
- 清除GC Roots不可達物件,和使用者執行緒一起工作,不需要暫停工作執行緒。基於標記結果,直接清理物件,由於耗時最長的併發標記和併發清除過程中,垃圾收集執行緒可以和使用者現在一起併發工作,所以總體上來看CMS收集器的記憶體回收和使用者執行緒是一起併發地執行。
|
|
G1垃圾回收器
JDK9預設 | G1垃圾回收器將堆記憶體分割成不同區域,然後併發的進行垃圾回收 |  |
|
| ZGC垃圾回收器
JDK11預設 | zgc是為大記憶體、多cpu而生,它通過分割槽的思路來降低STW,比如原來我有一個巨大的房間需要打掃衛生,每打掃一次就需要很長時間的STW,因為房間太大了,後來我改變了思路,把這個巨大的房間打隔斷,最終出來100個小房間,這些小房間可以是eden區、可以是s區、也可以是old區,沒有固定,每次只選擇最需要打掃的房間(垃圾最多的)進行打掃,最終把這個房間的存活物件轉移到其它房間,同時其它房間還可以繼續供客戶使用,也就是並行、併發的打掃,只在某幾個必須的階段進行很短暫的STW,其它時間都是和使用者執行緒並行工作,這樣可以很好的控制STW時間,同時也因為佔用了很多cpu時間併發幹活導致吞吐量降低,所以如果硬體充足的情況下 可以考慮 ZGC。 | |
預設垃圾回收器
使用下面JVM命令,檢視配置的初始引數
-XX:+PrintCommandLineFlags
然後執行一個程式後,能夠看到它的一些初始配置資訊
-XX:InitialHeapSize=266376000 -XX:MaxHeapSize=4262016000 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
-XX:+UseParallelGC
移動到最後一句,就能看到 -XX:+UseParallelGC 說明使用的是並行垃圾回收
-XX:+UseParallelGC
垃圾收集器
Java中一共有7大垃圾收集器
- UserSerialGC:序列垃圾收集器
- UserParallelGC:並行垃圾收集器
- UseConcMarkSweepGC:(CMS)併發標記清除
- UseParNewGC:年輕代的並行垃圾回收器
- UseParallelOldGC:老年代的並行垃圾回收器
- UseG1GC:G1垃圾收集器
- UserSerialOldGC:序列老年代垃圾收集器(已經被移除)
**
垃圾收集器使用範圍
引數說明
- DefNew:Default New Generation
- Tenured:Old
- ParNew:Parallel New Generation
- PSYoungGen:Parallel Scavenge
- ParOldGen:Parallel Old Generation
G1垃圾收集器各區都能使用
| 新生代 | 老年代 |
|---|---|
| - Serial Copying: UserSerialGC,序列垃圾回收器 |
ParNew:UserParNewGC,新生代並行垃圾收集器
- Parallel Scavenge:UserParallelGC,並行垃圾收集器
|
- Serial Old:UseSerialOldGC,老年代序列垃圾收集器Parallel Compacting(Parallel Old):UseParallelOldGC,老年代並行垃圾收集器
CMS:UseConcMarkSwepp,並行標記清除垃圾收集器
|


垃圾收集器組合選擇、引數配置
- 單CPU或者小記憶體,單機程式
- -XX:+UseSerialGC
- 多CPU,需要最大的吞吐量,如後臺計算型應用
- -XX:+UseParallelGC(這兩個相互啟用)
- -XX:+UseParallelOldGC
- 多CPU,追求低停頓時間,需要快速響應如網際網路應用
- -XX:+UseConcMarkSweepGC
- -XX:+ParNewGC
| 引數 | 新生代垃圾收集器 | 新生代演演算法 | 老年代垃圾收集器 | 老年代演演算法 |
| -XX:+UseSerialGC | SerialGC | 複製 | SerialOldGC | 標記整理 |
|---|---|---|---|---|
| -XX:+UseParNewGC | ParNew | 複製 | SerialOldGC | 標記整理 |
| -XX:+UseParallelGC | Parallel [Scavenge] | 複製 | Parallel Old | 標記整理 |
| -XX:+UseConcMarkSweepGC | ParNew | 複製 | CMS + Serial Old的收集器組合,Serial Old作為CMS出錯的後備收集器 | 標記清除 |
| -XX:+UseG1GC | G1整體上採用標記整理演演算法 | 區域性複製 |
引數配置
G1垃圾收集器
開啟G1垃圾收集器
-XX:+UseG1GC
以前收集器的特點
- 年輕代和老年代是各自獨立且連續的記憶體塊
- 年輕代收集使用單eden + S0 + S1 進行復制演演算法
- 老年代收集必須掃描珍整個老年代區域
- 都是以儘可能少而快速地執行GC為設計原則
#### G1是什麼
Garbage-First 收集器,是一款面向服務端應用的收集器,應用在多處理器和大容量記憶體環境中,在實現高吞吐量的同時,儘可能滿足垃圾收集暫停時間的要求。另外,它還具有一下特徵:
- 像CMS收集器一樣,能與應用程式併發執行
- 整理空閒空間更快
- 需要更多的時間來預測GC停頓時間
- 不希望犧牲大量的吞吐量效能
- 不需要更大的Java Heap
G1收集器設計目標是取代CMS收集器,它同CMS相比,在以下方面表現的更出色
- G1是一個有整理記憶體過程的垃圾收集器,不會產生很多記憶體碎片。
- G1的Stop The World(STW)更可控,G1在停頓時間上添加了預測機制,使用者可以指定期望停頓時間。
CMS垃圾收集器雖然減少了暫停應用程式的執行時間,但是它還存在著記憶體碎片問題。於是,為了去除記憶體碎片問題,同時又保留CMS垃圾收集器低暫停時間的優點,JAVA7釋出了一個新的垃圾收集器-G1垃圾收集器
G1是在2012版本才在JDK1.7中可用,Oracle官方在JDK9中將G1變成預設的垃圾收集器以替代CMS,它是一款面向服務端應用的收集器,主要應用在多CPU和大記憶體伺服器環境下,極大減少垃圾收集的停頓時間,全面提升伺服器的效能,逐步替換Java8以前的CMS收集器
主要改變時:Eden,Survivor和Tenured等記憶體區域不再是連續了,而是變成一個個大小一樣的region,每個region從1M到32M不等。一個region有可能屬於Eden,Survivor或者Tenured記憶體區域。
特點
- G1能充分利用多CPU,多核環境硬體優勢,儘量縮短STW
- G1整體上採用標記-整理演演算法,區域性是通過複製演演算法,不會產生記憶體碎片
- 巨集觀上看G1之中不再區分年輕代和老年代。把記憶體劃分成多個獨立的子區域(Region),可以近似理解為一個圍棋的棋盤
- G1收集器裡面將整個記憶體區域都混合在一起了,但其本身依然在小範圍內要進行年輕代和老年代的區分,保留了新生代和老年代,但他們不再是物理隔離的,而是通過一部分Region的集合且不需要Region是連續的,也就是說依然會採取不同的GC方式來處理不同的區域
- G1雖然也是分代收集器,但整個記憶體分割槽不存在物理上的年輕代和老年代的區別,也不需要完全獨立的Survivor(to space)堆做複製準備,G1只有邏輯上的分代概念,或者說每個分割槽都可能隨G1的執行在不同代之間前後切換。
#### 底層原理
Region區域化垃圾收集器,化整為零,打破了原來新生區和老年區的壁壘,避免了全記憶體掃描,只需要按照區域來進行掃描即可。
區域化記憶體劃片Region,整體遍為了一些列不連續的記憶體區域,避免了全記憶體區的GC操作。
核心思想是將整個堆記憶體區域分成大小相同的子區域(Region),在JVM啟動時會自動設定子區域大小
在堆的使用上,G1並不要求物件的儲存一定是物理上連續的,只要邏輯上連續即可,每個分割槽也不會固定地為某個代服務,可以按需在年輕代和老年代之間切換。啟動時可以通過引數`-XX:G1HeapRegionSize=n` 可指定分割槽大小(1MB~32MB,且必須是2的冪),預設將整堆劃分為2048個分割槽。
大小範圍在1MB~32MB,最多能設定2048個區域,也即能夠支援的最大記憶體為:32MB*2048 = 64G記憶體
Region區域化垃圾收集器
Region區域化垃圾收集器
G1將新生代、老年代的物理空間劃分取消了,同時對記憶體區域進行了劃分
G1演演算法將堆劃分為若干個區域(Reign),它仍然屬於分代收集器,這些Region的一部分包含新生代,新生代的垃圾收集依然採用暫停所有應用執行緒的方式,將存活物件拷貝到老年代或者Survivor空間。
這些Region的一部分包含老年代,G1收集器通過將物件從一個區域複製到另外一個區域,完成了清理工作。這就意味著,在正常的處理過程中,G1完成了堆的壓縮(至少是部分堆的壓縮),這樣也就不會有CMS記憶體碎片的問題存在了。
在G1中,還有一種特殊的區域,叫做Humongous(巨大的)區域,如果一個物件佔用了空間超過了分割槽容量50%以上,G1收集器就認為這是一個巨型物件,這些巨型物件預設直接分配在老年代,但是如果他是一個短期存在的巨型物件,就會對垃圾收集器造成負面影響,為瞭解決這個問題,G1劃分了一個Humongous區,它用來專門存放巨型物件。如果一個H區裝不下一個巨型物件,那麼G1會尋找連續的H區來儲存,為了能找到連續的H區,有時候不得不啟動Full GC。
回收步驟
針對Eden區進行收集,Eden區耗盡後會被觸發,主要是小區域收集 + 形成連續的記憶體塊,避免內碎片
- Eden區的資料移動到Survivor區,加入出現Survivor區空間不夠,Eden區資料會晉升到Old區
- Survivor區的資料移動到新的Survivor區,部分資料晉升到Old區
- 最後Eden區收拾乾淨了,GC結束,使用者的應用程式繼續執行
小區域收集 + 形成連續的記憶體塊,最後在收集完成後,就會形成連續的記憶體空間,這樣就解決了記憶體碎片的問題
四步過程
- 初始標記:只標記GC Roots能直接關聯到的物件
- 併發標記:進行GC Roots Tracing(鏈路掃描)的過程
- 最終標記:修正併發標記期間,因為程式執行導致標記發生變化的那一部分物件
- 篩選回收:根據時間來進行價值最大化回收
引數配置
開發人員僅僅需要申明以下引數即可
三步歸納:-XX:+UseG1GC -Xmx32G -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=n:最大GC停頓時間單位毫秒,這是個軟目標,JVM儘可能停頓小於這個時間
G1和CMS比較
- G1不會產生內碎片
- 是可以精準控制停頓。該收集器是把整個堆(新生代、老年代)劃分成多個固定大小的區域,每次根據允許停頓的時間去收集垃圾最多的區域。
###
# 十、確定垃圾、什麼是GC Roots?
### 什麼是垃圾?
簡單來說就是記憶體中不再被使用的空間就是垃圾
### 如何判斷一個物件是否可以被回收
| 引用計數法 | Java中,引用和物件是有關聯的。如果要操作物件則必須用引用進行。
因此,很顯然一個簡單的辦法就是通過引用計數來判斷一個物件是否可以回收。簡單說,給物件中新增一個引用計數器
每當有一個地方引用它,計數器值加1
每當有一個引用失效,計數器值減1
任何時刻計數器值為零的物件就是不可能再被使用的,那麼這個物件就是可回收物件。
那麼為什麼主流的Java虛擬機器器裡面都沒有選用這個方法呢?其中最主要的原因是它很難解決物件之間相互迴圈引用的問題。
該演演算法存在但目前無人用了,解決不了迴圈引用的問題,瞭解即可。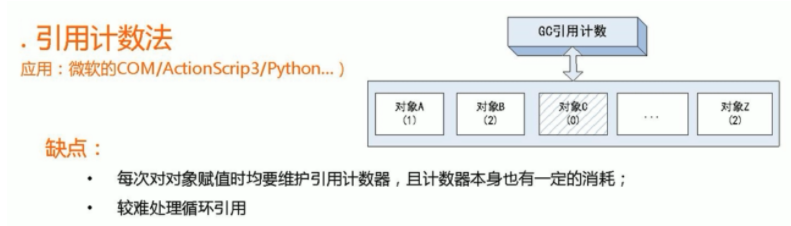 |
| --- | --- |
| 列舉根節點做可達性分析 | 為瞭解決引用計數法的迴圈引用個問題,Java使用了可達性分析的方法:
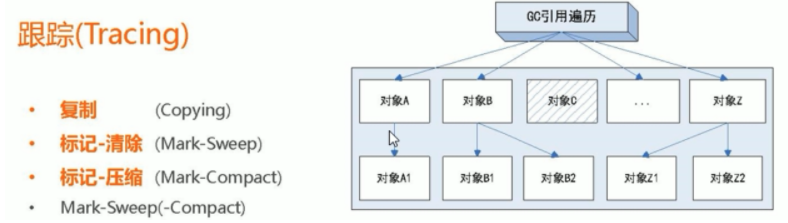
所謂 GC Roots 或者說 Tracing Roots的“根集合” 就是一組必須活躍的引用
基本思路就是通過一系列名為 GC Roots的物件作為起始點,從這個被稱為GC Roots的物件開始向下搜尋,如果一個物件到GC Roots沒有任何引用鏈相連,則說明此物件不可用。也即給定一個集合的引用作為根出發,通過引用關係遍歷物件圖,能被遍歷到的(可到達的)物件就被判定為存活,沒有被遍歷到的物件就被判定為死亡
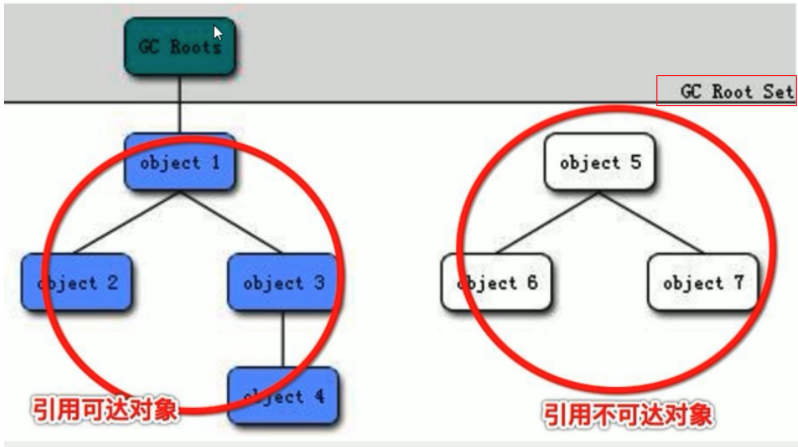
必須從GC Roots物件開始,這個類似於linux的 / 也就是根目錄
藍色部分是從GC Roots出發,能夠迴圈可達
而白色部分,從GC Roots出發,無法到達 |
| 可以被當做GC Roots的物件 |
- 虛擬機器器棧(棧幀中的區域性變數區,也叫做區域性變量表)中的引用物件
- 方法區中的類靜態屬性引用的物件
- 方法區中常量引用的物件
- 本地方法棧中的JNI(Native方法)的引用物件
|
GC前對於重寫的finalize方法的處理流程

一個案例理解GC Roots
假設我們現在有三個實體,分別是 人,狗,毛衣
然後他們之間的關係是:人 牽著 狗,狗穿著毛衣,他們之間是強連線的關係
有一天人消失了,只剩下狗狗 和 毛衣,這個時候,把人想象成 GC Roots,因為 人 和 狗之間失去了繩子連線,
那麼狗可能被回收,也就是被警察抓起來,被送到流浪狗寄養所
假設狗和人有強連線的時候,狗狗就不會被當成是流浪狗
/**
* 在Java中,可以作為GC Roots的物件有:
* - 虛擬機器器棧(棧幀中的區域性變數區,也叫做區域性變量表)中的引用物件
* - 方法區中的類靜態屬性引用的物件
* - 方法區中常量引用的物件
* - 本地方法棧中的JNI(Native方法)的引用物件
*/
public class GCRootDemo {
// 方法區中的類靜態屬性引用的物件
// private static GCRootDemo2 t2;
// 方法區中的常量引用,GC Roots 也會以這個為起點,進行遍歷
// private static final GCRootDemo3 t3 = new GCRootDemo3(8);
public static void m1() {
// 第一種,虛擬機器器棧中的引用物件
GCRootDemo t1 = new GCRootDemo();
System.gc();
System.out.println("第一次GC完成");
}
public static void main(String[] args) {
m1();
}
}
如何判斷常量、類被廢棄了

十一、強引用、軟引用、弱引用、虛引用
概念列表
| 強引用 StrongReference |
當記憶體不足的時候,JVM開始垃圾回收,對於強引用的物件,就算是出現了OOM也不會對該物件進行回收,打死也不回收~! 強引用是我們最常見的普通物件引用,只要還有一個強引用指向一個物件,就能表明物件還“活著”,垃圾收集器不會碰這種物件。在Java中最常見的就是強引用,把一個物件賦給一個引用變數,這個引用變數就是一個強引用。當一個物件被強引用變數引用時,它處於可達狀態,它是不可能被垃圾回收機制回收的,即使該物件以後永遠都不會被用到,JVM也不會回收,因此強引用是造成Java記憶體洩漏的主要原因之一。 對於一個普通的物件,如果沒有其它的引用關係,只要超過了引用的作用於或者顯示地將相應(強)引用賦值為null,一般可以認為就是可以被垃圾收集的了(當然具體回收時機還是要看垃圾回收策略) |
|
|---|---|---|
| 軟引用 SoftReference |
軟引用是一種相對弱化了一些的引用,需要用Java.lang.ref.SoftReference類來實現,可以讓物件豁免一些垃圾收集,對於只有軟引用的物件來講: - 當系統記憶體充足時,它不會被回收 |
- 當系統記憶體不足時,它會被回收
軟引用通常在對記憶體敏感的程式中,比如Mybatis快取記憶體就用到了軟引用,記憶體夠用 的時候就保留,不夠用就回收 | 它們的區別主要在於GC時對物件回收時:軟引用指向的物件只在記憶體不足時被回收,而只被弱引用指向的物件在下一次GC時被回收
弱/軟引用可以和一個引用佇列(ReferenceQueue)聯合使用,如果軟引用所引用的物件被JVM回收,這個軟引用就會被加入到與之關聯的引用佇列中,進行其他與該物件相關記憶體的回收,如HashMap中的Key被回收,則Entry應該被回收。這就是JVM的工作了。
弱引用對於構造弱集合最有用,如WeakHashMap ,它對鍵(而不是值)使用弱引用。
軟引用解決圖片快取的問題
弱應用解決HashMap中的oom問題 |
| 弱引用
WeakReference | 不管記憶體是否夠,只要有GC操作就會進行回收
弱引用需要用 java.lang.ref.WeakReference 類來實現,它比軟引用生存期更短
對於只有弱引用的物件來說,只要垃圾回收機制一執行,不管JVM的記憶體空間是否足夠,都會回收該物件佔用的空間。 | |
| 虛引用
PhantomReference | 虛引用又稱為幽靈引用,需要java.lang.ref.PhantomReference 類來實現
顧名思義,就是形同虛設,與其他幾種引用都不同,虛引用並不會決定物件的生命週期。
如果一個物件持有虛引用,那麼它就和沒有任何引用一樣,在任何時候都可能被垃圾回收器回收,它不能單獨使用也不能通過它訪問物件,虛引用必須和引用佇列ReferenceQueue聯合使用。
虛引用的主要作用和跟蹤物件被垃圾回收的狀態,僅僅是提供一種確保物件被finalize以後,做某些事情的機制。
PhantomReference的get方法總是返回null,因此無法訪問物件的引用物件。其意義在於說明一個物件已經進入finalization階段,可以被gc回收,用來實現比finalization機制更靈活的回收操作
換句話說,設定虛引用關聯的唯一目的,就是在這個物件被收集器回收的時候,收到一個系統通知或者後續新增進一步的處理,Java技術允許使用finalize()方法在垃圾收集器將物件從記憶體中清除出去之前,做必要的清理工作
這個就相當於Spring AOP裡面的後置通知
一般用於在回收時候做通知相關操作
| |
程式碼實現
StrongReference
public class SoftReferenceDemo {
/**
* 記憶體夠用的時候
*/
public static void softRefMemoryEnough() {
// 建立一個強應用
Object o1 = new Object();
// 建立一個軟引用
SoftReference<Object> softReference = new SoftReference<>(o1);
System.out.println(o1);
System.out.println(softReference.get());
o1 = null;
// 手動GC
System.gc();
System.out.println(o1);
System.out.println(softReference.get());
}
/**
* JVM配置,故意產生大物件並配置小的記憶體,讓它的記憶體不夠用了導致OOM,看軟引用的回收情況
* -Xms5m -Xmx5m -XX:+PrintGCDetails
*/
public static void softRefMemoryNoEnough() {
System.out.println("========================");
// 建立一個強應用
Object o1 = new Object();
// 建立一個軟引用
SoftReference<Object> softReference = new SoftReference<>(o1);
System.out.println(o1);
System.out.println(softReference.get());
o1 = null;
// 模擬OOM自動GC
try {
// 建立30M的大物件
byte[] bytes = new byte[30 * 1024 * 1024];
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(o1);
System.out.println(softReference.get());
}
}
public static void main(String[] args) {
softRefMemoryEnough();
softRefMemoryNoEnough();
}
}
我們寫了兩個方法,一個是記憶體夠用的時候,一個是記憶體不夠用的時候
我們首先檢視記憶體夠用的時候,首先輸出的是 o1 和 軟引用的 softReference,我們都能夠看到值
然後我們把o1設定為null,執行手動GC後,我們發現softReference的值還存在,說明記憶體充足的時候,軟引用的物件不會被回收
[email protected]
[email protected]
[GC (System.gc()) [PSYoungGen: 1396K->504K(1536K)] 1504K->732K(5632K), 0.0007842 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 504K->0K(1536K)] [ParOldGen: 228K->651K(4096K)] 732K->651K(5632K), [Metaspace: 3480K->3480K(1056768K)], 0.0058450 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
null
[email protected]
下面我們看當記憶體不夠的時候,我們使用了JVM啟動引數配置,給初始化堆記憶體為5M
-Xms5m -Xmx5m -XX:+PrintGCDetails
但是在建立物件的時候,我們建立了一個30M的大物件
// 建立30M的大物件
byte[] bytes = new byte[30 * 1024 * 1024];
這就必然會觸發垃圾回收機制,這也是中間出現的垃圾回收過程,最後看結果我們發現,o1 和 softReference都被回收了,因此說明,軟引用在記憶體不足的時候,會自動回收
[email protected]
[email protected]
[GC (Allocation Failure) [PSYoungGen: 31K->160K(1536K)] 682K->811K(5632K), 0.0003603 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 160K->96K(1536K)] 811K->747K(5632K), 0.0006385 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 96K->0K(1536K)] [ParOldGen: 651K->646K(4096K)] 747K->646K(5632K), [Metaspace: 3488K->3488K(1056768K)], 0.0067976 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
[GC (Allocation Failure) [PSYoungGen: 0K->0K(1536K)] 646K->646K(5632K), 0.0004024 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [PSYoungGen: 0K->0K(1536K)] [ParOldGen: 646K->627K(4096K)] 646K->627K(5632K), [Metaspace: 3488K->3488K(1056768K)], 0.0065506 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
null
null
SoftReference
public class WeakReferenceDemo {
public static void main(String[] args) {
Object o1 = new Object();
WeakReference<Object> weakReference = new WeakReference<>(o1);
System.out.println(o1);
System.out.println(weakReference.get());
o1 = null;
System.gc();
System.out.println(o1);
System.out.println(weakReference.get());
}
}
我們看結果,能夠發現,我們並沒有製造出OOM記憶體溢位,而只是呼叫了一下GC操作,垃圾回收就把它給收集了
[email protected]
[email protected]
[GC (System.gc()) [PSYoungGen: 5246K->808K(76288K)] 5246K->816K(251392K), 0.0008236 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 808K->0K(76288K)] [ParOldGen: 8K->675K(175104K)] 816K->675K(251392K), [Metaspace: 3494K->3494K(1056768K)], 0.0035953 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
null
null
軟引用和弱引用的使用場景
場景:假如有一個應用需要讀取大量的本地圖片
- 如果每次讀取圖片都從硬碟讀取則會嚴重影響效能
- 如果一次性全部載入到記憶體中,又可能造成記憶體溢位
此時使用軟引用可以解決這個問題
設計思路:使用HashMap來儲存圖片的路徑和相應圖片物件關聯的軟引用之間的對映關係,在記憶體不足時,JVM會自動回收這些快取圖片物件所佔的空間,從而有效地避免了OOM的問題
Map<String, SoftReference<String>> imageCache = new HashMap<String, SoftReference<Bitmap>>();
** WeakHashMap是什麼?**
比如一些常常和底層打交道的,mybatis等,底層都應用到了WeakHashMap
WeakHashMap和HashMap類似,只不過它的Key是使用了弱引用的,也就是說,當執行GC的時候,HashMap中的key會進行回收,下面我們使用例子來測試一下
我們使用了兩個方法,一個是普通的HashMap方法
我們輸入一個Key-Value鍵值對,然後讓它的key置空,然後在檢視結果
public class WeakHashMapDemo {
public static void main(String[] args) {
myHashMap();
System.out.println("==========");
myWeakHashMap();
}
private static void myHashMap() {
Map<Integer, String> map = new HashMap<>();
Integer key = new Integer(1);
String value = "HashMap";
map.put(key, value);
System.out.println(map);
key = null;
System.gc();
System.out.println(map);
}
private static void myWeakHashMap() {
Map<Integer, String> map = new WeakHashMap<>();
Integer key = new Integer(1);
String value = "WeakHashMap";
map.put(key, value);
System.out.println(map);
key = null;
System.gc();
System.out.println(map);
}
}
-------------------------------------------------
{1=HashMap}
{1=HashMap}
==========
{1=WeakHashMap}
{}
從這裡我們看到,對於普通的HashMap來說,key置空並不會影響,HashMap的鍵值對,因為這個屬於強引用,不會被垃圾回收。
但是WeakHashMap,在進行GC操作後,弱引用的就會被回收
PhantomReference
引用佇列 ReferenceQueue
軟引用,弱引用,虛引用在回收之前,需要在引用佇列儲存一下
我們在初始化的弱引用或者虛引用的時候,可以傳入一個引用佇列
那麼在進行GC回收的時候,弱引用和虛引用的物件都會被回收,但是在回收之前,它會被送至引用佇列中
public class PhantomReferenceDemo {
public static void main(String[] args) {
Object o1 = new Object();
// 建立引用佇列
ReferenceQueue<Object> referenceQueue = new ReferenceQueue<>();
// 建立一個弱引用
WeakReference<Object> weakReference = new WeakReference<>(o1, referenceQueue);
// 建立一個弱引用
// PhantomReference<Object> weakReference = new PhantomReference<>(o1, referenceQueue);
System.out.println(o1);
System.out.println(weakReference.get());
// 取佇列中的內容
System.out.println(referenceQueue.poll());
o1 = null;
System.gc();
System.out.println("執行GC操作");
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(o1);
System.out.println(weakReference.get());
// 取佇列中的內容
System.out.println(referenceQueue.poll());
}
}
-------------------------------------------------
[email protected]
[email protected]
null
執行GC操作
null
null
[email protected]
從這裡我們能看到,在進行垃圾回收後,我們弱引用物件,也被設定成null,
但是在佇列中還能夠匯出該引用的例項,這就說明在回收之前,該弱引用的例項被放置引用佇列中了,我們可以通過引用佇列進行一些後置操作
結合GC Roots的理解
- 紅色部分在垃圾回收之外,也就是強引用的
- 藍色部分:屬於軟引用,在記憶體不夠的時候,才回收
- 虛引用和弱引用:每次垃圾回收的時候,都會被幹掉,但是它在幹掉之前還會存在引用佇列中,我們可以通過引用佇列進行一些通知機制

十二、JVM調優和引數配置
JVM引數型別
| 標配引數 | - -version - -help - java -showversion |
|---|---|
| X引數(瞭解) | - -Xint 解釋執行 - -Xcomp 第一次使用就編譯成原生程式碼 - -Xmixed 混合模式 |
| XX引數(重點) | - Boolean型別 |
--公式:-XX:+或者-某個屬性 (+表示開啟 -表示關閉)
--案例:-XX:+PrintGCDetails 表示開啟了GC詳情列印功能
- K-V型別
--公式:-XX:屬性key=value
|
JPS、Jinfo的使用
在java程式起來後,在Bash視窗中輸入jps -l 可以獲得系統當前執行的java程式的程式號
然後使用jinfo 針對該程式進行一系列查詢
比如現在要查詢PrintGCDetails這個功能是否開啟

十三、常見OOM
經典錯誤
JVM中常見的兩個錯誤
- StackoverFlowError :棧溢位
- OutofMemoryError: java heap space:堆溢位
除此之外,還有以下的錯誤
- java.lang.StackOverflowError
- java.lang.OutOfMemoryError:java heap space
- java.lang.OutOfMemoryError:GC overhead limit exceeeded
- java.lang.OutOfMemoryError:Direct buffer memory
- java.lang.OutOfMemoryError:unable to create new native thread
- java.lang.OutOfMemoryError:Metaspace
StackOverflowError
堆疊溢位,我們有最簡單的一個遞迴呼叫,就會造成堆疊溢位,也就是深度的方法呼叫
棧一般是512K,不斷的深度呼叫,直到棧被撐破
public class StackOverflowErrorDemo {
public static void main(String[] args) {
stackOverflowError();
}
/**
* 棧一般是512K,不斷的深度呼叫,直到棧被撐破
* Exception in thread "main" java.lang.StackOverflowError
*/
private static void stackOverflowError() {
stackOverflowError();
}
}
------------------------
Exception in thread "main" java.lang.StackOverflowError
at com.moxi.interview.study.oom.StackOverflowErrorDemo.stackOverflowError(StackOverflowErrorDemo.java:8)
OutOfMemoryError
Java heap space
建立了很多物件,導致堆空間不夠儲存
public class JavaHeapSpaceDemo {
public static void main(String[] args) {
// 堆空間的大小 -Xms10m -Xmx10m
// 建立一個 80M的位元組陣列
byte [] bytes = new byte[80 * 1024 * 1024];
}
}
//我們建立一個80M的陣列,會直接出現Java heap space
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
GC overhead limit exceeded
GC超出開銷限制
GC回收時間過長時會丟擲OutOfMemoryError,過長的定義是,超過了98%的時間用來做GC,並且回收了不到2%的堆記憶體
連續多次GC都只回收了不到2%的極端情況下,才會丟擲。假設不丟擲GC overhead limit 錯誤會造成什麼情況呢?
那就是GC清理的這點記憶體很快會再次被填滿,迫使GC再次執行,這樣就形成了惡性迴圈,CPU的使用率一直都是100%,而GC卻沒有任何成果。
為了更快的達到效果,我們首先需要設定JVM啟動引數
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
public class GCOverheadLimitDemo {
public static void main(String[] args) {
int i = 0;
List<String> list = new ArrayList<>();
try {
while(true) {
list.add(String.valueOf(++i).intern());
}
} catch (Exception e) {
System.out.println("***************i:" + i);
e.printStackTrace();
throw e;
} finally {
}
}
}
-----------------------------
[Full GC (Ergonomics) [PSYoungGen: 2047K->2047K(2560K)] [ParOldGen: 7106K->7106K(7168K)] 9154K->9154K(9728K), [Metaspace: 3504K->3504K(1056768K)], 0.0311093 secs] [Times: user=0.13 sys=0.00, real=0.03 secs]
[Full GC (Ergonomics) [PSYoungGen: 2047K->0K(2560K)] [ParOldGen: 7136K->667K(7168K)] 9184K->667K(9728K), [Metaspace: 3540K->3540K(1056768K)], 0.0058093 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Heap
PSYoungGen total 2560K, used 114K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 5% used [0x00000000ffd00000,0x00000000ffd1c878,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 7168K, used 667K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 9% used [0x00000000ff600000,0x00000000ff6a6ff8,0x00000000ffd00000)
Metaspace used 3605K, capacity 4540K, committed 4864K, reserved 1056768K
class space used 399K, capacity 428K, committed 512K, reserved 1048576K
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.Integer.toString(Integer.java:403)
at java.lang.String.valueOf(String.java:3099)
at com.moxi.interview.study.oom.GCOverheadLimitDemo.main(GCOverheadLimitDemo.java:9)
!!! 我們能夠看到 多次Full GC,並沒有清理出空間,在多次執行GC操作後,就丟擲異常 GC overhead limit
Direct buffer memory
Netty + NIO:這是由於NIO引起的
寫NIO程式的時候經常會使用ByteBuffer來讀取或寫入資料,這是一種基於通道(Channel) 與 緩衝區(Buffer)的I/O方式,它可以使用Native 函式庫直接分配堆外記憶體,然後通過一個儲存在Java堆裡面的DirectByteBuffer物件作為這塊記憶體的引用進行操作。這樣能在一些場景中顯著提高效能,因為避免了在Java堆和Native堆中來回複製資料。
ByteBuffer.allocate(capability):第一種方式是分配JVM堆記憶體,屬於GC管轄範圍,由於需要拷貝所以速度相對較慢
ByteBuffer.allocteDirect(capability):第二種方式是分配OS本地記憶體,不屬於GC管轄範圍,由於不需要記憶體的拷貝,所以速度相對較快
但如果不斷分配本地記憶體,堆記憶體很少使用,那麼JVM就不需要執行GC,DirectByteBuffer物件就不會被回收,這時候懟記憶體充足,但本地記憶體可能已經使用光了,再次嘗試分配本地記憶體就會出現OutOfMemoryError,那麼程式就奔潰了。
一句話說:本地記憶體不足,但是堆記憶體充足的時候,就會出現這個問題
為了更快的達到效果,我們首先需要設定JVM啟動引數
-Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
// 只設定了5M的實體記憶體使用,但是卻分配 6M的空間
ByteBuffer bb = ByteBuffer.allocateDirect(6 * 1024 * 1024);
--------------------------
配置的maxDirectMemory:5.0MB
[GC (System.gc()) [PSYoungGen: 2030K->488K(2560K)] 2030K->796K(9728K), 0.0008326 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 488K->0K(2560K)] [ParOldGen: 308K->712K(7168K)] 796K->712K(9728K), [Metaspace: 3512K->3512K(1056768K)], 0.0052052 secs] [Times: user=0.09 sys=0.00, real=0.00 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:693)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at com.moxi.interview.study.oom.DIrectBufferMemoryDemo.main(DIrectBufferMemoryDemo.java:19)
unable to create new native thread
不能夠建立更多的新的執行緒了,也就是說建立執行緒的上限達到了
在高併發場景的時候,會應用到
高併發請求伺服器時,經常會出現如下異常java.lang.OutOfMemoryError:unable to create new native thread,準確說該native thread異常與對應的平臺有關
導致原因:
- 應用建立了太多執行緒,一個應用程式建立多個執行緒,超過系統承載極限
- 伺服器並不允許你的應用程式建立這麼多執行緒,linux系統預設執行單個程式可以建立的執行緒為1024個(除去系統佔用,實際在900左右,當然root使用者沒有上限),如果應用建立超過這個數量,就會報
java.lang.OutOfMemoryError:unable to create new native thread
解決方法:
- 想辦法降低你應用程式建立執行緒的數量,分析應用是否真的需要建立這麼多執行緒,如果不是,改程式碼將執行緒數降到最低
- 對於有的應用,確實需要建立很多執行緒,遠超過linux系統預設1024個執行緒限制,可以通過修改linux伺服器配置,擴大linux預設限制
```java
public class UnableCreateNewThreadDemo {
public static void main(String[] args) {
for (int i = 0; ; i++) {
System.out.println("************** i = " + i);
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, String.valueOf(i)).start();
}
}
}
這個時候,就會出現下列的錯誤,執行緒數大概在 900多個
Exception in thread "main" java.lang.OutOfMemoryError: unable to cerate new native thread
如何檢視執行緒數
```shell
ulimit -u

MetaSpace
元空間記憶體不足,Matespace元空間應用的是本地記憶體-XX:MetaspaceSize 的處理化大小為20M
#### 元空間是什麼
元空間就是我們的方法區的實現,存放的是類模板,類資訊,常量池等
Metaspace是方法區HotSpot中的實現,它與持久代最大的區別在於:Metaspace並不在虛擬記憶體中,而是使用本地記憶體,
也即在java8中,class metadata(the virtual machines internal presentation of Java class),
被儲存在叫做Matespace的native memory
永久代(java8後背元空間Metaspace取代了)存放了以下資訊:
- 虛擬機器器載入的類資訊
- 常量池
- 靜態變數
- 即時編譯後的程式碼
模擬Metaspace空間溢位,我們不斷生成類 往元空間裡灌輸,類佔據的空間總會超過Metaspace指定的空間大小
為了更快的達到效果,我們首先需要設定JVM啟動引數
-XX:MetaspaceSize=8m -XX:MaxMetaspaceSize=8m
public class MetaspaceOutOfMemoryDemo {
// 靜態類
static class OOMTest {
}
public static void main(final String[] args) {
// 模擬計數多少次以後發生異常
int i =0;
try {
while (true) {
i++;
// 使用Spring的動態位元組碼技術
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(OOMTest.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
return methodProxy.invokeSuper(o, args);
}
});
}
} catch (Exception e) {
System.out.println("發生異常的次數:" + i);
e.printStackTrace();
} finally {
}
}
}
------------------
報錯:
發生異常的次數: 201
java.lang.OutOfMemoryError:Metaspace