
一文搞懂單鏈表的六大解題套路
https://labuladong.gitee.io/algo/2/17/16/
讀完本文,你不僅學會了演算法套路,還可以順便去 LeetCode 上拿下如下題目:
———–
上次在視訊號直播,跟大家說到單鏈表有很多巧妙的操作,本文就總結一下單鏈表的基本技巧,每個技巧都對應著至少一道演算法題:
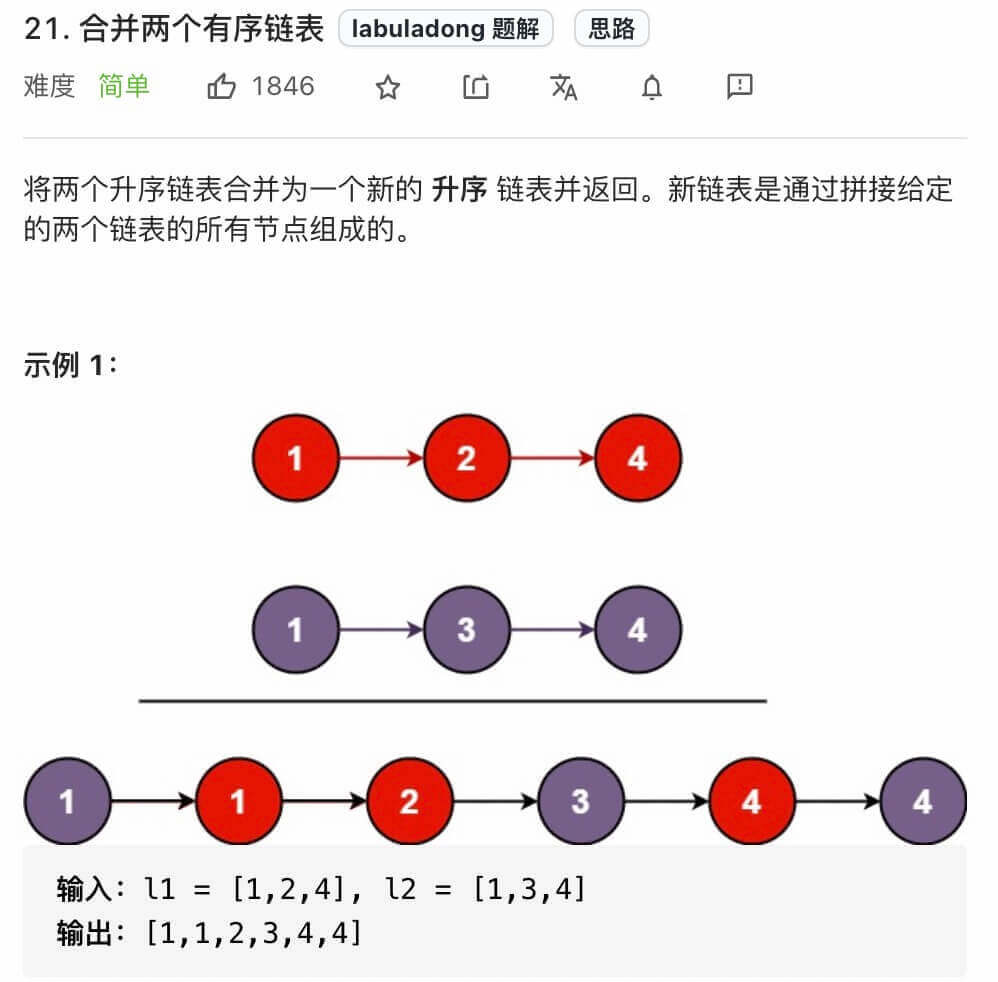
1、合併兩個有序連結串列
2、合併k個有序連結串列
3、尋找單鏈表的倒數第k
4、尋找單鏈表的中點
5、判斷單鏈表是否包含環並找出環起點
6、判斷兩個單鏈表是否相交併找出交點
這些解法都用到了雙指標技巧,所以說對於單鏈表相關的題目,雙指標的運用是非常廣泛的,下面我們就來一個一個看。
合併兩個有序連結串列
這是最基本的連結串列技巧,力扣第 21 題「合併兩個有序連結串列」就是這個問題:
{kind=link}
給你輸入兩個有序連結串列,請你把他倆合併成一個新的有序連結串列,函式簽名如下:
ListNode mergeTwoLists(ListNode l1, ListNode l2);
這題比較簡單,我們直接看解法:
ListNode mergeTwoLists(ListNode l1, ListNode l2) {
// 虛擬頭結點
ListNode dummy = new ListNode(-1), p = dummy;
ListNode p1 = l1, p2 = l2;
while (p1 != null && p2 != null) {
// 比較 p1 和 p2 兩個指標
// 將值較小的的節點接到 p 指標
if (p1.val > p2.val) {
p.next = p2;
p2 = p2.next;
} else {
p.next = p1;
p1 = p1.next;
}
// p 指標不斷前進
p = p.next;
}
if (p1 != null) {
p.next = p1;
}
if (p2 != null) {
p.next = p2;
}
return dummy.next;
}
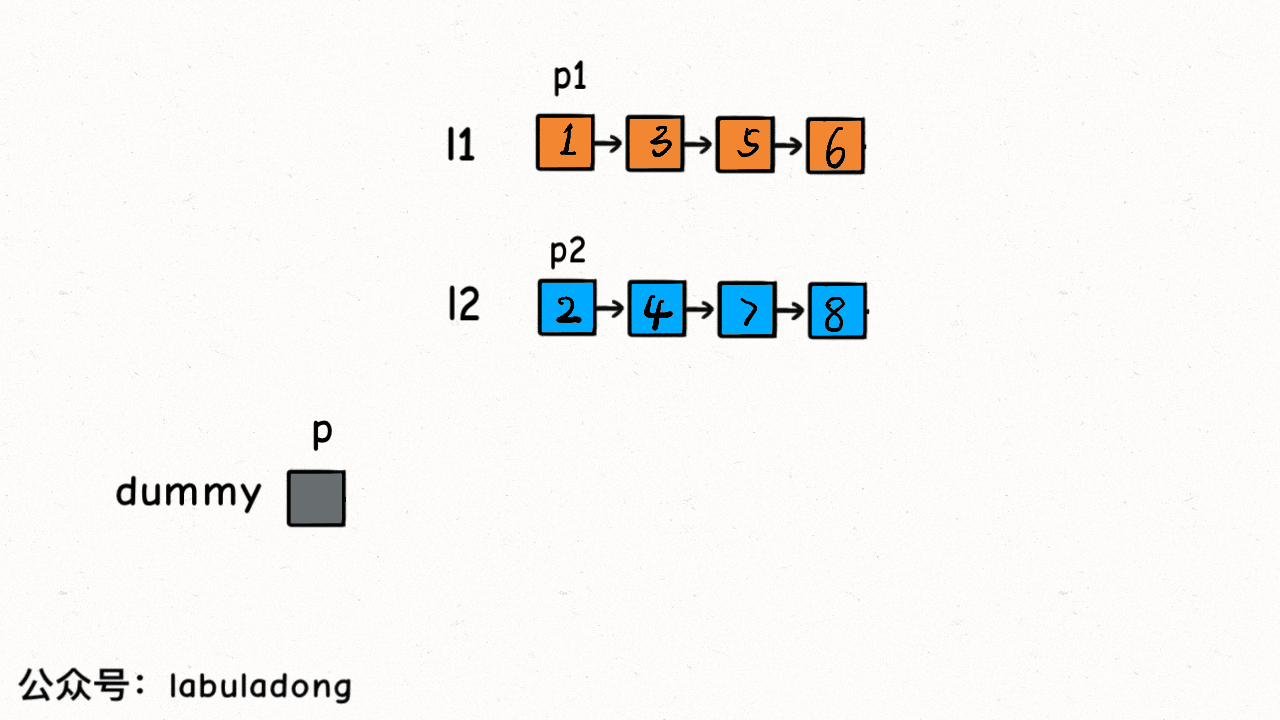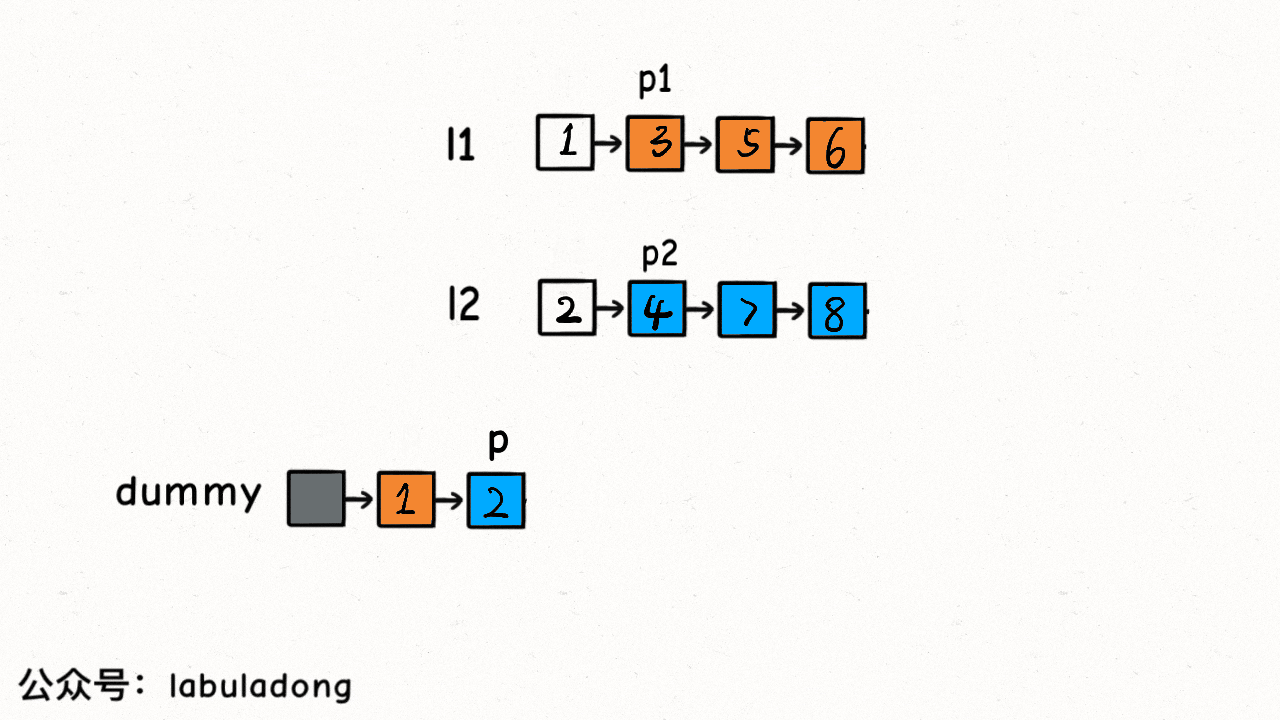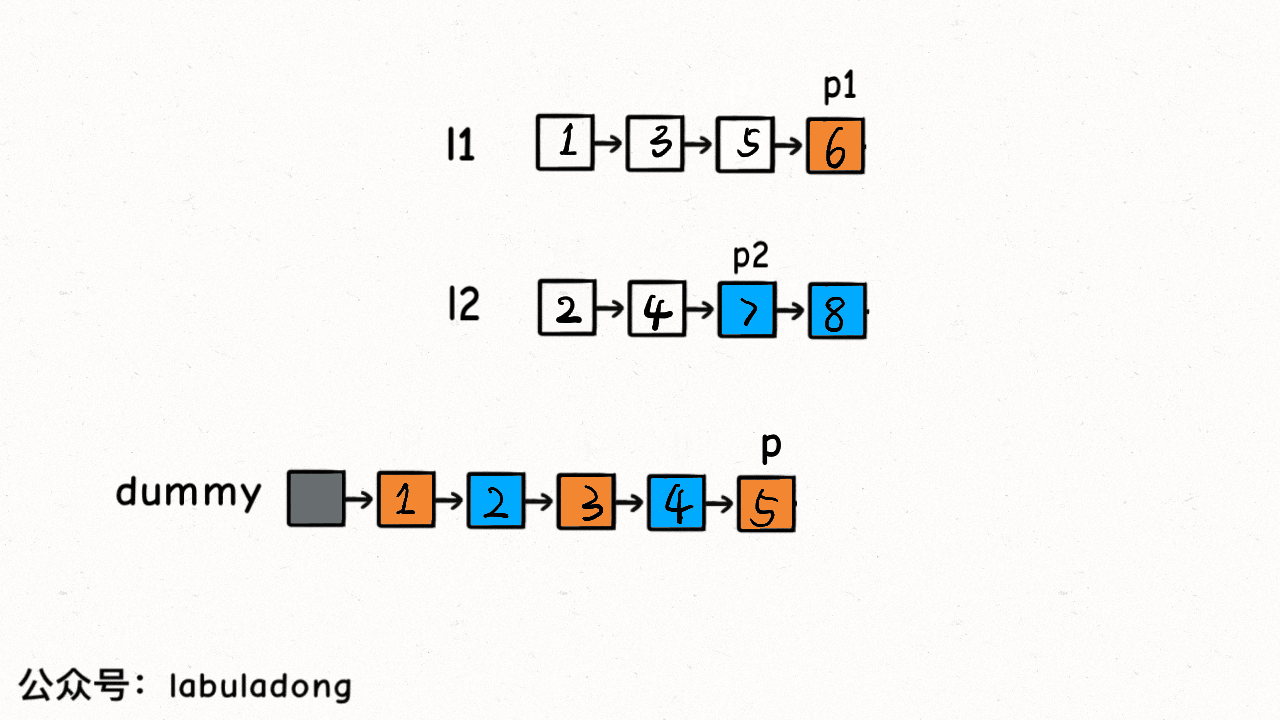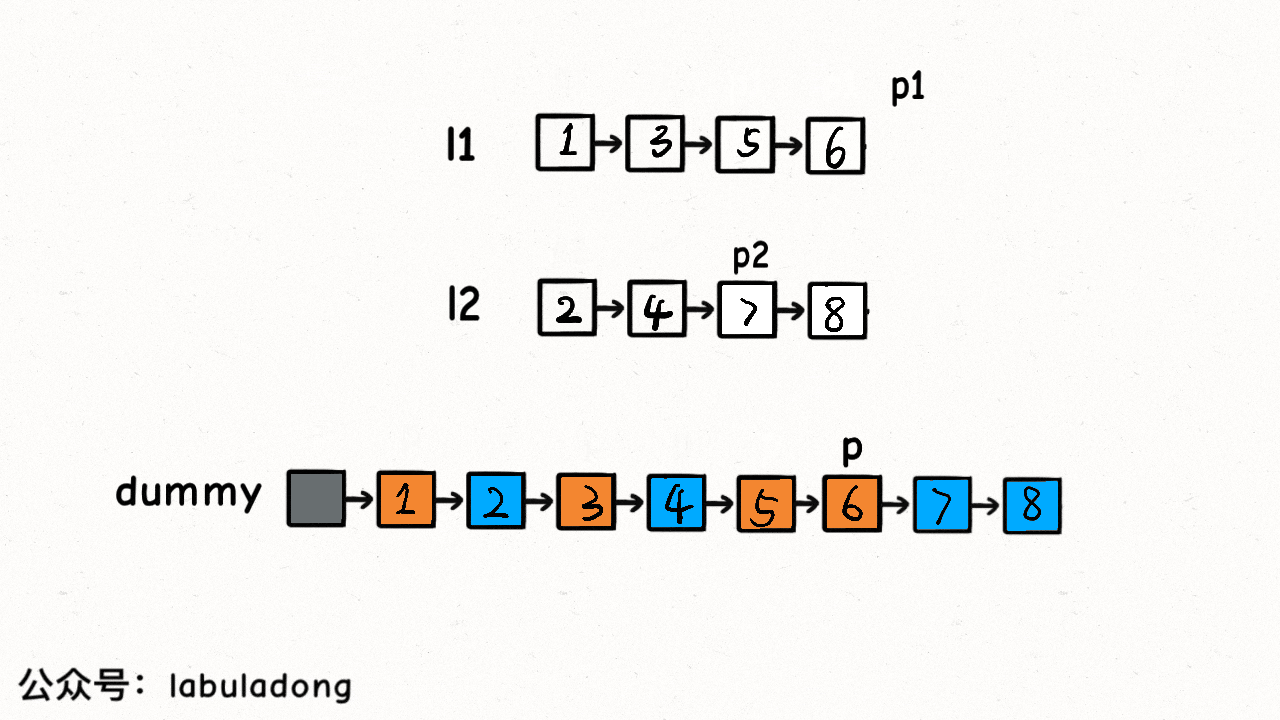
我們的 while 迴圈每次比較p1和p2的大小,把較小的節點接到結果連結串列上:
{kind=link}
這個演算法的邏輯類似於「拉拉鍊」,l1, l2類似於拉鍊兩側的鋸齒,指標p就好像拉鍊的拉索,將兩個有序連結串列合併。
程式碼中還用到一個連結串列的演算法題中是很常見的「虛擬頭結點」技巧,也就是dummy節點。你可以試試,如果不使用dummy虛擬節點,程式碼會複雜很多,而有了dummy節點這個佔位符,可以避免處理空指標的情況,降低程式碼的複雜性。
合併 k 個有序連結串列
看下力扣第 23 題「合併K個升序連結串列」:
{kind=link}
函式簽名如下:
ListNode mergeKLists(ListNode[] lists);
合併k個有序連結串列的邏輯類似合併兩個有序連結串列,難點在於,如何快速得到k個節點中的最小節點,接到結果連結串列上?
這裡我們就要用到優先順序佇列(二叉堆)這種資料結構,把連結串列節點放入一個最小堆,就可以每次獲得k個節點中的最小節點:
ListNode mergeKLists(ListNode[] lists) {
if (lists.length == 0) return null;
// 虛擬頭結點
ListNode dummy = new ListNode(-1);
ListNode p = dummy;
// 優先順序佇列,最小堆
PriorityQueue<ListNode> pq = new PriorityQueue<>(
lists.length, (a, b)->(a.val - b.val));
// 將 k 個連結串列的頭結點加入最小堆
for (ListNode head : lists) {
if (head != null)
pq.add(head);
}
while (!pq.isEmpty()) {
// 獲取最小節點,接到結果連結串列中
ListNode node = pq.poll();
p.next = node;
if (node.next != null) {
pq.add(node.next);
}
// p 指標不斷前進
p = p.next;
}
return dummy.next;
}
這個演算法是面試常考題,它的時間複雜度是多少呢?
優先佇列pq中的元素個數最多是k,所以一次poll或者add方法的時間複雜度是O(logk);所有的連結串列節點都會被加入和彈出pq,所以演算法整體的時間複雜度是O(Nlogk),其中k是連結串列的條數,N是這些連結串列的節點總數。
單鏈表的倒數第 k 個節點
從前往後尋找單鏈表的第k個節點很簡單,一個 for 迴圈遍歷過去就找到了,但是如何尋找從後往前數的第k個節點呢?
那你可能說,假設連結串列有n個節點,倒數第k個節點就是正數第n - k個節點,不也是一個 for 迴圈的事兒嗎?
是的,但是演算法題一般只給你一個ListNode頭結點代表一條單鏈表,你不能直接得出這條連結串列的長度n,而需要先遍歷一遍連結串列算出n的值,然後再遍歷連結串列計算第n - k個節點。
也就是說,這個解法需要遍歷兩次連結串列才能得到出倒數第k個節點。
那麼,我們能不能只遍歷一次連結串列,就算出倒數第k個節點?可以做到的,如果是面試問到這道題,面試官肯定也是希望你給出只需遍歷一次連結串列的解法。
這個解法就比較巧妙了,假設k = 2,思路如下:
首先,我們先讓一個指標p1指向連結串列的頭節點head,然後走k步:
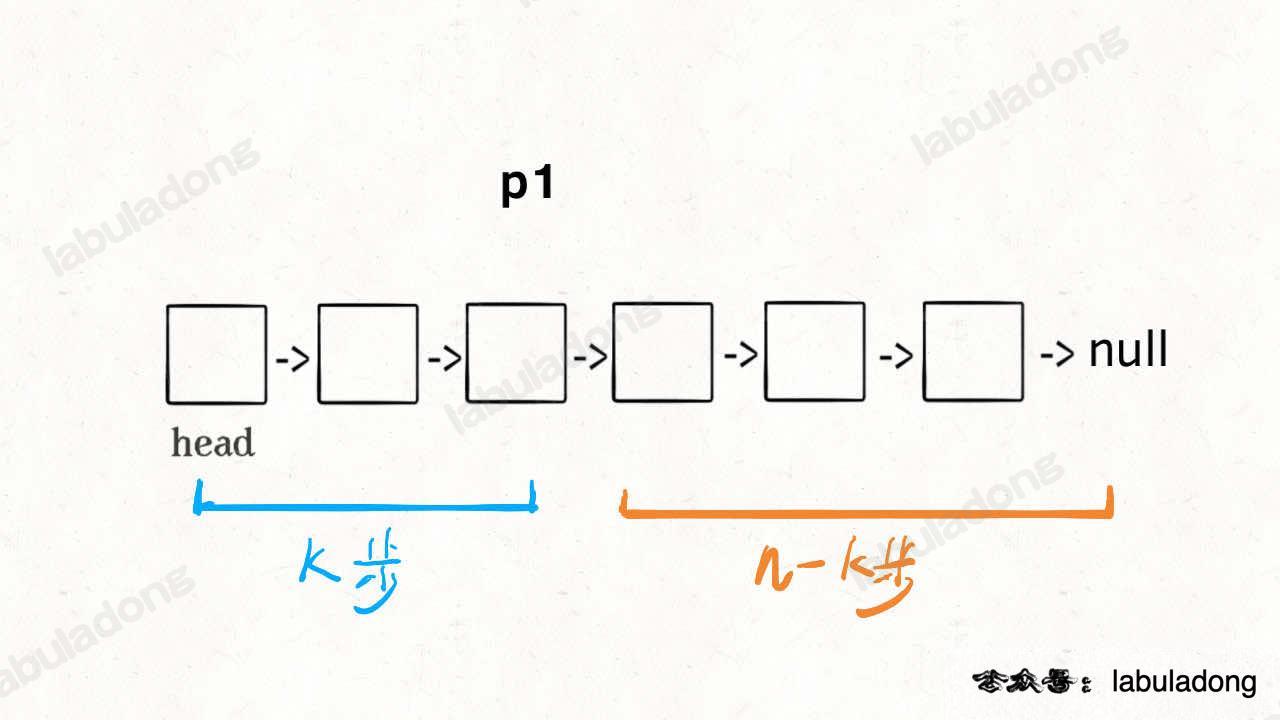{kind=link}
現在的p1,只要再走n - k步,就能走到連結串列末尾的空指標了對吧?
趁這個時候,再用一個指標p2指向連結串列頭節點head:
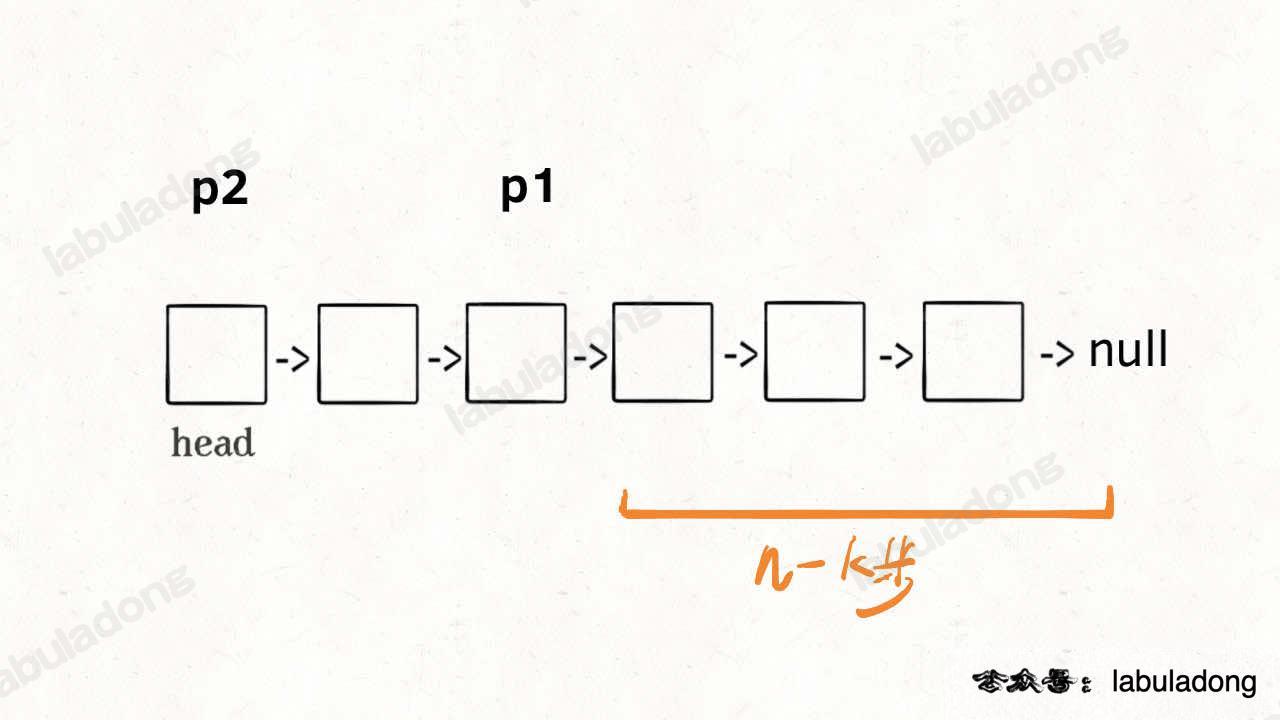{kind=link}
接下來就很顯然了,讓p1和p2同時向前走,p1走到連結串列末尾的空指標時走了n - k步,p2也走了n - k步,也就是連結串列的倒數第k個節點:
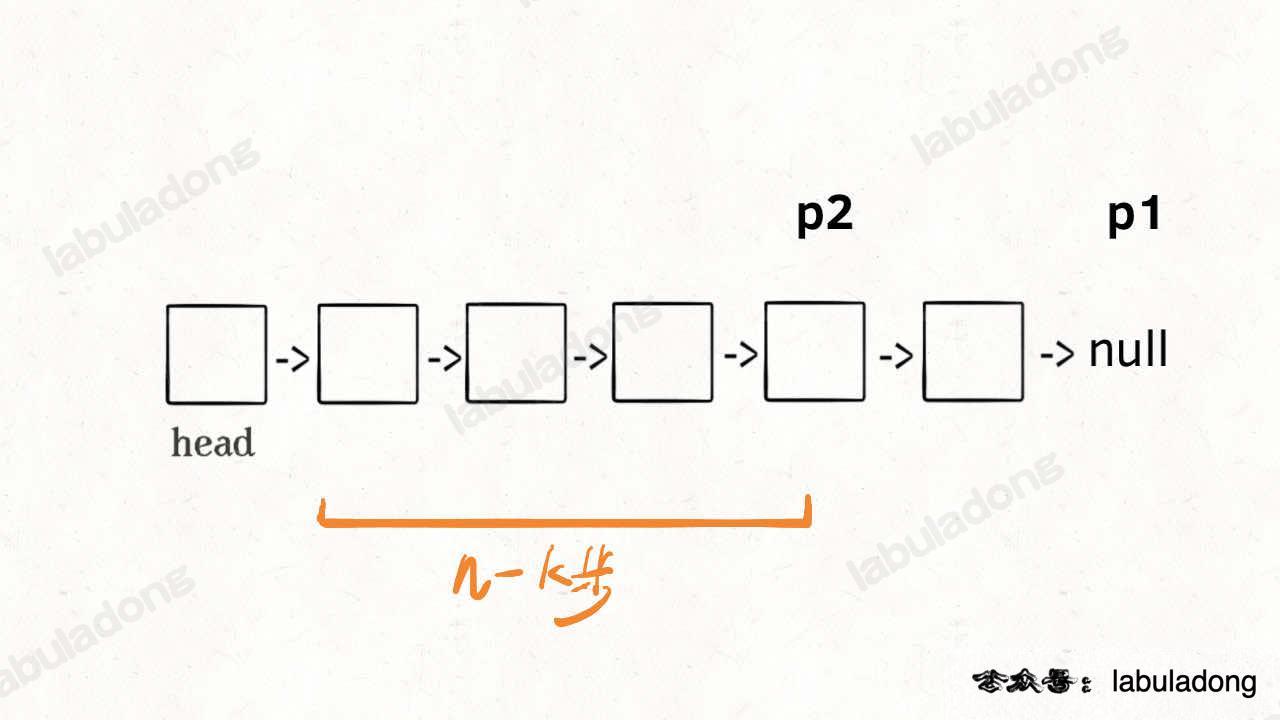{kind=link}
這樣,只遍歷了一次連結串列,就獲得了倒數第k個節點p2。
上述邏輯的程式碼如下:
// 返回連結串列的倒數第 k 個節點
ListNode findFromEnd(ListNode head, int k) {
ListNode p1 = head;
// p1 先走 k 步
for (int i = 0; i < k; i++) {
p1 = p1.next;
}
ListNode p2 = head;
// p1 和 p2 同時走 n - k 步
while (p1 != null) {
p2 = p2.next;
p1 = p1.next;
}
// p2 現在指向第 n - k 個節點
return p2;
}
當然,如果用 big O 表示法來計算時間複雜度,無論遍歷一次連結串列和遍歷兩次連結串列的時間複雜度都是O(N),但上述這個演算法更有技巧性。
很多連結串列相關的演算法題都會用到這個技巧,比如說力扣第 19 題「刪除連結串列的倒數第 N 個結點」:
{kind=link}
我們直接看解法程式碼:
// 主函式
public ListNode removeNthFromEnd(ListNode head, int n) {
// 虛擬頭結點
ListNode dummy = new ListNode(-1);
dummy.next = head;
// 刪除倒數第 n 個,要先找倒數第 n + 1 個節點
ListNode x = findFromEnd(dummy, n + 1);
// 刪掉倒數第 n 個節點
x.next = x.next.next;
return dummy.next;
}
private ListNode findFromEnd(ListNode head, int k) {
// 程式碼見上文
}
這個邏輯就很簡單了,要刪除倒數第n個節點,就得獲得倒數第n + 1個節點的引用,可以用我們實現的findFromEnd來操作。
不過注意我們又使用了虛擬頭結點的技巧,也是為了防止出現空指標的情況,比如說連結串列總共有 5 個節點,題目就讓你刪除倒數第 5 個節點,也就是第一個節點,那按照演算法邏輯,應該首先找到倒數第 6 個節點。但第一個節點前面已經沒有節點了,這就會出錯。
但有了我們虛擬節點dummy的存在,就避免了這個問題,能夠對這種情況進行正確的刪除。
單鏈表的中點
這個技巧在前文雙指標技巧彙總寫過,如果看過的讀者可以跳過。
力扣第 876 題「連結串列的中間結點」就是這個題目,問題的關鍵也在於我們無法直接得到單鏈表的長度n,常規方法也是先遍歷連結串列計算n,再遍歷一次得到第n / 2個節點,也就是中間節點。
如果想一次遍歷就得到中間節點,也需要耍點小聰明,使用「快慢指標」的技巧:
我們讓兩個指標slow和fast分別指向連結串列頭結點head。
每當慢指標slow前進一步,快指標fast就前進兩步,這樣,當fast走到連結串列末尾時,slow就指向了連結串列中點。
上述思路的程式碼實現如下:
ListNode middleNode(ListNode head) {
// 快慢指標初始化指向 head
ListNode slow = head, fast = head;
// 快指標走到末尾時停止
while (fast != null && fast.next != null) {
// 慢指標走一步,快指標走兩步
slow = slow.next;
fast = fast.next.next;
}
// 慢指標指向中點
return slow;
}
需要注意的是,如果連結串列長度為偶數,也就是說中點有兩個的時候,我們這個解法返回的節點是靠後的那個節點。
另外,這段程式碼稍加修改就可以直接用到判斷連結串列成環的演算法題上。
判斷連結串列是否包含環
這個技巧也在前文雙指標技巧彙總寫過,如果看過的讀者可以跳過。
判斷連結串列是否包含環屬於經典問題了,解決方案也是用快慢指標:
每當慢指標slow前進一步,快指標fast就前進兩步。
如果fast最終遇到空指標,說明連結串列中沒有環;如果fast最終和slow相遇,那肯定是fast超過了slow一圈,說明連結串列中含有環。
只需要把尋找連結串列中點的程式碼稍加修改就行了:
boolean hasCycle(ListNode head) {
// 快慢指標初始化指向 head
ListNode slow = head, fast = head;
// 快指標走到末尾時停止
while (fast != null && fast.next != null) {
// 慢指標走一步,快指標走兩步
slow = slow.next;
fast = fast.next.next;
// 快慢指標相遇,說明含有環
if (slow == fast) {
return true;
}
}
// 不包含環
return false;
}
當然,這個問題還有進階版:如果連結串列中含有環,如何計算這個環的起點?
這裡簡單提一下解法:
ListNode detectCycle(ListNode head) {
ListNode fast, slow;
fast = slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) break;
}
// 上面的程式碼類似 hasCycle 函式
if (fast == null || fast.next == null) {
// fast 遇到空指標說明沒有環
return null;
}
// 重新指向頭結點
slow = head;
// 快慢指標同步前進,相交點就是環起點
while (slow != fast) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
可以看到,當快慢指標相遇時,讓其中任一個指標指向頭節點,然後讓它倆以相同速度前進,再次相遇時所在的節點位置就是環開始的位置。
前文雙指標技巧彙總詳細解釋了其中的原理,這裡簡單說一下。
我們假設快慢指標相遇時,慢指標slow走了k步,那麼快指標fast一定走了2k步:
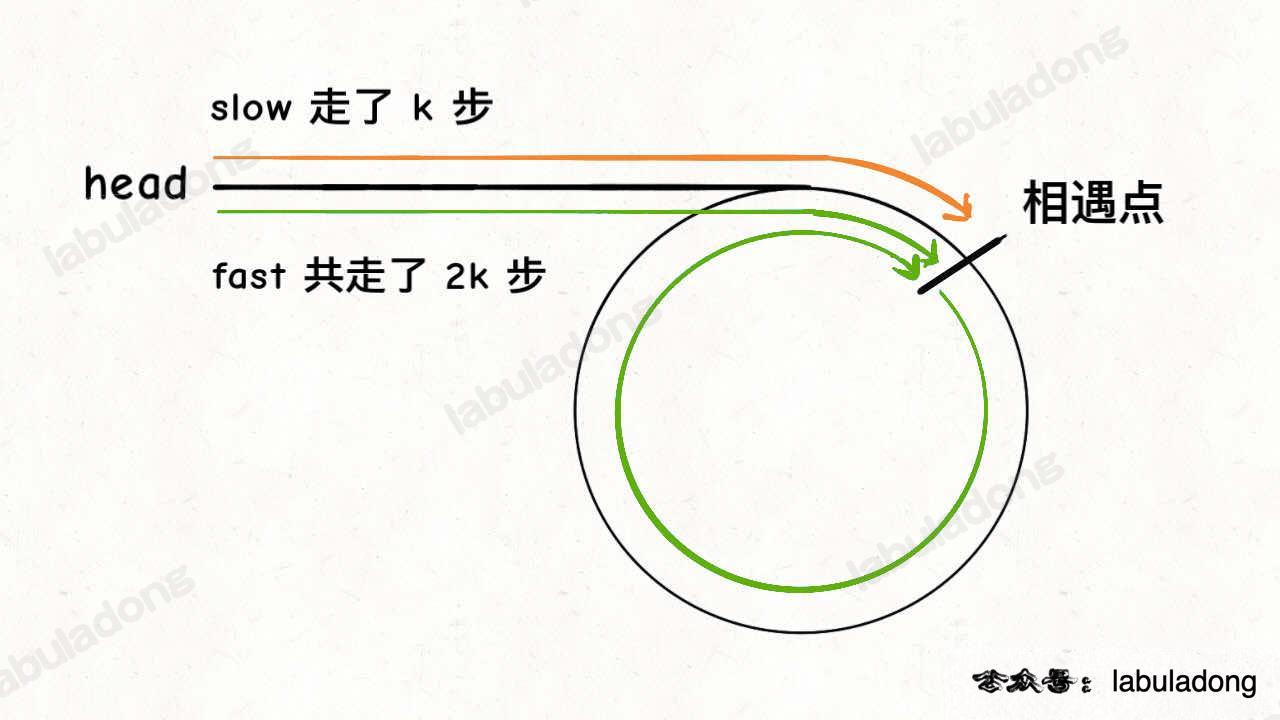{kind=link}
fast一定比slow多走了k步,這多走的k步其實就是fast指標在環裡轉圈圈,所以k的值就是環長度的「整數倍」。
假設相遇點距環的起點的距離為m,那麼結合上圖的slow指標,環的起點距頭結點head的距離為k - m,也就是說如果從head前進k - m步就能到達環起點。
巧的是,如果從相遇點繼續前進k - m步,也恰好到達環起點。因為結合上圖的fast指標,從相遇點開始走k步可以轉回到相遇點,那走k - m步肯定就走到環起點了:
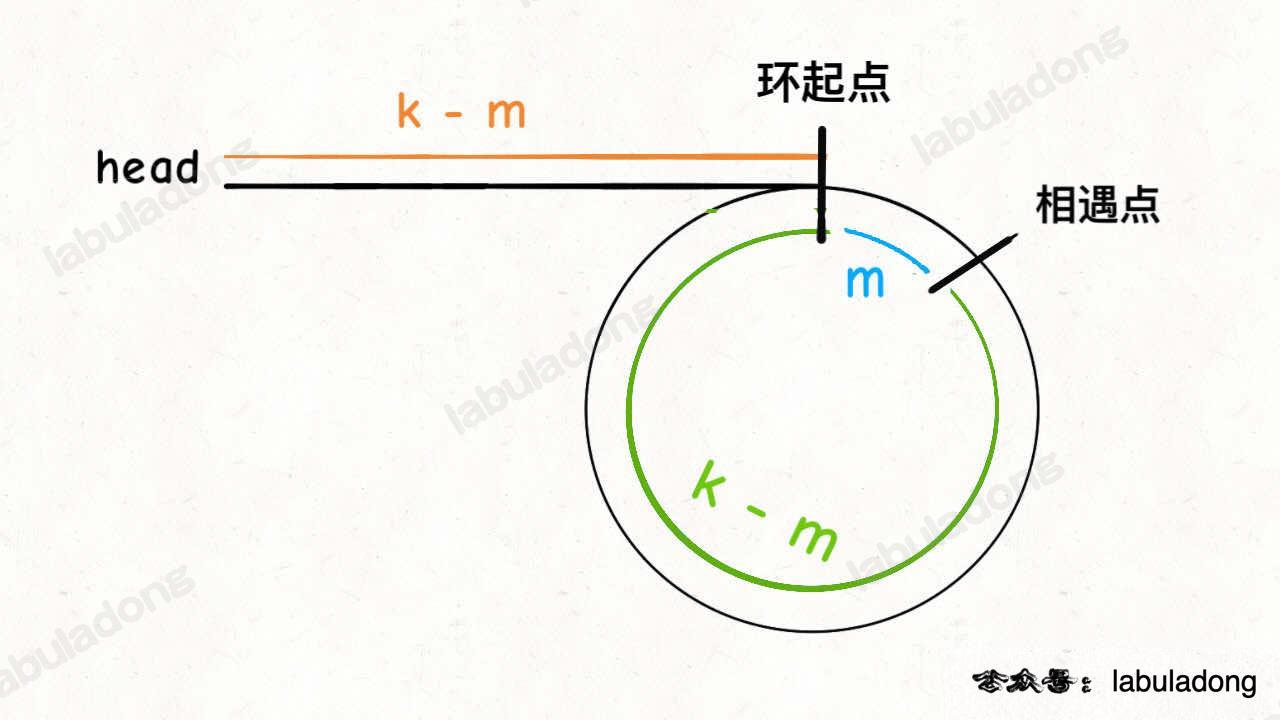{kind=link}
所以,只要我們把快慢指標中的任一個重新指向head,然後兩個指標同速前進,k - m步後一定會相遇,相遇之處就是環的起點了。
兩個連結串列是否相交
這個問題有意思,也是力扣第 160 題「相交連結串列」函式簽名如下:
ListNode getIntersectionNode(ListNode headA, ListNode headB);
給你輸入兩個連結串列的頭結點headA和headB,這兩個連結串列可能存在相交。
如果相交,你的演算法應該返回相交的那個節點;如果沒相交,則返回 null。
比如題目給我們舉的例子,如果輸入的兩個連結串列如下圖:
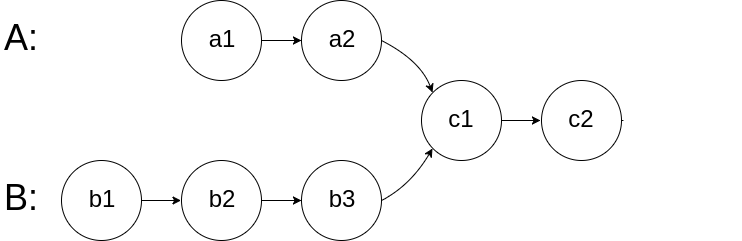{kind=link}
那麼我們的演算法應該返回c1這個節點。
這個題直接的想法可能是用HashSet記錄一個連結串列的所有節點,然後和另一條連結串列對比,但這就需要額外的空間。
如果不用額外的空間,只使用兩個指標,你如何做呢?
難點在於,由於兩條連結串列的長度可能不同,兩條連結串列之間的節點無法對應:
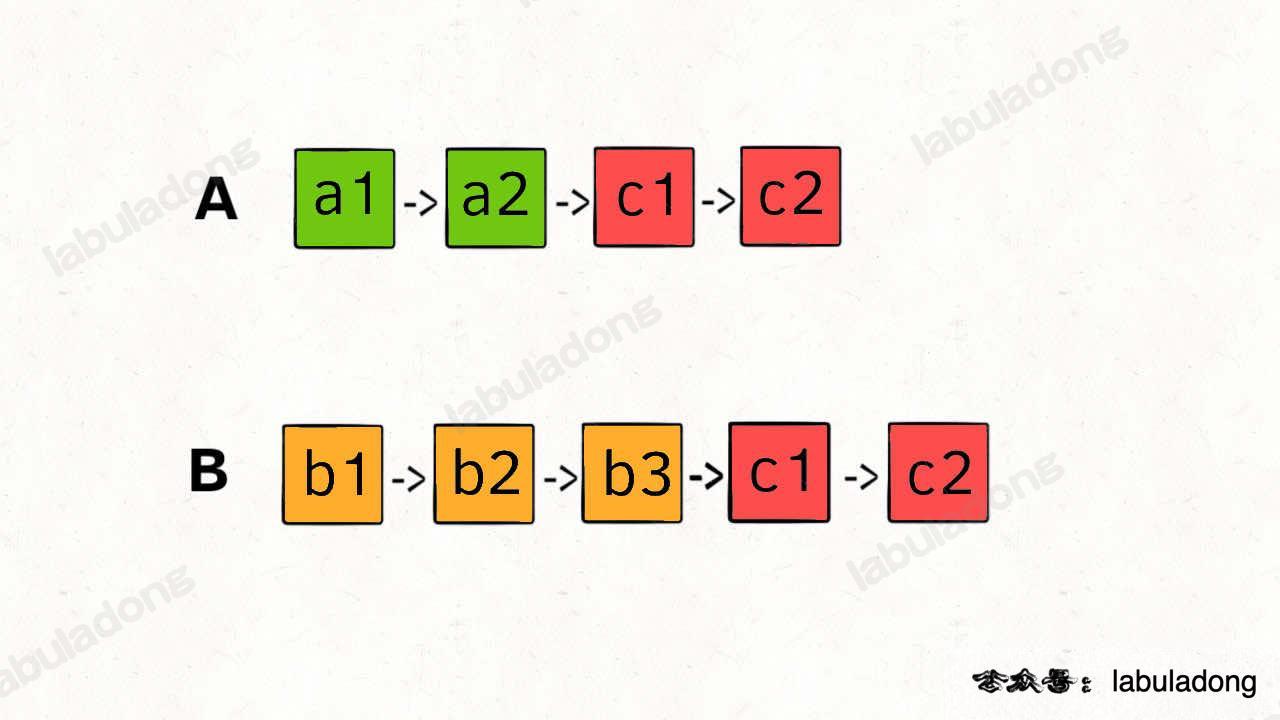{kind=link}
如果用兩個指標p1和p2分別在兩條連結串列上前進,並不能同時走到公共節點,也就無法得到相交節點c1。
所以,解決這個問題的關鍵是,通過某些方式,讓p1和p2能夠同時到達相交節點c1。
所以,我們可以讓p1遍歷完連結串列A之後開始遍歷連結串列B,讓p2遍歷完連結串列B之後開始遍歷連結串列A,這樣相當於「邏輯上」兩條連結串列接在了一起。
如果這樣進行拼接,就可以讓p1和p2同時進入公共部分,也就是同時到達相交節點c1:
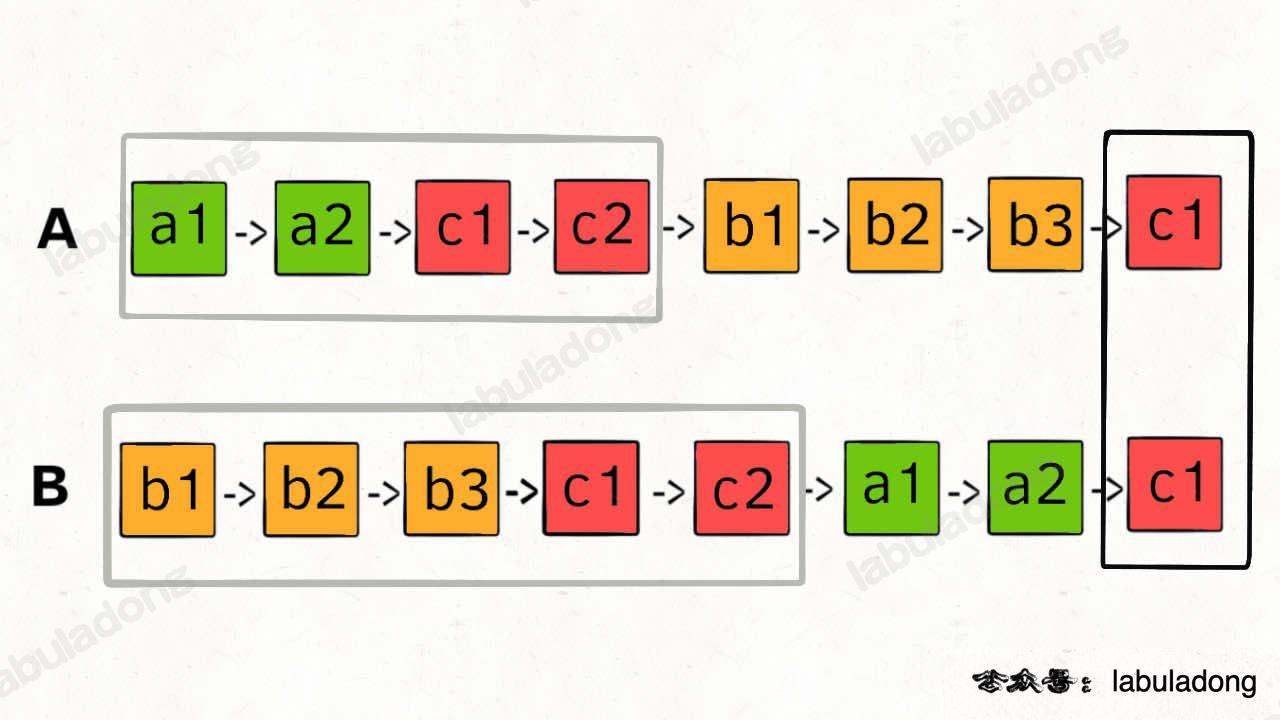{kind=link}
那你可能會問,如果說兩個連結串列沒有相交點,是否能夠正確的返回 null 呢?
這個邏輯可以覆蓋這種情況的,相當於c1節點是 null 空指標嘛,可以正確返回 null。
按照這個思路,可以寫出如下程式碼:
ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// p1 指向 A 連結串列頭結點,p2 指向 B 連結串列頭結點
ListNode p1 = headA, p2 = headB;
while (p1 != p2) {
// p1 走一步,如果走到 A 連結串列末尾,轉到 B 連結串列
if (p1 == null) p1 = headB;
else p1 = p1.next;
// p2 走一步,如果走到 B 連結串列末尾,轉到 A 連結串列
if (p2 == null) p2 = headA;
else p2 = p2.next;
}
return p1;
}
這樣,這道題就解決了,空間複雜度為O(1),時間複雜度為O(N)。
以上就是單鏈表的所有技巧,希望對你有啟發。
_____________