
Linux效能優化實戰:開篇+平均負載
摘 學習筆記:
開篇
效能指標概念:高併發 => 吞吐 響應快 => 延時
該概念是從應用負載的角度出發:Application ▹Libraries▹System Call▹Linux Kernel ▹Drive
與之對應的是系統資源視角出發 :Drive▹Linux Kernel ▹System Call ▹Libraries ▹Application
效能指標的評判有以上二種常用的角度
接著六步
1.選擇效能指標評估應用和系統的效能
2.為應用和系統設定效能目標
3.進行效能基準測試
4.效能分析定位瓶頸
5.優化系統和應用程式
6.效能監控和告警
六步總結,從正確的角度出發,設定目標(效能優化不是漫無目的的),基準測試(瞭解現有系統應用的執行時情況),根據情況分析瓶頸,優化它,設定監控和告警(其實可以再擴充套件比如達到一定的負載,採取降級等操作)
https://static001.geekbang.org/resource/image/92/1d/920601da775da08844d231bc2b4c301d.png
{kind=link}
工具圖譜
https://static001.geekbang.org/resource/image/9e/7a/9ee6c1c5d88b0468af1a3280865a6b7a.png
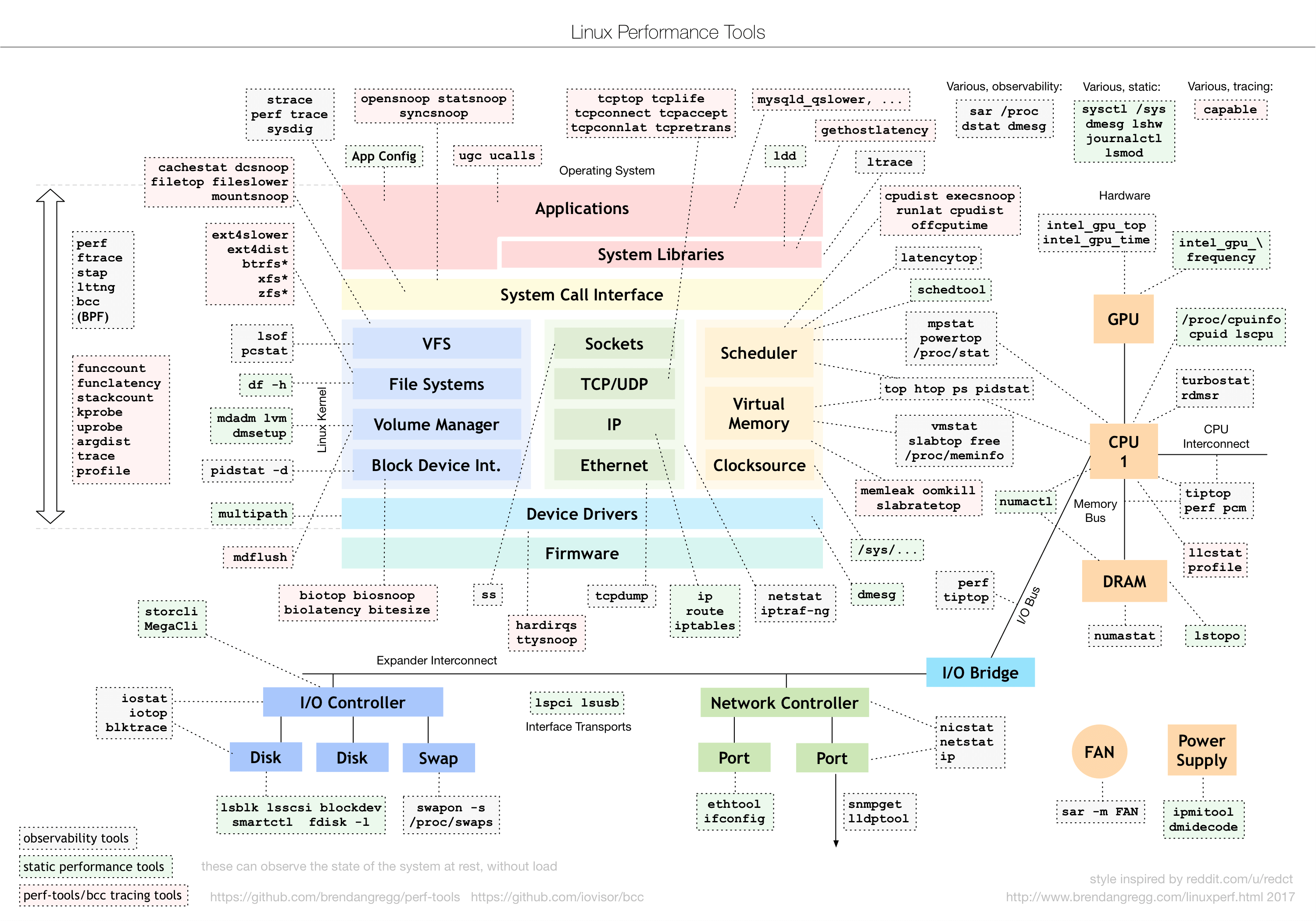{kind=link}
思維導圖
一、什麼是平均負載
正確定義:單位時間內,系統中處於可執行狀態和不可中斷狀態的平均程序數。
錯誤定義:單位時間內的cpu使用率。
可執行狀態的程序:正在使用cpu或者正在等待cpu的程序,即ps aux命令下STAT處於R狀態的程序。
不可中斷狀態的程序:處於核心態關鍵流程中的程序,且不可被打斷,如等待硬體裝置IO響應,ps命令D狀態的程序。
理想狀態:每個cpu上都有一個活躍程序,即平均負載數等於cpu數。
過載經驗值:平均負載高於cpu數量70%的時候。
二、相關命令
cpu核數: lscpu、 grep 'model name' /proc/cpuinfo | wc -l
顯示平均負載:uptime、top,顯示的順序是最近1分鐘、5分鐘、15分鐘,從此可以看出平均負載的趨勢
watch -d uptime: -d會高亮顯示變化的區域
strees: 壓測命令,--cpu cpu壓測選項,-i io壓測選項,-c 程序數壓測選項,--timeout 執行時間
mpstat: 多核cpu效能分析工具,-P ALL監視所有cpu
pidstat: 程序效能分析工具,-u 顯示cpu利用率
三、平均負載與cpu使用率的區別
CPU使用率:單位時間內cpu繁忙情況的統計
情況1:CPU密集型程序,CPU使用率和平均負載基本一致
情況2:IO密集型程序,平均負載升高,CPU使用率不一定升高
情況3:大量等待CPU的程序排程,平均負載升高,CPU使用率也升高
四、平均負載過高時,如何調優
工具:stress、sysstat,yum即可安裝
1. CPU密集型程序case:
mpstat -P ALL 5: -P ALL表示監控所有CPU,5表示每5秒重新整理一次資料,觀察是否有某個cpu的%usr會很高,但iowait應很低
pidstat -u 5 1:每5秒輸出一組資料,觀察哪個程序%cpu很高,但是%wait很低,極有可能就是這個程序導致cpu飈高
2. IO密集型程序case:
mpstat -P ALL 5: 觀察是否有某個cpu的%iowait很高,同時%usr也較高
pidstat -u 5 1:觀察哪個程序%wait較高,同時%CPU也較高
3. 大量程序case:
pidstat -u 5 1:觀察那些%wait較高的程序是否有很多
五、其他推薦工具和命令
htop看負載,更直接(在F2配置中勾選所有開關項,開啟顏色區分功能),不同的負載會用不同的顏色標識。比如cpu密集型的應用,它的負載顏色是綠色偏高,iowait的操作,它的負載顏色是紅色偏高等等,根據這些指標再用htop的sort就很容易定位到有問題的程序。
atop命令,好像是基於sar的統計生成的報告,直接就把有問題的程序標紅了,更直觀。
六、其他問題
現在大多數CPU有超執行緒能力,在計算和評估平均負載的時候,CPU的核數並不是指物理核數,而是指超執行緒功能的邏輯核數。