
通過預測API竊取機器學習模型
由於機器學習可能涉及到訓練資料的隱私敏感資訊、機器學習模型的商業價值及其安全中的應用,所以機器學習模型在一定程度上是可以認為是機密的。但是越來越對機器學習服務提供商將機器學習作為一種服務部署在雲上。筆者認為:這樣部署機器學習即服務是存在安全隱患的,攻擊者利用對模型的API可以竊取模型。
1.問題描述
由於機器學習可能涉及到訓練資料的隱私敏感資訊、機器學習模型的商業價值及其安全領域中的應用(垃圾郵件過濾、惡意軟體檢測、流量分析等),所以機器學習模型在一定程度上是可以認為是機密的。但是,機器學習模型不斷地被部署,通過公共訪問介面訪問模型, 例如機器學習即服務( Machine Learning as a service, MLaaS):使用者可以在MLaaS 平臺利用隱私敏感資料訓練機器學習模型,並且將訪問介面釋出給其他使用者使用,同時收取一定的費用。針對機器學習模型機密性和其公共訪問的矛盾上,筆者提出了機器學習模型提取攻擊:攻擊者在沒有任何關於該模型的先驗知識(訓練資料,模型引數,模型型別等)情況下,只利用公共訪問介面對該模型的黑盒訪問,從而構造出和目標模型相似度非常高的模型。
MLaaS提供商 |
白盒(其他使用者是否可以付費下載模型) |
是否商業化(使用者釋出模型其他使用者使用) |
API是否輸出置信度 |
|---|---|---|---|
亞馬遜 |
√ |
||
微軟 |
√ |
||
BigML |
√ |
||
√ |
|||
√ |
|||
PredictionIO |
|||
√ |
|||
√ |
|||
√ |
|||
表1 MLaaS提供商的主要特點

圖1 機器學習即服務商業化模式
2.攻擊模型
當用戶在MLaaS平臺上訓練了自己的機器學習模型,併發布該模型給其他使用者使用,並利用其他使用者每次對模型的訪問收取一定的費用,賺回自己在訓練模型和標定資料投入時的成本。如果利用API訪問目標模型的是攻擊者,該攻擊者利用對目標模型的儘量少地訪問,試圖在本地構造一個與目標模型相近甚至一致的模型。
筆者認為攻擊可能出於以下目的竊取目標模型:
1. 想免費使用模型:模型訓練者將模型託管在雲上,通過提供API的方式來提供對模型的訪問,通過對每次呼叫 API 的方式來收費,惡意的使用者將企圖偷取這個模型免費使用。這將破壞MLaaS的商業化模式,同時很可能存在這種情況:攻擊者竊取模型所花的費用是低於模型訓練者標定訓練集和訓練模型的成本。
2. 破壞訓練資料隱私性:模型提取攻擊會洩露訓練資料的隱私,越來越多的研究工作表明:利用對模型的多次訪問可以推斷出訓練資料資訊,因為模型本身就是由訓練資料所得到的,分析所提取到的模型,必然可以推斷訓練資料。具體可以參考這篇文章:Membership Inference Attacks against Machine Learning Models .
3.繞過安全檢測:在越來越多的場景中,機器學習模型用於檢測惡意行為,例如垃圾郵件過濾,惡意軟體檢測,網路異常檢測。攻擊者在提取到目標模型後,可以根據相關知識,構造相應的對抗樣本,以繞過安全檢測。參考文章:Evading Classifiers by Morphing in the Dark

圖2 模型提取攻擊場景
3.模型提取攻擊
筆者首先將引入針對輸入返回置信度輸出的場景,然後利用二分類讓大家明白如何實現解方程攻擊,進而講解多分類場景中的方程求解攻擊。由於決策樹演算法的置信度計算和邏輯迴歸(LR)、支援向量機(SVM)、神經網路(NN)演算法不同,筆者還將講解如何提取決策樹模型。同時還進一步討論當預測API隱藏置信度,只輸出分類標籤場景下的模型提取攻擊。
3.1方程求解攻擊
方程求解攻擊針對邏輯迴歸(LR)、支援向量機(SVM)、神經網路(NN)演算法,因為這些演算法的模型不同於樹形模型,這些模型都是函式對映,輸出的置信度是函式的直接輸出,模型的輸入是函式的輸入,該函式由一些列引數組成。也就是說,由置信度和輸入資料可以構造方程,求解函式的引數就可以得到與目標相近的模型。
3.1.1二分類
筆者先從一個簡單的場景引入,不考慮多項迴歸。假設受害者使用者利用MLaaS的LR演算法在其平臺上訓練了一個人臉識別模型,然後受害者想通過把模型釋出給其他使用者使用,並賺取一定的利潤,然後受害者給很多使用者釋出其模型訪問API,這些使用者中有些人想通過對該模型的訪問提取該二分類模型。

圖3 簡單二分類場景
於是該攻擊者通過API訪問模型,其返回是置信度資訊。我們都知道模型只是由一系列引數決定。求解引數就可以實現模型提取。

在二分類中輸出的置信度就是該函式的對映輸出f(x),函式的引數是W,b其中W是一個n維向量,b是偏置。這些圖象是92*112的灰度圖,也就是特徵維數為10304維。對sigmod函式求反函式就可以看出這是包含n+1個引數的函式,而且這些函式是線性函式。在特徵空間足夠大的,且攻擊者隨機訪問的場景下,攻擊者只需要隨機訪問模型n+1次,便可得到n+1個線性的方程組,求解這n+1個引數,便可得到目標模型。

3.1.2 多分類
假設多分類要完成對c個類別分類,置信度則是輸入在每個類別的概率分佈,輸出的置信度是n維向量。

圖4 多分類分類場景
則其輸出的置信度公式是:

其未知引數有c(n+1)(每個類別存在n+1個未知數),當然這個函式是非線性函式,也就是說,通過多次訪問構建的方程組是非線性方程組,而且每個方程都是超越方程。關於這種方程組的求解可以利用梯度下降方法實現,構造一個損失函式為凸函式,轉化為凸優化問題求解,求解全域性最優解也就是該模型的引數。
3.2 決策樹提取攻擊
決策樹的置信度是在給定訓練資料集,就已經確定了,每個葉子節點都有其對應的置信度值,筆者在此假設每個葉子節點都有不同的置信度值,也就說可以通過置信度標定不同的葉子節點:利用置信度作為決策樹葉子節點的偽標識。同時很多MLaaS提供商做為了提升API訪問的可訪問性,MLaaS提供商的做法是即使輸入的資料使部分特徵依然可以得到輸出結果。

圖5 決策樹示例
例如針對上述決策樹:僅輸入Color = Y,依然可以得到id6的置信度輸出。不斷在特徵空間遍歷, 便可以得到和置信度對應的葉子節點。例如我現在得到了id2的偽標識,通過只改其中的Color特徵為B即可找到id3葉子節點。
主要基於兩點假設前提:
1.設每個葉子節點都有不同的置信度值; 2.為了提升API訪問的可訪問性,MLaaS提供商的做法是即使輸入的資料使部分特徵依然可以得到輸出結果。
3.3 對於不考慮置信度的模型提取攻擊
筆者認為:隱藏置信度的輸出仍然不能解決所存在的模型提取攻擊:
1) 首先隨機確定訪問資料,對目標模型進行訪問,並得到預測結果, 2) 利用這些資料集訓練在本地訓練機器學習模型 3) 找到離所訓練機器學習模型分類邊界很近的資料點,然後將這些資料對目標模型訪問 4) 利用輸入資料集和訪問結果更新重訓練模型,重複3 過程直到模型誤差低於一定的值。
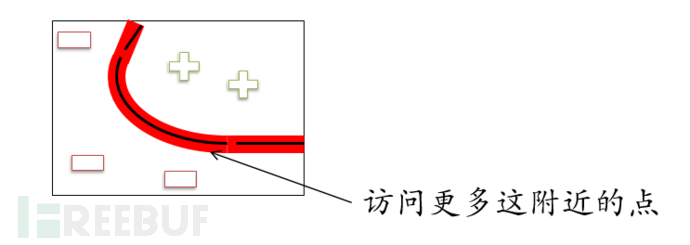具體細節可以閱讀我的GitHub程式碼。
4.總結
MLaaS提供商所提供的靈活的預測API可能被攻擊者用於模型提取攻擊,這種商業化模式在筆者的角度是不安全的,本文提出了三種機器模型提取攻擊方法,同時表明即使不輸出置信度,只輸出類標籤,通過自適應地訪問資料集的方法,模型提取攻擊依然可行。MLaaS的部署應該謹慎考慮,同時MLaaS的安全部署有待進一步研究。