
《怪物獵人崛起》散彈重弩畢業配裝推薦
- 一、存取資料的演變史
- 二、資料庫軟體應用史
- 三、資料庫的本質
- 四、資料庫的分類
- 五、MySQL簡介
- 六、MySQL基本使用
-
七、將MySQL服務製作成系統服務
- 八、密碼相關操作
- 九、SQL與NoSQL
- 十、資料庫重要概念
- 十一、基本SQL語句
-
十二、字元編碼與配置檔案
- 十三、資料庫儲存引擎
- 十四、建立表的完整語法
- 十五、欄位型別之整型
- 十六、嚴格模式
- 十七、欄位型別之浮點型
- 十八、欄位型別之字元型別
- 十九、數字的含義
- 二十、欄位型別之列舉(enum)與集合集合(set)
- 二十一、欄位型別之日期型別
- 二十二、主題:欄位約束條件
- 二十三、SQL語句查詢關鍵字
- 二十四、前期資料準備
- 二十五、編寫SQL語句的小技巧
- 二十六、查詢關鍵字之where篩選
- 二十七、查詢關鍵字之group by分組
- 二十八、查詢關鍵字之having過濾
- 二十九、查詢關鍵字之distinct去重
- 三十、查詢關鍵字之order by排序
- 三十一、查詢關鍵字之limit分頁
- 三十二、查詢關鍵字之regexp正則表示式
- 三十三、多表查詢的思路
一、存取資料的演變史
1、文字檔案
使用文字檔案儲存資料的時候路徑不固定資料格式不統一,一旦更換裝置就容易出現無法使用的情況。
檔案路徑不固定:C:\aaa.txt D:\bbb.txt E:\ccc.txt
資料格式不統一:jason|123 jason$123 jason 123
2、軟體開發目錄規範
規定了資料應該儲存在db目錄下>>>:路徑偏向統一。
db/user.txt
db/userinfo.txt
db/jason.json
db/jason(比如使用pocket模組儲存物件)
但是資料格式還是沒有得到統一,有文字、json格式、物件等資料儲存格式。
3、資料庫服務(重點)
特點
統一路徑,統一操作方式
降低學習成本,提高開發效率
1.資料庫管理軟體的由來
基於我們之前所學,資料要想永久儲存,都是保存於檔案中,毫無疑問,一個檔案僅僅只能存在於某一臺機器上。
如果我們暫且忽略直接基於檔案來存取資料的效率問題,並且假設程式所有的元件都執行在一臺機器上,那麼用檔案存取資料,並沒有問題。
很不幸,這些假設都是你自己意淫出來的,上述假設存在以下幾個問題。。。。。。
①程式所有的元件就不可能執行在一臺機器上
- 因為這臺機器一旦掛掉則意味著整個軟體的崩潰,並且程式的執行效率依賴於承載它的硬體,而一臺機器機器的效能總歸是有限的,受限於目前的硬體水平,就一臺機器的效能垂直進行擴充套件是有極限的。
- 於是我們只能通過水平擴充套件來增強我們系統的整體效能,這就需要我們將程式的各個元件分佈於多臺機器去執行。
②資料安全問題
- 根據1的描述,我們將程式的各個元件分佈到各臺機器,但需知各元件仍然是一個整體,言外之意,所有元件的資料還是要共享的。但每臺機器上的元件都只能操作本機的檔案,這就導致了資料必然不一致。
- 於是我們想到了將資料與應用程式分離:把檔案存放於一臺機器,然後將多臺機器通過網路去訪問這臺機器上的檔案(用socket實現),即共享這臺機器上的檔案,共享則意味著競爭,會發生資料不安全,需要加鎖處理。。。。
③併發
根據2的描述,我們必須寫一個socket服務端來管理這臺機器(資料庫伺服器)上的檔案,然後寫一個socket客戶端,完成如下功能:
- 1.遠端連線(支援併發)
- 2.開啟檔案
- 3.讀寫(加鎖)
- 4.關閉檔案
總結
我們在編寫任何程式之前,都需要事先寫好基於網路操作一臺主機上檔案的程式(socket服務端與客戶端程式),於是有人將此類程式寫成一個專門的處理軟體,這就是mysql等資料庫管理軟體的由來,但mysql解決的不僅僅是資料共享的問題,還有查詢效率,安全性等一系列問題,總之,把程式設計師從資料管理中解脫出來,專注於自己的程式邏輯的編寫。
二、資料庫軟體應用史
1.單機遊戲
資料儲存於各個計算機的本地 無法共享
2.網路遊戲
資料儲存於網路中 可以共享(資料庫服務)
資料庫服務叢集:提升資料的安全性
三、資料庫的本質
1.站在底層原理的角度
資料庫指的是操作資料的程序(一堆程式碼)
2.站在實際應用的角度
資料庫指的是視覺化操作介面(一些軟體)
ps:以後不做特殊說明的情況下講資料庫其實指的是資料庫軟體
資料庫軟體本質也是CS架構的程式。這意味著所有的程式設計師其實都有資格編寫一款資料庫軟體,只不過我們短時間內沒這個水平。
四、資料庫的分類
1.關係型資料庫
特徵1:擁有固定的表結構(欄位名 欄位型別)
id name pwd
特徵2:資料之間可以建立資料庫層面關係
使用者表資料
豪車表資料
豪宅表資料
常見的關係型資料庫:
MySQL、Oracle(中文叫甲骨文)、MariaDB、PostgreSQL、sql server、sqlite、db2、access
1.MySQL:開源免費,使用最廣,價效比賊高。
主要用於大型門戶,例如搜狗、新浪等,它主要的優勢就是開放原始碼。
因為開放原始碼,這個資料庫是免費的,他現在是甲骨文公司的產品。
2.Oracle:收費,使用成本較高。但是安全性也是最高的。
主要用於銀行、鐵路、飛機場等。該資料庫功能強大,軟體費用高。也是甲骨文公司的產品。
3.PostgreSQL:開源免費並且支援二次開發,相容性極高。
4.MariaDB:跟MySQL是一個作者,開源免費。
SUN被甲骨文收購後,MySQL 的原創人員有拉出另外一個分支,命名MariaDB 。該資料庫被維基百科,Facebook 甚至 Google等技術巨頭使用。
MariaDB 是一種可為 MySQL 提供外掛替換功能的資料庫伺服器。開發人員的首要關注點是安全性,在每個版本釋出時,開發人員還會合並所有 MySQL 的安全修補程式,並在需要時對其進行增強。
5.sqlite:小型資料庫,主要用於本地測試
2.非關係型資料庫
特徵1:沒有固定的表結構 資料儲存採用K:V鍵值對的形式
{'name':'jason'}
{'username':'kevin','pwd':123}
特徵2:資料之間無法建立資料庫層面的關係
- 雖然不能建立資料庫層面的關係,但是我們可以自己編寫程式碼建立邏輯層面的關係。
redis、mongoDB、memcache
1.redis:目前最火、使用頻率最高的非關係型資料庫(快取資料庫)
雖然快取資料庫是基於記憶體做資料存取但是擁有持久化的功能,也就是有自動儲存和寫日誌的功能。
2.mongoDB:文件型資料庫 最像關係型資料庫的非關係型資料庫
主要用在爬蟲以及大資料領域
3.memcache:以及被redis淘汰
雖然資料庫軟體有很多 但是操作方式大差不差 學會了一個幾乎就可以學會所有
其中以MySQL最為典型
五、MySQL簡介
1.版本問題
8.0:最新版
5.7:使用頻率較高
5.6:學習推薦使用
ps:站在開發的角度使用哪個版本學習都沒有關係,但是新版的軟體封裝了一些功能,不需要我們自己操作了,對於學習者來說應該親自實踐一下更好。
2、MySQL軟體下載及安裝見部落格
MySQL軟體安裝教程(windows系統):
https://www.cnblogs.com/zhihuanzzh/p/16915579.html
3.主要目錄介紹
bin目錄
存放啟動檔案
mysqld.exe(服務端) mysql.exe(客戶端)
data目錄
存放核心資料
my-default.ini
預設的配置檔案
readme
軟體說明
六、MySQL基本使用
當我們剛下載完MySQL的安裝包解壓到指定目錄後其實已經可以使用MySQL了。只是需要開兩個cmd窗口才能使用MySQL服務
開啟步驟講解:
1、先開啟cmd視窗(cmd建議使用管理員身份開啟)
2、切換到mysql的bin目錄下先啟動服務端
mysqld
3、保持視窗不關閉 重新開啟一個新的cmd視窗
4、切換到mysql的bin目錄下啟動客戶端
mysql
ps:直接使用mysql命令預設是遊客模式 許可權和功能都很少
使用使用者名稱登陸的指令
mysql -u使用者名稱 -p密碼
管理員預設沒有密碼,連續回車即可(有密碼就輸入)
mysql -uroot -p密碼
有些同學的電腦在啟動服務端的時候就會報錯,不要慌。拷貝報錯資訊,然後百度搜索:
mysql啟動報錯(後面貼上錯誤資訊)
七、將MySQL服務製作成系統服務
1、把bin目錄新增到環境變數
先清空之前開啟的cmd視窗,一定要把之前用cmd啟動的服務端關閉(ctrl+c)
1.右鍵計算機,點選屬性
2.點選高階系統設定
3.在彈出的視窗中點選環境變數
4.雙擊第二個內容框(系統變數)中的path
5.在彈出的新視窗中點選新建,然後輸入bin資料夾的路徑
ps:將MySQL的bin目錄路徑追加到環境變數中時,win7需要用;分割。
2、將MySQL服務製作成windows系統服務(相當於把MySQL服務製作成系統的守護程序)
將MySQL服務製作成windows系統服務後就不需要使用cmd開啟MySQL服務端了。
1.如何檢視系統服務
方式一:
同時按住ESC鍵+SHIFT鍵+CTRL鍵開啟工作管理員,然後點選側邊欄中最後一個選項就可以檢視系統服務
方式二:
同時按住win鍵和R鍵,輸入services.msc,然後按回車,就能開啟服務介面
2.製作MySQL的Windows服務
步驟一:以管理員身份開啟cmd視窗
步驟二:輸入指令
mysqld --install
3.首次新增MySQL服務後並不會自動啟動,需要認為操作一下
開啟方式一:選中MySQL服務右鍵,然後點選啟動
開啟方式二:使用cmd輸入程式碼啟動
開啟後我們可以去服務視窗檢視狀態
3.如何解除安裝
步驟一:先關閉服務端
開啟cmd,輸入指令:net stop mysql
步驟二:移除系統服務
接著輸入指令:mysqld --remove
八、密碼相關操作
1.修改密碼
方式1:mysqladmin
輸入下列指令:
mysqladmin -u使用者名稱 -p原密碼 password 新密碼
方式2:直接修改儲存使用者資料的表
如何檢視儲存使用者資料的表
select * from mysql.user\G
這裡如果不在末尾跟上\G讀取的內容會出現格式錯亂,跟上\G後可以一行行展示檔案內容。
方式3:冷門操作 有些版本可能還不支援
set password=password('新密碼') # 修改當前登入使用者的密碼
2.忘記密碼的解決方法
方式1:解除安裝重新裝
方式2:把data目錄刪除 拷貝同桌的目錄
這裡就相當於用你同桌的資訊登陸
方式3:小把戲操作
1.關閉正常的服務端
net stop mysql
2.以跳過授權表的方式重啟服務端(不校驗密碼)
mysqld --skip-grant-table
3.以管理員身份進入然後修改mysql.user表資料即可
mysql -uroot -p
update mysql.user set password=password('123') where Host='localhost' and User='root';
最後一行的程式碼的作用是設定root賬號的密碼為123
4.關閉服務端 然後以正常方式啟動即可
九、SQL與NoSQL
資料庫服務端是可以服務多種型別的客戶端,客戶端可以是自己開發的,也可以是python程式碼編寫,也可以是java程式碼編寫,但是這樣就導致了資料庫服務端操作會變得複雜。
SQL和NoSQL就相當於是資料庫服務端規定了客戶端操作服務端的資料時需要使用的語言。
SQL(操作關係型資料庫的語言)
SQL結構化查詢語言是一種資料庫操作的非程序式程式設計語言,用於存取資料以及查詢、更新和管理關係型資料庫系統,一般指令碼檔案字尾為.sql。
NoSQL(操作非關係型資料庫的語言)
NoSQL泛指非關係型資料庫,主要用於針對超大規模和高併發的社交SNS型別網站的解決方案
ps:要想跟資料庫互動就必須使用資料庫指定的語言。
SQL有時候也指代關係型資料庫。
NoSQL有時候也指代非關係型資料庫。
SQL 和 NoSQL對比
複雜查詢SQL資料庫比較擅長;
SQL資料庫不適合分層次的資料儲存,NoSQL可以很好的實現資料的分層次儲存,更適合大資料;
對於要求資料嚴格一致性的應用中SQL非常使用,而且穩定,能夠保證資料操作的原子性和一致
性;而NoSQL對事務的處理能力有限,一般保證最終一致性;
SQL廠商支援,而NoSQL是社群支援;
效能對比中,NoSQL明顯優於SQL資料庫,一般NoSQL都充分的利用系統的記憶體資源;
NoSQL資料庫開發方便,不用考慮資料關係和格式。
十、資料庫重要概念
什麼是資料庫伺服器
執行有DBMS服務端的計算機,該計算機對記憶體和硬碟要求都相對較高
什麼是資料庫管理系統(DataBase Management System 簡稱DBMS)
管理資料的套接字軟體,CS架構
什麼是庫(DataBase,簡稱DB)
資料夾
什麼是表
檔案
什麼是記錄
一組資料構成一條記錄,相當於檔案中的一行內容,如1,jason,male,18
什麼是資料(Data)
事物的狀態
舉例
強調:小白階段為了更加方便的理解,做了以下比喻,本質其實有一點點的區別。
庫 就相當於是 資料夾
表 就相當於是 資料夾裡面的檔案
記錄 就相當於是 資料夾裡面的檔案中的一行行資料
驗證指令
1.檢視所有的庫名稱
show databases;
2.檢視所有的表名稱
show tables;
3.檢視所有的記錄
select * from mysql.user;
十一、基本SQL語句
注意事項
1.sql語句必須以分號結尾
2.sql語句編寫錯誤之後不用擔心 可以直接執行報錯即可
基於庫的增刪改查指令
1.建立庫
create database 庫名;
庫檔案會建立在MySQL資料夾內的data資料夾內。
2.檢視庫
show databases; 檢視所有的庫名稱
其中上圖中放的information_schema存在於記憶體中
show create database 庫名; 檢視指定庫資訊
3.編輯庫
alter database 庫名 charset='utf8';
修改字元編碼型別(預設情況是latinl——拉丁文)
4.刪除庫
drop database 庫名;
基於表的增刪改查
操作表之前需要先建立庫庫
create database db1;
然後切換操作庫
use db1;
1.建立表
create table 表名(欄位名 欄位型別,欄位名 欄位型別);
2.查看錶
show tables; 檢視庫下所有的表名稱
show create table 表名; 檢視指定表資訊
describe 表名; 查看錶結構
desc 表名;
ps:如果想跨庫操作其他表 只需要在表名前加庫名即可
desc mysql.user;
3.編輯表
alter table 表名 rename 新表名;
4.刪除表
drop table 表名;
基於記錄的增刪改查
1.插入資料
insert into 表名 values(資料值1,資料值2);
有幾個欄位名插入幾個值
2.查詢資料
select * from 表名;
查詢表中所有的資料
3.編輯資料
update 表名 set 欄位名=新資料 where 篩選條件;
4.刪除資料
delete from 表名;
後面不寫where篩選的話就會刪除表中的所有資料。
delete from 表名 where id=2;
十二、字元編碼與配置檔案
昨天我們講解到MySQL資料夾內的my-default.ini檔案是配置檔案,這裡我們講一些簡單的配置設定。
ps:修改配置檔案後需要重新啟動MySQL服務才能生效。
mysql配置檔案的作用
1.影響服務端的啟動(mysqld)
2.影響客戶端的連線
1.\s——檢視MySQL相關資訊
登陸MySQL後使用\s命令後就可以檢視當前使用者、版本、編碼、埠號。
MySQL5.6及之前的版本編碼需要人為統一 之後的版本已經全部預設統一。如果想要永久修改編碼配置,需要操作配置檔案。
2.配置檔案修改預設字元編碼型別
預設的配置檔案是my-default.ini
但是我們在使用的時候不建議直接修改預設的配置檔案,理想的操作應該是拷貝上述檔案並重命名為my.ini,然後再my.ini中修改配置。
配置檔案開啟後分成兩部分內容,一部分是註釋,一部分是配置程式碼。註釋部分在每一行的開頭有井號(#)。
ps:配置檔案中的註釋可以有中文,但是配置程式碼中不能出現中文。
配置程式碼
直接拷貝字元編碼相關配置即可無需記憶
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
ps:
1.utf8mb4能夠儲存表情 功能更強大
2.utf8與utf-8是有區別的 MySQL中只有utf8
修改了配置檔案中關於[mysqld]的配置 需要重啟服務端
3.利用配置檔案免輸入賬號資訊登陸
將管理員登入的賬號密碼直接寫在配置檔案中,之後使用mysql登入即可。
程式碼如下:
[mysql]
user='root'
password=123
十三、資料庫儲存引擎
1、儲存引擎
資料庫針對資料採取的多種存取方式。儲存引擎是資料庫底層軟體元件,資料庫管理系統(DBMS)使用資料引擎進行建立、查詢、更新和刪除資料庫操作。不同的儲存引擎提供不同的儲存機制、索引技巧、鎖定水平等功能。使用不同的儲存引擎,還可以獲得特定的功能。現在許多不同的資料庫管理系統都支援多種不同的資料引擎。MySQL的核心就是儲存引擎。
2、檢視儲存引擎的語句
show engines;
3、需要了解的四個儲存引擎
1.MyISAM
MySQL5.5(包括5.5版本)之前預設使用的的儲存引擎。
存取資料的速度快,但是功能較少,安全性較低。
2.InnoDB
MySQL5.5之後預設使用的的儲存引擎。
支援事務、行鎖、外來鍵等操作,雖然存取速度沒有MyISAM快,但是安全性更高。
3.Memory
基於記憶體存取資料,僅用於臨時表資料存取。
4.BlackHole
任何寫入進去的資料都會立刻丟失。
4、瞭解不同儲存引擎底層檔案個數
用各個儲存引擎建立不同的表,然後去檢視檔案個數(如果不是5.6版本可能檔案個數會不一樣)。
create database db2;
use db2;
create table t1(id int) engine=innodb;
create table t2(id int) engine=myisam;
create table t3(id int) engine=memory;
create table t4(id int) engine=blackhole;
1.innodb有兩個檔案
.frm 表結構
.ibd 表資料(表索引也放一起了)
2.myisam有三個檔案
.frm 表結構
.MYD 表資料
.MYI 表索引
3.memory只有一個檔案
.frm 表結構
4.blackhole只有一個檔案
.frm 表結構
建立了表之後我們加入資料
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
ps:MySQL預設忽略大小寫
十四、建立表的完整語法
語法
create table 表名(
欄位名 欄位型別(數字) 約束條件,
欄位名 欄位型別(數字) 約束條件,
欄位名 欄位型別(數字) 約束條件
);
1.欄位名和欄位型別是必須的
2.數字和約束條件是可選的
3.約束條件也可以寫多個 空格隔開即可
4.最後一行結尾不能加逗號
常見約束
not null 非空
default 預設值
auto_increment 自增長
primary key 主鍵 非空且唯一
ps:編寫SQL語句報錯之後不要慌,仔細檢視提示,他會告知語句的什麼位置疑似有錯誤,通過提示可以很快解決問題。
十五、欄位型別之整型
概念
整型主要用於儲存整數值,主要有以下幾個欄位型別:
這裡的範圍是根據位元組大小計算得到的(一個位元組等於八位二進位制)。
整型經常被用到,比如 tinyint、smallint、int、bigint 。預設是有符號的,符號會佔用一個位元組(bytes),若只需儲存無符號值,可增加 unsigned 屬性。
int(M)中的 M 代表最大顯示寬度,並不是說 int(1) 就不能儲存數值10了,不管設定了顯示寬度是多少個字元,int 都是佔用4個位元組,即int(5)和int(10)可儲存的範圍一樣。
儲存位元組越小,佔用空間越小。所以本著最小化儲存的原則,我們要儘量選擇合適的整型,例如:儲存一些狀態值或人的年齡可以用 tinyint ;主鍵列,無負數,建議使用 int unsigned 或者 bigint unsigned,預估欄位數字取值會超過 42 億,使用 bigint 型別。
驗證整型預設是否攜帶正負號
需要先在配置檔案中刪除下列資訊:
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
不刪除的情況下就屬於嚴格模式。
輸入下列程式碼建立表(用上tinyint欄位型別)並新增資料值
create table t5(id tinyint);
insert into t5 values(-129),(128);
結果是-128和127,也就意味著預設情況下是自帶正負號的。
我們也可以用unsigned取消正負號
create table t6(id tinyint unsigned);
insert into t6 values(-129),(128),(1000);
取消正負號後最小就是0,最大255.
十六、嚴格模式
當我們在使用資料庫儲存資料的時候,如果資料不符合規範,應該直接報錯而不是擅自修改資料,這樣會導致資料的失真(沒有實際意義)。
在測試整形欄位是否自帶正負號的時候,就出現了失真的情況。正常都應該報錯。但是我們之前不小心改了配置檔案。
使用下方程式碼可以檢視是否啟動了嚴格模式:
show variables like '%mode%';
1.臨時修改
set session sql_mode='strict_trans_tables';
在當前客戶端有效
set global sql_mode='strict_trans_tables';
在當前服務端有效
修改後的結果
2.永久修改
直接修改配置檔案在mysqld下方加上如下程式碼:
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
十七、欄位型別之浮點型
概念
浮點型主要有 float,double 兩個,浮點型在資料庫中存放的是近似值,例如float(6,3),如果插入一個數123.45678,實際資料庫裡存的是123.457。
語法簡介
float(20,10)
總共儲存20位數,小數點後面佔10位數。
定點型欄位型別有 decimal 一個,主要用於儲存有精度要求的小數。
對於宣告語法 DECIMAL(M,D) ,自變數的值範圍如下:
M是最大位數(精度),範圍是1到65。可不指定,預設值是10。
D是小數點右邊的位數(小數位)。範圍是0到30,並且不能大於M,可不指定,預設值是0。
例如欄位 salary DECIMAL(5,2),能夠儲存具有五位數字和兩位小數的任何值,因此可以儲存在salary列中的值的範圍是從-999.99到999.99。
程式碼驗證精確度
float(20,10)
總共儲存20位數 小數點後面佔10
double(20,10)
總共儲存20位數 小數點後面佔10
decimal(20,10)
總共儲存20位數 小數點後面佔10
create table t7(id float(60,20));
create table t8(id double(60,20));
create table t9(id decimal(60,20));
insert into t7 values(1.11111111111111111111);
insert into t8 values(1.11111111111111111111);
insert into t9 values(1.11111111111111111111);
我們會發現儲存在表中的資料精確度不一樣,float欄位型別的精確度最低,其次是double,decimal精確度最高。
三者的核心區別在於精確度不同
float < double < decimal
十八、欄位型別之字元型別
概念
字串型別也經常用到,常用的幾個型別如下表:
其中 char 和 varchar 是最常用到的。char 型別是定長的,MySQL 總是根據定義的字串長度分配足夠的空間。當儲存 char 值時,在它們的右邊填充空格以達到指定的長度,當檢索到 char 值時,尾部的空格被刪除掉。varchar 型別用於儲存可變長字串(即變長),儲存時,如果字元沒有達到定義的位數,也不會在後面補空格。
char(M) 與 varchar(M) 中的的 M 表示儲存的最大字元數,單個字母、數字、中文等都是佔用一個字元。char 適合儲存很短的字串,或者所有值都接近同一個長度。例如,char 非常適合儲存密碼的 MD5 值,因為這是一個定長的值。對於字串很長或者所要儲存的字串長短不一的情況,varchar 更加合適。
我們在定義欄位最大長度時應該按需分配,提前做好預估,能使用 varchar 型別就儘量不使用 text 型別。除非有儲存長文字資料需求時,再考慮使用 text 型別。
程式碼檢視char和varchar的實際情況
create table t10(id int, name char(4));
create table t11(id int, name varchar(4));
insert into t10 values(1, 'jason1');
insert into t11 values(1, 'jason2');
ps:char_length()獲取欄位儲存的資料長度
預設情況下MySQL針對char的儲存會自動填充空格和刪除空格
因此我們需要使用set global進行設定,在設定的時候需要把之前設定的指令也寫上,否則會之前的指令就不生效了。
set global sql_mode='strict_trans_tables,pad_char_to_full_length';
接著使用
select char_length(name) from t10;
select char_length(name) from t11;
就能看到字元的長度變成了4和1
char和varchar對比
char
優勢:整存整取 速度快
劣勢:浪費儲存空間
varchar
優勢:節省儲存空間
劣勢:存取資料的速度較char慢
比如在儲存下方的字元時,char欄位型別使用空格填充,varchar就需要使用報頭,記錄每一次記錄的字元的長度,而報頭需要佔用一個位元組
jacktonyjasonkevintomjerry
1bytes+jack1bytes+tony1bytes+jason1bytes+kevin1bytes+tom1bytes+jerry
十九、數字的含義
- 數字在很多地方都是用來表示限制儲存資料的長度,但是在整型中數字卻不是用來限制儲存長度,是用來設定展示長度的(即列印長度),預設情況下(也就是括號內不寫數字)int括號內的引數是11。
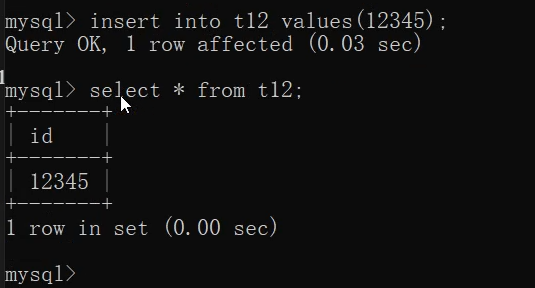
create table t12(id int(3)); 不是用來限制長度
insert into t12 values(12345);
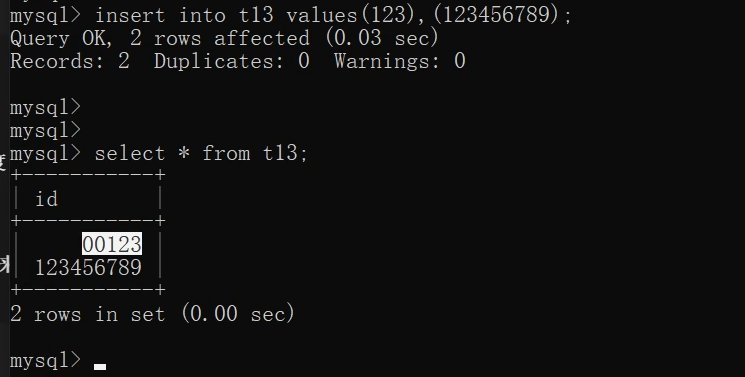
create table t13(id int(5) zerofill); 而是用來控制展示的長度
insert into t13 values(123),(123456789);
create table t14(id int);
"""以後寫整型無需新增數字"""
二十、欄位型別之列舉(enum)與集合集合(set)
enum列舉是多選一,像python布林型別,
set集合是多選一或多
列舉
多選一
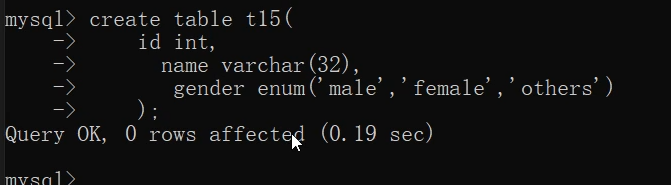
create table t15(
id int,
name varchar(32),
gender enum('male','female','others')
);
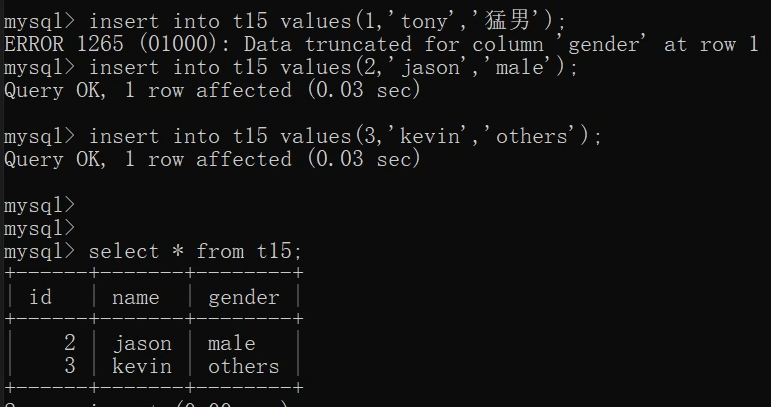
insert into t15 values(1,'tony','猛男');
insert into t15 values(2,'jason','male');
insert into t15 values(3,'kevin','others');
意思就是在給表新增記錄的時候,列舉型別的值只能從建立時設定的值中選一個,否則都會報錯。
集合
多選多(多選一)
create table t16(
id int,
name varchar(16),
hobbies set('basketabll','football','doublecolorball')
);
insert into t16 values(1,'jason','study');
insert into t16 values(2,'tony','doublecolorball');
insert into t16 values(3,'kevin','doublecolorball,football');
集合的選擇條件是讓我們在給定的資料值中選擇一個或多個,如果一個也沒有就會報錯。
二十一、欄位型別之日期型別
概念
MySQL支援的日期和時間型別有 YEAR 、TIME 、DATE 、DATETIME 、TIMESTAMP,幾種型別比較如下:
涉及到日期和時間欄位型別選擇時,根據儲存需求選擇合適的型別即可。
datetime 年月日時分秒
date 年月日
time 時分秒
year 年
關於 DATETIME 與 TIMESTAMP 兩種型別如何選用,可以按照儲存需求來,比如要求儲存範圍更廣,則推薦使用 DATETIME ,如果只是儲存當前時間戳,則可以使用 TIMESTAMP 型別。不過值得注意的是,TIMESTAMP 欄位資料會隨著系統時區而改變但 DATETIME 欄位資料不會。總體來說 DATETIME 使用範圍更廣。
實操程式碼
create table t17(
id int,
name varchar(32),
register_time datetime,
birthday date,
study_time time,
work_time year
);
insert into t17 values(1,'jason','2000-11-11 11:11:11','1998-01-21','11:11:11','2000');
ps:以後涉及到日期相關欄位一般都是系統自動獲取 無需我們可以操作
二十二、主題:欄位約束條件
- 什麼是欄位約束
簡而言之,欄位約束就是將欄位的內容定一個規則,我們要按照規則辦事,常見的欄位約束有下面幾個。
- 欄位約束的作用
1、保證資料的完整性
描述:我們有時候填表會發現有些是必填項,這裡就是not null的作用,他要求這個表格不能為空,獲取我們完整的資訊。
2、保證資料的有效性
描述:在這裡我們假設一個個場景,要是張三的電話號碼是123×××××××45,那麼李四的電話號碼絕對不會和張三一摸一樣,這裡就體現出unique的作用了
- 常用的約束條件作用概述
| 約束條件 | 作用 |
|---|---|
| unsigned | 去掉正負號 |
| zerofill | 欄位資料長度不夠用0填充 |
| not null | 讓欄位資料不能為空 |
| default | 設定欄位預設值 |
| unique | 設定欄位資料唯一 |
| primary key | 主鍵,不能為空且唯一 |
一、無符號、零填充
無正負符號
儲存記錄的時候取消正負號,這時候就只能儲存0~max的資料值。
關鍵字:unsigned
id int unsigned
欄位資料長度不夠用0填充
昨天學習後我們瞭解到,int欄位括號內數字的作用是控制輸出的長度,這裡用上zerofill之後,如果輸入333就會把前面空著的兩個位置用0填充。
關鍵字:zerofill
id int(5) zerofill
二、非空
關鍵字:not null
作用描述:當我們預設情況下建立欄位的時候,是可以輸入null讓值為空的,但是加上not null之後就不能空著不輸入該欄位的值了,但是我們輸入'',這樣的空資訊卻是可以在not null條件下輸入進去的,並且在檢視的時候該欄位在該條記錄對應的值就是空的。
create table t1(
id int,
name varchar(16)
);
insert into t1(id) values(1);
insert into t1(name) values('jason');
insert into t1(name,id) values('kevin',2);
我們發現預設情況下,也就是不設定欄位約束的情況下,欄位值是可以為空的,結果如下:
ps:所有欄位型別不加約束條件的情況下預設都可以為空
create table t2(
id int,
name varchar(16) not null
);
insert into t2(id) values(1);
insert into t2(name) values('jason');
insert into t2 values(1,'');
insert into t2 values(2,null);
這裡我們發現添加了欄位約束後我們新增記錄的時候如果出現空的值就會報錯。
三、預設值
關鍵字:default 預設值
作用描述:當我們設定了預設值欄位約束的時候,可以在後面設定預設值,在新增記錄的時候如果輸入了值,就會使用輸入的值,否則就會用預設值填充(可以跟python中的關鍵字引數類比記憶)。
create table t3(
id int default 666,
name varchar(16) default '匿名'
);
insert into t3(id) values(1);
insert into t3(name) values('jason');
insert into t3 values(2,'kevin');
四、唯一值
關鍵字:unique
作用描述:分成單列唯一和多列唯一兩種使用方式,單列唯一就很好理解,一個欄位內的所有資料值不能重複。多列唯一的意思是設定多列唯一的幾個欄位中的資料組合起來不能相同。
單列唯一
'''單列唯一'''
create table t4(
id int unique,
name varchar(32) unique
);
insert into t4 values(1,'jason'),(2,'jason');
這裡我們就是用兩個相同的資料值測試唯一性。結果如下:
多列唯一
'''聯合唯一'''
create table t5(
id int,
ip varchar(32),
port int,
unique(ip,port)
);
insert into t5 values(1,'127.0.0.1',8080),(2,'127.0.0.1',8081),(3,'127.0.0.2',8080);
insert into t5 values(4,'127.0.0.1',8080);
這裡我們在新增第四條記錄的時候會報錯,原因就是我們的第四條記錄跟第一條記錄的ip和port的值組合起來之後重複了。
五、主鍵
關鍵字:primary key
作用描述:單從約束層面上而言主鍵相當於not null + unique(非空且唯一)
ps:主鍵分成單列主鍵和聯合主鍵,聯合主鍵跟多列唯一用法一樣,但是用的較少。
程式碼驗證主鍵作用
create table t6(
id int primary key,
name varchar(32)
);
insert into t6(name) values('jason');
insert into t6 values(1,'kevin');
insert into t6 values(1,'jerry');
結果如下:
InnoDB儲存引擎規定一張表必須有且只有一個主鍵
InnoDB儲存引擎規定了所有的表都必須有且只有一個主鍵(主鍵是組織資料的重要條件並且主鍵可以加快資料的查詢速度),因此當我們沒有新增主鍵的時候InnoDB儲存引擎會自動設定一個欄位當作主鍵,有以下兩種設定方式:
方式一:
當表中沒有主鍵也沒有其他非空切唯一的欄位的情況下。
InnoDB會採用一個隱藏的欄位作為表的主鍵,隱藏意味著無法使用,基於該表的資料查詢只能一行行查詢,速度很慢。
方式二:
當表中沒有主鍵但是有其他非空且唯一的欄位,那麼會從上往下將第一個該欄位自動升級為主鍵。
create table t7(
id int,
age int not null unique,
phone bigint not null unique,
birth int not null unique,
height int not null unique
);
ps:我們在建立表的時候應該有一個欄位用來標識資料的唯一性,並且該欄位通常情況下就是'id'(編號)欄位。
id nid sid pid gid uid
0create 0table userinfo(
uid int primary key,
);
六、自增
功能簡介
關鍵字:auto_increment
作用描述:在設定了自增的欄位下,我們如果不輸入對應的資料值,他會自動給值,同時也會在下一次記錄資料值的時候自動把上一次的值加一當作結果繫結給下一次的記錄,前提是這一次記錄資料值的時候也沒有給定值。
特殊情況1
把表的id欄位設定成自增,然後在新增第一條記錄,我們把id的值設定成200,後續新增記錄的時候如果沒有給定id 的值,就會從200開始自增。
特殊情況2
把表的id欄位設定成自增,然後在新增第一條記錄,我們把id的值設定成200,如果再次新增一條記錄id的值也是200的話,就會報錯。
特殊情況3
把表的id欄位設定成自增,然後在新增第一條記錄,我們把id的值設定成200,接著再新增幾條資料值,讓他自增,接著我們刪除id為200的記錄,我們就可以在新增記錄的時候重新新增一條id欄位值為200的記錄。
ps:該約束條件不能單獨出現,並且一張表中只能出現一次,主要就是配合主鍵一起用。
create table t8(
id int primary key,
name varchar(32)
);
create table t9(
id int primary key auto_increment,
name varchar(32)
);
insert into t8 values(200,'zzh');
insert into t8(name) values('jason');
結果如下:
特性描述
自增特性
自增不會因為資料的刪除而回退 永遠自增往前
如果自己設定了更大的數 則之後按照更大的往前自增
如果想重置某張表的主鍵值 可以使用
truncate t9;
清空表資料並重置主鍵。
七、外來鍵前戲
1、外來鍵的定義
外來鍵是某個表中的一列,它包含在另一個表的主鍵中。
外來鍵也是索引的一種,是通過一張表中的一列指向另一張表中的主鍵,來對兩張表進行關聯。
一張表可以有一個外來鍵,也可以存在多個外來鍵,與多張表進行關聯。
2、外來鍵的作用
外來鍵的主要作用是保證資料的一致性和完整性,並且減少資料冗餘。
主要體現在以下兩個方面:
阻止執行
從表插入新行,其外來鍵值不是主表的主鍵值便阻止插入。
從表修改外來鍵值,新值不是主表的主鍵值便阻止修改。
主表刪除行,其主鍵值在從表裡存在便阻止刪除(要想刪除,必須先刪除從表的相關行)。
主表修改主鍵值,舊值在從表裡存在便阻止修改(要想修改,必須先刪除從表的相關行)。
級聯執行
這裡需要提前設定
on update cascade
on delete cascade
關聯主表和從表
主表刪除行,連帶從表的相關行一起刪除。
主表修改主鍵值,連帶從表相關行的外來鍵值一起修改。
3、外來鍵建立限制
父表必須已經存在於資料庫中,或者是當前正在建立的表。
如果是後一種情況,則父表與子表是同一個表,這樣的表稱為自參照表,這種結構稱為自參照完整性。
必須為父表定義主鍵。
外來鍵中列的數目必須和父表的主鍵中列的數目相同。
兩個表必須是 InnoDB 表,MyISAM 表暫時不支援外來鍵。
外來鍵列必須建立了索引,MySQL 4.1.2 以後的版本在建立外來鍵時會自動建立索引,但如果在較早的版本則需要顯式建立。
外來鍵關係的兩個表的列必須是資料型別相似,也就是可以相互轉換型別的列,比如 int 和tinyint 可以,而 int 和 char 則不可以;
4、例子引入
我們需要一張員工表
id name age dep_name(部門名稱) dep_desc(部門功能)
出現的問題:
1.表語義不明確(到底是員工表還是部門表)
2.存取資料過於冗餘(浪費儲存空間),如部門名稱和功能重複出現。
3.資料的擴充套件性極差(修改的時候會遇到很的問題,比較繁瑣)
解決方案
將上述表一分為二
員工表:id name age
部門表:id dep_name dep_desc
上述的三個問題全部解決,但是員工跟部門之間沒有了關係,接著我們引出外來鍵來解決這個問題:
外來鍵欄位:用於標識資料與資料之間關係的欄位。
八 、表關係的判斷
表關係、資料關係其實意思是一樣的,只是知識說法上有區分。
關係總共有四種:
- 一對多
- 多對多
- 一對一
- 沒有關係
關係的判斷可以採用'換位思考'原則
九、一對多關係
以員工表和部門表為例
1.先站在員工表的角度
問:一名員工能否對應多個部門
答:不可以
2.再站在部門表的角度
問:一個部門能否對應多名員工
答:可以
結論:一個可以一個不可以 那麼關係就是'一對多'
針對'一對多'關係 外來鍵欄位建在'多'的一方
十、外來鍵欄位的建立
因為外來鍵欄位需要引入其他表中的欄位,所以我們應該先建立沒有外來鍵的表,再建立含有外來鍵的表。
小技巧:先定義出含有普通欄位的表 之後再考慮外來鍵欄位的新增
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id)
);
create table dep(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(64)
);
1.建立表的時候一定要先建立被關聯表
2.錄入表資料的時候一定要先錄入被關聯表
3.修改資料的時候外來鍵欄位無法修改和刪除
針對3有簡化措施>>>:級聯更新級聯刪除
create table emp1(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep1(id)
on update cascade
on delete cascade
);
create table dep1(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(64)
);
這裡我們可以看到外來鍵的key值是MUL,意為複合約束條件
- 外來鍵其實是強耦合,不符合解耦合的特性,會導致維護難度和成本變高。
- 所以很多時候 實際專案中當表較多的情況 我們可能不會使用外來鍵 而是使用程式碼建立邏輯層面的關係
十一、多對多關係
以書籍表與作者表為例
1.先站在書籍表的角度
問:一本書能否對應多個作者
答:可以
2.再站在作者表的角度
問:一個作者能否對應多本書
答:可以
結論:兩個都可以,關係就是'多對多'
針對'多對多'關係不能在表中直接建立,需要新建第三張關係表。
create table book(
id int primary key auto_increment,
title varchar(32),
price float(5,2)
);
create table author(
id int primary key auto_increment,
name varchar(32),
phone bigint
);
create table book2author(
id int primary key auto_increment,
author_id int,
foreign key(author_id) references author(id)
on update cascade
on delete cascade,
book_id int,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
);
十二、一對一關係
以使用者表與使用者詳情表為例
1.先站在使用者表的角度
問:一個使用者能否對應多個使用者詳情
答:不可以
2.再站在使用者詳情表的角度
問:一個使用者詳情能否對應多個使用者
答:不可以
結論:兩個都可以 關係就是'一對一'或者沒有關係
針對'一對一'外來鍵欄位建在任何一方都可以 但是推薦建在查詢頻率較高的表中
create table user(
id int primary key auto_increment,
name varchar(32),
detail_id int unique,
foreign key(detail_id) references userdetail(id)
on update cascade
on delete cascade
);
create table userdetail(
id int primary key auto_increment,
phone bigint
);
二十三、SQL語句查詢關鍵字
關鍵詞:select和from
作用描述:from的作用是指定需要查詢資訊的表,select的作用是指定需要查詢的欄位資訊,根據欄位資訊獲取內容
select
指定需要查詢的欄位資訊
select * 查詢所有欄位的資訊
select name 查詢name欄位的資訊
select char_length(name) = 4
支援對欄位做處理,比如這裡是查詢name欄位中長度為4的記錄
from
指定需要查詢的表資訊
from mysql.user
from t1
SQL語句中關鍵字的執行順序和編寫順序並不是一致的 可能會錯亂
eg:
select id,name from userinfo;
-
比如這裡就是先執行from查詢到表中的資訊,然後再根據select跟後面的欄位名稱查詢對應的id和name資訊。
-
對應關鍵字的編寫順序和執行順序我們沒必要過多的在意,熟練之後會非常自然的編寫,我們只需要把注意力放在每個關鍵字的功能上即可。
二十四、前期資料準備
- 為後面的查詢準備的資料值,cv複製執行即可
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
gender enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一個部門一個屋子
depart_id int
);
#插入記錄
#三個部門:教學,銷售,運營
insert into emp(name,gender,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','浦東第一帥形象代言',7300.33,401,1), #以下是教學部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是銷售部門
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('樂樂','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龍','male',28,'20160311','operation',10000.13,403,3), #以下是運營部門
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬銀','female',18,'20130311','operation',19000,403,3),
('程咬銅','male',18,'20150411','operation',18000,403,3),
('程咬鐵','female',18,'20140512','operation',17000,403,3);
二十五、編寫SQL語句的小技巧
- 針對select後面的欄位名可以先用*佔位往後寫 最後再回來修改
select * from 表名稱
- 在實際應用中select後面很少直接寫* 因為*表示所有,當表中欄位和資料都特別多的情況下非常浪費資料庫資源(也就是說記錄特別多的時候就會顯示不下,造成資料顯示混亂,但是可以用\G來分行檢視)。
- SQL語句的編寫類似於程式碼的編寫,不是一蹴而就的,也需要反反覆覆的修修補補。
二十六、查詢關鍵字之where篩選
關鍵詞:where
使用描述:where後面跟上條件,根據條件查詢資訊
1.查詢id大於等於3小於等於6的資料
select * from emp where id >= 3 and id <= 6; 支援邏輯運算子(如<>表示不等於等)
select * from emp where id between 3 and 6;
2.查詢薪資是20000或者18000或者17000的資料
select * from emp where salary=20000 or salary=18000 or salary=17000;
select * from emp where salary in (20000,18000,17000); 支援成員運算
3.查詢id小於3大於6的資料
select * from emp where id<3 or id>6;
select * from emp where id not between 3 and 6;
4.查詢員工姓名中包含字母o的員工姓名與薪資
因為查詢條件不夠精確的查詢,我們稱之為——模糊查詢。
模糊查詢的關鍵字:
- like
模糊查詢的常用符號 :
- %:匹配任意個數的任意字元
- _:匹配單個個數的任意字元
eg:
%o% o jason owen loo wwoww
%o o asdasdo asdo
_o_ aox wob iok
o_ oi ok ol
select * from emp where name like '%o%';
5.查詢員工姓名是由四個字元組成的員工姓名與其薪資
select * from emp where name like '____';
select name,salary from emp where name like '____';
select * from emp where char_length(name) = 4;
select name,salary from emp where char_length(name)=4;
6.查詢崗位描述為空的員工名與崗位名,針對null不能用等號,只能用is
select * from emp where post_comment=NULL; 不可以
select * from emp where post_comment is NULL; 可以
在MySQL中也有很多內建方法,我們可以通過檢視幫助手冊學習。同時我們可以使用如下方法,檢視不同方法名的簡介:
help 方法名
二十七、查詢關鍵字之group by分組
group by介紹
關鍵詞:group by
使用描述:group by 後面接上條件,根據條件進行篩選,同時除了5.6版本,別的版本需要把select後面的* 號改成固定的欄位。
分組:按照指定的條件將單個單個的資料組成一個個整體
eg:
將班級學生按照性別分組
將全國人民按照民族分組
將全世界的人按照膚色分組
分組的目的是為了更好的統計相關資料
eg:
每個班級的男女比例
每個民族的總佔比
每個部門的平均薪資
聚合函式
專門用於分組之後的資料統計
| 名稱 | 含義 |
|---|---|
| avg | 表示求指定列的平均值 |
| min | 表示求指定列的最小值 |
| max | 表示求指定列的最大值 |
| sum | 表示求指定列的和 |
| count | 表示求指定列的總行數 |
例子
1.將員工資料按照部門分組
select * from emp group by post;
- 小知識點
輸入上面的程式碼的時候,MySQL5.6預設不會報錯,MySQL5.7及8.0預設都會直接報錯。
原因是分組之後,select後面預設只能直接填寫分組的依據,不能再寫其他欄位。
5.6版本如果需要修改成跟其他版本一樣的話需要修改配置:
set global sql_mode='strict_trans_tables,only_full_group_by'
接著使用下方程式碼即可正確查詢
select post from emp group by post;
select age from emp group by age;
ps:分組之後預設的最小單位就應該是組,而不應該再是組內的單個數據單個欄位。
2.獲取每個部門的最高工資
要不要分組我們完全可以從題目的需求中分析出來,尤其是出現關鍵字:每個、平均等詞的時候。
select post,max(salary) from emp group by post;
針對sql語句執行之後的結果 我們是可以修改欄位名稱的 關鍵字as 也可以省略
select post as '部門',max(salary) as '最高薪資' from emp group by post;
3.一次獲取部門薪資相關統計
select post,max(salary) '最高薪',min(salary) '最低薪',avg(salary) '平均薪資',sum(salary) '月支出' from emp group by post;
4.統計每個部門的人數
select post,count(id) from emp group by post;
5.統計每個部門的部門名稱以及部門下的員工姓名
分組以外的欄位無法直接填寫,因此我們需要藉助於方法。
group_concat作用:將group by產生的同一個分組中的值連線起來,返回一個字串結果。
select post,name from emp group by post;
這裡只能看到每個部門中的一個名字
select post,group_concat(name) from emp group by post;
使用了group_concat方法後就可以獲得每個部門的所有名字
group_concat方法還可以獲取多個欄位的值。
select post,group_concat(name,age) from emp group by post;
group_concat方法獲取的欄位值可以拼接。
select post,group_concat(name,'|',age) from emp group by post;
select post,group_concat(name,'_NB') from emp group by post;
select post,group_concat('DSB_',name,'_NB') from emp group by post;
二十八、查詢關鍵字之having過濾
關鍵詞:having
作用描述:
- having與where本質是一樣的 都是用來對資料做篩選
- 只不過where用在分組之前(首次篩選),having用在分組之後(二次篩選)
題目:統計各部門年齡在30歲以上的員工平均工資 並且保留大於10000的資料
'''
稍微複雜一點的SQL 跟寫程式碼幾乎一樣 也需要提前想好大致思路
每條SQL的結果可以直接看成就是一張表 基於該表如果還想繼續操作則直接在產生該表的SQL語句上新增即可
'''
步驟1:先篩選出所有年齡大於30歲的員工資料
select * from emp where age > 30;
步驟2:再對篩選出來的資料按照部門分組並統計平均薪資
select post,avg(salary) from emp where age > 30 group by post;
步驟3:針對分組統計之後的結果做二次篩選
select post,avg(salary) from emp where age > 30 group by post having avg(salary) > 10000;
二十九、查詢關鍵字之distinct去重
關鍵詞:distinct
作用描述:類似python中的集合的去重作用。
ps:去重有一個必須的條件,也是很容易被忽略的條件——資料必須一模一樣才可以去重
select distinct id,age from emp;
當我們的去重關鍵字後跟上多個欄位後,去重的物件就會變成這些欄位組合起來之後的結果,如果組合起來的結果出現了重複,才會去重。
關鍵字後跟上單個欄位的時候就會針對單個欄位內的值進行去重。
select distinct age from emp;
select distinct age,post from emp;
三十、查詢關鍵字之order by排序
概念講解
關鍵詞:order by
作用描述:關鍵詞後面跟上欄位名稱,會根據欄位的值進行排序,預設情況下是升序,欄位名稱後面跟上asc也是升序,欄位名稱後面跟上desc就會變成降序。
舉例:
1.可以是單個欄位排序
select * from emp order by age; 預設升序
select * from emp order by age asc; 預設升序(asc可以省略)
select * from emp order by age desc; 降序
2.也可以是多個欄位排序
select * from emp order by age,salary desc;
先按照年齡升序排 相同的情況下再按照薪資降序排
統計各部門年齡在10歲以上的員工平均工資,並且保留平均工資大於1000的部門,然後對平均工資進行排序
1.先篩選出所有年齡大於10歲的員工
select * from emp where age > 10;
2.再對他們按照部門分組統計平均薪資
select post,avg(salary) from emp where age > 10 group by post;
3.針對分組的結果做二次篩選
select post,avg(salary) from emp where age > 10 group by post having avg(salary)>1000;
4.最後按照指定欄位排序
select post,avg(salary) from emp where age > 10 group by post having avg(salary)>1000 order by avg(salary);
"""
當一條SQL語句中很多地方都需要使用聚合函式計算之後的結果 我們可以節省操作(主要是節省了底層執行效率 程式碼看不出來)
select post,avg(salary) as avg_salary from emp where age > 10 group by post having avg_salary>1000 order by avg_salary;
"""
三十一、查詢關鍵字之limit分頁
關鍵詞:limit
作用描述:當表中資料特別多的情況下 我們很少會一次性獲取所有的資料,limit的作用就是控制一次性顯示多少跳記錄。後面跟的數字就是規定顯示幾條資料。
ps:很多網站也是做了分頁處理 一次性只能看一點點
select * from emp limit 5; 直接限制展示的條數
select * from emp limit 5,5; 從第5條開始往後讀取5條
查詢工資最高的人的詳細資訊
'''千萬不要慣性思維 一看到工資最高就想著用分組聚合'''
select * from emp order by salary desc limit 1;
三十二、查詢關鍵字之regexp正則表示式
關鍵詞:regexp
作用描述:關鍵詞後面接上正則表示式進行篩選。
SQL語句的模糊匹配如果用不習慣,也可以自己寫正則批量查詢。
ps:8.0之前的MySQL無法理解?運算子。
select * from emp where name regexp '^j.*?(n|y)$';
select * from emp where name regexp '^j.*(n|y)$';
三十三、多表查詢的思路
表資料準備
create table dep(
id int primary key auto_increment,
name varchar(16)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入資料
insert into dep values
(200,'技術'),
(201,'人力資源'),
(202,'銷售'),
(203,'運營'),
(205,'財務');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('dragon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
多表查詢
select * from emp,dep;
會將兩張表中所有的資料對應一遍
這個現象我們也稱之為'笛卡爾積' 無腦的對應沒有意義,應該將有關係的資料對應到一起才合理。
笛卡爾積概念
首先,先簡單解釋一下笛卡爾積。現在,我們有兩個集合A和B。
A = {0,1} B = {2,3,4}
集合 A×B 和 B×A的結果集就可以分別表示為以下這種形式:
A×B = {(0,2),(1,2),(0,3),(1,3),(0,4),(1,4)};
B×A = {(2,0),(2,1),(3,0),(3,1),(4,0),(4,1)};
可以得出A×B和B×A的笛卡爾積,但總體思路為用
以上A×B和B×A的結果就可以叫做兩個集合相乘的‘笛卡爾積’。
從以上的資料分析我們可以得出以下兩點結論:
1,兩個集合相乘,不滿足交換率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相結合的所有的可能性。既兩個集合相乘得到的新集合的元素個數是 A集合的元素個數 × B集合的元素個數;
基於笛卡爾積可以將部門編號與部門id相同的資料篩選出來
涉及到兩張及以上的表時 欄位很容易衝突 我們需要在欄位前面加上表名來指定
select * from emp,dep where emp.dep_id=dep.id;
基於上述的操作就可以將多張表合併到一起然後一次性獲取更多的資料