
使用 prometheus-operator 監控 Kubernetes 叢集【轉】
https://www.cnblogs.com/lvcisco/p/12575298.html
目錄
- 一、介紹
- 1、Kubernetes Operator 介紹
- 2、Prometheus Operator 介紹
- 3、Prometheus Operator 系統架構圖
- 二、拉取 Prometheus Operator
- 三、進行檔案分類
- 四、修改原始碼 yaml 檔案
- 1、修改映象
- 2、修改 Service 埠設定
- 3、修改資料持久化儲存
- 五、部署前各節點提前下載映象
- 六、更改 kubernetes 配置與建立對應 Service
- 1、更改 kubernetes 配置
- 2、建立 kube-scheduler & controller-manager 對應 Service
- 七、安裝Prometheus Operator
- 1、建立 namespace
- 2、安裝 Operator
- 3、安裝其它元件
- 八、檢視 Prometheus & Grafana
- 1、檢視 Prometheus
- 2、檢視 Grafana
正文
注意:
Prometheus-operator已經改名為Kube-promethues
參考:
- https://www.liangzl.com/get-article-detail-126792.html
- https://blog.51cto.com/zgui2000/2388379
- http://www.gdjmqj.com/news/hulianwang/10721.html
系統引數:
- Prometheus Operator版本:0.29 (Prometheus Operator更名為Kube-Prometheus,且版本變為:0.1.0)
- Kubernetes 版本:1.14.0
- 專案 Github 地址:https://github.com/coreos/kube-prometheus
一、介紹
1、Kubernetes Operator 介紹
在 Kubernetes 的支援下,管理和伸縮 Web 應用、移動應用後端以及 API 服務都變得比較簡單了。其原因是這些應用一般都是無狀態的,所以 Deployment 這樣的基礎 Kubernetes API 物件就可以在無需附加操作的情況下,對應用進行伸縮和故障恢復了。
而對於資料庫、快取或者監控系統等有狀態應用的管理,就是個挑戰了。這些系統需要應用領域的知識,來正確的進行伸縮和升級,當資料丟失或不可用的時候,要進行有效的重新配置。我們希望這些應用相關的運維技能可以編碼到軟體之中,從而藉助 Kubernetes 的能力,正確的執行和管理複雜應用。
Operator 這種軟體,使用 TPR(第三方資源,現在已經升級為 CRD) 機制對 Kubernetes API 進行擴充套件,將特定應用的知識融入其中,讓使用者可以建立、配置和管理應用。和 Kubernetes 的內建資源一樣,Operator 操作的不是一個單例項應用,而是叢集範圍內的多例項。
2、Prometheus Operator 介紹
Kubernetes 的 Prometheus Operator 為 Kubernetes 服務和 Prometheus 例項的部署和管理提供了簡單的監控定義。
安裝完畢後,Prometheus Operator提供了以下功能:
- 建立/毀壞:在 Kubernetes namespace 中更容易啟動一個 Prometheus 例項,一個特定的應用程式或團隊更容易使用Operator。
- 簡單配置:配置 Prometheus 的基礎東西,比如在 Kubernetes 的本地資源 versions, persistence, retention policies, 和 replicas。
- Target Services 通過標籤:基於常見的Kubernetes label查詢,自動生成監控target 配置;不需要學習普羅米修斯特定的配置語言。
3、Prometheus Operator 系統架構圖
{kind=link}
- Operator:Operator 資源會根據自定義資源(Custom Resource Definition / CRDs)來部署和管理 Prometheus Server,同時監控這些自定義資源事件的變化來做相應的處理,是整個系統的控制中心。
- Prometheus:Prometheus 資源是宣告性地描述 Prometheus 部署的期望狀態。
- Prometheus Server:Operator 根據自定義資源 Prometheus 型別中定義的內容而部署的 Prometheus Server 叢集,這些自定義資源可以看作是用來管理 Prometheus Server 叢集的 StatefulSets 資源。
- ServiceMonitor:ServiceMonitor 也是一個自定義資源,它描述了一組被 Prometheus 監控的 targets 列表。該資源通過 Labels 來選取對應的 Service Endpoint,讓 Prometheus Server 通過選取的 Service 來獲取 Metrics 資訊。
- Service:Service 資源主要用來對應 Kubernetes 叢集中的 Metrics Server Pod,來提供給 ServiceMonitor 選取讓 Prometheus Server 來獲取資訊。簡單的說就是 Prometheus 監控的物件,例如 Node Exporter Service、Mysql Exporter Service 等等。
- Alertmanager:Alertmanager 也是一個自定義資源型別,由 Operator 根據資源描述內容來部署 Alertmanager 叢集。
二、拉取 Prometheus Operator
先從 Github 上將原始碼拉取下來,利用原始碼專案已經寫好的 kubernetes 的 yaml 檔案進行一系列整合映象的安裝,如 grafana、prometheus 等等。
從 GitHub 拉取 Prometheus Operator 原始碼
$ wget https://github.com/coreos/kube-prometheus/archive/v0.1.0.tar.gz
解壓
$ tar -zxvf v0.1.0.tar.gz
三、進行檔案分類
由於它的檔案都存放在專案原始碼的 manifests 資料夾下,所以需要進入其中進行啟動這些 kubernetes 應用 yaml 檔案。又由於這些檔案堆放在一起,不利於分類啟動,所以這裡將它們分類。
進入原始碼的 manifests 資料夾
$ cd kube-prometheus-0.1.0/manifests/
建立資料夾並且將 yaml 檔案分類
# 建立資料夾
$ mkdir -p operator node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter
# 移動 yaml 檔案,進行分類到各個資料夾下
mv *-serviceMonitor* serviceMonitor/
mv 0prometheus-operator* operator/
mv grafana-* grafana/
mv kube-state-metrics-* kube-state-metrics/
mv alertmanager-* alertmanager/
mv node-exporter-* node-exporter/
mv prometheus-adapter* adapter/
mv prometheus-* prometheus/
基本目錄結構如下:
manifests/
├── 00namespace-namespace.yaml
├── adapter
│ ├── prometheus-adapter-apiService.yaml
│ ├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
│ ├── prometheus-adapter-clusterRoleBindingDelegator.yaml
│ ├── prometheus-adapter-clusterRoleBinding.yaml
│ ├── prometheus-adapter-clusterRoleServerResources.yaml
│ ├── prometheus-adapter-clusterRole.yaml
│ ├── prometheus-adapter-configMap.yaml
│ ├── prometheus-adapter-deployment.yaml
│ ├── prometheus-adapter-roleBindingAuthReader.yaml
│ ├── prometheus-adapter-serviceAccount.yaml
│ └── prometheus-adapter-service.yaml
├── alertmanager
│ ├── alertmanager-alertmanager.yaml
│ ├── alertmanager-secret.yaml
│ ├── alertmanager-serviceAccount.yaml
│ └── alertmanager-service.yaml
├── grafana
│ ├── grafana-dashboardDatasources.yaml
│ ├── grafana-dashboardDefinitions.yaml
│ ├── grafana-dashboardSources.yaml
│ ├── grafana-deployment.yaml
│ ├── grafana-serviceAccount.yaml
│ └── grafana-service.yaml
├── kube-state-metrics
│ ├── kube-state-metrics-clusterRoleBinding.yaml
│ ├── kube-state-metrics-clusterRole.yaml
│ ├── kube-state-metrics-deployment.yaml
│ ├── kube-state-metrics-roleBinding.yaml
│ ├── kube-state-metrics-role.yaml
│ ├── kube-state-metrics-serviceAccount.yaml
│ └── kube-state-metrics-service.yaml
├── node-exporter
│ ├── node-exporter-clusterRoleBinding.yaml
│ ├── node-exporter-clusterRole.yaml
│ ├── node-exporter-daemonset.yaml
│ ├── node-exporter-serviceAccount.yaml
│ └── node-exporter-service.yaml
├── operator
│ ├── 0prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
│ ├── 0prometheus-operator-0prometheusCustomResourceDefinition.yaml
│ ├── 0prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
│ ├── 0prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
│ ├── 0prometheus-operator-clusterRoleBinding.yaml
│ ├── 0prometheus-operator-clusterRole.yaml
│ ├── 0prometheus-operator-deployment.yaml
│ ├── 0prometheus-operator-serviceAccount.yaml
│ └── 0prometheus-operator-service.yaml
├── prometheus
│ ├── prometheus-clusterRoleBinding.yaml
│ ├── prometheus-clusterRole.yaml
│ ├── prometheus-prometheus.yaml
│ ├── prometheus-roleBindingConfig.yaml
│ ├── prometheus-roleBindingSpecificNamespaces.yaml
│ ├── prometheus-roleConfig.yaml
│ ├── prometheus-roleSpecificNamespaces.yaml
│ ├── prometheus-rules.yaml
│ ├── prometheus-serviceAccount.yaml
│ └── prometheus-service.yaml
└── serviceMonitor
├── 0prometheus-operator-serviceMonitor.yaml
├── alertmanager-serviceMonitor.yaml
├── grafana-serviceMonitor.yaml
├── kube-state-metrics-serviceMonitor.yaml
├── node-exporter-serviceMonitor.yaml
├── prometheus-serviceMonitorApiserver.yaml
├── prometheus-serviceMonitorCoreDNS.yaml
├── prometheus-serviceMonitorKubeControllerManager.yaml
├── prometheus-serviceMonitorKubelet.yaml
├── prometheus-serviceMonitorKubeScheduler.yaml
└── prometheus-serviceMonitor.yaml
四、修改原始碼 yaml 檔案
由於這些 yaml 檔案中設定的應用映象國內無法拉取下來,所以修改原始碼中的這些 yaml 的映象設定,替換映象地址方便拉取安裝。再之後因為需要將 Grafana & Prometheus 通過 NodePort 方式暴露出去,所以也需要修改這兩個應用的 service 檔案。
1、修改映象
(1)、修改 operator
修改 0prometheus-operator-deployment.yaml
$ vim operator/0prometheus-operator-deployment.yaml
改成如下:
......
containers:
- args:
- --kubelet-service=kube-system/kubelet
- --logtostderr=true
- --config-reloader-image=quay-mirror.qiniu.com/coreos/configmap-reload:v0.0.1 #修改映象
- --prometheus-config-reloader=quay-mirror.qiniu.com/coreos/prometheus-config-reloader:v0.29.0 #修改映象
image: quay-mirror.qiniu.com/coreos/prometheus-operator:v0.29.0 #修改映象
......
(2)、修改 adapter
修改 prometheus-adapter-deployment.yaml
$ vim adapter/prometheus-adapter-deployment.yaml
改成如下:
......
containers:
- args:
- --cert-dir=/var/run/serving-cert
- --config=/etc/adapter/config.yaml
- --logtostderr=true
- --metrics-relist-interval=1m
- --prometheus-url=http://prometheus-k8s.monitoring.svc:9090/
- --secure-port=6443
image: quay-mirror.qiniu.com/coreos/k8s-prometheus-adapter-amd64:v0.4.1 #修改映象
name: prometheus-adapter
......
(3)、修改 alertmanager
修改 alertmanager-alertmanager.yaml
$ vim alertmanager/alertmanager-alertmanager.yaml
改成如下:
......
spec:
baseImage: quay-mirror.qiniu.com/prometheus/alertmanager #修改映象
nodeSelector:
beta.kubernetes.io/os: linux
replicas: 3
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: alertmanager-main
version: v0.17.0
(4)、修改 node-exporter
修改 node-exporter-daemonset.yaml
$ vim node-exporter/node-exporter-daemonset.yaml
改成如下:
......
containers:
- args:
- --web.listen-address=127.0.0.1:9100
image: quay-mirror.qiniu.com/prometheus/node-exporter:v0.17.0 #修改映象
......
- args:
- --logtostderr
- --upstream=http://127.0.0.1:9100/
image: quay-mirror.qiniu.com/coreos/kube-rbac-proxy:v0.4.1 #修改映象
......
(5)、修改 kube-state-metrics
修改 kube-state-metrics-deployment.yaml 檔案
$ vim kube-state-metrics/kube-state-metrics-deployment.yaml
改成如下:
......
containers:
- args:
- --logtostderr
- --secure-listen-address=:8443
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
- --upstream=http://127.0.0.1:8081/
image: quay-mirror.qiniu.com/coreos/kube-rbac-proxy:v0.4.1 #修改映象
name: kube-rbac-proxy-main
- args:
- --logtostderr
- --secure-listen-address=:9443
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
- --upstream=http://127.0.0.1:8082/
image: quay-mirror.qiniu.com/coreos/kube-rbac-proxy:v0.4.1 #修改映象
name: kube-rbac-proxy-self
- args:
- --host=127.0.0.1
- --port=8081
- --telemetry-host=127.0.0.1
- --telemetry-port=8082
image: quay-mirror.qiniu.com/coreos/kube-state-metrics:v1.5.0 #修改映象
name: kube-state-metrics
- command:
- /pod_nanny
- --container=kube-state-metrics
- --deployment=kube-state-metrics
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: registry.aliyuncs.com/google_containers/addon-resizer:1.8.4 #修改映象
name: addon-resizer
......
(6)、修改 node-exporter
修改 node-exporter-daemonset.yaml 檔案
$ vim prometheus/prometheus-prometheus.yaml
改成如下:
......
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay-mirror.qiniu.com/prometheus/prometheus #修改映象
nodeSelector:
beta.kubernetes.io/os: linux
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.7.2
2、修改 Service 埠設定
(1)、修改 Prometheus Service
修改 prometheus-service.yaml 檔案
$ vim prometheus/prometheus-service.yaml
修改prometheus Service埠型別為NodePort,設定nodePort埠為32101
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 32101
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
(2)、修改 Grafana Service
修改 grafana-service.yaml 檔案
$ vim grafana/grafana-service.yaml
修改garafana Service埠型別為NodePort,設定nodePort埠為32102
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 32102
selector:
app: grafana
3、修改資料持久化儲存
prometheus 實際上是通過 emptyDir 進行掛載的,我們知道 emptyDir 掛載的資料的生命週期和 Pod 生命週期一致的,如果 Pod 掛掉了,那麼資料也就丟失了,這也就是為什麼我們重建 Pod 後之前的資料就沒有了的原因,所以這裡修改它的持久化配置。
(1)、建立 StorageClass
建立一個名稱為 fast 的 StorageClass,不同的儲存驅動建立的 StorageClass 配置也不同,下面提供基於”GlusterFS”和”NFS”兩種配置,如果是NFS儲存,請提前確認叢集中是否存在”nfs-provisioner”應用。
GlusterFS 儲存的 StorageClass 配置
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast #---SorageClass 名稱
provisioner: kubernetes.io/glusterfs #---標識 provisioner 為 GlusterFS
parameters:
resturl: "http://10.10.249.63:8080"
restuser: "admin"
gidMin: "40000"
gidMax: "50000"
volumetype: "none" #---分佈巻模式,不提供備份,正式環境切勿用此模式
NFS 儲存的 StorageClass 配置
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: nfs-client #---動態卷分配應用設定的名稱,必須和叢集中的"nfs-provisioner"應用設定的變數名稱保持一致
parameters:
archiveOnDelete: "true" #---設定為"false"時刪除PVC不會保留資料,"true"則保留資料
(2)、修改 Prometheus 持久化
修改 prometheus-prometheus.yaml 檔案
$ vim prometheus/prometheus-prometheus.yaml
prometheus是一種 StatefulSet 有狀態集的部署模式,所以直接將 StorageClass 配置到裡面,在下面的yaml中最下面新增持久化配置:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay-mirror.qiniu.com/prometheus/prometheus
nodeSelector:
beta.kubernetes.io/os: linux
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.7.2
storage: #----新增持久化配置,指定StorageClass為上面建立的fast
volumeClaimTemplate:
spec:
storageClassName: fass #---指定為fast
resources:
requests:
storage: 10Gi
(3)、修改 Grafana 持久化配置
建立 grafana-pvc.yaml 檔案
由於 Grafana 是部署模式為 Deployment,所以我們提前為其建立一個 grafana-pvc.yaml 檔案,加入下面 PVC 配置。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana
namespace: monitoring #---指定namespace為monitoring
spec:
storageClassName: fast #---指定StorageClass為上面建立的fast
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
修改 grafana-deployment.yaml 檔案設定持久化配置,應用上面的 PVC
$ vim grafana/grafana-deployment.yaml
將 volumes 裡面的 “grafana-storage” 配置注掉,新增如下配置,掛載一個名為 grafana 的 PVC
......
volumes:
- name: grafana-storage #-------新增持久化配置
persistentVolumeClaim:
claimName: grafana #-------設定為建立的PVC名稱
#- emptyDir: {} #-------註釋掉舊的配置
# name: grafana-storage
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
......
五、部署前各節點提前下載映象
為了保證服務啟動速度,所以最好部署節點提前下載所需映象。
docker pull quay-mirror.qiniu.com/coreos/configmap-reload:v0.0.1
docker pull quay-mirror.qiniu.com/coreos/prometheus-config-reloader:v0.29.0
docker pull quay-mirror.qiniu.com/coreos/prometheus-operator:v0.29.0
docker pull quay-mirror.qiniu.com/coreos/k8s-prometheus-adapter-amd64:v0.4.1
docker pull quay-mirror.qiniu.com/prometheus/alertmanager:v0.17.0
docker pull quay-mirror.qiniu.com/prometheus/node-exporter:v0.17.0
docker pull quay-mirror.qiniu.com/coreos/kube-rbac-proxy:v0.4.1
docker pull quay-mirror.qiniu.com/coreos/kube-state-metrics:v1.5.0
docker pull registry.aliyuncs.com/google_containers/addon-resizer:1.8.4
docker pull quay-mirror.qiniu.com/prometheus/prometheus:v2.7.2
六、更改 kubernetes 配置與建立對應 Service
必須提前設定一些 Kubernetes 中的配置,否則 kube-scheduler 和 kube-controller-manager 無法監控到資料。
1、更改 kubernetes 配置
由於 Kubernetes 叢集是由 kubeadm 搭建的,其中 kube-scheduler 和 kube-controller-manager 預設繫結 IP 是 127.0.0.1 地址。Prometheus Operator 是通過節點 IP 去訪問,所以我們將 kube-scheduler 繫結的地址更改成 0.0.0.0。
(1)、修改 kube-scheduler 配置
編輯 /etc/kubernetes/manifests/kube-scheduler.yaml 檔案
$ vim /etc/kubernetes/manifests/kube-scheduler.yaml
將 command 的 bind-address 地址更改成 0.0.0.0
......
spec:
containers:
- command:
- kube-scheduler
- --bind-address=0.0.0.0 #改為0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
......
(2)、修改 kube-controller-manager 配置
編輯 /etc/kubernetes/manifests/kube-controller-manager.yaml 檔案
$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
將 command 的 bind-address 地址更改成 0.0.0.0
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0 #改為0.0.0.0
......
2、建立 kube-scheduler & controller-manager 對應 Service
因為 Prometheus Operator 配置監控物件 serviceMonitor 是根據 label 選取 Service 來進行監控關聯的,而通過 Kuberadm 安裝的 Kubernetes 叢集只建立了 kube-scheduler & controller-manager 的 Pod 並沒有建立 Service,所以 Prometheus Operator 無法這兩個元件資訊,這裡我們收到建立一下這倆個元件的 Service。
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
如果是二進位制部署還得建立對應的 Endpoints 物件將兩個元件掛入到 kubernetes 叢集內,然後通過 Service 提供訪問,才能讓 Prometheus 監控到。
七、安裝Prometheus Operator
所有檔案都在 manifests 目錄下執行。
1、建立 namespace
$ kubectl apply -f 00namespace-namespace.yaml
2、安裝 Operator
$ kubectl apply -f operator/
檢視 Pod,等 pod 建立起來在進行下一步
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS
prometheus-operator-5d6f6f5d68-mb88p 1/1 Running 0
3、安裝其它元件
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
檢視 Pod 狀態
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS
alertmanager-main-0 2/2 Running 0
alertmanager-main-1 2/2 Running 0
alertmanager-main-2 2/2 Running 0
grafana-b6bd6d987-2kr8w 1/1 Running 0
kube-state-metrics-6f7cd8cf48-ftkjw 4/4 Running 0
node-exporter-4jt26 2/2 Running 0
node-exporter-h88mw 2/2 Running 0
node-exporter-mf7rr 2/2 Running 0
prometheus-adapter-df8b6c6f-jfd8m 1/1 Running 0
prometheus-k8s-0 3/3 Running 0
prometheus-k8s-1 3/3 Running 0
prometheus-operator-5d6f6f5d68-mb88p 1/1 Running 0
八、檢視 Prometheus & Grafana
1、檢視 Prometheus
開啟地址:http://192.168.2.11:32101檢視 Prometheus 採集的目標,看其各個採集服務狀態有木有錯誤。
{kind=link}
{kind=link}
2、檢視 Grafana
開啟地址:http://192.168.2.11:32102檢視 Grafana 圖表,看其 Kubernetes 叢集是否能正常顯示。
- 預設使用者名稱:admin
- 預設密碼:admin
{kind=link}
可以看到各種儀表盤
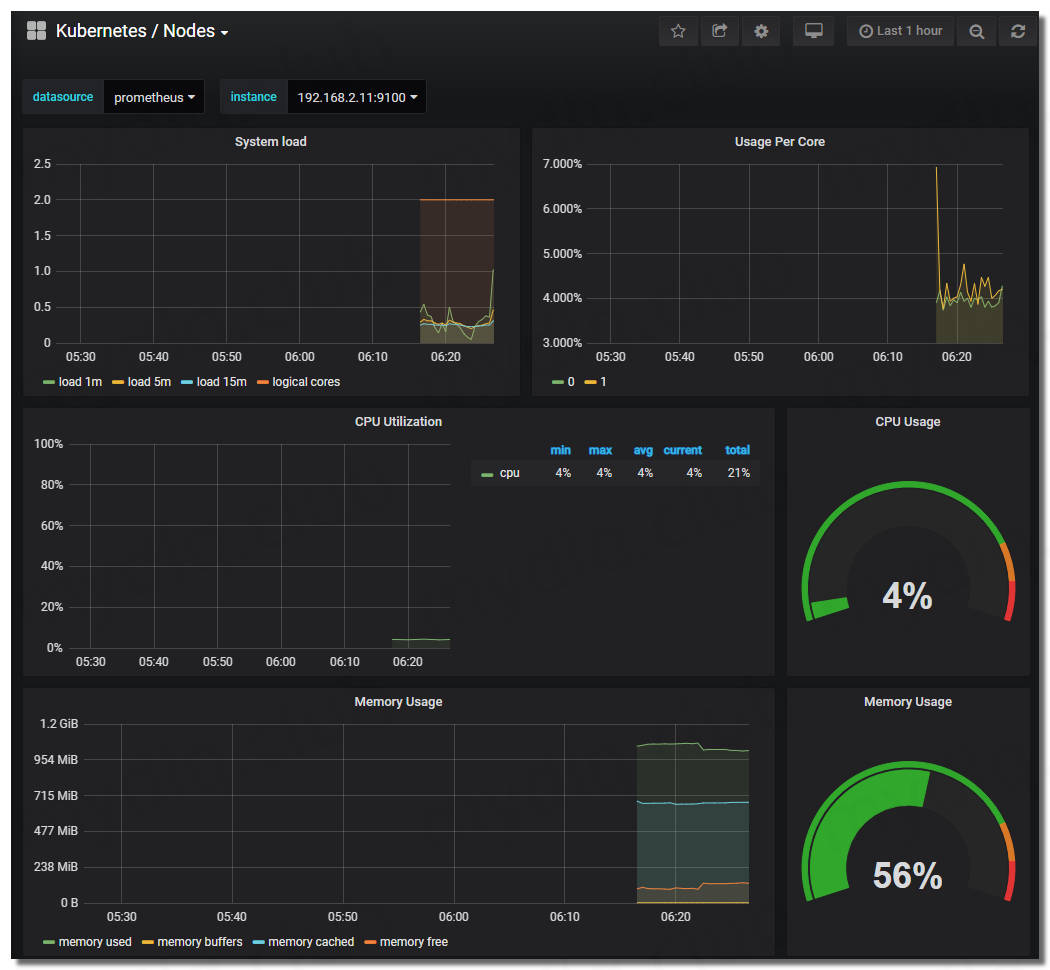{kind=link}