
elasticsearch之初始叢集
一、初始叢集
前言
現在,講述一個真實的故事!
一天小黑在完成專案任務,美滋滋的開始準備和物件約會的時候。突然接到命令,公司談了個大專案,預計一天後,將會有海量的搜尋請求訪問小黑寫的介面。小黑慌了啊!該怎麼辦?該怎麼辦?是刪庫還是跑路?手裡目前就執行著一臺es例項、但幸好有三臺備用的伺服器。你自己該如何搞?趕緊拉個QQ群,把之前的朋友資源都用上!鼓搗一圈,發現沒人能救得了自己!這個苦逼群主就管理自己!後來就準備死磕es了。謝天謝地,可愛的elasticsearch叢集還真能救得了!
在elasticsearch中,一個節點(node)就是一個elasticsearch例項,而一個叢集(cluster)
cluster.name,並且協同工作,分享資料和負載。當加入新的節點或者刪除一個節點時,叢集就會感知到並平衡資料。當Elasticsearch用於構建高可用和可擴充套件的系統時(解決小黑的燃眉之急)。擴充套件的方式可以是:
- 購買更好的伺服器(縱向擴充套件(vertical scale or scaling up))
- 購買更多的伺服器(橫向擴充套件(horizontal scale or scaling out))
Elasticsearch雖然能從更強大的硬體中獲得更好的效能,但是縱向擴充套件有它的侷限性。真正的擴充套件應該是橫向的,它通過增加節點來均攤負載和增加可靠性。
這正好合了小黑的意,正好有三臺備用伺服器。只需要這個水平擴充套件就可以繼續美滋滋的去約會了。叢集看起來難,做起來——試試看!
向叢集中加入節點
小黑首先在本地環境搭建叢集,那麼只需要三步就行了:
- 在本地單獨的目錄中,再複製一份elasticsearch檔案
- 分別啟動bin目錄中的啟動檔案
- 貌似沒有第三步了.....
然後,在瀏覽器位址列輸入:
Copyhttp 返回的結果中:
Copycluster_name "elasticsearch"
status "green"
timed_out false
number_of_nodes 2
number_of_data_nodes 2
active_primary_shards 0
active_shards 0
relocating_shards 0
initializing_shards 0
unassigned_shards 0
delayed_unassigned_shards 0
number_of_pending_tasks 0
number_of_in_flight_fetch 0
task_max_waiting_in_queue_millis 0
active_shards_percent_as_number 100
通過number_of_nodes可以看到,目前叢集中已經有了兩個節點了。小黑一看,這完事了啊!走走走,去約會!
發現節點
小黑在約會的路上突然對一個問題很好奇,這兩個es例項是如何發現相互發現,並且自動的加入叢集的?誰是群主?不由自主的思考入迷......
es使用兩種不同的方式來發現對方:
- 廣播
- 單播
也可以同時使用兩者,但預設的廣播,單播需要已知節點列表來完成。
廣播
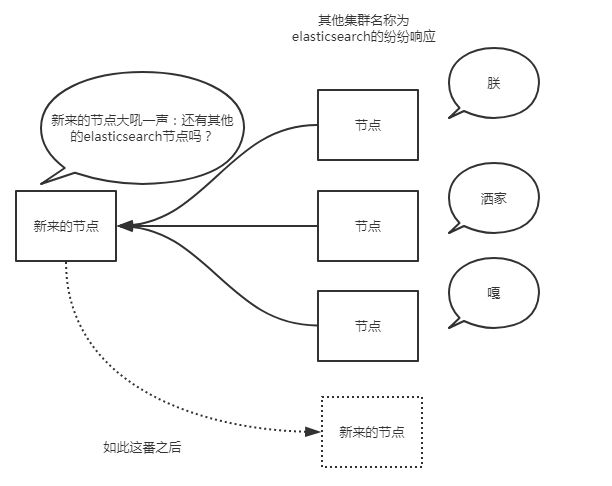
當es例項啟動的時候,它傳送了廣播的ping請求到地址224.2.2.4:54328。而其他的es例項使用同樣的叢集名稱響應了這個請求。
{kind=link}
一般這個預設的叢集名稱就是上面的cluster_name對應的elasticsearch。通常而言,廣播是個很好地方式。想象一下,廣播發現就像你大吼一聲:別說話了,再說話我就發紅包了!然後所有聽見的紛紛響應你。
但是,廣播也有不好之處,過程不可控。
單播
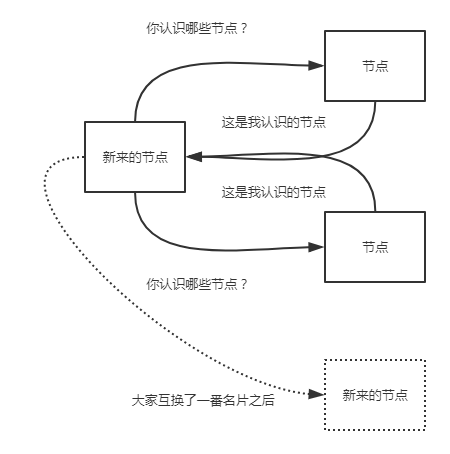
當節點的ip(想象一下我們的ip地址是不是一直在變)不經常變化的時候,或者es只連線特定的節點。單播發現是個很理想的模式。使用單播時,我們告訴es叢集其他節點的ip及(可選的)埠及埠範圍。我們在elasticsearch.yml配置檔案中設定:
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.3:9300", "10.0.0.6[9300-9400]"]
大家就像交換微信名片一樣,相互傳傳就加群了.....
{kind=link}
一般的,我們沒必要關閉單播發現,如果你需要廣播發現的話,配置檔案中的列表保持空白即可。
選取主節點
無論是廣播發現還是到單播發現,一旦叢集中的節點發生變化,它們就會協商誰將成為主節點,elasticsearch認為所有節點都有資格成為主節點。如果叢集中只有一個節點,那麼該節點首先會等一段時間,如果還是沒有發現其他節點,就會任命自己為主節點。
對於節點數較少的叢集,我們可以設定主節點的最小數量,雖然這麼設定看上去叢集可以擁有多個主節點。實際上這麼設定是告訴叢集有多少個節點有資格成為主節點。怎麼設定呢?修改配置檔案中的:
discovery.zen.minimum_master_nodes: 3
一般的規則是叢集節點數除以2(向下取整)再加一。比如3個節點叢集要設定為2。這麼著是為了防止腦裂(split brain)問題。
什麼是腦裂
腦裂這個詞描述的是這樣的一個場景:(通常是在重負荷或網路存在問題時)elasticsearch叢集中一個或者多個節點失去和主節點的通訊,然後小老弟們(各節點)就開始選舉新的主節點,繼續處理請求。這個時候,可能有兩個不同的叢集在相互執行著,這就是腦裂一詞的由來,因為單一叢集被分成了兩部分。為了防止這種情況的發生,我們就需要設定叢集節點的總數,規則就是節點總數除以2再加一(半數以上)。這樣,當一個或者多個節點失去通訊,小老弟們就無法選舉出新的主節點來形成新的叢集。因為這些小老弟們無法滿足設定的規則數量。
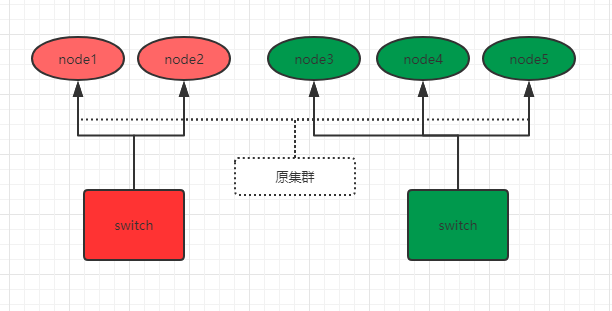
我們通過下圖來說明如何防止腦裂。比如現在,有這樣一個5個節點的叢集,並且都有資格成為主節點:
{kind=link}
為了防止腦裂,我們對該叢集設定引數:
Copydiscovery.zen.minimum_master_nodes: 3 # 3=5/2+1
之前原叢集的主節點是node1,由於網路和負荷等原因,原叢集被分為了兩個switch:node1 、2和node3、4、5。因為minimum_master_nodes引數是3,所以node3、4、5可以組成叢集,並且選舉出了主節點node3。而node1、2節點因為不滿足minimum_master_nodes條件而無法選舉,只能一直尋求加入叢集(還記得單播列表嗎?),要麼網路和負荷恢復正常後加入node3、4、5組成的叢集中,要麼就是一直處於尋找叢集狀態,這樣就防止了叢集的腦裂問題。
除了設定minimum_master_nodes引數,有時候還需要設定node_master引數,比如有兩個節點的叢集,如果出現腦裂問題,那麼它們自己都無法選舉,因為都不符合半數以上。這時我們可以指定node_master,讓其中一個節點有資格成為主節點,另外一個節點只能做儲存用。當然這是特殊情況。
那麼,主節點是如何知道某個小老弟(節點)還活著呢?這就要說到錯誤識別了。
錯誤識別
其實錯誤識別,就是當主節點被確定後,建立起內部的ping機制來確保每個節點在叢集中保持活躍和健康,這就是錯誤識別。
主節點ping叢集中的其他節點,而且每個節點也會ping主節點來確認主節點還活著,如果沒有響應,則宣佈該節點失聯。想象一下,老大要時不常的看看(迴圈)小弟們是否還活著,而小老弟們也要時不常的看看老大還在不在,不在了就趕緊再選舉一個出來!
{kind=link}
但是,怎麼看?多久沒聯絡算是失聯?這些細節都是可以設定的,不是一拍腦門子,就說某個小老弟掛了!在配置檔案中,可以設定:
Copydiscovery.zen.fd.ping_interval: 1
discovery.zen.fd.ping_timeout: 30
discovery_zen.fd.ping_retries: 3
每個節點每隔discovery.zen.fd.ping_interval的時間(預設1秒)傳送一個ping請求,等待discovery.zen.fd.ping_timeout的時間(預設30秒),並嘗試最多discovery.zen.fd.ping_retries次(預設3次),無果的話,宣佈節點失聯,並且在需要的時候進行新的分片和主節點選舉。
根據開發環境,適當修改這些值。
小黑覺得研究的差不多了就美滋滋的要繼續約會,但是恍然大悟——我是條單身狗,哪來的女朋友,就看著右手,陷入了沉思........
歡迎斧正,that's all see also:[elasticsearch的master選舉機制](https://www.cnblogs.com/zziawanblog/p/6577383.html)
二、本地環境搭建叢集
前言#
我們搭建一個有4個節點的單播叢集。
- 系統環境:windows 10
- elasticsearch版本: elasticsearch6.5.4
- kibana版本:kibana6.5.4
配置各節點#
需要說明的是,檢視叢集還可以用到elasticsearch head外掛,但是該外掛依賴nodejs,我嫌麻煩就沒裝。採用kibana一樣。而且,由於elasticsearch比較大,所以,根據系統環境適當的減少節點也是合理的,沒必要非要搞4個。最好放到固態盤下演示效果最好!
為了便於管理,我在C盤的根目錄下建立一個es_cluster目錄,然後將elasticsearch壓縮包和kibana壓縮包解壓到該目錄內,並且重新命名為如下結構:
{kind=link}
補充一點,這裡僅是搭建叢集,並沒有安裝ik分詞外掛,如果要安裝的話,直接安裝在各es目錄內的plugins目錄下即可。具體安裝方法參見ik分詞器的安裝
配置單播發現#
現在,我們為這個叢集增加一些單播配置,開啟各節點內的\config\elasticsearch.yml檔案。每個節點的配置如下(原配置檔案都被註釋了,可以理解為空,我寫好各節點的配置,直接貼上進去,沒有動註釋的,出現問題了好恢復):
- elasticsearch1節點,,叢集名稱是my_es1,叢集埠是9300;節點名稱是node1,監聽本地9200埠,可以有許可權成為主節點和讀寫磁碟(不寫就是預設的)。
cluster.name: my_es1
node.name: node1
network.host: 127.0.0.1
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
- elasticsearch2節點,叢集名稱是my_es1,叢集埠是9302;節點名稱是node2,監聽本地9202埠,可以有許可權成為主節點和讀寫磁碟。
cluster.name: my_es1
node.name: node2
network.host: 127.0.0.1
http.port: 9202
transport.tcp.port: 9302
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
- elasticsearch3節點,叢集名稱是my_es1,叢集埠是9303;節點名稱是node3,監聽本地9203埠,可以有許可權成為主節點和讀寫磁碟。
cluster.name: my_es1
node.name: node3
network.host: 127.0.0.1
http.port: 9203
transport.tcp.port: 9303
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
- elasticsearch4節點,叢集名稱是my_es1,叢集埠是9304;節點名稱是node4,監聽本地9204埠,僅能讀寫磁碟而不能被選舉為主節點。
cluster.name: my_es1
node.name: node4
network.host: 127.0.0.1
http.port: 9204
transport.tcp.port: 9304
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
由上例的配置可以看到,各節點有一個共同的名字my_es1,但由於是本地環境,所以各節點的名字不能一致,我們分別啟動它們,它們通過單播列表相互介紹,發現彼此,然後組成一個my_es1叢集。誰是老大則是要看誰先啟動了!
kibana測試#
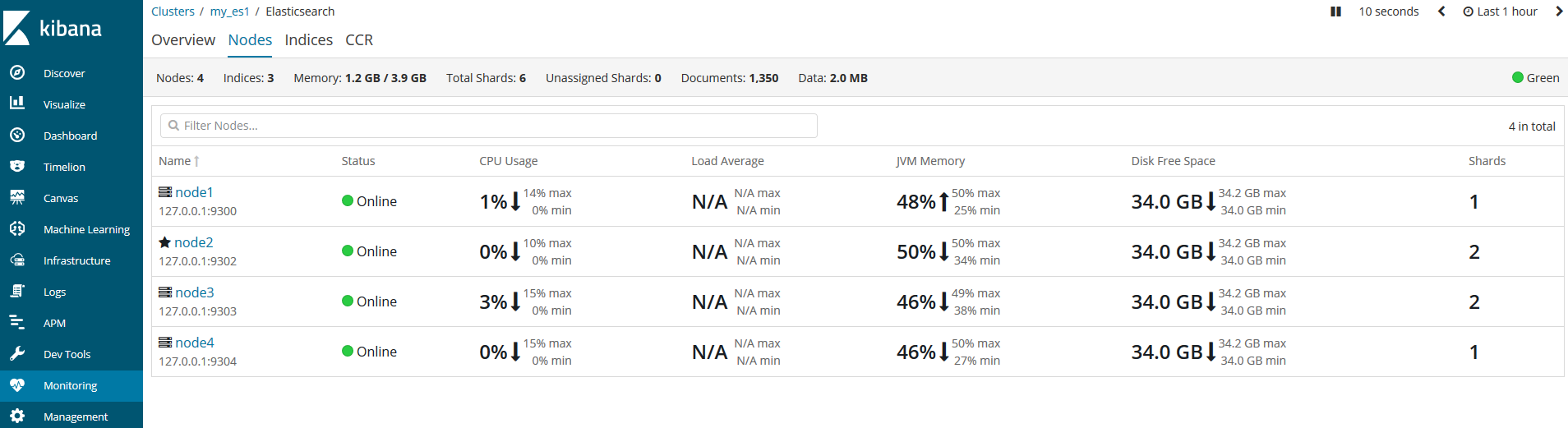
我們開啟kibana,通過左側選單欄的Monitoring來監控各叢集的健康狀況。
{kind=link}
由於我先啟動的是node2節點,所以node2就是主節點。
問題#
- 出現kibana連不上的問題,可能原因是我是測試,頻繁改一些配置導致的,解決辦法,就是刪除各節點下的data目錄。放心它會再建立回來的。
- 防止腦裂配置上,es例項就無法啟動,檢視日誌發現是
[2019-03-21T09:33:30,142][INFO ][o.e.x.m.j.p.NativeController] [XkfReKb] Native controller process has stopped - no new native processes can be started,我懷疑是由於是本地環境引起,等下次在不同的主機上測試再來解決這個問題。
discovery.zen.fd.ping_interval: 1
discovery.zen.fd.ping_timeout: 20
discovery.zen.fd.ping_retries: 3
discouery.zen.minimum_master_nodes: 3
歡迎斧正,that's all
三、elasticsearch叢集那點事兒
前言#
接下來的演示,在本地需要一個新的叢集,沒有搭建好呢?來點選
空叢集#
現在,萬事俱備,只欠東風。我們繼續來探討叢集的內部細節。
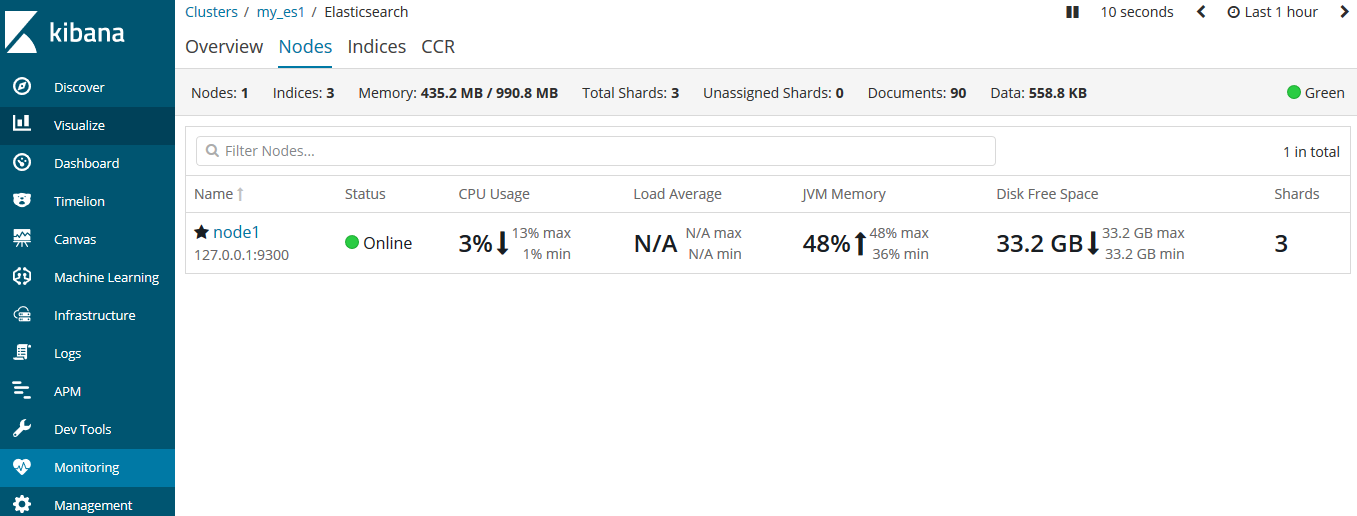
當我們開啟一個單獨的節點node1,此時它還沒有資料和索引。那麼這個叢集就是個空叢集。
{kind=link}
是的,一個叢集下轄一個主節點,空白白的........
叢集健康#
我們通過kibana的監控來檢視叢集狀態:
{kind=link}
或者這麼查詢:
CopyGET cluster/health # 在kibana的Dev Tools中查詢
http://127.0.0.1:9200/_cluster/health?pretty # 瀏覽器中輸入
返回結果如下:
Copy{
"cluster_name" : "my_es1",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 3,
"active_shards" : 3,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
在返回的結果中,我們拿到了叢集名稱、狀態資訊、是否超時等資訊。我們要對這個status保持關注。
status欄位提供一個綜合的指標來表示該叢集的服務狀況,它有三種不同的顏色代表不同的含義:
| 顏色 | 描述 |
|---|---|
| green | 所有主要分片和複製分片都可用 |
| yellow | 所有主要分片可用,但不是所有複製分片都可用 |
| red | 不是所有的主要分片都可用 |
我們將資料新增到elasticsearch中的索引中——一個儲存關聯資料的地方。實際上索引只是用來指向一個或者多個分片的邏輯名稱空間。
一個分片是一個最小級別的工作單元。它只是儲存了索引中所有資料的一部分。我們可以把分片想象成容器,文件就儲存在分片中,然後分片被分配到你的叢集節點上。當我們擴容或縮小叢集時,elasticsearch會自動在節點間遷移分片,以保持叢集的平衡。
分片又可以分為主分片(primary shard)和複製分片(replica shard)。我們索引的每個文件都是一個單獨的主分片,主分片的數量決定了索引最多能儲存多少資料。
而複製分片只是主分片的一個副本,它用來防止硬體故障導致的資料丟失,同時可以提供讀請求。
當索引建立完成後,主分片的數量級就固定了,但是複製分片的數量可以隨時調整。
新增索引#
瞭解了叢集中的索引和分片。我們就來為空叢集建立一個索引(在kibana中):
CopyPUT /blogs
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
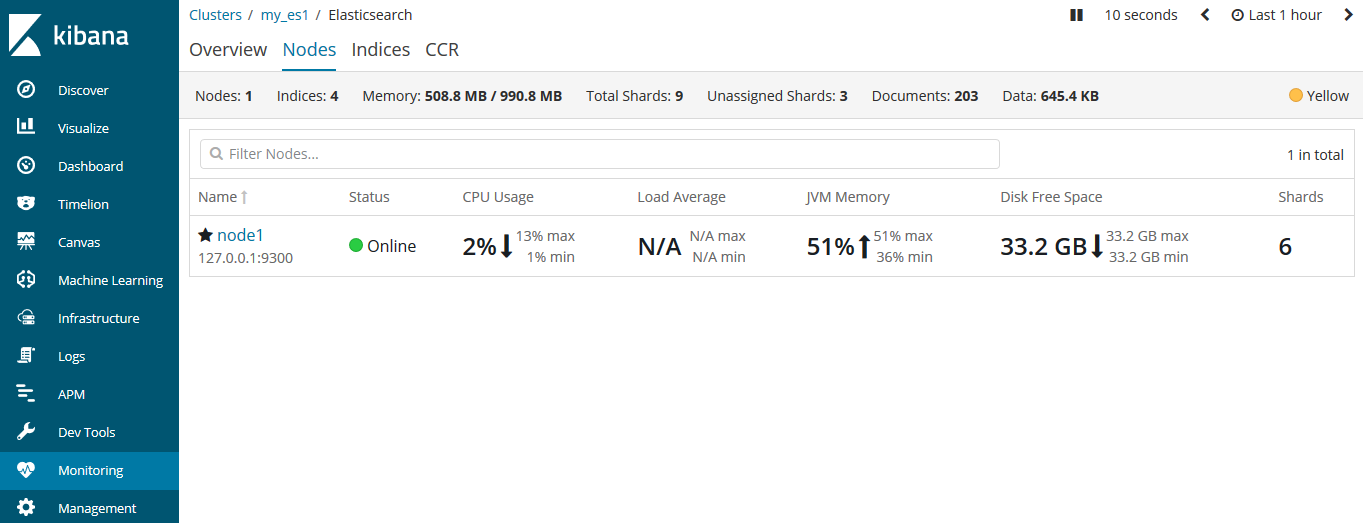
上例中,我們為blogs節點分配了3個分片(預設是5個)和1個複製分片(每個主分片預設都有一個複製分片)。
{kind=link}
現在三個分片都被分配到節點1中了。我們來檢視一下叢集的健康狀態:
Copy{
"cluster_name" : "my_es1",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 6,
"active_shards" : 6,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 3,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 66.66666666666666
}
此時的叢集健康狀態是yellow,表示所有的主分片都正常,叢集可以正常的處理請求。只是複製分片還沒有全部可用,此時複製分片處於unassigned狀態,它們還沒分配給節點。因為沒有必要在同一個節點上儲存相同的資料副本。只要這個節點掛了,那麼資料副本也都丟了。
在kibana中看更直觀一些:
{kind=link}
現在叢集工作正常,比如我們為blogs索引新增一條資料:
CopyPUT /blogs/doc/1
{
"title": "es叢集"
}
GET /blogs/_search
{
"query": {
"match_all": {}
}
}
新增和查詢都沒問題。現在一切看起來非常的完美。但雖然叢集的功能完備,但是存在因硬體故障導致資料丟失的風險。
新增更多的節點#
我們為這個叢集新增一個新的節點,來承擔資料丟失的風險。啟動我們的叢集中的node2節點。啟動後,我們就可以在kibana中來檢測這兩個節點。
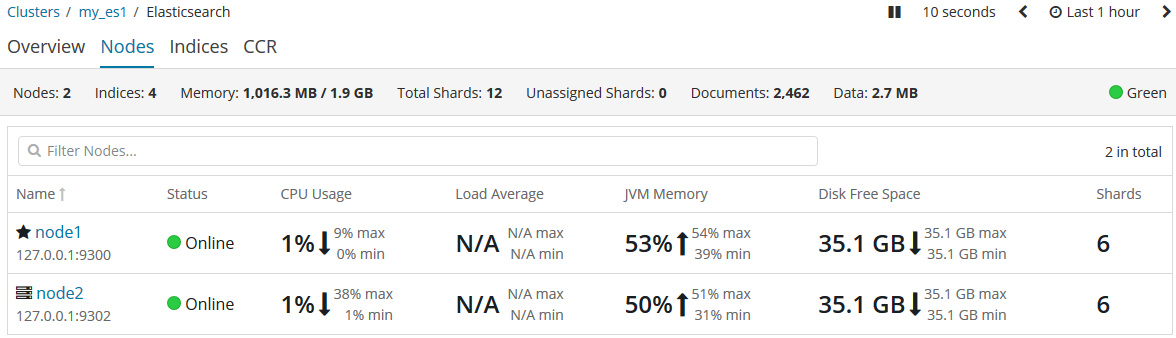{kind=link}
當第二個節點加入到集群后,三個複製分片也已經被分配,這意味著,當在叢集中有任意一個節點掛掉依然可以保證資料的完整性。
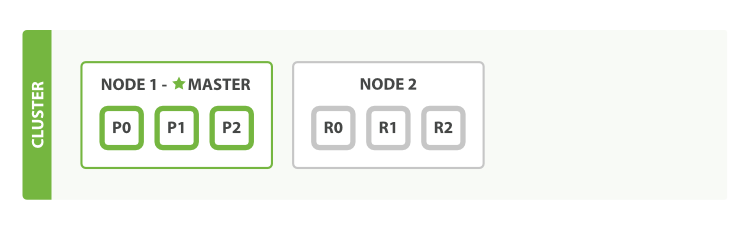{kind=link}
其實,當第二個節點再加入到叢集中時,文件的索引將首先被儲存在主分片中,然後併發複製到對應的複製節點上。這可以確保我們的資料在主節點和複製節點上都可以被檢索。
再來看叢集的健康狀態:
{
"cluster_name" : "my_es1",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 6,
"active_shards" : 12,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
此時的叢集狀態是green,這就表明6個分片都可用了。
目前為止,我們的叢集不僅是功能完備,而且是高可用的了。
繼續擴充套件#
隨著應用需求的增長,我們需要啟動更多的節點,現在讓我們啟動node3和node4。
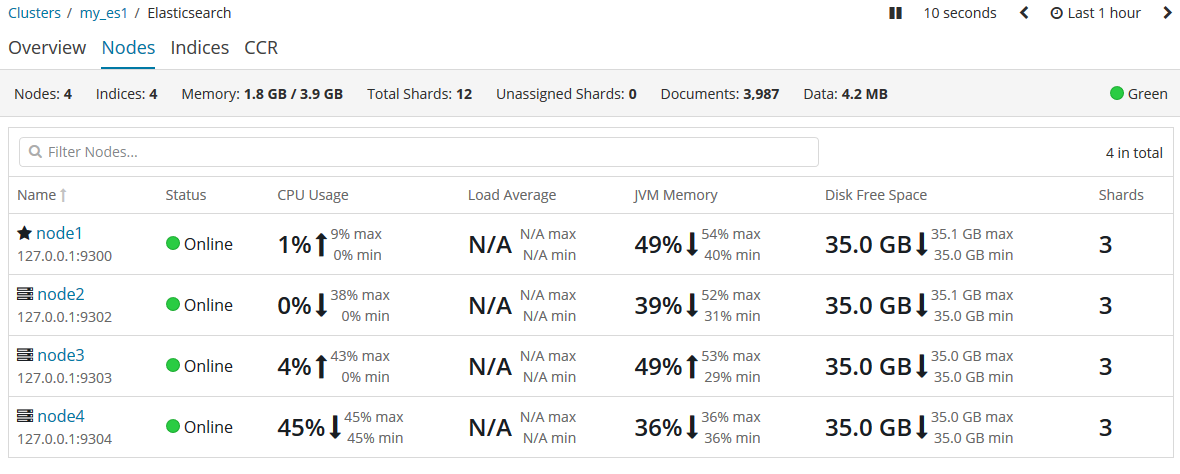{kind=link}
越來越多的節點意味著分片將獲得更多的硬體資源,包括CPU、RAM、I/O。
我們可以使用命令來檢視當前叢集的資訊:
GET _cluster/state/master_node,nodes?pretty # 返回所有節點
GET _cluster/state/master_node,node?pretty # 返回當前主節點的資訊
GET _nodes # 返回所有節點列表
當老大(主節點)掛了怎麼辦#
有一天,我們的主節點掛掉了,比如小黑不小心踢掉了其中一個主機的電源插頭,恰好,這個主機的es例項是主節點node1。相當於小黑親手幹掉了叢集中的老大!此時會發生什麼?
首先,我們由於是通過kibana來監控叢集的,而kibana在啟動的時候預設尋找的是9200埠,也就是老大node1,但這傢伙剛被我們幹掉,所以,kibana先掛掉了。現在我們先把kibana的配置檔案把埠臨時改為(提醒自己一會演示完別忘了改回來!)9202埠(你叢集的其他的示例埠)。然後重啟kibana服務。再訪問監控:
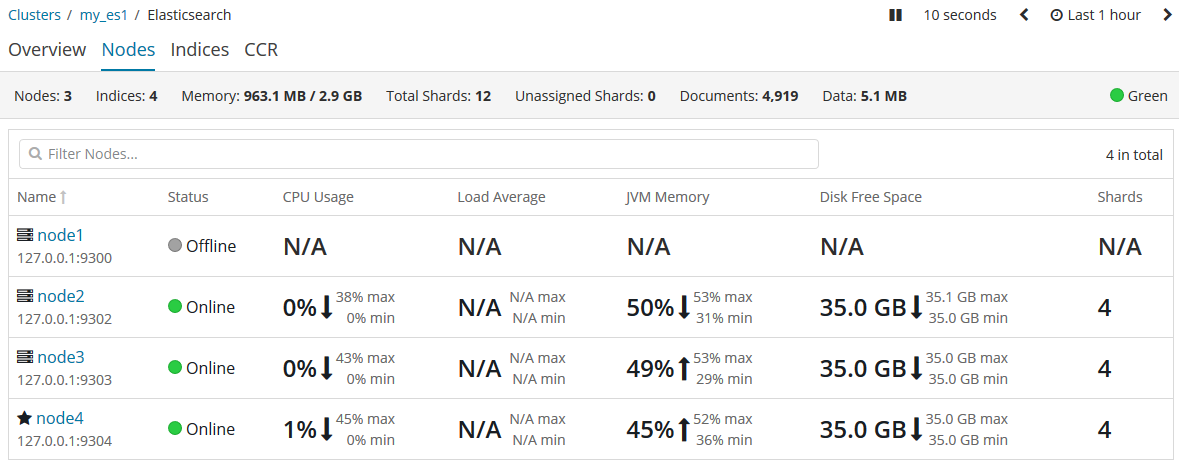{kind=link}
可以看到,老大node1提示離線狀態,而老大則換成了node4。這其中到底發生了什麼呢?
我們殺掉了老大主節點。但是一個叢集必須有一個主節點才能使其功能正常,所以,叢集做的第一件事就是在小弟們(各節點)中選舉出一個新的老大(主節點)。
當原來的老大被幹掉後,它節點內的主分片也都沒了,但還好,其他的節點還存著副本。所以新官上任三把火的頭一把火就是把分佈在別的節點上覆制分片升級為主分片,這個過程是非常快的。當然,它身為新的主節點還要做些別的事情。它將臨時管理叢集級別的一些變更,例如新建或刪除索引、增加或移除節點等。主節點不參與文件級別的變更或搜尋,這意味著在流量增長的時候,該主節點不會成為叢集的瓶頸。
但不幸的的是,原主節點在被小黑殺掉扔下懸崖後,幸運地掛在了樹上而逃過一死(故障解決,重啟node1),它就回來了。你就會在kibana中發現:
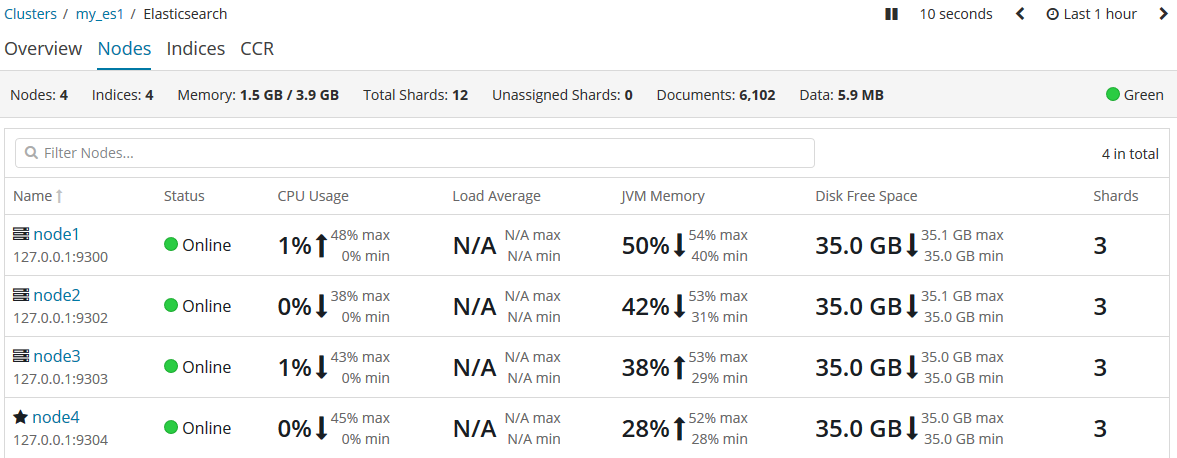{kind=link}
雖然胡漢三又回來了,但是隻能做個小弟了。主節點依然被node4牢牢把握。
成為主節點的資格#
之前當主節點node1被幹掉後,為什麼node4被選舉出來,這其中是否存在著py交易暫且不提。但能說的是,叢集下的各節點都有資格被選舉為主節點。所以node4上位後,就在思考,要把這資格收回來,怎麼做呢?其實在配置檔案中可以體現:
node.master: false # 該節點是否可以被選舉為主節點,預設為true
node.data: true # 該節點是否有儲存許可權,預設為true
我們通過node.master來設定哪個節點有資格稱為主節點。
停用節點#
很多時候,我們需要維護的時候,就需要關閉某個節點,那怎麼做呢?
CopyPUT /_cluster/settings
{
"transient": {
"cluster.routing.allocation.exclude._ip": "192.168.1.1"
}
}
一旦執行上述命令,elasticsearch將該節點上的全部分片轉移到其他的節點上。並且這個設定是暫時的,叢集重啟後就不再有效。
see also:[Elasticsearch權威指南(中文版)](https://es.xiaoleilu.com/020_Distributed_Cluster/05_Empty_cluster.html) 歡迎斧正,that's all