
數據庫之Oracle(二)
上文中對於oracle數據庫做了一些介紹,本文中將主要著重介紹在數據庫開發中運用到的知識,比如字符串的格式轉換,還有存儲過程的書寫,高級連接等
一:存儲過程
存儲過程是為了更加方便,有效的去執行復雜的sql語句。
存儲過程的格式:
示例:輸出hello world
Create or replace procedure name Is --->創建存儲過程,存在就替換
begin --->開始執行
Execute immediate --->立即執行(對表做操作時必須要有這條語句)
DBMS_output.put_line(‘Hello World’); --->輸出‘hello world’
End; --->結尾
目前我在工作中用存儲過程的主要作用是為了存放 創表還有查詢,添加數據語句
存在存儲過程和java 代碼一樣,我們習慣於去創建一個package包保存,創建包
示例:
Create or replace package Packagename As
Begin
Class :=’二年級’; --->公共變量(可以在下面的存儲過程中使用)
School:=’中南小學’; --->公共變量
Procedure name1; --->Package Body中的存儲過程 name1
Procedure name2; --->Package Body中的存儲過程 name2
End Packagename ;
上問中的包內有兩個存儲過程,這兩個存儲過程實際是存放在包底下的body裏面,創建好包以後,需要創建它的Body
示例:
Create or replace Package Body bodyname AS --->創建body
Begin --->開始
Create or replace Procedure name1 as --->存放存儲過程
Begin
Create table table1 (name varchar2(20),age number);
End name1 ;
Procedure name2 ..........
End bodyname; ---->body 結束
二:在上篇中介紹了函數,那麽實際開發中對於數據的處理,往往需要多個函數一起使用。
|
示例: |
Sql語句 |
|
顯示+10000/-10000 |
To_char(nvl(num,0),’$09999’) |
|
需要將數字輸出 |
lpad(nvl(user_id,0),12,0) 這裏需要使用從左補充0,否則取值會有問題 |
|
對於日期格式的取值 |
Nvl2(date,To_char(date,’yyyymmdd’),’19931111’) 利用nvl2函數去判斷非空 |
|
未完待續...... |
|
當我們在對數據做處理的時候,需要從各個不同的表中取到相應的數據,這時候就有了高級連接。
三:高級連接
開發中往往需要從不止一張表中獲取數據,那麽都有哪些方法可以獲取到這些數據呢?
下面讓我來一一為大家介紹,數據庫中各種表之間的聯系。
表與表之間的連接通常分為內聯和外聯還有全聯。
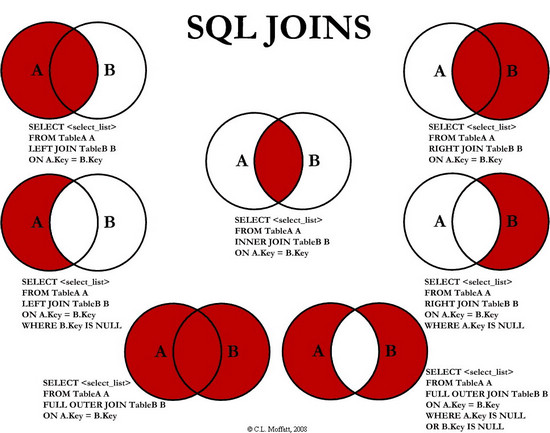
內聯:inner join on
|
示例: |
會顯示bugrecord和bug表中bug_name相等的數據所有信息 |
|
Sql語句 |
select * from bugrecord inner join bug onbug.BUG_NAME=bugrecord.bug_name |
外聯(左聯和右聯)
在多表進行連接時,我們會有主表和從表的區別。
左連接 Left join on
|
示例: |
會將左邊主表(bugrecord)中的數據全部顯示,右邊從表(bug)的數據只有和主表bug_name匹配的才會顯示 |
|
Sql語句 |
select * from bugrecord left join bug on bug.BUG_NAME=bugrecord.bug_name |
右連接 Right join on
|
示例: |
會將右邊主表(bug)中的數據全部顯示,左邊從表(bugrecord)的數據只有和主表bug_name匹配的才會顯示 |
|
Sql語句 |
select * from bugrecord right join bug on bug.BUG_NAME=bugrecord.bug_name |
Union 與Union ALL的區別
Union ALL
|
示例: |
Union ALL 使用時,表中的數據結構必須相同,會將關聯表中所有的信息都顯示出來 |
|
Sql語句 |
select * from bugrecord union all select * from project |
Union
|
示例: |
Union 使用時,表中的數據結構必須相同,會將關聯表中所有的信息都顯示出來,會自動去掉重復的信息 |
|
Sql語句 |
select * from bugrecord union select * from project |
在開發中如果遇到A表中的一個字段需要在B表中去對照獲取最終值,這種情況推薦使用臨時表來處理,使用臨時表的效率更加高效,在數據量大的情況下效率很重要。
With t_lise as lise
(select a.bugId as t_id,
B.tranformvalue as t_value
From (select bugId from A) a left join B b on a.bugid=b.codevalue
)
Select p.describe ||list.t_value from project p Left join lise on lise.t_id=p.bugId
這種寫法很很大程度上會優化sql的效率,使用起來十分的便利。今後將會有一段時間從事oracle數據庫的開發工作,後續會補充在工作中遇到的難點,以及各種優化的語句,也期望大家可以在下面留言,有更好的優化或者本文提到的不對的地方一一指出。
始終堅信------但行好事,莫問前程!
數據庫之Oracle(二)