
Hadoop化繁為簡-從安裝Linux到搭建集群環境
簡介與環境準備
hadoop的核心是分布式文件系統HDFS以及批處理計算MapReduce。近年,隨著大數據、雲計算、物聯網的興起,也極大的吸引了我的興趣,看了網上很多文章,感覺還是雲裏霧裏,很多不必要的配置都在入門教程出現。通過思考總結與相關教程,我想通過簡單的方式傳遞給同樣想入門hadoop的同學。其實,如果你有很好的Java基礎,當你入門以後,你會感覺到hadoop其實也是很簡單的,大數據無非就是數據量大,需要很多機器共同來完成存儲工作,雲計算無非就是多臺機器一起運算。
操作建議:理論先了解三分,先實踐操作完畢,再回頭看理論,在後續文章我將對理論進行分析,最後用思維導圖總結了解它的hadoop的整體面貌。
環境準備: http://pan.baidu.com/s/1dFrHyxV 密碼:1e9g(建議自己去官網下環境,要原生原味的,不要二手貨)
CentOS-Linux系統:CentOS-7-x86_64-DVD-1511.iso
VirtualBox虛擬機:VirtualBox-5.1.18-114002-Win.exe
xshell遠程登錄工具:xshell.exe
xftp遠程文件傳輸:xftp.exe
hadoop:hadoop-2.7.3.tar.gz
jdk8:jdk-8u91-linux-x64.rpm
hadoop的物理架構
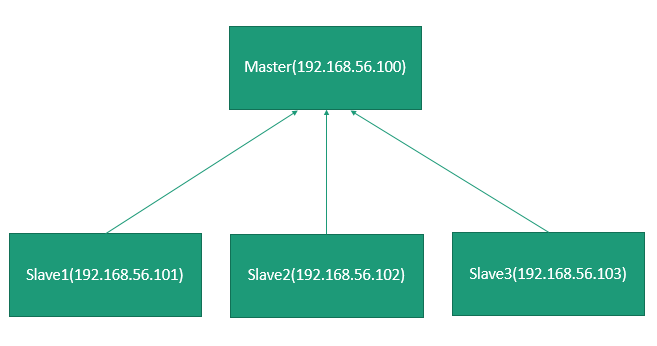
物理架構:假設機房有四臺機器搭建一個集群環境,Master(ip:192.168.56.100)、Slave1(ip:192.168.56.101)、Slave2(ip:192.168.56.102)、Slave3(ip:192.168.56.103)。在這裏簡要介紹一下,至於具體內容,我將在Hadoop的Hdfs文章詳細介紹。
分布式:將不同地點,不同功能的,用於不同數據的多態計算機通過通信網絡連接其他,統一控制,協調完成大規模信息處理的計算機系統。簡單說,一塊硬盤可以分成兩部分:文件索引和文件數據,那麽文件索引部署在單獨一臺服務器上我們稱為Master根節點(NameNode),文件數據部署在Master結點管理的孩子結點被稱為Slave結點(DataNode)。
利用VirtulBox安裝Linux
參考:http://www.cnblogs.com/qiuyong/p/6815903.html
配置集群在同一虛擬局域網下通信
說明:通過上述操作,已經搭建好master(192.168.56.100)這臺機器,開始配置虛擬網絡環境在同一虛擬機下。
- vim /etc/sysconfig/network
- NETWORKING=yes GATEWAY=192.168.56.1(說明:配置意思是,連上VirtualBox這塊網卡)
- vim /etc/sysconfig/network-sripts/ifcfg-enp0s3
- TYPE=Ethernet IPADDR=192.168.56.100 NETMASK=255.255.255.0(說明:配置意思是,設置自己ip)
- 修改主機名:hostnamectl set-hostname master
- 重啟網絡:service network restart
- 查看ip:ifconfig
- 與windows能否ping通、若ping不同,關閉防火墻。master:ping 192.168.56.1 windows:ping 192.168.56.100
- systemctl stop firewalld -->system disable firewalld
利用Xshell、Xftp進行遠程登錄與文件傳輸
利用VirtualBox登錄,上傳文件會比較麻煩,采用Xshell遠程登錄。
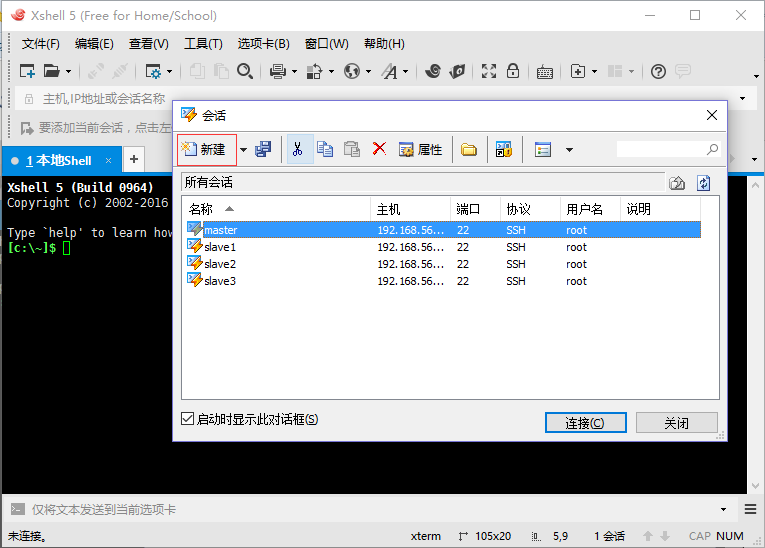
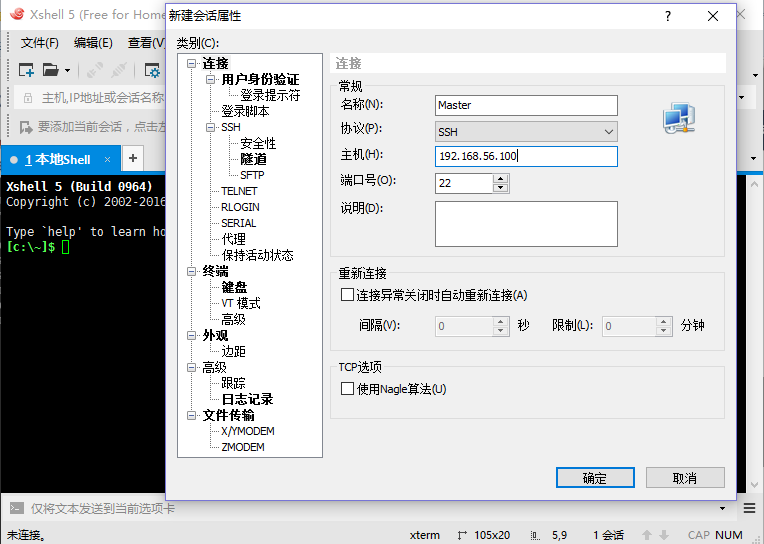
采用Xftp上傳文件。
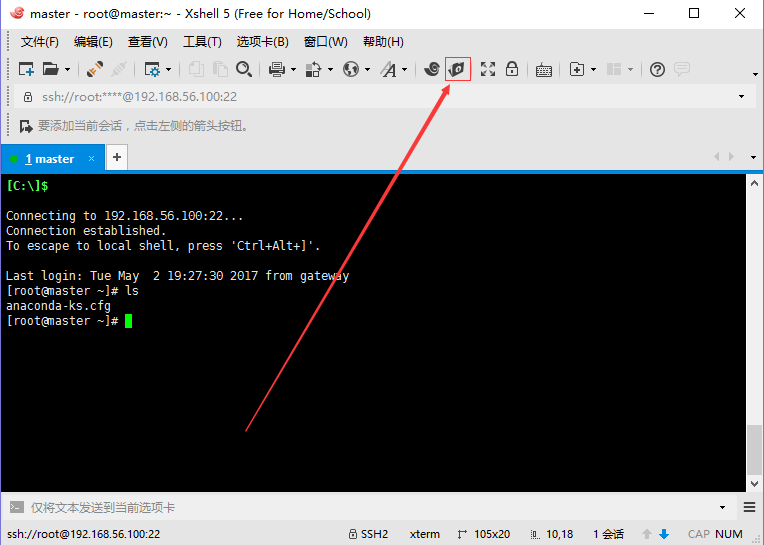
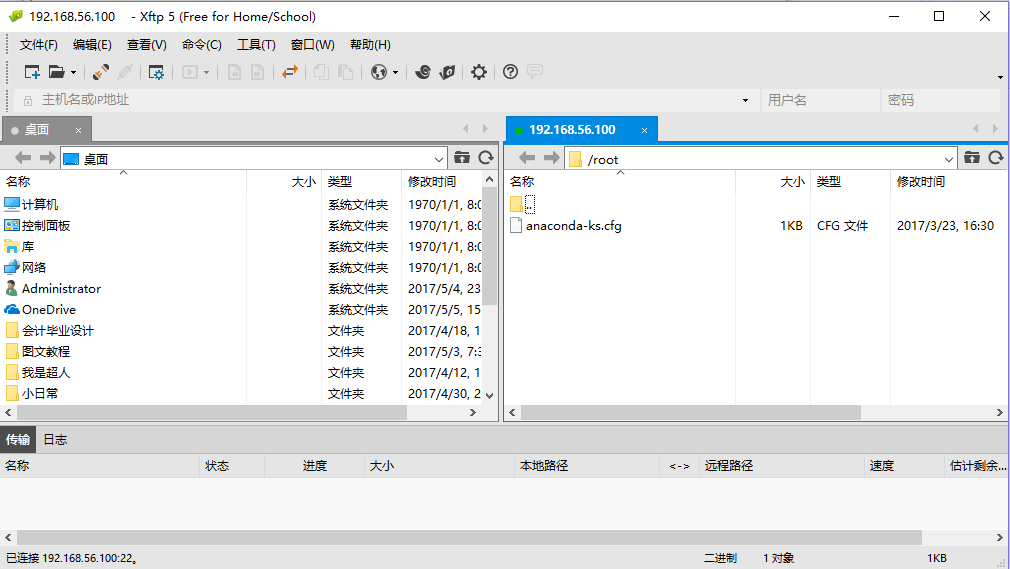
上傳hadoop-2.7.3.tar.gz、jdk-8u91-linux-x64.rpm到/usr/local目錄下。新手提示:在右邊窗口選中/usr/local目錄,左邊雙擊壓縮包就上傳成功了。
配置hadoop環境
- 解壓jdk-8u91-linux-x64.rpm:rpm -ivh /usr/local/jdk-8u91-linux-x64.rpm-->默認安裝目錄到/usr/java
- 確認jdk是否安裝成功。 rpm -qa | grep jdk,java -version查看是否安裝成功。
- 解壓hadoop-2.7.3.tar.gz:tar -vhf /usr/local/hadoop-2.7.3.tar.gz。
- 修改目錄名為hadoop:mv /usr/local/hadoop-2.7.3 hadoop
- 切換目錄到hadoop配置文件目錄:cd /usr/local/hadoop/etc/hadoop
- vim hadoop-env.sh
- 修改export JAVA_HOME 語句為 export JAVA_HOME=/usr/java/default
- 退出編輯頁面:按esc鍵 輸入:wq
- vim /etc/profile
- 在文件最後追加 export PATH=$PATH:/usr/hadoop/bin:/usr/hadoop/sbin
- source /etc/profile
發散思考-更進一步
問題1:現在只是配置了一臺master?那slave1、slave2、slave3也這樣一臺一臺配置嗎?
答:潛意識裏面,肯定有解決辦法避免。當然,VirtualBox也提供了,復制機器的功能。選中master,右鍵復制。這樣的話,就一臺跟master一模一樣的機器就搞定了。我們只需要修改網絡的相關配置即可。註意:搭建集群環境需要自己復制三臺。
問題2:如何查看這些linux機器是否在同一個環境下?
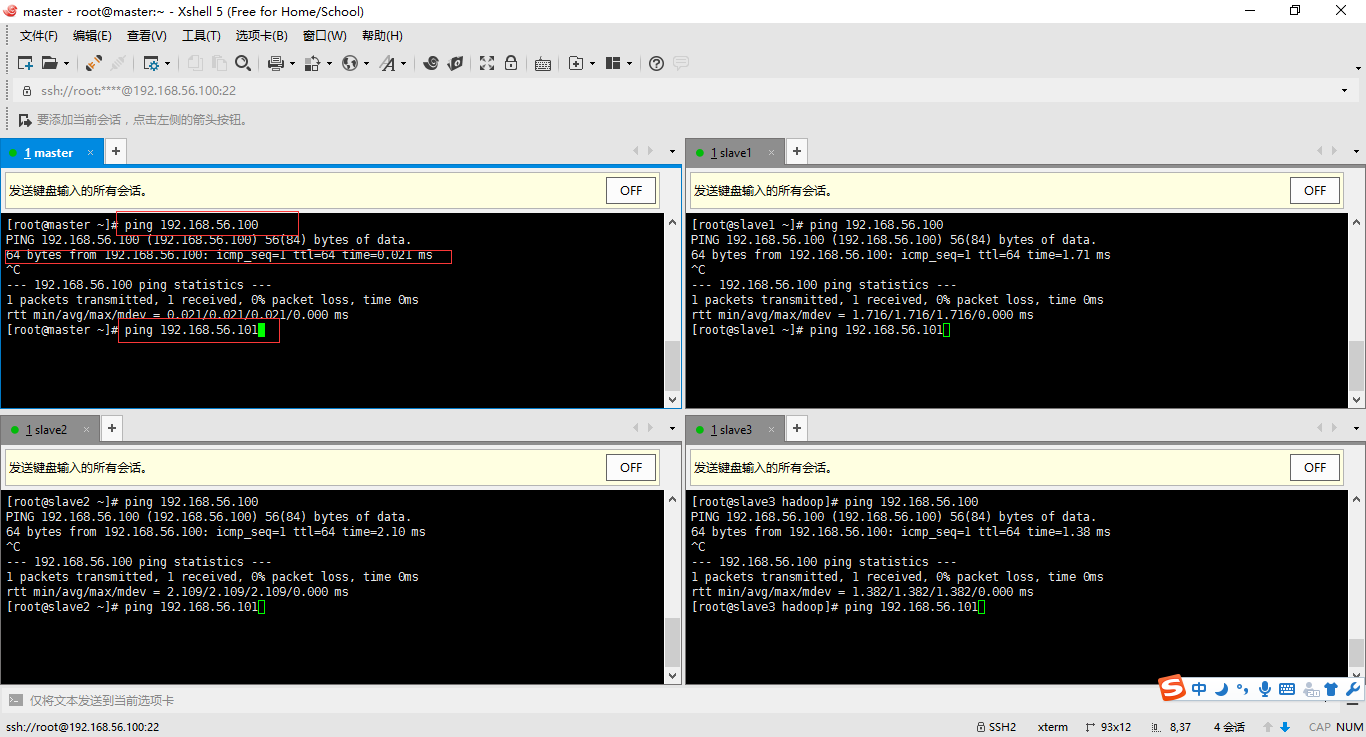
答:我重新捋一遍內容。啟動四臺linux機器(可以右鍵選擇無界面啟動)-->利用xshell遠程登錄-->選擇工具(發送鍵到所用界面)。依次輸入ping 192.168.56.100、192.168.56.101、192.168.56.102、192.168.56.103。
配置與啟動hadoop
1、為四臺機器配置域名。vim /etc/hosts
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
2、切換到hadoop配置文件目錄 /usr/local/hadoop/etc/hadoop vim core-site.xml
3、修改四臺linux機器的core-site.xml,指名四臺機器誰是master(NameNode)。
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
4、在master結點機器指名它的子節點有哪些:vim /usr/local/hadoop/etc/hadoop/slaves(其實就是指名子節點的ip)
slave1
slave2
slave3
5、初始化一下master配置:hdfs namenode -format
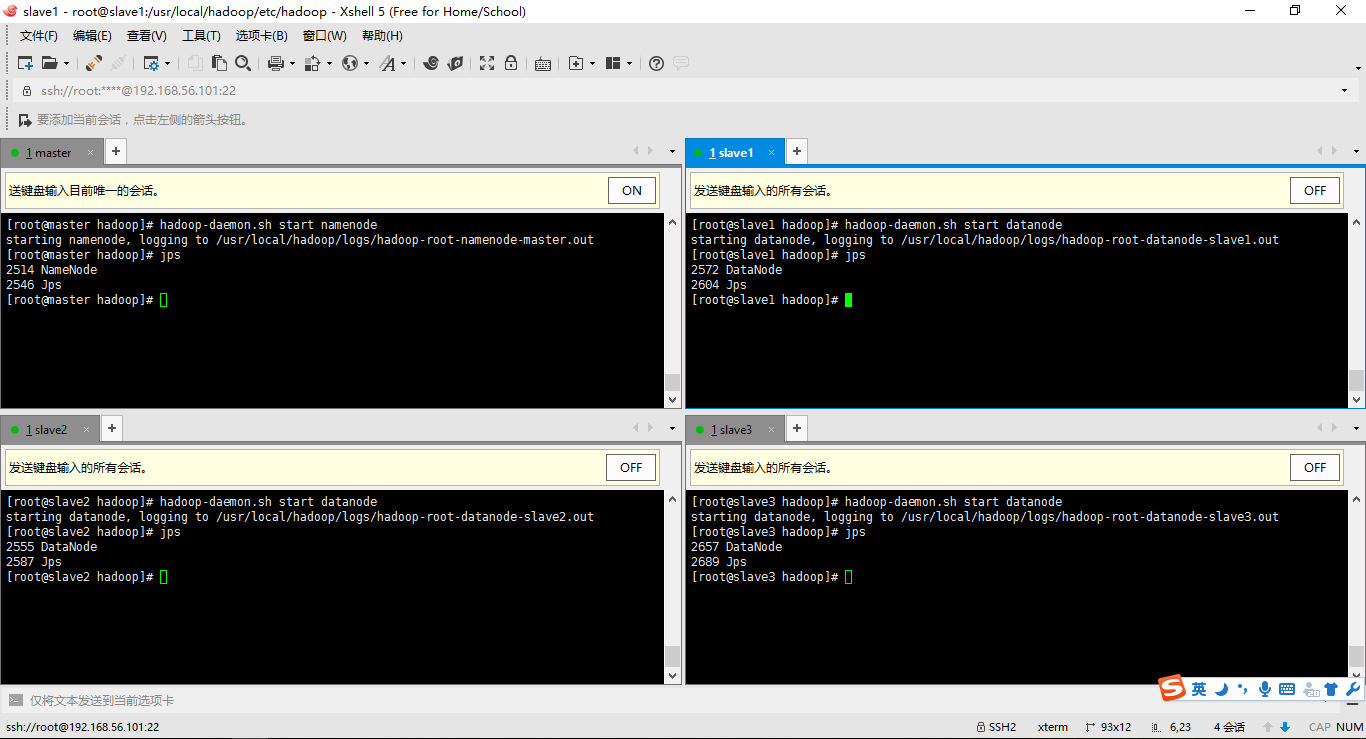
6、啟動hadoop集群並且用jps查看結點的啟動情況
啟動master:hadoop-daemon.sh start namenode
啟動slave:hadoop-daemon.sh start datanode
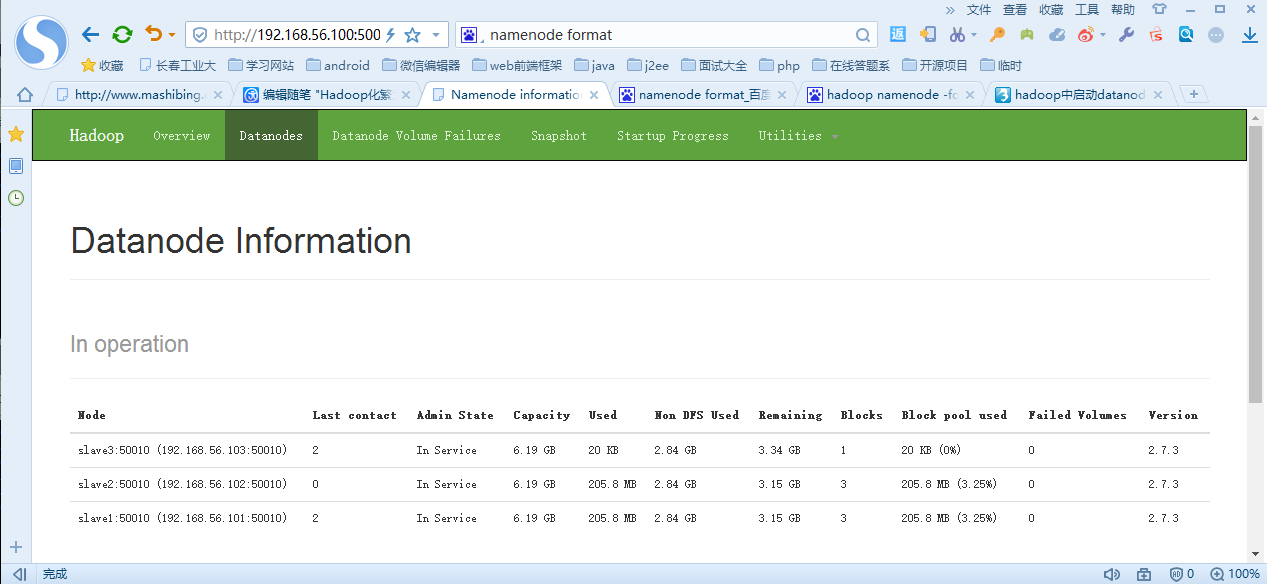
7、查看集群啟動情況:hdfs dfsadmin -report或者利用網頁http://192.168.56.100:50070/
Hadoop化繁為簡-從安裝Linux到搭建集群環境