
Ng第二課:單變量線性回歸(Linear Regression with One Variable)
二、單變量線性回歸(Linear Regression with One Variable)
2.1 模型表示
2.2 代價函數
2.3 代價函數的直觀理解
2.4 梯度下降
2.5 梯度下降的直觀理解
2.6 梯度下降的線性回歸
2.7 接下來的內容
2.1 模型表示
之前的房屋交易問題為例,假使我們回歸問題的訓練集(Training Set)如下表所示:

我們將要用來描述這個回歸問題的標記如下:
m 代表訓練集中實例的數量
x 代表特征/輸入變量
y 代表目標變量/輸出變量
(x,y) 代表訓練集中的實例
(x(i),y(i)) 代表第 i 個觀察實例
h 代表學習算法的解決方案或函數也稱為假設(hypothesis)
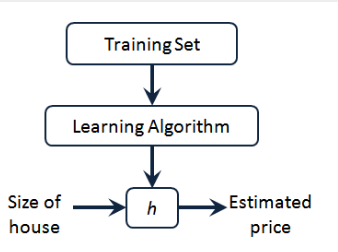
因而,要解決房價預測問題,我們實際上是要將訓練集“餵”給我們的學習算法,進而學習得到一個假設 h,然後把我們要預測的房屋的尺寸作為輸入變量輸入給 h,預測出該房屋的交易價格作為輸出變量輸出為結果。對於這個房價預測問題,一種可能的表達方式為:
![]() ,因為只含有一個特征/輸入變量,因此這樣的問題叫作單變量線性回歸問題。
,因為只含有一個特征/輸入變量,因此這樣的問題叫作單變量線性回歸問題。
2.2 代價函數
我們現在要做的便是為我們的模型選擇合適的參數(parameters)θ0 和 θ1,在房價問題這個例子中便是直線的斜率和在 y 軸上的截距。
我們選擇的參數決定了我們得到的直線相對於我們的訓練集的準確程度,模型所預測的值與訓練集中實際值之間的差距(下圖中藍線所指部分)就是建模誤差(modeling error)。
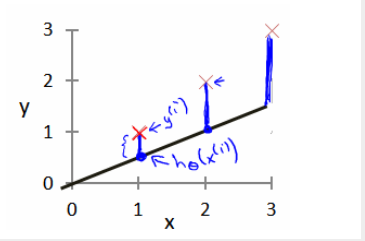
我們的目標便是選擇出可以使得建模誤差的平方和能夠最小的模型參數。 即使得代價函數 ![]() 最小。
最小。
我們繪制一個等高線圖,三個坐標分別為 θ0 和 θ1 和 J(θ0,θ1):
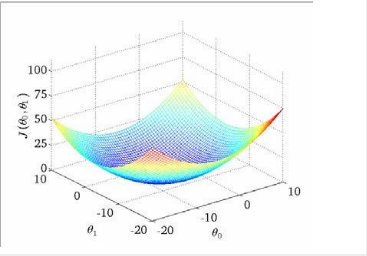
則可以看出在三維空間中存在一個使得 J(θ0,θ1)最小的點。
2.3 代價函數的直觀理解
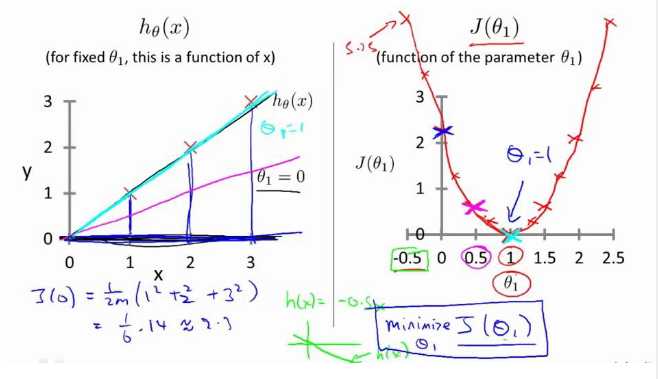
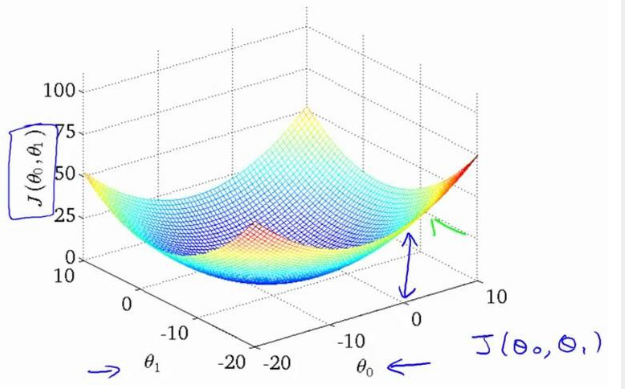
圖1是不考慮θ0、θ1時J(0)為常數,圖2是當只考慮θ1時代價函數J(θ1)的情況,圖3是θ0、θ1都考慮時J(θ0,θ1)的情況。
代價函數的樣子:
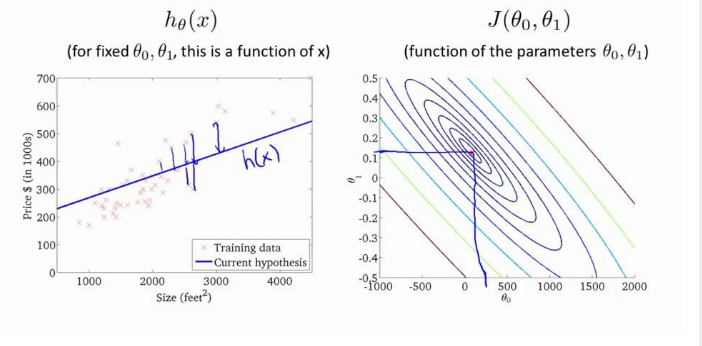
圖1是固定的θ0、θ1,圖2是參數的θ0、θ1
2.4 梯度下降的直觀理解
梯度下降算法如下:
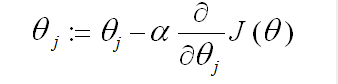
梯度下降的原理描述:首先對

![]()
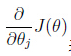 表示最陡的那個方向,α 是學習率(learning rate)(步長)也就是說每次向下降最快的方向走多遠。α過大時,有可能越過最小值,當α過小時,容易造成叠代次數較多收斂速度較慢。
表示最陡的那個方向,α 是學習率(learning rate)(步長)也就是說每次向下降最快的方向走多遠。α過大時,有可能越過最小值,當α過小時,容易造成叠代次數較多收斂速度較慢。
2.5 梯度下降的線性回歸
梯度下降算法和線性回歸算法比較如圖:

對之前的線性回歸問題運用梯度下降法,關鍵在於求出代價函數的導數,即:
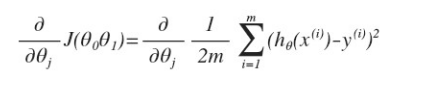
j=0 時:
j=1 時:  (計算得出)
(計算得出)
則算法改寫成:
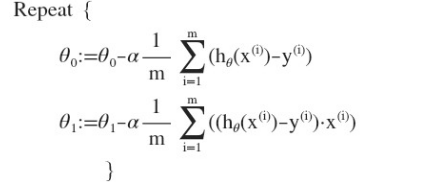
2.6 接下來的內容
在接下來的一組視頻中,我會對將用到的線性代數進行一個快速的復習回顧。
通過它們,你可以實現和使用更強大的線性回歸模型。事實上,線性代數不僅僅在線性回歸中應用廣泛,它其中的矩陣和向量將有助於幫助我們實現之後更多的機器學習模型,並在計算上更有效率。正是因為這些矩陣和向量提供了一種有效的方式來組織大量的數據,特別是當我們處理巨大的訓練集時。
事實上,為了實現機器學習算法,我們只需要一些非常非常基礎的線性代數知識。具體來說,為了幫助你判斷是否有需要學習接 下來的一組視頻,我會討論什麽是矩陣和向量,談談如何加 、減 、乘矩陣和向量,討論逆 矩陣和轉置矩陣的概念。
Ng第二課:單變量線性回歸(Linear Regression with One Variable)