
【轉】使用YCSB測試mongodb分片集群性能
1. 測試工具
本次測試選取YCSB(Yahoo! Cloud System Benchmark)作為測試客戶端工具。YCSB是Yahoo開源的一個nosql測試工具,用來測試比較各種nosql的性能,項目地址:https://github.com/brianfrankcooper/YCSB。項目的mongodb目錄下有詳細的安裝和測試方法。
YCSB支持常見的nosql數據庫讀寫,如插入,修改,刪除,讀取等。它可以使用多線程來提高客戶端的性能。可以方便的自定義各種場景,如95%插入5%讀,或者90%讀5%更新5%插入等等。可以自定義數據請求分布方式:平均分布,zipfian(大約20%數據獲得80%訪問請求),最新數據。
2. 測試步驟
1. 選擇客戶端線程數。使用YCSB測試,要選擇一個合適的線程數,否則測試的瓶頸可能在客戶端而不是數據庫,經過比較,大概100個線程時,YCSB達到最大性能。
2.定義測試場景。本次測試的場景如下:
| workloada | 寫多讀少,90%插入,5%讀,5%更新。 |
| workloadb | 讀多寫少,95%讀,5%更新。 |
| workloadc | 讀多寫少,100%讀。 |
| workloadd | 讀多寫少,95%讀,5%插入。 |
| workloadf | 讀多寫少,50%讀,50%讀寫修改同一條記錄。 |
| workloadg | 讀多寫少,60%讀,20%讀,20%更新。 |
3.測試不同數量記錄下的各種場景。分成兩個階段:
1),load。加載數據。命令為:
./bin/ycsb load mongodb -threads 100 -s -P workloads/workloada -p mongodb.url=mongodb://mongos:28000/ycsb?w=0 > outputLoad.txt
執行load 命令時,僅有recordcount參數起作用,如recordcount=60000000表示加載六千萬條記錄。執行run命令時,recordcount不起作用。mongos是集群中mongos實例的ip地址。
2),run。load數據完成後,各種場景運行測試。
測試場景workloada,位於workloads目錄下:
./bin/ycsb run mongodb -threads 100 -s -P workloads/workloada -p mongodb.url=mongodb://mongos:28000/ycsb?w=0 > outputRun.txt
每次load數據前要把上次測試中產生的數據刪除,包括各個分片,配置服務器,mongos等的數據。
3. 測試系統架構
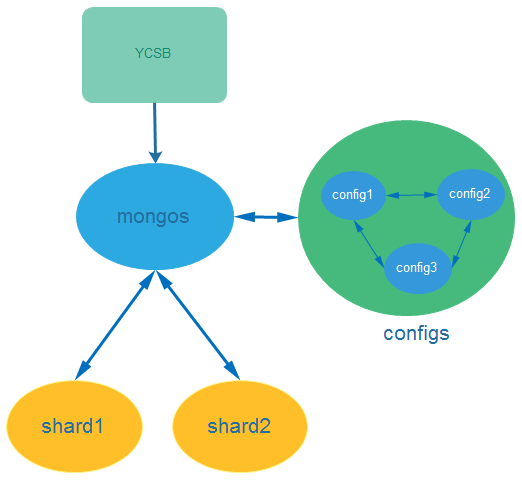
集群配置服務器的3個實例部署在configs服務器上,YCSB,mongos實例,shard1,shard2各自部署在一臺服務器。shard1和shard2都是單獨的mongodb instance,不是replicate set。mongodb 使用2.6版本。
4. 服務器的配置
| OS | CPU | RAM | |
| YCSB | ubuntu14.04 | Intel(R) Core(TM) i5-4440 CPU @ 3.10GHz 4核 | 1G |
| mongos | Red Hat 4.4 | Intel(R) Xeon(R) CPU E5645 @ 2.40GHz 1核 | 8G |
| shards | Red Hat 4.4 | Intel(R) Xeon(R) CPU E5645 @ 2.40GHz 1核 | 16G |
| configs | ubuntu14.04 | Intel(R) Core(TM) i5-4440 [email protected] 1核 | 1G |
5. 測試結果
表1, 一個分片,1百萬,1千萬,6千萬,1億記錄時各個場景的吞吐量(ops/sec)。
表2,兩個分片,1百萬,1千萬,6千萬記錄時各個場景的吞吐量(ops/sec)。
| 數據量(百萬) | workloada | workloadb | workloadc | workloadd | workloadf | workloadg |
| 1 | 4878 | 7352 | 7536 | 7885 | 2131 | 5986 |
| 10 | 4343 | 7282 | 7442 | 6996 | 2164 | 6119 |
| 60 | 1669 | 7242 | 7847 | 7810 | 2577 | 6054 |
| 100 | 157 | 7333 | 6796 | 7766 | 2082 | 4389 |
表1
| 數據量(百萬) | workloada | workloadb | workloadc | workloadd | workloadf | workloadg |
| 1 | 6462 | 7416 | 7518 | 7633 | 2622 | 6777 |
| 10 | 5826 | 8198 | 7664 | 8073 | 2093 | 7376 |
| 60 | 5662 | 7707 | 7546 | 7716 | 2181 | 6540 |
表2
6. 測試結果分析
圖1,一個分片時各個場景下吞吐量隨記錄量的變化曲線。
圖2,兩個分片時各個場景下吞吐量隨記錄量的變化曲線。
圖3,重寫場景(workloada) 不同分片數量的吞吐量隨記錄量的變化曲線。
圖4,重讀場景(workloadb) 不同分片數量的吞吐量隨記錄量的變化曲線。
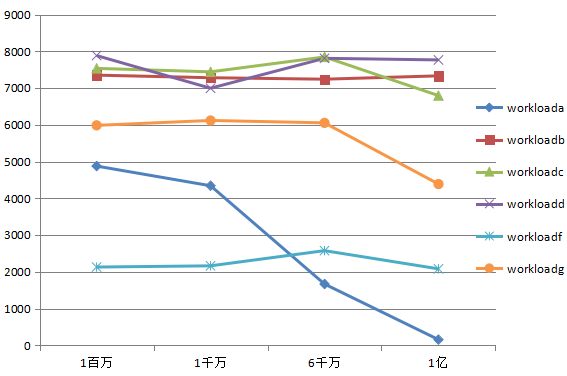
圖1
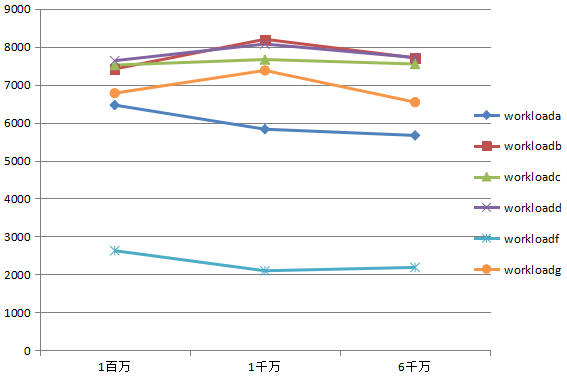
圖2
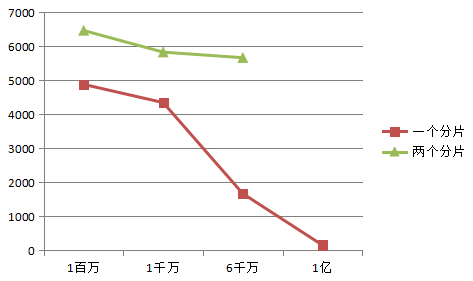
圖3

圖4
由圖1,workloada可以看出,mongodb的寫性能率先達到瓶頸,隨著記錄數量增加,下降很快,而讀取的性能變化很小。
由圖3和圖4,可以看出,當mongodb遇到寫瓶頸時,增加分片,大大增加寫性能,少量增加讀性能。
可能由於數據量,或者YCSB的瓶頸,測試中mongodb讀性能未出現瓶頸。
7.結論
1.Mongodb的讀性能很高,適合重讀的場景。
2.通過增加分片,可以大大增加mongodb集群的寫性能, 部分增加讀性能。
3.與關系型數據庫相比,mongodb 的優勢
-
文檔型數據庫,json風格的文件存儲,結構清晰,無需ORM。
-
復制和高可用性,易於擴展。
-
自動分片
-
使用基於文檔的查詢語言,有一定的查詢能力。
-
任何屬性可索引。
所以對於不太復雜的查詢場景下,mongodb可以很方便的作為mysql的替代方案,提高db的讀寫能力。對於大數據場景,內容管理和交付平臺,用戶數據管理中心,日誌平臺等都適合使用mongodb。
【轉】使用YCSB測試mongodb分片集群性能