
HDFS 架構簡述
HDFS 架構簡述
Hadoop分布式文件系統(HDFS)是一個分布式的文件系統,運行在廉價的硬件上。它與現有的分布式文件系統有很多相似之處。然而與其他的分布式文件系統的差異也是顯著的。HDFS是高容錯的,被設計成在低成本硬件上部署。HDFS為應用數據提供高吞吐量的訪問,適用於具有大規模數據集的應用程序。HDFS放松了一些POSIX的要求,以便提供流式方式來訪問文件系統數據。
1、HDFS 基本概念
1.1 Block
Block是一塊磁盤當中最小的單位,HDFS中的Block是一個很大的單元。在HDFS中的文件將會按塊大小進行分解,並作為獨立的單元進行存儲。
Block概念
磁盤有一個Block size的概念,它是磁盤讀/寫數據的最小單位。構建在這樣的磁盤上的文件系統也是通過塊來管理數據的,文件系統的塊通常是磁盤塊的整數倍。文件系統的塊一般為幾千字節(byte),磁盤塊一般為512字節(byte)。
HDFS也有Block的概念,但它的塊是一個很大的單元,默認是64MB。像硬盤中的文件系統一樣,在HDFS中的文件將會按塊大小進行分解,並作為獨立的單元進行存儲。但和硬盤中的文件系統不一樣的是,存儲在塊中的硬的一個比塊小的文件並不會占據一個塊大小盤物理空間(HDFS中一個塊只存儲一個文件的內容)。
那為什麽HDFS中的block如此之大呢?
在HDFS學習(一) – HDFS設計中,我們曾說過,對HDFS來說,讀取整個數據的時間延遲要比讀取到第一條記錄的數據延遲更重要,就體現在這裏。HDFS的Block設計的如此之大,也就是為了最小化尋道時間。把一個數據塊設計的足夠大,就能夠使得數據傳輸的時間顯著地大於尋找到Block所在時間。這樣,傳輸一個由多個Block組成的文件的時間就取決於磁盤的傳輸速率。
舉一個簡單的例子,假設尋道時間大約為10ms,傳輸速度為100MB/s。為了使得尋道時間僅為傳輸時間的1%,我們就需要設置塊的大小為100MB。HDFS默認的Block size是64MB,但是更多的企業裏邊,已經設置成128M,而且這個參數將隨著新一代硬盤速度的增長而增長。
而Block Size的值也不宜設置過大,通常,Mapreduce中的Map任務一次只處理一個Block中的數據,如果啟動太少的Task(少於集群中的節點的數量),作業的速度就會比較慢。
對HDFS進行塊抽象有哪些好處呢?
一、一個顯而易見的好處是:一個文件的大小,可以大於網絡中任意一個硬盤的大小。
文件的塊並不需要存儲在同一個硬盤上,一個文件的快可以分布在集群中任意一個硬盤上。事實上,雖然實際中並沒有,整個集群可以只存儲一個文件,該文件的塊占滿整個集群的硬盤空間。
二、使用抽象塊而非整個文件作為存儲單元,大大簡化了系統的設計。
簡化設計,對於故障種類繁多的分布式系統來說尤為重要。以塊為單位,一方面簡化存儲管理,因為塊大小是固定的,所以一個硬盤放多少個塊是非常容易計算的;另一方面,也消除了元數據的顧慮,因為Block僅僅是存儲的一塊數據,其文件的元數據,例如權限等就不需要跟數據塊一起存儲,可以交由另外的其他系統來處理。
三、塊更適合於數據備份,進而提供數據容錯能力和系統可用性。
為了防止數據塊損壞或者磁盤或者機器故障,每一個block都可以被分到少數幾天獨立的機器上(默認3臺)。這樣,如果一個block不能用了,就從其他的一處地方,復制過來一份。
1.2 NameNode、DataNode
HDFS采用master-worker架構。一個HDFS集群是有一個Namenode和一定數目的Datanode組成。
HDFS NameSpace
HDFS 支持傳統的層次型文件組織結構。用戶或者應用程序可以創建目 錄,然後將文件保存在這些目錄裏。文件系統名字空間的層次結構和大多數 現有的文件系統類似:用戶可以創建、刪除、移動或重命名文件。當前, HDFS 不支持用戶磁盤配額和訪問權限控制,也不支持硬鏈接和軟鏈接。但 是 HDFS 架構並不妨礙實現這些特性。
NameNode
Namenode是一個中心服務器,負責管理文件系統的namespace和客戶端對文件的訪問。Datanode在集群中一般是一個節點一個,負責管理節點上它們附帶的存儲。在內部,一個文件其實分成一個或多個block,這些block存儲在Datanode集合裏。Namenode執行文件系統的namespace操作,例如打開、關閉、重命名文件和目錄,同時決定block到具體Datanode節點的映射。
DataNode
DataNode在Namenode的指揮下進行block的創建、刪除和復制。Namenode和Datanode都是設計成可以跑在普通的廉價的運行linux的機器上。Datanode 將 HDFS 數據以文件的形式存儲在本地的文件系統中,它並不知道有 關 HDFS 文件的信息。它把每個 HDFS 數據塊存儲在本地文件系統的一個單獨的文件 中。 Datanode 並不在同一個目錄創建所有的文件,實際上,它用試探的方法來確定 每個目錄的最佳文件數目,並且在適當的時候創建子目錄。在同一個目錄中創建所 有的本地文件並不是最優的選擇,這是因為本地文件系統可能無法高效地在單個目 錄中支持大量的文件。
HDFS采用java語言開發,因此可以部署在很大範圍的機器上。一個典型的部署場景是一臺機器跑一個單獨的Namenode節點,集群中的其他機器各跑一個Datanode實例。這個架構並不排除一臺機器上跑多個Datanode,不過這比較少見。
單一節點的Namenode大大簡化了系統的架構。Namenode負責保管和管理所有的HDFS元數據,因而用戶數據就不需要通過Namenode(也就是說文件數據的讀寫是直接在Datanode上)。
1.3 Secondary NameNode 、Checkpoint Node
Secondary NameNode
Secondary NameNode 是用於對 fsimage, edit log進行合並操作。對於 NameNode來說,合並fsimage, edit log的動作只會在NameNode啟動時做,在運行過程中是不會做的,是由Secondary NameNode來做的。
Secondary NameNode 會周期性的對fsimage, edit logs 進行合並。相關的配置有:
·dfs.namenode.checkpoint.period,指定合並周期。
·dfs.namenode.checkpoint.txns ,指定最大事務數。如果在一個合並周期內,對有頻繁的文件操作,如果操作數超過這個值,也會強制進行合並,不會等到合並周期到達才進行合並。
合並過程,參見:http://www.cnblogs.com/f1194361820/p/6768623.html
Checkpoint Node
Checkpoint Node 與 Secondary NameNode的作用、配置都是一樣的,只是啟動的命令不同,估計是因為Secondary NameNode 的名字容易引起誤解,所以才新加了這個Checkpoint Node。
另外在HDFS集群中,可以配置多個Checkpoint Node。
啟動checkpoint node的命令:bin/hdfs namenode -checkpoint
此外,因為Secondary NameNode (或者Checkpoint Node)會定時的合並fsimage, edit logs,所以它們會必須是保留了相對來說最新的 filesystem namespace。那麽當出現故障時,就可以使用它們來恢復 HDFS。從這個角度來說,它們其實相當於文件系統的一個冷備份。
1.4 Backup Node
Backup Node才是一個真正意義的備份,也可以認為它是文件系統的熱備份。因為Backup Node是時刻與NameNode同步的,所以它不需要像Checkpoint Node那樣周期性的下載namespace(fsimage, edit logs)來進行合並。
對於每個NameNode,目前版本只允許配置一個Backup Node,以後可能會有多個。而且利用Backup node模式就不允許註冊CheckPoint Node了。
此外,因為Backup Node 會在內存和本地文件系統中對namespace進行備份,所以backup node的內存配置要不低於 NameNode的配置。
啟動backup node的命令:bin/hdfs namenode -backup
2、HDFS 相關流程
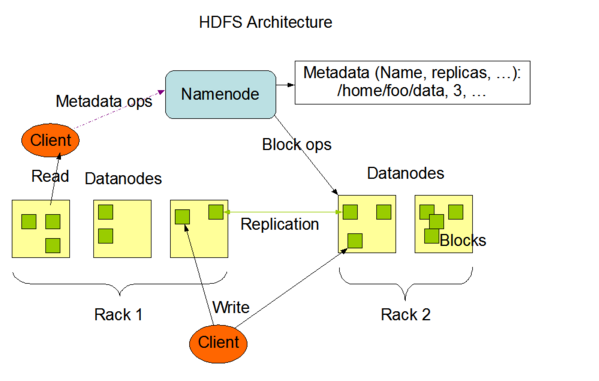
2.1 Read 文件
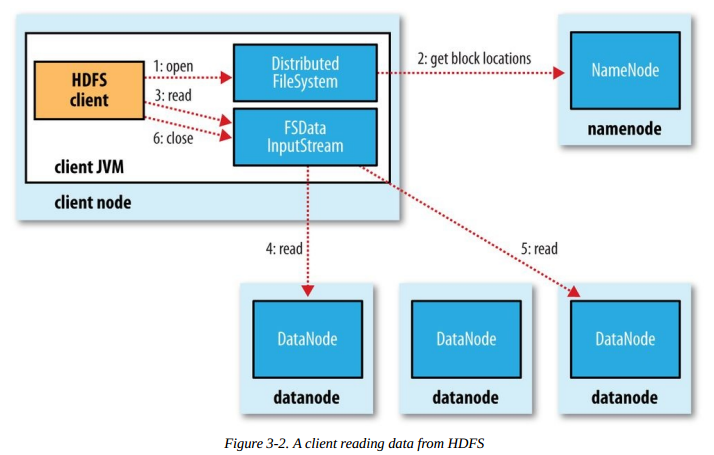
1.使用HDFS提供的客戶端開發庫Client,向遠程的Namenode發起RPC請求;
2.Namenode會視情況返回文件的部分或者全部block列表,對於每個block,Namenode都會返回有該block拷貝的DataNode地址;
3.客戶端開發庫Client會選取離客戶端最接近的DataNode來讀取block;如果客戶端本身就是DataNode,那麽將從本地直接獲取數據.
4.讀取完當前block的數據後,關閉與當前的DataNode連接,並為讀取下一個block尋找最佳的DataNode;
5.當讀完列表的block後,且文件讀取還沒有結束,客戶端開發庫會繼續向Namenode獲取下一批的block列表。
6.讀取完一個block都會進行checksum驗證,如果讀取datanode時出現錯誤,客戶端會通知Namenode,然後再從下一個擁有該block拷貝的datanode繼續讀。
如果要了解更詳細的過程:參見http://shiyanjun.cn/archives/962.html
2.2 Write 文件
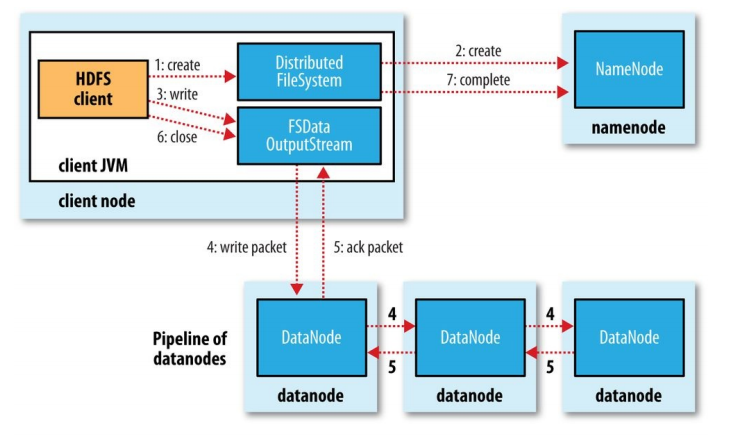
1.使用HDFS提供的客戶端開發庫Client,向遠程的Namenode發起RPC請求;
2.Namenode會檢查要創建的文件是否已經存在,創建者是否有權限進行操作,成功則會為文件 創建一個記錄,否則會讓客戶端拋出異常;
3.當客戶端開始將數據寫入文件的時候,會將數據切分成多個packets,並在內部以數據隊列”data queue”的形式管理這些packets,並向Namenode申請新的blocks,獲取用來存儲replicas的合適的datanodes列表,列表的大小根據在Namenode中對replication的設置而定。
4.開始以pipeline(管道)的形式將packet寫入所有的replicas中。把packet以流的方式寫入第一個datanode,該datanode把該packet存儲之後,再將其傳遞給在此pipeline中的下一個datanode,直到最後一個datanode,這種寫數據的方式呈流水線的形式。
5.最後一個datanode成功存儲之後會返回一個ack packet,在pipeline裏傳遞至客戶端,在客戶端的開發庫內部維護著”ack queue”,成功收到datanode返回的ack packet後會從”ack queue”移除相應的packet。
6.如果傳輸過程中,有某個datanode出現了故障,那麽當前的pipeline會被關閉,出現故障的datanode會從當前的pipeline中移除,剩余的block會繼續剩下的datanode中繼續以pipeline的形式傳輸,同時Namenode會分配一個新的datanode,保持replicas設定的數量。
如果要了解更詳細的過程,參見:http://shiyanjun.cn/archives/942.html
2.3 數據復制
從上面的寫文件的過程,可以看到每個block會被復制到多個datanode上。在寫block之前,會先選擇將block存放到哪些datanode上。這個選擇的策略是:采用機架感知策略來選擇合適的datanode。
在選擇完畢datanode後,就開始寫數據。寫數據時,就相關的datanode就開始自動完成數據復制了。
復制的過程:

When a client is writing data to an HDFS file, its data is first written to a local buffer as explained in the previous section. Suppose the HDFS file has a replication factor of three. When the local buffer accumulates a chunk of user data, the client retrieves a list of DataNodes from the NameNode. This list contains the DataNodes that will host a replica of that block.
The client then flushes the data chunk to the first DataNode. The first DataNode starts receiving the data in small portions, writes each portion to its local repository and transfers that portion to the second DataNode in the list. The second DataNode, in turn starts receiving each portion of the data block, writes that portion to its repository and then flushes that portion to the third DataNode. Finally, the third DataNode writes the data to its local repository. Thus, a DataNode can be receiving data from the previous one in the pipeline and at the same time forwarding data to the next one in the pipeline. Thus, the data is pipelined from one DataNode to the next.
修改副本數
集群只有3個Datanode,hadoop系統replication=4時,會出現什麽情況?
對於上傳文件到hdfs上時,當時hadoop的副本系數是幾,這個文件的塊數副本數就會有幾份,無論以後你怎麽更改系統副本系統,這個文件的副本數都不會改變,也就說上傳到分布式系統上的文件副本數由當時的系統副本數決定,不會受replication的更改而變化,除非用命令來更改文件的副本數。因為dfs.replication實質上是client參數,在create文件時可以指定具體replication,屬性dfs.replication是不指定具體replication時的采用默認備份數。文件上傳後,備份數已定,修改dfs.replication是不會影響以前的文件的,也不會影響後面指定備份數的文件。只影響後面采用默認備份數的文件。但可以利用hadoop提供的命令後期改某文件的備份數:hadoop fs -setrep -R 1。如果你是在hdfs-site.xml設置了dfs.replication,這並一定就得了,因為你可能沒把conf文件夾加入到你的 project的classpath裏,你的程序運行時取的dfs.replication可能是hdfs-default.xml裏的 dfs.replication,默認是3。可能這個就是造成你為什麽dfs.replication老是3的原因。你可以試試在創建文件時,顯式設定replication。replication一般到3就可以了,大了意義也不大。
2.4 文件刪除
當用戶或應用程序刪除某個文件時,這個文件並沒有立刻從 HDFS 中刪除。實際上, HDFS 會將這個文件重命名轉移到 /trash 目錄。只要文件還在 /trash 目錄中,該文件就可以被迅速地恢復。文件在 /trash 中保存的時間是可 配置的,當超過這個時間時, NameNode 就會將該文件從名字空間中刪除。 刪除文件會使得該文件相關的數據塊被釋放。註意,從用戶刪除文件到 HDFS 空閑空間的增加之間會有一定時間的延遲。
只要被刪除的文件還在 /trash 目錄中,用戶就可以恢復這個文件。如果 用戶想恢復被刪除的文件,他 / 她可以瀏覽 /trash 目錄找回該文件。 /trash 目錄僅僅保存被刪除文件的最後副本。 /trash 目錄與其他的目錄沒有什麽區別 ,除了一點:在該目錄上 HDFS 會應用一個特殊策略來自動刪除文件。目前 的默認策略是刪除 /trash 中保留時間超過 6 小時的文件。將來,這個策略可以 通過一個被良好定義的接口配置。
3、HDFS HA
通過之前的對HDFS的基礎架構的了解,很容易發現NameNode有單點故障的風險。
雖然有了Checkpoint Node、Backup Node等,保證了文件系統namespace數據不丟失,但是NameNode出現故障時,仍然是需要人為幹預來保證文件系統正常工作,並且這種人為幹預操作在啟動一個NameNode後需要很長時間(加載fsimage,replay edit log,接收足夠的block report後)後,文件系統才能正常工作。所以就急需一種HA機制來解決這個問題。
如果要實現HDFS的HA,對HDFS的基礎架構稍作調整就可以了:
1)NameNode必須得有一個HA的共享存儲(用於存儲edit log)。當一個standby namenode啟動後,它要從共享存儲裏讀取edit log,並以此與active NameNode進行同步。隨後standby NameNodeg還要一直持續的從共享存儲裏讀取edit log來進行同步。
2)DataNodes必須發送block 報告給active NameNode和standby NameNode。
3)Client要采用一種對用於透明的機制來處理namenode故障轉移
4)secondary namenode的角色被Standby NameNode取代。
從上面來看,主要就是引入了Standby NameNode來取代Secondary NameNode,並引入共享存儲來存儲edit log。
3.1 HDFS HA 架構
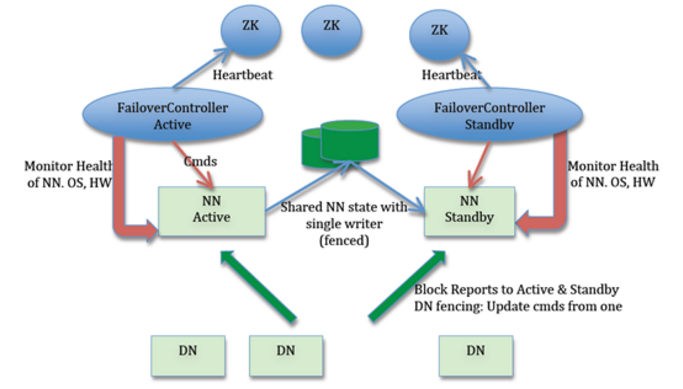
HA架構中組件說明
從上圖中,我們可以看出 NameNode 的高可用架構主要分為下面幾個部分:
- Active NameNode 和 Standby NameNode:兩臺 NameNode 形成互備,一臺處於 Active 狀態,為主 NameNode,另外一臺處於 Standby 狀態,為備 NameNode,只有主 NameNode 才能對外提供讀寫服務。
- 主備切換控制器 ZKFailoverController:ZKFailoverController 作為獨立的進程運行,對 NameNode 的主備切換進行總體控制。ZKFailoverController 能及時檢測到 NameNode 的健康狀況,在主 NameNode 故障時借助 Zookeeper 實現自動的主備選舉和切換,當然 NameNode 目前也支持不依賴於 Zookeeper 的手動主備切換。
- Zookeeper 集群:為主備切換控制器提供主備選舉支持。
- 共享存儲系統:共享存儲系統是實現 NameNode 的高可用最為關鍵的部分,共享存儲系統保存了 NameNode 在運行過程中所產生的 HDFS 的元數據。主 NameNode 和
NameNode 通過共享存儲系統實現元數據同步。在進行主備切換的時候,新的主 NameNode 在確認元數據完全同步之後才能繼續對外提供服務。
- DataNode 節點:除了通過共享存儲系統共享 HDFS 的元數據信息之外,主 NameNode 和備 NameNode 還需要共享 HDFS 的數據塊和 DataNode 之間的映射關系。DataNode 會同時向主 NameNode 和備 NameNode 上報數據塊的位置信息。
3.2 主備切換
NameNode 主備切換主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 這 3 個組件來協同實現:
ZKFailoverController 作為 NameNode 機器上一個獨立的進程啟動 (在 hdfs 啟動腳本之中的進程名為 zkfc),啟動的時候會創建 HealthMonitor 和 ActiveStandbyElector 這兩個主要的內部組件,ZKFailoverController 在創建 HealthMonitor 和 ActiveStandbyElector 的同時,也會向 HealthMonitor 和 ActiveStandbyElector 註冊相應的回調方法。
HealthMonitor 主要負責檢測 NameNode 的健康狀態,如果檢測到 NameNode 的狀態發生變化,會回調 ZKFailoverController 的相應方法進行自動的主備選舉。
ActiveStandbyElector 主要負責完成自動的主備選舉,內部封裝了 Zookeeper 的處理邏輯,一旦 Zookeeper 主備選舉完成,會回調 ZKFailoverController 的相應方法來進行 NameNode 的主備狀態切換。
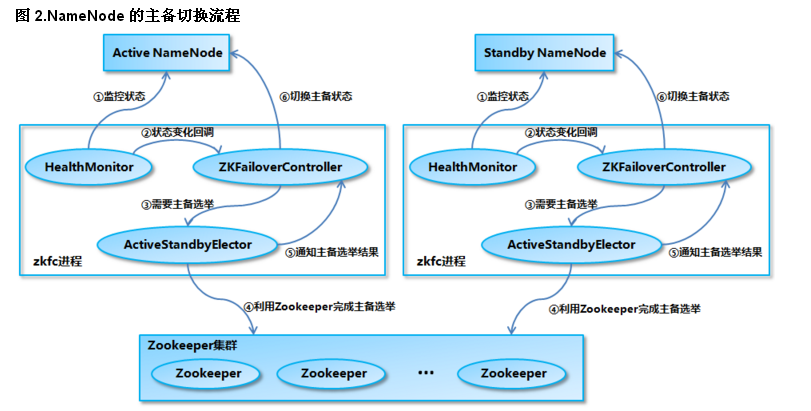
NameNode 實現主備切換的流程(圖2)有下面幾步:
1、HealthMonitor 初始化完成之後會啟動內部的線程來定時調用對應 NameNode 的 HAServiceProtocol RPC 接口的方法,對 NameNode 的健康狀態進行檢測。
2、HealthMonitor 如果檢測到 NameNode 的健康狀態發生變化,會回調 ZKFailoverController 註冊的相應方法進行處理。
3、如果 ZKFailoverController 判斷需要進行主備切換,會首先使用 ActiveStandbyElector 來進行自動的主備選舉。
4、ActiveStandbyElector 與 Zookeeper 進行交互完成自動的主備選舉。
5、ActiveStandbyElector 在主備選舉完成後,會回調 ZKFailoverController 的相應方法來通知當前的 NameNode 成為主 NameNode 或備 NameNode。
6、ZKFailoverController 調用對應 NameNode 的 HAServiceProtocol RPC 接口的方法將 NameNode 轉換為 Active 狀態或 Standby 狀態。
3.2.1 主備切換實現細節說明
下面分別對 HealthMonitor、ActiveStandbyElector 和 ZKFailoverController 的實現細節進行分析:
3.2.1.1 HealthMonitor 實現分析
ZKFailoverController 在初始化的時候會創建 HealthMonitor,HealthMonitor 在內部會啟動一個線程來循環調用 NameNode 的 HAServiceProtocol RPC 接口的方法來檢測 NameNode 的狀態,並將狀態的變化通過回調的方式來通知 ZKFailoverController。
HealthMonitor主要檢測NameNode的兩類狀態,分別是 HealthMonitor.State 和 HAServiceStatus。HealthMonitor.State 是通過 HAServiceProtocol RPC 接口的 monitorHealth 方法來獲取的,反映了 NameNode 節點的健康狀況,主要是磁盤存儲資源是否充足。HealthMonitor.State 包括下面幾種狀態:
·INITIALIZING:HealthMonitor 在初始化過程中,還沒有開始進行健康狀況檢測;
·SERVICE_HEALTHY:NameNode 狀態正常;
·SERVICE_NOT_RESPONDING:調用 NameNode 的 monitorHealth 方法調用無響應或響應超時;
·SERVICE_UNHEALTHY:NameNode 還在運行,但是 monitorHealth 方法返回狀態不正常,磁盤存儲資源不足;
·HEALTH_MONITOR_FAILED:HealthMonitor 自己在運行過程中發生了異常,不能繼續檢測 NameNode 的健康狀況,會導致 ZKFailoverController 進程退出;
HealthMonitor.State 在狀態檢測之中起主要的作用,在 HealthMonitor.State 發生變化的時候,HealthMonitor 會回調 ZKFailoverController 的相應方法來進行處理,具體處理見後文 ZKFailoverController 部分所述。
而 HAServiceStatus 則是通過 HAServiceProtocol RPC 接口的 getServiceStatus 方法來獲取的,主要反映的是 NameNode 的 HA 狀態,包括:
·INITIALIZING:NameNode 在初始化過程中;
·ACTIVE:當前 NameNode 為主 NameNode;
·STANDBY:當前 NameNode 為備 NameNode;
·STOPPING:當前 NameNode 已停止;
HAServiceStatus 在狀態檢測之中只是起輔助的作用,在 HAServiceStatus 發生變化時,HealthMonitor 也會回調 ZKFailoverController 的相應方法來進行處理,具體處理見後文 ZKFailoverController 部分所述。
3.2.1.2 ActiveStandbyElector 實現分析
Namenode(包括 YARN ResourceManager) 的主備選舉是通過 ActiveStandbyElector 來完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的寫一致性和臨時節點機制,具體的主備選舉實現如下:
創建鎖節點
如果 HealthMonitor 檢測到對應的 NameNode 的狀態正常,那麽表示這個 NameNode 有資格參加 Zookeeper 的主備選舉。如果目前還沒有進行過主備選舉的話,那麽相應的 ActiveStandbyElector 就會發起一次主備選舉,嘗試在 Zookeeper 上創建一個路徑為/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 的臨時節點 (${dfs.nameservices} 為 Hadoop 的配置參數 dfs.nameservices 的值,下同),Zookeeper 的寫一致性會保證最終只會有一個 ActiveStandbyElector 創建成功,那麽創建成功的 ActiveStandbyElector 對應的 NameNode 就會成為主 NameNode,ActiveStandbyElector 會回調 ZKFailoverController 的方法進一步將對應的 NameNode 切換為 Active 狀態。而創建失敗的 ActiveStandbyElector 對應的 NameNode 成為備 NameNode,ActiveStandbyElector 會回調 ZKFailoverController 的方法進一步將對應的 NameNode 切換為 Standby 狀態。
註冊 Watcher 監聽
不管創建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 節點是否成功,ActiveStandbyElector 隨後都會向 Zookeeper 註冊一個 Watcher 來監聽這個節點的狀態變化事件,ActiveStandbyElector 主要關註這個節點的 NodeDeleted 事件。
自動觸發主備選舉
如果 Active NameNode 對應的 HealthMonitor 檢測到 NameNode 的狀態異常時, ZKFailoverController 會主動刪除當前在 Zookeeper 上建立的臨時節點/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock,這樣處於 Standby 狀態的 NameNode 的 ActiveStandbyElector 註冊的監聽器就會收到這個節點的 NodeDeleted 事件。收到這個事件之後,會馬上再次進入到創建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 節點的流程,如果創建成功,這個本來處於 Standby 狀態的 NameNode 就選舉為主 NameNode 並隨後開始切換為 Active 狀態。
當然,如果是 Active 狀態的 NameNode 所在的機器整個宕掉的話,那麽根據 Zookeeper 的臨時節點特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 節點會自動被刪除,從而也會自動進行一次主備切換。
使用隔離(fencing)防止腦裂
Zookeeper 在工程實踐的過程中經常會發生的一個現象就是 Zookeeper 客戶端“假死”,所謂的“假死”是指如果 Zookeeper 客戶端機器負載過高或者正在進行 JVM Full GC,那麽可能會導致 Zookeeper 客戶端到 Zookeeper 服務端的心跳不能正常發出,一旦這個時間持續較長,超過了配置的 Zookeeper Session Timeout 參數的話,Zookeeper 服務端就會認為客戶端的 session 已經過期從而將客戶端的 Session 關閉。“假死”有可能引起分布式系統常說的雙主或腦裂 (brain-split) 現象。具體到本文所述的 NameNode,假設 NameNode1 當前為 Active 狀態,NameNode2 當前為 Standby 狀態。如果某一時刻 NameNode1 對應的 ZKFailoverController 進程發生了“假死”現象,那麽 Zookeeper 服務端會認為 NameNode1 掛掉了,根據前面的主備切換邏輯,NameNode2 會替代 NameNode1 進入 Active 狀態。但是此時 NameNode1 可能仍然處於 Active 狀態正常運行,即使隨後 NameNode1 對應的 ZKFailoverController 因為負載下降或者 Full GC 結束而恢復了正常,感知到自己和 Zookeeper 的 Session 已經關閉,但是由於網絡的延遲以及 CPU 線程調度的不確定性,仍然有可能會在接下來的一段時間窗口內 NameNode1 認為自己還是處於 Active 狀態。這樣 NameNode1 和 NameNode2 都處於 Active 狀態,都可以對外提供服務。這種情況對於 NameNode 這類對數據一致性要求非常高的系統來說是災難性的,數據會發生錯亂且無法恢復。Zookeeper 社區對這種問題的解決方法叫做 fencing,中文翻譯為隔離,也就是想辦法把舊的 Active NameNode 隔離起來,使它不能正常對外提供服務。
ActiveStandbyElector 為了實現 fencing,會在成功創建 Zookeeper 節點 hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 從而成為 Active NameNode 之後,創建另外一個路徑為/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 的持久節點,這個節點裏面保存了這個 Active NameNode 的地址信息。Active NameNode 的 ActiveStandbyElector 在正常的狀態下關閉 Zookeeper Session 的時候 (註意由於/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 是臨時節點,也會隨之刪除),會一起刪除節點/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb。但是如果 ActiveStandbyElector 在異常的狀態下 Zookeeper Session 關閉 (比如前述的 Zookeeper 假死),那麽由於/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久節點,會一直保留下來。後面當另一個 NameNode 選主成功之後,會註意到上一個 Active NameNode 遺留下來的這個節點,從而會回調 ZKFailoverController 的方法對舊的 Active NameNode 進行 fencing,具體處理見後文 ZKFailoverController 部分所述。
3.2.1.3 ZKFailoverController 實現分析
ZKFailoverController 在創建 HealthMonitor 和 ActiveStandbyElector 的同時,會向 HealthMonitor 和 ActiveStandbyElector 註冊相應的回調函數,ZKFailoverController 的處理邏輯主要靠 HealthMonitor 和 ActiveStandbyElector 的回調函數來驅動。
對 HealthMonitor 狀態變化的處理
如前所述,HealthMonitor 會檢測 NameNode 的兩類狀態,HealthMonitor.State 在狀態檢測之中起主要的作用,ZKFailoverController 註冊到 HealthMonitor 上的處理 HealthMonitor.State 狀態變化的回調函數主要關註 SERVICE_HEALTHY、SERVICE_NOT_RESPONDING 和 SERVICE_UNHEALTHY 這 3 種狀態:
如果檢測到狀態為 SERVICE_HEALTHY,表示當前的 NameNode 有資格參加 Zookeeper 的主備選舉,如果目前還沒有進行過主備選舉的話,ZKFailoverController 會調用 ActiveStandbyElector 的 joinElection 方法發起一次主備選舉。
如果檢測到狀態為 SERVICE_NOT_RESPONDING 或者是 SERVICE_UNHEALTHY,就表示當前的 NameNode 出現問題了,ZKFailoverController 會調用 ActiveStandbyElector 的 quitElection 方法刪除當前已經在 Zookeeper 上建立的臨時節點退出主備選舉,這樣其它的 NameNode 就有機會成為主 NameNode。
而 HAServiceStatus 在狀態檢測之中僅起輔助的作用,在 HAServiceStatus 發生變化時,ZKFailoverController 註冊到 HealthMonitor 上的處理 HAServiceStatus 狀態變化的回調函數會判斷 NameNode 返回的 HAServiceStatus 和 ZKFailoverController 所期望的是否一致,如果不一致的話,ZKFailoverController 也會調用 ActiveStandbyElector 的 quitElection 方法刪除當前已經在 Zookeeper 上建立的臨時節點退出主備選舉。
對 ActiveStandbyElector 主備選舉狀態變化的處理
在 ActiveStandbyElector 的主備選舉狀態發生變化時,會回調 ZKFailoverController 註冊的回調函數來進行相應的處理:
如果 ActiveStandbyElector 選主成功,那麽 ActiveStandbyElector 對應的 NameNode 成為主 NameNode,ActiveStandbyElector 會回調 ZKFailoverController 的 becomeActive 方法,這個方法通過調用對應的 NameNode 的 HAServiceProtocol RPC 接口的 transitionToActive 方法,將 NameNode 轉換為 Active 狀態。
如果 ActiveStandbyElector 選主失敗,那麽 ActiveStandbyElector 對應的 NameNode 成為備 NameNode,ActiveStandbyElector 會回調 ZKFailoverController 的 becomeStandby 方法,這個方法通過調用對應的 NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,將 NameNode 轉換為 Standby 狀態。
如果 ActiveStandbyElector 選主成功之後,發現了上一個 Active NameNode 遺留下來的/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 節點 (見“ActiveStandbyElector 實現分析”一節“防止腦裂”部分所述),那麽 ActiveStandbyElector 會首先回調 ZKFailoverController 註冊的 fenceOldActive 方法,嘗試對舊的 Active NameNode 進行 fencing,在進行 fencing 的時候,會執行以下的操作:
首先嘗試調用這個舊 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它轉換為 Standby 狀態。
如果 transitionToStandby 方法調用失敗,那麽就執行 Hadoop 配置文件之中預定義的隔離措施,Hadoop 目前主要提供兩種隔離措施,通常會選擇 sshfence:
sshfence:通過 SSH 登錄到目標機器上,執行命令 fuser 將對應的進程殺死;
shellfence:執行一個用戶自定義的 shell 腳本來將對應的進程隔離;
只有在成功地執行完成 fencing 之後,選主成功的 ActiveStandbyElector 才會回調 ZKFailoverController 的 becomeActive 方法將對應的 NameNode 轉換為 Active 狀態,開始對外提供服務。
3.3 共享存儲
過去幾年中 Hadoop 社區湧現過很多的 NameNode 共享存儲方案,比如 shared NAS+NFS、BookKeeper、BackupNode 和 QJM(Quorum Journal Manager) 等等。目前社區已經把由 Clouderea 公司實現的基於 QJM 的方案合並到 HDFS 的 trunk 之中並且作為默認的共享存儲實現,本部分只針對基於 QJM 的共享存儲方案的內部實現原理進行分析。為了理解 QJM 的設計和實現,首先要對 NameNode 的元數據存儲結構有所了解。
3.3.1 基於QJM(Quorum Journal Manager)的HA
一種推薦的方式共享存儲方式是采用QJM(Quorum Journal Manager)。在這個方案下,會運行一組的 Journal Nodes( 簡稱JNs)。
3.3.1.1 基於QJM共享存儲的HA的總架構
基於 QJM 的共享存儲系統主要用於保存 EditLog,並不保存 FSImage 文件。FSImage 文件還是在 NameNode 的本地磁盤上。QJM 共享存儲的基本思想來自於 Paxos 算法 (參見參考文獻 [3]),采用多個稱為 JournalNode 的節點組成的 JournalNode 集群來存儲 EditLog。每個 JournalNode 保存同樣的 EditLog 副本。每次 NameNode 寫 EditLog 的時候,除了向本地磁盤寫入 EditLog 之外,也會並行地向 JournalNode 集群之中的每一個 JournalNode 發送寫請求,只要大多數 (majority) 的 JournalNode 節點返回成功就認為向 JournalNode 集群寫入 EditLog 成功。如果有 2N+1 臺 JournalNode,那麽根據大多數的原則,最多可以容忍有 N 臺 JournalNode 節點掛掉。
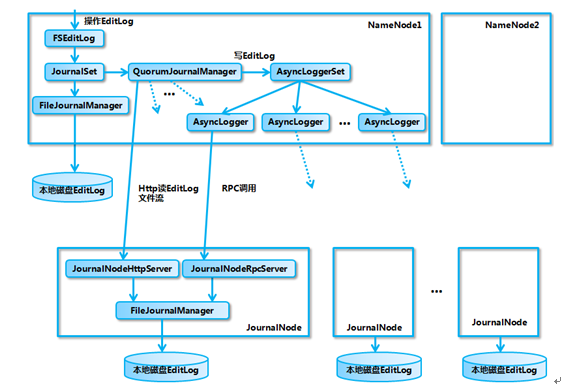
- FSEditLog:這個類封裝了對 EditLog 的所有操作,是 NameNode 對 EditLog 的所有操作的入口。
- JournalSet: 這個類封裝了對本地磁盤和 JournalNode 集群上的 EditLog 的操作,內部包含了兩類 JournalManager,一類為 FileJournalManager,用於實現對本地磁盤上 EditLog 的操作。一類為 QuorumJournalManager,用於實現對 JournalNode 集群上共享目錄的 EditLog 的操作。FSEditLog 只會調用 JournalSet 的相關方法,而不會直接使用 FileJournalManager 和 QuorumJournalManager。
- FileJournalManager:封裝了對本地磁盤上的 EditLog 文件的操作,不僅 NameNode 在向本地磁盤上寫入 EditLog 的時候使用 FileJournalManager,JournalNode 在向本地磁盤寫入 EditLog 的時候也復用了 FileJournalManager 的代碼和邏輯。
- QuorumJournalManager:封裝了對 JournalNode 集群上的 EditLog 的操作,它會根據 JournalNode 集群的 URI 創建負責與 JournalNode 集群通信的類 AsyncLoggerSet, QuorumJournalManager 通過 AsyncLoggerSet 來實現對 JournalNode 集群上的 EditLog 的寫操作,對於讀操作,QuorumJournalManager 則是通過 Http 接口從 JournalNode 上的 JournalNodeHttpServer 讀取 EditLog 的數據。
- AsyncLoggerSet:內部包含了與 JournalNode 集群進行通信的 AsyncLogger 列表,每一個 AsyncLogger 對應於一個 JournalNode 節點,另外 AsyncLoggerSet 也包含了用於等待大多數 JournalNode 返回結果的工具類方法給 QuorumJournalManager 使用。
- AsyncLogger:具體的實現類是 IPCLoggerChannel,IPCLoggerChannel 在執行方法調用的時候,會把調用提交到一個單線程的線程池之中,由線程池線程來負責向對應的 JournalNode 的 JournalNodeRpcServer 發送 RPC 請求。
- JournalNodeRpcServer:運行在 JournalNode 節點進程中的 RPC 服務,接收 NameNode 端的 AsyncLogger 的 RPC 請求。
- JournalNodeHttpServer:運行在 JournalNode 節點進程中的 Http 服務,用於接收處於 Standby 狀態的 NameNode 和其它 JournalNode 的同步 EditLog 文件流的請求。
3.3.1.2 基於 QJM 的共享存儲系統的數據同步機制分析
Active NameNode 和 StandbyNameNode 使用 JouranlNode 集群來進行數據同步的過程如圖 5 所示,Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然後 Standby NameNode 再從 JournalNode 集群定時同步 EditLog:
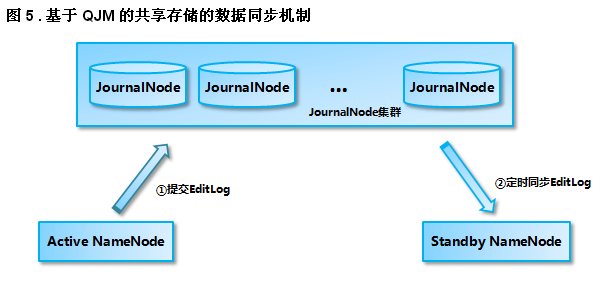
1)Active NameNode 提交 EditLog 到 JournalNode 集群
當處於 Active 狀態的 NameNode 調用 FSEditLog 類的 logSync 方法來提交 EditLog 的時候,會通過 JouranlSet 同時向本地磁盤目錄和 JournalNode 集群上的共享存儲目錄寫入 EditLog。寫入 JournalNode 集群是通過並行調用每一個 JournalNode 的 QJournalProtocol RPC 接口的 journal 方法實現的,如果對大多數 JournalNode 的 journal 方法調用成功,那麽就認為提交 EditLog 成功,否則 NameNode 就會認為這次提交 EditLog 失敗。提交 EditLog 失敗會導致 Active NameNode 關閉 JournalSet 之後退出進程,留待處於 Standby 狀態的 NameNode 接管之後進行數據恢復。
從上面的敘述可以看出,Active NameNode 提交 EditLog 到 JournalNode 集群的過程實際上是同步阻塞的,但是並不需要所有的 JournalNode 都調用成功,只要大多數 JournalNode 調用成功就可以了。如果無法形成大多數,那麽就認為提交 EditLog 失敗,NameNode 停止服務退出進程。如果對應到分布式系統的 CAP 理論的話,雖然采用了 Paxos 的“大多數”思想對 C(consistency,一致性) 和 A(availability,可用性) 進行了折衷,但還是可以認為 NameNode 選擇了 C 而放棄了 A,這也符合 NameNode 對數據一致性的要求。
2)Standby NameNode 從 JournalNode 集群同步 EditLog
當 NameNode 進入 Standby 狀態之後,會啟動一個 EditLogTailer 線程。這個線程會定期調用 EditLogTailer 類的 doTailEdits 方法從 JournalNode 集群上同步 EditLog,然後把同步的 EditLog 回放到內存之中的文件系統鏡像上 (並不會同時把 EditLog 寫入到本地磁盤上)。
這裏需要關註的是:從 JournalNode 集群上同步的 EditLog 都是處於 finalized 狀態的 EditLog Segment。“NameNode 的元數據存儲概述”一節說過 EditLog Segment 實際上有兩種狀態,處於 in-progress 狀態的 Edit Log 當前正在被寫入,被認為是處於不穩定的中間態,有可能會在後續的過程之中發生修改,比如被截斷。Active NameNode 在完成一個 EditLog Segment 的寫入之後,就會向 JournalNode 集群發送 finalizeLogSegment RPC 請求,將完成寫入的 EditLog Segment finalized,然後開始下一個新的 EditLog Segment。一旦 finalizeLogSegment 方法在大多數的 JournalNode 上調用成功,表明這個 EditLog Segment 已經在大多數的 JournalNode 上達成一致。一個 EditLog Segment 處於 finalized 狀態之後,可以保證它再也不會變化。
從上面描述的過程可以看出,雖然 Active NameNode 向 JournalNode 集群提交 EditLog 是同步的,但 Standby NameNode 采用的是定時從 JournalNode 集群上同步 EditLog 的方式,那麽 Standby NameNode 內存中文件系統鏡像有很大的可能是落後於 Active NameNode 的,所以 Standby NameNode 在轉換為 Active NameNode 的時候需要把落後的 EditLog 補上來。
3.3.1.3 基於 QJM 的共享存儲系統的數據恢復機制分析
處於Standby 狀態的 NameNode 轉換為 Active 狀態的時候,有可能上一個 Active NameNode 發生了異常退出,那麽 JournalNode 集群中各個 JournalNode 上的 EditLog 就可能會處於不一致的狀態,所以首先要做的事情就是讓 JournalNode 集群中各個節點上的 EditLog 恢復為一致。另外如前所述,當前處於 Standby 狀態的 NameNode 的內存中的文件系統鏡像有很大的可能是落後於舊的 Active NameNode 的,所以在 JournalNode 集群中各個節點上的 EditLog 達成一致之後,接下來要做的事情就是從 JournalNode 集群上補齊落後的 EditLog。只有在這兩步完成之後,當前新的 Active NameNode 才能安全地對外提供服務。
補齊落後的 EditLog 的過程復用了前面描述的 Standby NameNode 從 JournalNode 集群同步 EditLog 的邏輯和代碼,最終調用 EditLogTailer 類的 doTailEdits 方法來完成 EditLog 的補齊。使 JournalNode 集群上的 EditLog 達成一致的過程是一致性算法 Paxos 的典型應用場景,QJM 對這部分的處理可以看做是 Single Instance Paxos(參見參考文獻 [3]) 算法的一個實現,在達成一致的過程中,Active NameNode 和 JournalNode 集群之間的交互流程如圖 6 所示,具體描述如下:
圖 6.Active NameNode 和 JournalNode 集群的交互流程圖

1)生成一個新的 Epoch
Epoch 是一個單調遞增的整數,用來標識每一次 Active NameNode 的生命周期,每發生一次 NameNode 的主備切換,Epoch 就會加 1。這實際上是一種 fencing 機制,為什麽需要 fencing 已經在前面“ActiveStandbyElector 實現分析”一節的“防止腦裂”部分進行了說明。產生新 Epoch 的流程與 Zookeeper 的 ZAB(Zookeeper Atomic Broadcast) 協議在進行數據恢復之前產生新 Epoch 的過程完全類似:
Active NameNode 首先向 JournalNode 集群發送 getJournalState RPC 請求,每個 JournalNode 會返回自己保存的最近的那個 Epoch(代碼中叫 lastPromisedEpoch)。
NameNode 收到大多數的 JournalNode 返回的 Epoch 之後,在其中選擇最大的一個加 1 作為當前的新 Epoch,然後向各個 JournalNode 發送 newEpoch RPC 請求,把這個新的 Epoch 發給各個 JournalNode。
每一個 JournalNode 在收到新的 Epoch 之後,首先檢查這個新的 Epoch 是否比它本地保存的 lastPromisedEpoch 大,如果大的話就把 lastPromisedEpoch 更新為這個新的 Epoch,並且向 NameNode 返回它自己的本地磁盤上最新的一個 EditLogSegment 的起始事務 id,為後面的數據恢復過程做好準備。如果小於或等於的話就向 NameNode 返回錯誤。
NameNode 收到大多數 JournalNode 對 newEpoch 的成功響應之後,就會認為生成新的 Epoch 成功。
在生成新的 Epoch 之後,每次 NameNode 在向 JournalNode 集群提交 EditLog 的時候,都會把這個 Epoch 作為參數傳遞過去。每個 JournalNode 會比較傳過來的 Epoch 和它自己保存的 lastPromisedEpoch 的大小,如果傳過來的 epoch 的值比它自己保存的 lastPromisedEpoch 小的話,那麽這次寫相關操作會被拒絕。一旦大多數 JournalNode 都拒絕了這次寫操作,那麽這次寫操作就失敗了。如果原來的 Active NameNode 恢復正常之後再向 JournalNode 寫 EditLog,那麽因為它的 Epoch 肯定比新生成的 Epoch 小,並且大多數的 JournalNode 都接受了這個新生成的 Epoch,所以拒絕寫入的 JournalNode 數目至少是大多數,這樣原來的 Active NameNode 寫 EditLog 就肯定會失敗,失敗之後這個 NameNode 進程會直接退出,這樣就實現了對原來的 Active NameNode 的隔離了。
2)選擇需要數據恢復的 EditLog Segment 的 id
需要恢復的 Edit Log 只可能是各個 JournalNode 上的最後一個 Edit Log Segment,如前所述,JournalNode 在處理完 newEpoch RPC 請求之後,會向 NameNode 返回它自己的本地磁盤上最新的一個 EditLog Segment 的起始事務 id,這個起始事務 id 實際上也作為這個 EditLog Segment 的 id。NameNode 會在所有這些 id 之中選擇一個最大的 id 作為要進行數據恢復的 EditLog Segment 的 id。
3)向 JournalNode 集群發送 prepareRecovery RPC 請求
NameNode 接下來向 JournalNode 集群發送 prepareRecovery RPC 請求,請求的參數就是選出的 EditLog Segment 的 id。JournalNode 收到請求後返回本地磁盤上這個 Segment 的起始事務 id、結束事務 id 和狀態 (in-progress 或 finalized)。
這一步對應於 Paxos 算法的 Phase 1a 和 Phase 1b(參見參考文獻 [3]) 兩步。Paxos 算法的 Phase1 是 prepare 階段,這也與方法名 prepareRecovery 相對應。並且這裏以前面產生的新的 Epoch 作為 Paxos 算法中的提案編號 (proposal number)。只要大多數的 JournalNode 的 prepareRecovery RPC 調用成功返回,NameNode 就認為成功。
選擇進行同步的基準數據源,向 JournalNode 集群發送 acceptRecovery RPC 請求 NameNode 根據 prepareRecovery 的返回結果,選擇一個 JournalNode 上的 EditLog Segment 作為同步的基準數據源。選擇基準數據源的原則大致是:在 in-progress 狀態和 finalized 狀態的 Segment 之間優先選擇 finalized 狀態的 Segment。如果都是 in-progress 狀態的話,那麽優先選擇 Epoch 比較高的 Segment(也就是優先選擇更新的),如果 Epoch 也一樣,那麽優先選擇包含的事務數更多的 Segment。
在選定了同步的基準數據源之後,NameNode 向 JournalNode 集群發送 acceptRecovery RPC 請求,將選定的基準數據源作為參數。JournalNode 接收到 acceptRecovery RPC 請求之後,從基準數據源 JournalNode 的 JournalNodeHttpServer 上下載 EditLog Segment,將本地的 EditLog Segment 替換為下載的 EditLog Segment。
這一步對應於 Paxos 算法的 Phase 2a 和 Phase 2b(參見參考文獻 [3]) 兩步。Paxos 算法的 Phase2 是 accept 階段,這也與方法名 acceptRecovery 相對應。只要大多數 JournalNode 的 acceptRecovery RPC 調用成功返回,NameNode 就認為成功。
4)向 JournalNode 集群發送 finalizeLogSegment RPC 請求,數據恢復完成
上一步執行完成之後,NameNode 確認大多數 JournalNode 上的 EditLog Segment 已經從基準數據源進行了同步。接下來,NameNode 向 JournalNode 集群發送 finalizeLogSegment RPC 請求,JournalNode 接收到請求之後,將對應的 EditLog Segment 從 in-progress 狀態轉換為 finalized 狀態,實際上就是將文件名從 edits_inprogress_${startTxid} 重命名為 edits_${startTxid}-${endTxid},見“NameNode 的元數據存儲概述”一節的描述。
只要大多數 JournalNode 的 finalizeLogSegment RPC 調用成功返回,NameNode 就認為成功。此時可以保證 JournalNode 集群的大多數節點上的 EditLog 已經處於一致的狀態,這樣 NameNode 才能安全地從 JournalNode 集群上補齊落後的 EditLog 數據。
需要註意的是,盡管基於 QJM 的共享存儲方案看起來理論完備,設計精巧,但是仍然無法保證數據的絕對強一致,下面選取參考文獻 [2] 中的一個例子來說明:假設有 3 個 JournalNode:JN1、JN2 和 JN3,Active NameNode 發送了事務 id 為 151、152 和 153 的 3 個事務到 JournalNode 集群,這 3 個事務成功地寫入了 JN2,但是在還沒能寫入 JN1 和 JN3 之前,Active NameNode 就宕機了。同時,JN3 在整個寫入的過程中延遲較大,落後於 JN1 和 JN2。最終成功寫入 JN1 的事務 id 為 150,成功寫入 JN2 的事務 id 為 153,而寫入到 JN3 的事務 id 僅為 125,如圖 7 所示 (圖片來源於參考文獻 [2])。按照前面描述的只有成功地寫入了大多數的 JournalNode 才認為寫入成功的原則,顯然事務 id 為 151、152 和 153 的這 3 個事務只能算作寫入失敗。在進行數據恢復的過程中,會發生下面兩種情況:
圖 7.JournalNode 集群寫入的事務 id 情況
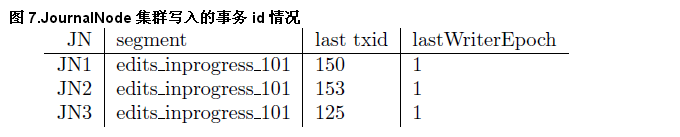
a)如果隨後的 Active NameNode 進行數據恢復時在 prepareRecovery 階段收到了 JN2 的回復,那麽肯定會以 JN2 對應的 EditLog Segment 為基準來進行數據恢復,這樣最後在多數 JournalNode 上的 EditLog Segment 會恢復到事務 153。從恢復的結果來看,實際上可以認為前面宕機的 Active NameNode 對事務 id 為 151、152 和 153 的這 3 個事務的寫入成功了。但是如果從 NameNode 自身的角度來看,這顯然就發生了數據不一致的情況。
b)如果隨後的 Active NameNode 進行數據恢復時在 prepareRecovery 階段沒有收到 JN2 的回復,那麽肯定會以 JN1 對應的 EditLog Segment 為基準來進行數據恢復,這樣最後在多數 JournalNode 上的 EditLog Segment 會恢復到事務 150。在這種情況下,如果從 NameNode 自身的角度來看的話,數據就是一致的了。
事實上不光本文描述的基於 QJM 的共享存儲方案無法保證數據的絕對一致,大家通常認為的一致性程度非常高的 Zookeeper 也會發生類似的情況,這也從側面說明了要實現一個數據絕對一致的分布式存儲系統的確非常困難。
3.3.2基於NFS共享存儲的HA
在理解了上面的ha架構後,以及基於qjm的共享存儲方案後,想來基於nfs的共享存儲也同樣可以解決類似問題。
具體詳情參見:
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html
3.3.3 NameNode 在進行狀態轉換時對共享存儲的處理
下面對 NameNode 在進行狀態轉換的過程中對共享存儲的處理進行描述,使得大家對基於 QJM 的共享存儲方案有一個完整的了解,同時也作為本部分的總結。
1)NameNode 初始化啟動,進入 Standby 狀態
在 NameNode 以 HA 模式啟動的時候,NameNode 會認為自己處於 Standby 模式,在 NameNode 的構造函數中會加載 FSImage 文件和 EditLog Segment 文件來恢復自己的內存文件系統鏡像。在加載 EditLog Segment 的時候,調用 FSEditLog 類的 initSharedJournalsForRead 方法來創建只包含了在 JournalNode 集群上的共享目錄的 JournalSet,也就是說,這個時候只會從 JournalNode 集群之中加載 EditLog,而不會加載本地磁盤上的 EditLog。另外值得註意的是,加載的 EditLog Segment 只是處於 finalized 狀態的 EditLog Segment,而處於 in-progress 狀態的 Segment 需要後續在切換為 Active 狀態的時候,進行一次數據恢復過程,將 in-progress 狀態的 Segment 轉換為 finalized 狀態的 Segment 之後再進行讀取。
加載完 FSImage 文件和共享目錄上的 EditLog Segment 文件之後,NameNode 會啟動 EditLogTailer 線程和 StandbyCheckpointer 線程,正式進入 Standby 模式。如前所述,EditLogTailer 線程的作用是定時從 JournalNode 集群上同步 EditLog。而 StandbyCheckpointer 線程的作用其實是為了替代 Hadoop 1.x 版本之中的 Secondary NameNode 的功能,StandbyCheckpointer 線程會在 Standby NameNode 節點上定期進行 Checkpoint,將 Checkpoint 之後的 FSImage 文件上傳到 Active NameNode 節點。
2)NameNode 從 Standby 狀態切換為 Active 狀態
當 NameNode 從 Standby 狀態切換為 Active 狀態的時候,首先需要做的就是停止它在 Standby 狀態的時候啟動的線程和相關的服務,包括上面提到的 EditLogTailer 線程和 StandbyCheckpointer 線程,然後關閉用於讀取 JournalNode 集群的共享目錄上的 EditLog 的 JournalSet,接下來會調用 FSEditLog 的 initJournalSetForWrite 方法重新打開 JournalSet。不同的是,這個 JournalSet 內部同時包含了本地磁盤目錄和 JournalNode 集群上的共享目錄。這些工作完成之後,就開始執行“基於 QJM 的共享存儲系統的數據恢復機制分析”一節所描述的流程,調用 FSEditLog 類的 recoverUnclosedStreams 方法讓 JournalNode 集群中各個節點上的 EditLog 達成一致。然後調用 EditLogTailer 類的 catchupDuringFailover 方法從 JournalNode 集群上補齊落後的 EditLog。最後打開一個新的 EditLog Segment 用於新寫入數據,同時啟動 Active NameNode 所需要的線程和服務。
3)NameNode 從 Active 狀態切換為 Standby 狀態
當 NameNode 從 Active 狀態切換為 Standby 狀態的時候,首先需要做的就是停止它在 Active 狀態的時候啟動的線程和服務,然後關閉用於讀取本地磁盤目錄和 JournalNode 集群上的共享目錄的 EditLog 的 JournalSet。接下來會調用 FSEditLog 的 initSharedJournalsForRead 方法重新打開用於讀取 JournalNode 集群上的共享目錄的 JournalSet。這些工作完成之後,就會啟動 EditLogTailer 線程和 StandbyCheckpointer 線程,EditLogTailer 線程會定時從 JournalNode 集群上同步 Edit Log。
4、HDFS Federation
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/Federation.html
聯邦模式隨後說明
5、HDFS 健壯性
HDFS 的主要目標就是即使在出錯的情況下也要保證數據存儲的可靠性。 常見的三種出錯情況是: Namenode 出錯 , Datanode 出錯和網絡割裂 ( network partitions) 。
磁盤數據錯誤,心跳檢測和重新復制
每個 Datanode 節點周期性地向 Namenode 發送心跳信號。網絡割裂可能 導致一部分 Datanode 跟 Namenode 失去聯系。 Namenode 通過心跳信號的缺 失來檢測這一情況,並將這些近期不再發送心跳信號 Datanode 標記為宕機 ,不會再將新的 IO 請求發給它們。任何存儲在宕機 Datanode 上的數據將不 再有效。 Datanode 的宕機可能會引起一些數據塊的副本系數低於指定值, Namenode 不斷地檢測這些需要復制的數據塊,一旦發現就啟動復制操作。
在下列情況下,可能需要重新復制:某個 Datanode 節點失效,某個副本遭 到損壞, Datanode 上的硬盤錯誤,或者文件的副本系數增大。
數據完整性
從某個 Datanode 獲取的數據塊有可能是損壞的,損壞可能是由 Datanode 的存儲設備錯誤、網絡錯誤或者軟件 bug 造成的。
HDFS 客戶端軟 件實現了對 HDFS 文件內容的校驗和 (checksum) 檢查。當客戶端創建一個新 的 HDFS 文件,會計算這個文件每個數據塊的校驗和,並將校驗和作為一個 單獨的隱藏文件保存在同一個 HDFS 名字空間下。當客戶端獲取文件內容後 ,它會檢驗從 Datanode 獲取的數據跟相應的校驗和文件中的校驗和是否匹 配,如果不匹配,客戶端可以選擇從其他 Datanode 獲取該數據塊的副本。
元數據磁盤錯誤
FsImage 和 Editlog 是 HDFS 的核心數據結構。如果這些文件損壞了,整個 HDFS 實例都將失效。因而, Namenode 可以配置成支持維護多個 FsImage 和 Editlog 的副本。任何對 FsImage 或者 Editlog 的修改,都將同步到它們的副 本上。這種多副本的同步操作可能會降低 Namenode 每秒處理的名字空間事 務數量。然而這個代價是可以接受的,因為即使 HDFS 的應用是數據密集的 ,它們也非元數據密集的。當 Namenode 重啟的時候,它會選取最近的完整 的 FsImage 和 Editlog 來使用。
Namenode 是 HDFS 集群中的單點故障 (single point of failure) 所在。如果 Namenode 機器故障,是需要手工幹預的。目前,自動重啟或在另一臺機器 上做 Namenode 故障轉移的功能還沒實現。
快照
快照支持某一特定時刻的數據的復制備份。利用快照,可以讓 HDFS 在 數據損壞時恢復到過去一個已知正確的時間點。 HDFS 目前還不支持快照功 能,但計劃在將來的版本進行支持。
本文參考:
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/#N1008F
HDFS 架構簡述