
scrapy爬蟲框架
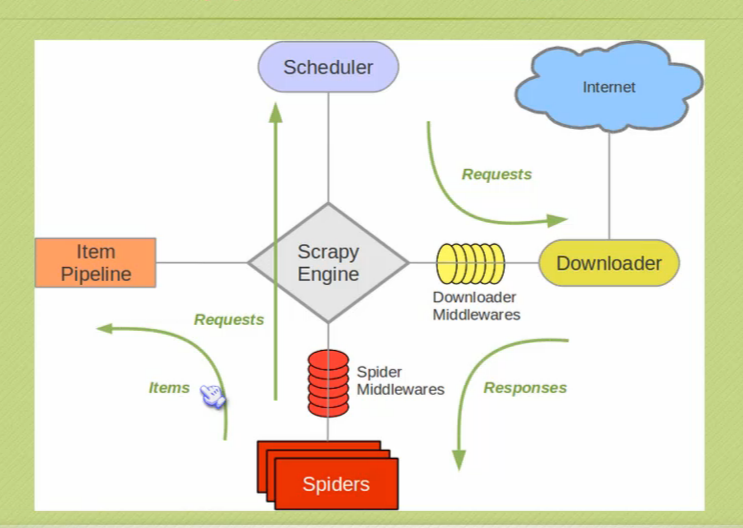
downloader:負責下載html頁面
spider:負責爬取頁面內容,我們需要自己寫爬取規則 srapy提供了selector,獲取的方式有xpath,css,正則,extract
item容器:spider獲取到的內容放到item中
schedul:負責調度
scrapy爬蟲框架
相關推薦
Python 和 Scrapy 爬蟲框架部署
python scrapy 爬蟲框架 Scrapy 是采用Python 開發的一個快速可擴展的抓取WEB 站點內容的爬蟲框架。安裝依賴 yum install gcc gcc-c++ openssl mysql mysql-server libffi* libxml* libxml2 l
Scrapy 爬蟲框架入門案例詳解
tin mon setting 爬蟲框架 finished perror project 原因 create 歡迎大家關註騰訊雲技術社區-博客園官方主頁,我們將持續在博客園為大家推薦技術精品文章哦~ 作者:崔慶才 Scrapy入門 本篇會通過介紹一
scrapy爬蟲框架
cnblogs logs spi down 方式 ges htm width sched downloader:負責下載html頁面 spider:負責爬取頁面內容,我們需要自己寫爬取規則 srapy提供了selector,獲取的方式有xpath,css,正則,extr
scrapy爬蟲框架實例之一
獲取 名稱 返回 工程 ima 1-57 response lines star 本實例主要通過抓取慕課網的課程信息來展示scrapy框架抓取數據的過程。 1、抓取網站情況介紹 抓取網站:http://www.imooc.com/course/list
python爬蟲—使用scrapy爬蟲框架
pywin32 rip for 鏈接 是把 ror sdn 成功 repl 問題1.使用scrapy框架,使用命令提示符pip命令下載scrapy後,卻無法使用scrapy命令,出現scrapy不是內部或外部命令。也不是可運行的程序 解決:一開始,我是把python安裝在
Python之Scrapy爬蟲框架安裝及簡單使用
intern 原理 seda api release linux發行版 3.5 pic www 題記:早已聽聞python爬蟲框架的大名。近些天學習了下其中的Scrapy爬蟲框架,將自己理解的跟大家分享。有表述不當之處,望大神們斧正。 一、初窺Scrapy Scrapy是
2017.07.26 Python網絡爬蟲之Scrapy爬蟲框架
返回 scripts http ref select 文本 lang bsp str 1.windows下安裝scrapy:cmd命令行下:cd到python的scripts目錄,然後運行pip install 命令 然後pycharmIDE下就有了Scrapy:
scrapy爬蟲框架setting模塊解析
ocs 不用 依賴 cookies received over ade maximum ole 平時寫爬蟲的時候並不需要設置setting裏所有的參數,今天心血來潮,花了點時間查了一下setting模塊創建後自動寫入的所有參數的含義,記錄一下。 模塊相關說明信息 # -
Scrapy爬蟲框架第一講(Linux環境)
配置文件 如何解決 成了 文件路徑 selenium linux 文件 權限 vmw 1、What is Scrapy? 答:Scrapy是一個使用python語言(基於Twistec框架)編寫的開源網絡爬蟲框架,其結構清晰、模塊之間的耦合程度低,具有較強的擴張性,能滿足
Python3環境安裝Scrapy爬蟲框架過程
-o 每一個 evel base awl 列表 all field size Python3環境安裝Scrapy爬蟲框架過程 1. 安裝wheel pip install wheel 安裝檢查: 2. 安裝lxml pip install lxml-4.2.1-c
Scrapy爬蟲框架第七講【ITEM PIPELINE用法】
不能 doc from 參考 數據去重 17. con pic set ITEM PIPELINE用法詳解: ITEM PIPELINE作用: 清理HTML數據 驗證爬取的數據(檢查item包含某些字段) 去重(並丟棄)【預防數據去重,真正去重是在url,即請求階段
Scrapy爬蟲框架下執行爬蟲的方法
python sta 方法 args setting crawler split req .cn 在使用Scrapy框架進行爬蟲時,執行爬蟲文件的方法是 scrapy crawl xxx ,其中 xxx 是爬蟲文件名。 但是,當我們在建立了多個文件時,使用上面的命令
Scrapy(爬蟲框架)中,Spider類中parse()方法的工作機制
生成 工作 就會 ffffff 遞歸 賦值 () 其他 根據 parse(self,response):當請求url返回網頁沒有指定回調函數,默認的Request對象的回調函數,用來處理網頁返回的response,和生成的Item或者Request對象 以下分析一下pars
Scrapy爬蟲框架的安裝和使用
deep 使用 cts file pen ESS win .org all Scrapy是一個十分強大的爬蟲框架,依賴的庫比較多,至少需要依賴的庫有Twisted 14.0、lxml 3.4和pyOpenSSL 0.14。在不同的平臺環境下,它所依賴的庫也各不相同,所以在安
Python爬蟲教程-30-Scrapy 爬蟲框架介紹
start pre 出錯 名稱 erp pro rtp ise 結構性 從本篇開始學習 Scrapy 爬蟲框架 Python爬蟲教程-30-Scrapy 爬蟲框架介紹 框架:框架就是對於相同的相似的部分,代碼做到不出錯,而我們就可以將註意力放到我們自己的部分了 常見爬蟲框
scrapy爬蟲框架(三):爬取桌布儲存並命名
寫在開始之前 按照上一篇介紹過的 scrapy爬蟲的建立順序,我們開始爬取桌布的爬蟲的建立。 首先,我們先過一遍 scrapy爬蟲的建立順序: 第一步:確定要在pipelines裡進行處理的資料,寫好items檔案 第二步:建立爬蟲檔案,將所需要的資訊從
scrapy爬蟲框架(二):建立一個scrapy爬蟲
在建立新的scrapy爬蟲之前,我們需要先了解一下建立一個scrapy爬蟲的基本步驟 一、確定要爬取的資料 以爬取豆瓣電影資料為例: 每部電影所要爬取的資訊有: 片名:《頭號玩家》 導演: 史蒂文·斯皮爾伯格 編劇: 扎克·佩恩 / 恩斯特·克萊
scrapy爬蟲框架(一):scrapy框架簡介
一、安裝scrapy框架 #開啟命令列輸入如下命令: pip install scrapy 二、建立一個scrapy專案 安裝完成後,python會自動將 scrapy命令新增到環境變數中去,這時我們就可以使用 scrapy命令來建立我們的第一個 scrapy專案了。
scrapy爬蟲框架(四):scrapy中 yield使用詳解
開始前的準備工作: MySQL下載:點我 python MySQL驅動下載:pymysql(pyMySql,直接用pip方式安裝) 全部安裝好之後,我們來熟悉一下pymysql模組 import pymysql #建立連結物件 connection = pymysql
Python Scrapy 爬蟲框架例項(一)
之前有介紹 scrapy 的相關知識,但是沒有介紹相關例項,在這裡做個小例,供大家參考學習。 注:後續不強調python 版本,預設即為python3.x。 爬取目標 這裡簡單找一個圖片網站,獲取圖片的先關資訊。 該網站網址: http://www.58pic.com/c/ 建立專案 終端命令列執